本篇文章为Linux学习的进程控制部分学习分享,希望也能够为你带来些许的帮助!
那咱们废话不多说,直接开始吧!
一、进程创建
当一个进程还没创建子进程时,它的数据段在页表中的权限是 "读写"。
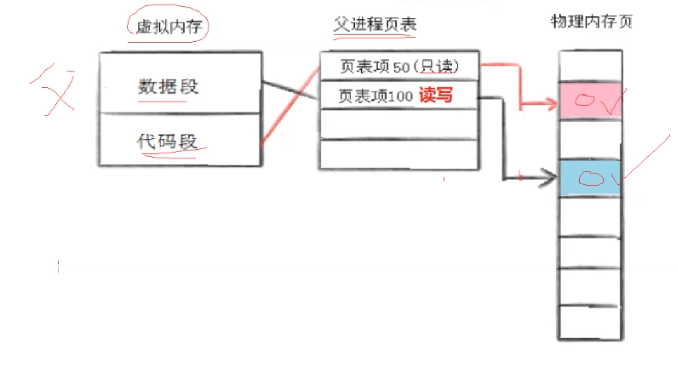
可一旦调用fork()创建子进程后,情况就变了 ------ 子进程的数据段权限会改成 "只读"。为啥呢?因为子进程的代码和数据都是从父进程那拷贝来的,初始状态下父子俩共享这些东西,所以权限得保持一致,先设成 "只读"。
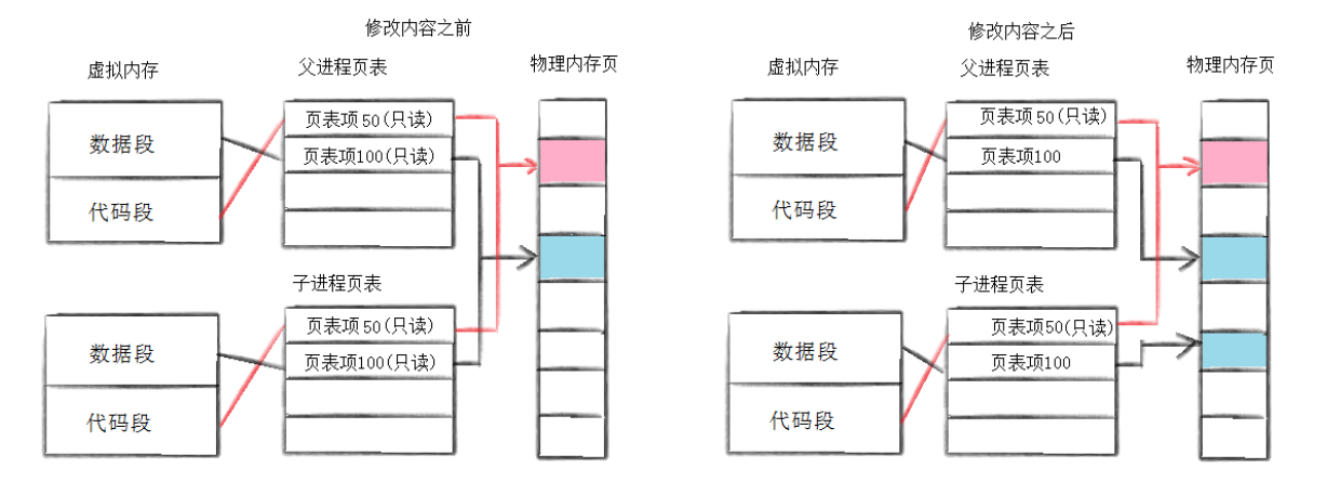
这时候要是有一方想修改数据,系统就会 "出面" 判断:
- 要是发现这个写入操作在页表里压根没有对应的映射关系 ------ 系统会吐槽:"好好好原来是个野指针啊",直接判定是真错误,把进程终止掉!
