当你通过第三方供应商使用 AI 模型时,你会发现一个尴尬的现实:模型在快速迭代,而你的配置永远慢一拍。这篇文章记录了我从发现痛点,到构建 Yi-Shepherd(AI 模型牧羊人)的完整思考过程。
🎬 起因:一个被忽视的痛点
某天在使用 opencode(一个开源的 AI 终端编程助手)进行日常开发,通过 UCloud 这样的"中转站"来访问各家旗舰模型。
一切看起来很美好------直到某天我发现:
- Claude Opus 4.6 上线了三天,我还在用 4.5
- GPT-5.3 已经发布,我的配置里还写着 5.2
- 一个已下架的模型让我的 agent 调用直接报错
于是乎就查看UCloud手动维护模型列表? 需要:
- 去 API 文档或调接口看有哪些新模型
- 打开 JSON 配置文件手动添加
- 判断哪些旧模型该淘汰
- 更新你的 agent 配置里的模型引用
- 每隔几天重复以上步骤
这不是一个 5 分钟的事------当你管理着 20+ 个模型系列、每个系列有多个变体(base、thinking、preview),特别是中转站这种聚合了多家多个系列的模型,手动维护就变成了一种折磨。
核心矛盾:供应商的模型更新是连续的,而我们的配置更新是离散的。这个 gap 越大,稍微不留神,就越容易踩坑。
调研:这不是个例
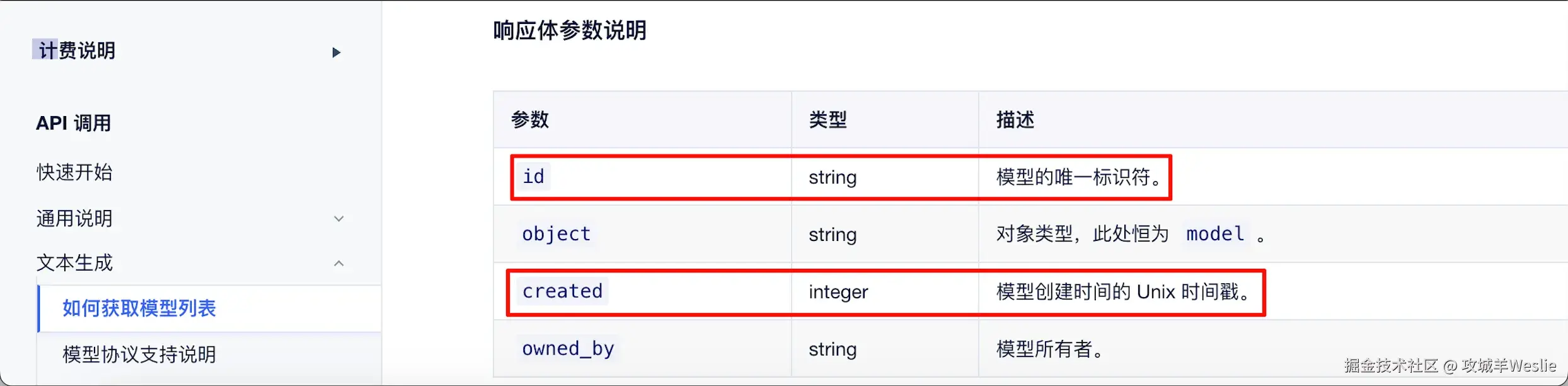
有了这个痛点后,我好奇地看了看其他中转站------OpenRouter、One API、New API 等。结果发现,它们的模型列表接口几乎如出一辙,都遵循 OpenAI 兼容的 /v1/models 规范:
| UCloud ModelVerse | OpenRouter |
|---|---|
 |
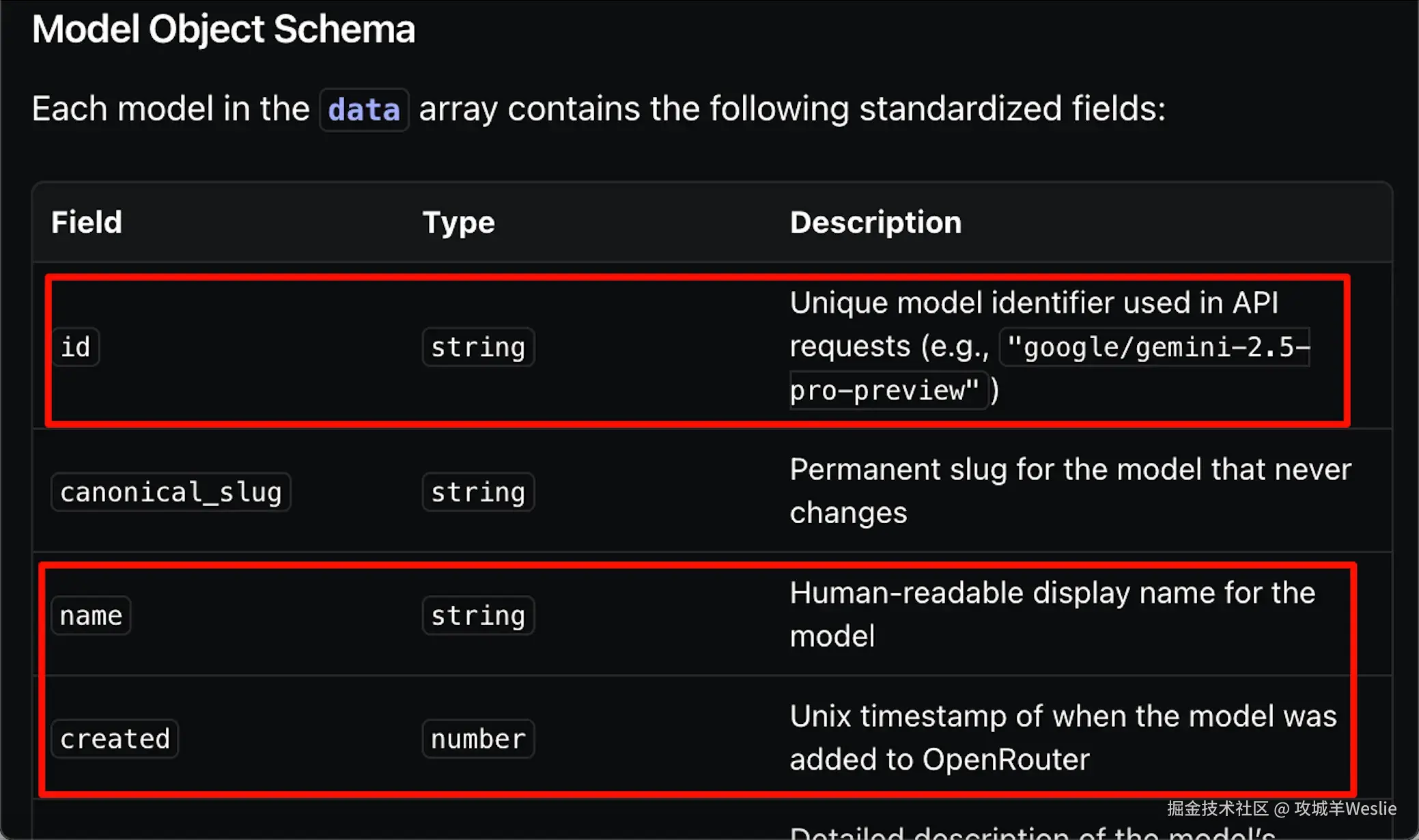 |
核心字段完全一致------id(模型标识)、created(创建时间戳)------这意味着同一套同步逻辑可以适用于大部分中转站。
这让我想到一个画面:150+ 个模型散落在旷野上,旗舰的、实验的、旧版的、重复的------它们就像一群无序的羊。我需要一个牧羊人------而且是一个能在任何草原上放牧的牧羊人。
于是,就写了这个Yi-Shepherd 。