- 要是页表里有映射关系,只是用户想修改 ------ 那 OS 就会先搞 "写时拷贝" 操作,拷贝完了再把父子进程的数据段权限改回 "读写"。
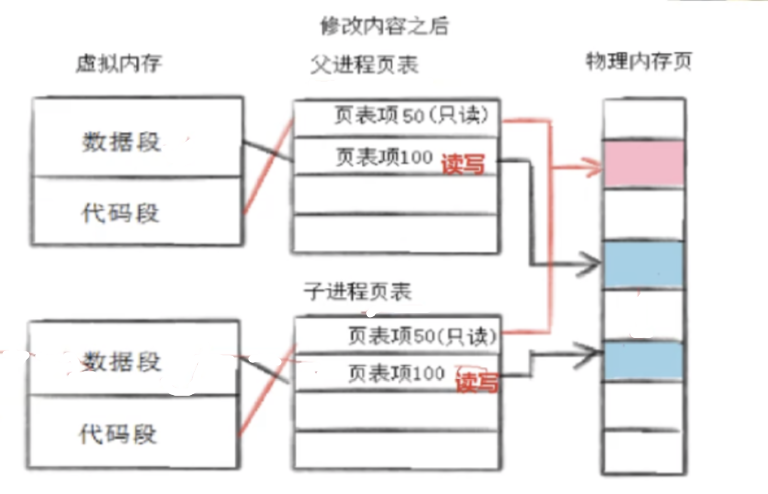
关于写时拷贝的两个常见问题
1. 为啥创建子进程后不直接给子进程拷贝一份父进程的数据,非要搞写时拷贝呢?
这你就不知道了吧!
首先,子进程不一定会修改父进程的数据啊,可能就是只读,这时候直接拷贝一份纯属浪费内存;其次,写时拷贝本质是 "按需获取",只有被修改的内容才会复制,没改的(哪怕属于数据段)还能保持共享,比全拷贝省太多内存了;
而且这还是一种 "惰性申请",不需要的时候,内存资源可以先给别的进程用,能提高资源利用率。
2. 那为啥非要拷贝呢?只给子进程开辟需要的空间不行吗?
你想啊,咱们平时改数据,很多时候是 "覆盖式修改",但像 "++a" 这种操作,它得先知道 a 的原始值啊!没有原始数据咋自增?所以拷贝操作是必须的。
拓展问题:C/C++ 里的 malloc/new 是直接在物理内存上开辟空间吗?
当然不是!调用 malloc/new 的时候,系统只会先给你开辟一块虚拟地址空间。等你真要访问这块地址时,因为物理页还没分配,就会触发 "缺页中断"。
这时候系统才会实际去申请物理内存,再把虚拟地址和物理地址的映射关系建好。这整个过程就是 "惰性空间开辟",咱们用户完全感知不到,也不用操心。
二、进程终止
先搞懂两个基础问题
1. 进程终止后会发生啥?
系统会回收进程的虚拟地址、页表和物理内存,然后把 PCB 里的进程状态改成 "僵尸状态"。
2. main 函数里的 return 0 到底啥意思?这个 0 给谁了?
这个 return 的 0 啊,其实是进程运行结束后的 "退出码",会被系统拿到,用来判断进程任务完成得咋样:0 表示成功,非 0 表示失败,而且不同数字对应不同失败原因。
咱们在命令行里用echo $?就能查到最近一个进程的退出码。比如你把 main 函数的退出码设成 2:
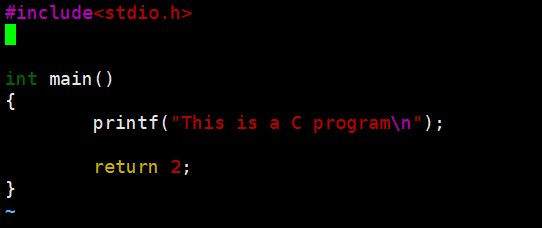
第一次执行echo $?会显示 2,但第二次就变成 0 了
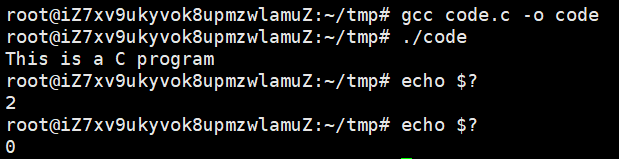
为啥?
因为第一次显示的是那个退出码为 2 的进程的结果,第二次显示的是echo $?这个命令自己的退出码(它成功完成了显示任务,所以是 0)。
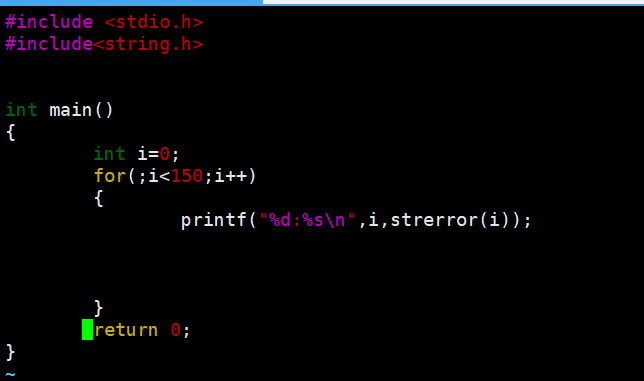
系统其实早就给咱们准备了一堆错误原因,用strerror()函数就能拿到字符串形式的错误描述,足足有 134 种呢!

进程退出的三种情况
- 代码跑完,结果正确
- 代码跑完,结果错误
- 代码没跑完,进程异常
前两种情况由退出码决定,对应的有三种设置退出码的方法:
- 在 main 函数里 return n,n 就是退出码
- 直接调用
exit(n),n 是退出码 - 直接调用
_exit(n),n 是退出码
肯定有人会问:
return 和 exit () 有啥区别?exit () 和_exit () 又有啥区别?
别急,听我慢慢说:
- return 本来是表示函数调用结束,但 main 函数比较特殊,它是进程的入口,所以 main 里的 return 也代表进程结束;而 exit () 是专门表示进程退出的,跟 return 不一样,它能在程序任意地方调用。
- exit () 和_exit () 的区别更关键:exit () 是库函数,_exit () 是系统调用;用 exit () 退出时,输出缓冲区会自动刷新(哪怕 printf 里没加 \n),但_exit () 会直接结束进程,不刷新缓冲区。