当然,也有一些中转站并没有提供标准的模型列表 API,而是直接在页面上列出可用的模型 ID:
不过这类中转站自身已经做过一轮时效性筛选------只展示当前可用的模型,而且命名通常比较规范(如
claude-opus-4-6、claude-sonnet-4-5-20250929)。这意味着即使没有 API,你也可以根据页面上的模型 ID 构造一份静态列表,再用同一套分组和版本管理规则来处理。
🧠 思考:这个问题的本质是什么
在动手写代码之前,我先梳理了问题的结构:
模型供应商 API ──→ 百余个模型(含各种变体、旧版本、非旗舰)
↓
我只需要 ~50 个旗舰模型
↓
而且只需要每个系列最新的 2 个大版本
↓
更新完还要同步到 agent 配置中
↓
最好有变更通知,别让我猜每一步都有明确的输入和输出,适合用脚本自动化。
🏗️ 第一步:巡牧------模型数据采集
最简单的一步------正如前面调研所见,几乎所有模型供应商都提供 OpenAI 兼容的 /v1/models 接口:
python
def fetch_models() -> list[dict]:
req = urllib.request.Request(API_URL, headers={"Content-Type": "application/json"})
with urllib.request.urlopen(req, timeout=30, context=ctx) as resp:
data = json.loads(resp.read().decode("utf-8"))
return data.get("data", [])返回的数据结构统一而简洁------无论 UCloud 还是 OpenRouter,我们只需要 id 和 created 两个字段:
json
{"id": "claude-opus-4-6", "created": 1738800000, "owned_by": "anthropic"}💡 可复用思路 :正因为各家中转站都遵循同一套 OpenAI 兼容规范,Yi-Shepherd 设计之初就不绑定任何特定供应商。只要 API 返回
{data: [{id, created}]}格式,换个 API 地址和密钥就能直接用。