给你看几个测试用例就明白了:
- return的测试:return n,退出码就是 n


- exit () 的测试:不但会把缓冲区内容打印出来,而且调用后确实退出了,退出码是 3。
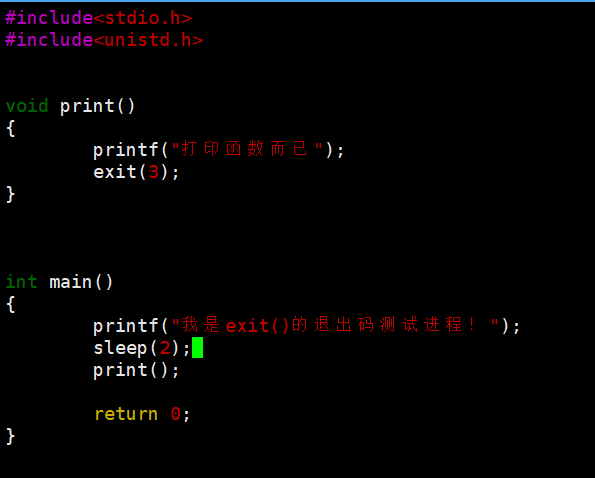
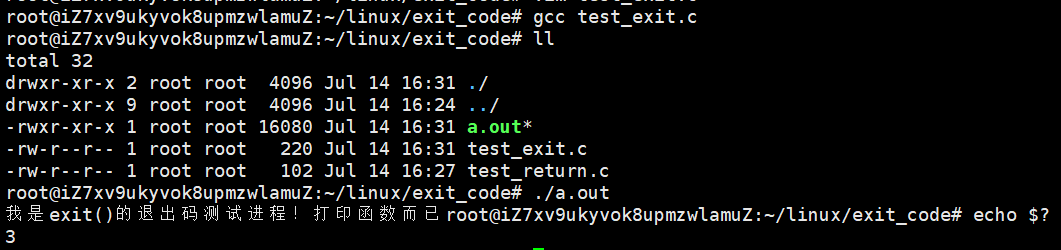
- _exit () 的测试:啥都不打印,但退出码是 3,这就说明它真没刷新缓冲区。
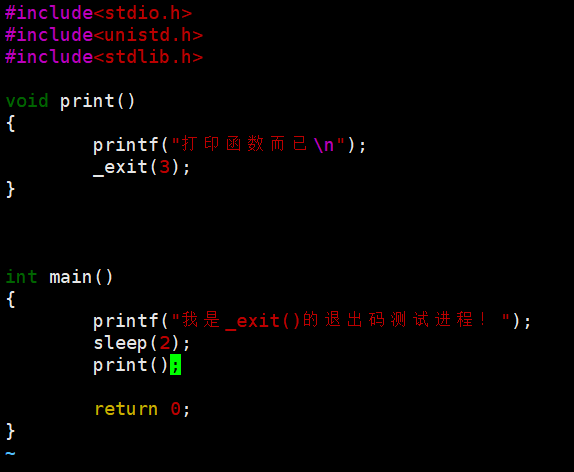

但不管是哪种方式,最终都得调用系统调用,让系统来完成真正的进程删除!毕竟库函数和系统调用是上下层关系,exit () 内部肯定封装了_exit (),不然没法实现进程终止。
那输出缓冲区到底在哪儿呢?
首先咱能肯定这是块内存空间,而且绝对不在操作系统里!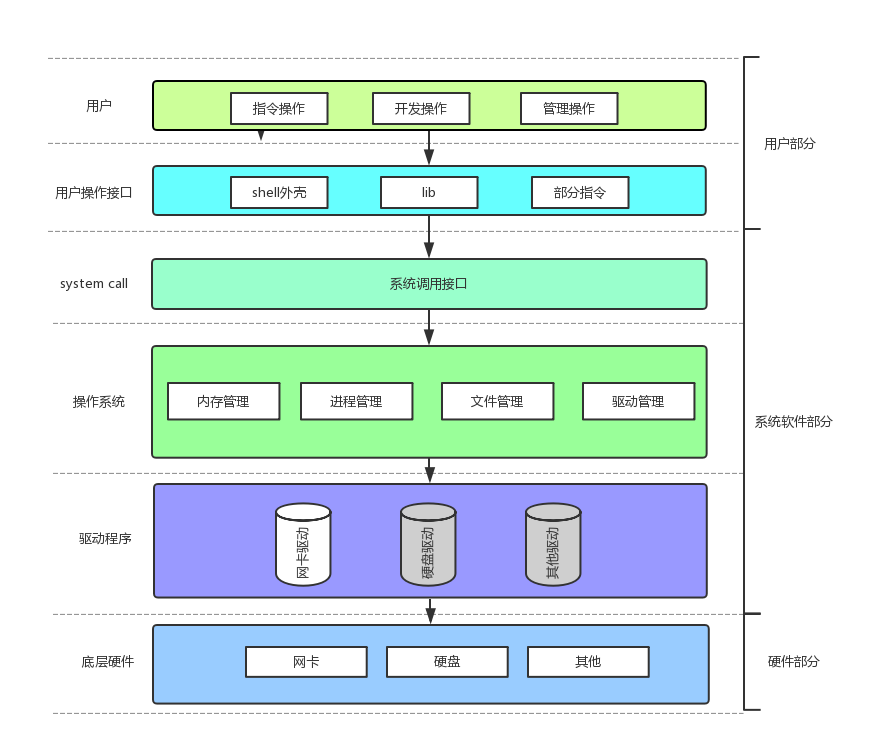
从用户接口的结构图能看出来,库(lib)属于用户操作接口,如果缓冲区在操作系统里,那 exit () 和_exit () 应该都能刷新,但事实是_exit () 没刷新。
所以啊,这缓冲区其实在咱们的库里面,真名应该叫 "库缓冲区"!
三、进程等待
为啥要搞进程等待?
还记得不?子进程要是没被父进程回收,就会变成僵尸进程 ------ 一旦变僵尸,就算用kill -9都搞不定,会造成内存泄漏。所以进程等待有两个必要原因:
- 一方面:回收子进程(必须做)
- 另一方面:获取子进程的退出信息(可选做)
啥是进程等待?就是让父进程通过等待的方式,回收处于僵尸状态的子进程,有需要的话再拿它的退出信息。
先看 wait () 函数
1. 基本原型与功能
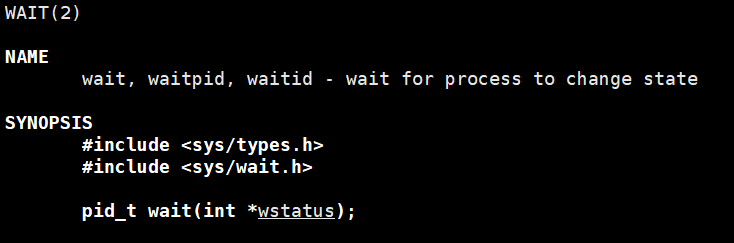

- 功能:等待任意一个子进程结束,回收它的资源,还能获取退出状态(如果 status 不是 NULL 的话)。
- 返回值:成功返回子进程 PID,失败返回 - 1(比如没有子进程)。
2. 子进程回收流程
子进程终止 → 进入僵尸状态(保留 PCB 和退出状态) → 父进程调用 wait () → 内核操作:
- 移除子进程的 PCB(回收进程表项)
- 要是 status 不为 NULL,就把状态信息复制到用户空间
- 给父进程返回子进程的 PID
3. 状态信息的编码机制
内核会把退出状态编成一个 16 位整数(存在 status 里):
- 高 8 位:存正常退出的状态码(exit () 或 return 的参数)
- 低 7 位:存导致进程终止的信号编号(如果是被信号终止的)
- 第 8 位:标志位(core dump 标志,这里先不说)
举个例子:
- 子进程执行
exit(42):status 的高 8 位是 42,低 8 位是 0 - 子进程被 SIGTERM(信号 15)终止:低 7 位是 15,高 8 位没啥意义
4. 状态解析宏(得包含 <sys/wait.h>)
| 宏函数 | 作用 | 解析逻辑 |
|---|---|---|
| WIFEXITED(status) | 判断子进程是否正常退出(返回非零就是) | (status & 0xFF) == 0 |
| WEXITSTATUS(status) | 获取正常退出的状态码(得先调用 WIFEXITED) | (status >> 8) & 0xFF |
| WIFSIGNALED(status) | 判断子进程是否被信号终止 | ((status & 0xFF) > 0) && ((status & 0xFF) < 128) |
| WTERMSIG(status) | 获取终止子进程的信号编号(得先调用 WIFSIGNALED) | status & 0x7F |
| WCOREDUMP(status) | 判断子进程是否生成 core dump 文件 | status & 0x80 |
5. wait(&status) vs wait(NULL)
| 特性 | wait(&status) | wait(NULL) |
|---|---|---|
| 获取退出状态 | 能拿到状态码和终止原因 | 啥都拿不到 |
| 子进程回收 | 能正常回收,避免僵尸进程 | 也能正常回收 |
| 典型场景 | 需要根据子进程结果做决策(比如错误处理) | 只需要确保子进程结束(比如批处理脚本) |
| 性能 | 稍微有点开销(要复制状态到用户空间) | 理论上快一点(不用复制) |
代码示例:解析不同退出场景
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
int status;
if (pid == 0) {
// 子进程:三种场景选一个测试
// exit(42); // 场景1:正常退出,状态码42
// raise(SIGTERM); // 场景2:被信号15终止
// *(int*)0 = 0; // 场景3:段错误(信号11)
} else {
wait(&status); // 获取状态
if (WIFEXITED(status)) {
printf("子进程正常退出,状态码:%d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("子进程被信号 %d 终止", WTERMSIG(status));