🔒 一个小坑:SSL 证书
首次运行就遇到了 SSL: CERTIFICATE_VERIFY_FAILED。原因是某些供应商的证书链在 macOS 上验证不过。简单粗暴但有效的解决方案:
python
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE🧹 第二步:筛选------从 147 到 50
API 返回了 147 个模型,但其中包含大量你不需要的东西:
- 语音合成模型(
speech-*) - 文本嵌入模型(
text-embedding-*) - 重复的别名(
openai/gpt-5.3和gpt-5.3是同一个模型) - 旧版本(GPT-4 系列已经过时)
- 小参数开源模型(
Qwen3-30B这种) - 实验性版本(
DeepSeek-V3.1-Exp)
牧羊人不需要管野兔和狐狸------只管好自己的羊群。我的方案是维护一个 排除正则列表:
python
EXCLUDE_PATTERNS = [
r"^speech-", # 语音模型
r"^text-embedding-", # 嵌入模型
r"^openai/", # 重复的前缀别名
r"^gpt-4[.o]", # GPT-4 太旧了
r"^Qwen/Qwen3-\d+B", # 开源小参数
r"^deepseek-ai/DeepSeek-V3\.\d+-(?:Exp|Terminus)", # 实验版
# ... 更多
]💡 可复用思路:排除规则用正则而不是硬编码模型 ID。当供应商上新模型时,排除规则不需要变动------新旗舰模型自然会通过过滤。 而且不同中转站对应的命名也不同,但核心模型名字不会变(如gpt-xxx、deepseek-xxx) 你只需要维护"什么不要"的规则,而不是"什么要"的清单。
⚠️ 踩坑:过滤太激进
但也要注意一些多模态模型,比如之前写了 ^gemini-[\d.]+-pro-image 的排除规则,本意是排除图像生成模型,结果把 gemini-3-pro-image-preview 也干掉了------但它实际上是一个强大的多模态理解模型,不是纯图像生成。
📊 第三步:分群------最核心的设计决策
问题:模型供应商的命名并不统一。哪些羊属于同一个羊群,哪些是同一代?
arduino
claude-opus-4-6
claude-opus-4-5-20251101
claude-opus-4-5-20251101-thinking
gpt-5.3-chat-latest
gpt-5.3-codex
gpt-5.3-codex-max
deepseek-ai/DeepSeek-V3.2
deepseek-ai/DeepSeek-V3.2-Think🏷️ 分层设计
我把问题拆成两层:
第一层:系列归属(SERIES_RULES)------ "哪些羊是同一品种"
python
SERIES_RULES = [
("claude-opus", r"^claude-(?:4-)?opus", "Claude Opus"),
("gpt-codex-max", r"^gpt-5[\d.]*-codex-max", "GPT Codex Max"),
("gpt-codex", r"^gpt-5[\d.]*-codex(?!-)", "GPT Codex"),
# ...
]关键细节:
- 顺序重要 ------
codex-max必须在codex之前,否则会被codex吃掉 - thinking 合入主系列 ------
claude-opus-4-5-thinking属于claude-opus,不是单独系列 - 用负向前瞻
(?!-)避免codex匹配codex-max
第二层:大版本提取(extract_major_version)------ "哪些羊是同一代"
python
def extract_major_version(model_id: str) -> tuple:
VERSION_PATTERNS = [
r'claude-(?:opus|sonnet|haiku)-(\d+)[-.](\d+)', # opus-4-6 → (4, 6)
r'gpt-(\d+)\.(\d+)', # gpt-5.3 → (5, 3)
r'DeepSeek-V(\d+)\.(\d+)', # V3.2 → (3, 2)
# ...
]返回版本元组后,同一元组的模型被视为同一大版本:
scss
claude-opus-4-5-20251101 → (4, 5)
claude-opus-4-5-20251101-thinking → (4, 5) ← 同代!
claude-opus-4-6 → (4, 6) ← 不同代✂️ 版本保留策略------汰弱留强
每个系列保留最新 2 个大版本(这里随你定义,我设置的目的是可体验最新以及上版本模型,可做对比),同一大版本内所有变体全部保留:
python
# 保留最新 2 个大版本
kept_versions = sorted_versions[:2]🔄 第四步:归栏------配置同步联动
模型列表更新后,需要同步到两个配置文件:
opencode.json(模型注册表)
python
config["provider"]["ucloud"]["models"] = {
"claude-opus-4-6": {"name": "claude-opus-4-6 (latest-2026-02-06)"},
"claude-opus-4-5-20251101": {"name": "claude-opus-4-5-20251101"},
# ...
}(latest-YYYY-MM-DD) 标注让你一眼看出哪个是最新版本,日期来自 API 的 created 时间戳。
One More Thing: oh-my-opencode.jsonc(Agent 模型分配)
由于我使用这个插件,因此在模型更新同时还需要更新对应agent适配推荐的模型。这里可查阅oh my Opencode 插件(推荐!github.com/code-yeongy... ),是一个无感实现多agent插件。
这里有一个有趣的问题:当 agent 使用的模型被新版本替代时,应该自动升级。
python
# agent 原来用 ucloud/claude-opus-4-5 → 新版是 4-6
# 自动替换为 ucloud/claude-opus-4-6但有一个边界情况------thinking 变体感知:
python
# agent 用的是 claude-opus-4-5-thinking
# 替换时不应该给它 claude-opus-4-6(非 thinking)
# 而应该找 claude-opus-4-6-thinking(如果存在)解决方案:
python
def find_best_replacement(series, old_model_id, new_models, series_latest):
suffix = extract_variant_suffix(old_model_id) # "-thinking" or None
if not suffix:
return series_latest[series] # 无后缀,直接给 latest
# 有后缀,优先找同后缀的新版本
for mid, info in new_models.items():
if info["series"] == series and mid.endswith(suffix):
return mid
# 找不到同后缀的,退回 latest
return series_latest[series]🛡️ 第五步:安全兜底------别把自己搞炸了
自动修改配置文件是危险的。万一脚本逻辑有 bug,把配置写坏了怎么办?好的牧羊人不仅放牧,还要防狼。
写前备份
python
def backup_file(path, max_backups=5):
bak_path = path.with_suffix(f".bak.{date_str}")
shutil.copy2(path, bak_path)
# 清理旧备份,只保留最新 5 个
for old_bak in sorted(glob(pattern), reverse=True)[max_backups:]:
os.remove(old_bak)每次写入前自动备份,保留 5 天的历史。出了问题随时回滚。
dry-run 模式
bash
python model-sync.py --dry-run先看看会发生什么,再决定要不要执行。所有写操作都被 dry_run 参数门控:
python
if not dry_run:
save_json(OPENCODE_JSON, config, backup=True)状态文件
model-state.json 记录上次同步的完整快照。变更检测基于 diff 而不是猜测:
python
def compute_changes(old_models, new_models):
old_ids = set(old_models.keys())
new_ids = set(new_models.keys())
return {"added": sorted(new_ids - old_ids), "removed": sorted(old_ids - new_ids)}💡 可复用思路:任何自动修改配置的工具都应该有这三件套------备份、dry-run、状态快照。它们的实现成本很低,但能在关键时刻救你一命。
📢 第六步:报信------别让自动化变成黑箱
牧羊人巡完牧要回来报信。自动化跑起来之后,你不担心它做干什么操作吗?
macOS 原生通知
python
def notify_macos(title, message):
script = f'display notification "{message}" with title "{title}"'
subprocess.run(["osascript", "-e", script], capture_output=True)简单直接,零依赖。弹窗告诉你"新增 3 个模型,淘汰 2 个模型"。
Windows Toast 通知
python
def notify_windows(title, message):
ps_script = f'''
[Windows.UI.Notifications.ToastNotificationManager, ...]
# ... PowerShell 调用 WinRT Toast API
'''
subprocess.run(["powershell", "-Command", ps_script], capture_output=True)邮件通知(HTML 格式)
用 Python 标准库 smtplib 发送带表格的 HTML 邮件,一目了然:
| 模型 ID | 显示名称 | 系列 |
|---|---|---|
gpt-5.3-chat-latest |
gpt-5.3-chat-latest (latest-2026-03-06) | gpt-chat |
关键设计:只在有变更时通知
python
if has_changes or omo_changes:
notify(...)
send_email(...)
else:
log("同步完成,无变更") # 静默,不打扰⏰ 第七步:定时巡牧------真正的"设置后遗忘"
macOS: launchd
python
def install_launchd():
plist_content = f"""
<dict>
<key>StartCalendarInterval</key>
<dict>
<key>Hour</key><integer>9</integer>
<key>Minute</key><integer>0</integer>
</dict>
</dict>
"""
# 写入 ~/Library/LaunchAgents/com.yi-shepherd.model-sync.plist
# launchctl load ...一行 --install 搞定,不用手动写 plist。
Windows: 任务计划程序
powershell
$action = New-ScheduledTaskAction -Execute "python" -Argument "C:\path\to\model-sync.py"
$trigger = New-ScheduledTaskTrigger -Daily -At "09:00"
Register-ScheduledTask -TaskName "Yi-Shepherd" -Action $action -Trigger $triggerLinux: cron
bash
0 9 * * * /usr/bin/python3 /path/to/model-sync.py >> /path/to/sync.log 2>&1🎯 总结:"牧羊人"
回顾整个过程,有几个思路还是可以运用到之后自动化场景(特别是目前引入ai后,要掌控好ai这个黑盒)的:
1. 🛡️ 安全三件套
备份 + dry-run + 状态快照。成本极低,收益极高。
2. 📦 零依赖哲学
整个脚本只用 Python 标准库,没有 pip install 这一步。这意味着:
- 在任何有 Python 3.10+ 的机器上都能直接跑
- 不需要虚拟环境
- 不会因为某个三方包更新而 break
- 部署成本 ≈ 0
3. 🔔 渐进式通知
无变更 → 静默日志;有变更 → 系统通知 + 邮件。不制造噪音,但不遗漏重要信息。
🐑 Yi-Shepherd------我的模型牧羊人。如果你也在用一些中转站,可能苦于配置,不妨试试把模型管理自动化------一次配置,终身受益。
项目地址: Gitee - Yi-Shepherd
做的不足的地方恳请各位佬指点