if (WCOREDUMP(status)) printf(",生成了core dump文件\n");
else printf("\n");
}
}
}状态编码与解析的底层逻辑
1. 编码示例(子进程 exit (42))
status 的二进制长这样:
cpp
0000 0000 0010 1010 0000 0000
└───────────┘ └───────────┘
高8位(42) 低8位(0)2. 解析示例(宏展开)
假设 status 是 0x002A00(十进制 10752):
- WIFEXITED (status) → (0x002A00 & 0xFF) == 0 → 0x00 == 0 → 真
- WEXITSTATUS(status) → (0x002A00 >> 8) & 0xFF → 0x2A & 0xFF → 42
要是子进程被 SIGTERM(15)终止,status 是 0x00000F:
- WIFSIGNALED (status) → (0x00000F & 0xFF) > 0 → 0x0F > 0 → 真
- WTERMSIG(status) → 0x00000F & 0x7F → 0x0F → 15
常见应用场景
检查命令执行结果:
cpp
if (WEXITSTATUS(status) != 0) {
fprintf(stderr, "子进程执行失败,状态码:%d\n", WEXITSTATUS(status));
}处理信号:
cpp
if (WIFSIGNALED(status) && WTERMSIG(status) == SIGSEGV) {
printf("子进程段错误!\n");
}批处理任务:
cpp
// 循环回收所有子进程并检查状态
while ((pid = wait(&status)) > 0) {
if (WIFEXITED(status) && WEXITSTATUS(status) == 0) {
printf("子进程 %d 成功完成\n", pid);
}
}关键总结
- 状态编码:内核把退出状态打包成 16 位整数,通过 status 传给用户空间。
- 解析工具:必须用宏函数解析 status,别直接按位操作(不同系统编码可能不一样)。
- 安全检查:调用 WEXITSTATUS 或 WTERMSIG 之前,必须先用 WIFEXITED 或 WIFSIGNALED 判断状态类型。
那要回收多个子进程咋办?
得循环调用 wait () 才行!多进程里,父进程往往是最先创建、最后退出的。
其实还有个更强大的函数 ------waitpid(),它不光能实现 wait () 的功能,还有额外技能,所以真要说的话,这个函数更全面!
waitpid () 函数详解
1. 函数原型与参数
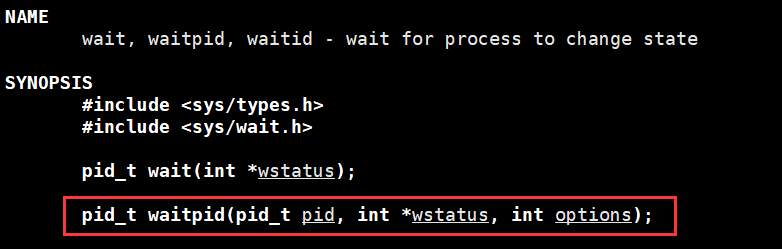
-
pid 参数:指定要等的子进程,规则如下:
-
>0(指定子进程 pid):等 PID 等于这个值的子进程
-
-1:等任意子进程(跟 wait () 一样)
-
0:等跟调用进程同组的所有子进程(fork 出来的子进程默认跟父进程同组,main 进程是组长)
-
< -1:等进程组 ID 等于这个值绝对值的所有子进程
-
-
status 指针:跟 wait () 一样,存子进程退出状态(不为 NULL 的话)
-
options 标志:
- WNOHANG:非阻塞模式,子进程没结束就立即返回 0
- WUNTRACED:跟踪被 SIGSTOP 暂停的子进程
- WCONTINUED:跟踪被 SIGCONT 恢复的子进程
2. 返回值
- 成功:
- 子进程结束了:返回子进程 PID
- WNOHANG 且子进程没结束:返回 0
- 失败:返回 - 1,还会设置 errno(比如 ECHILD 表示没有子进程)
3. 核心特性
- 精准控制:能指定等特定子进程或进程组
- 非阻塞模式:用 WNOHANG 的话,父进程不用一直堵着,能去干别的事(非阻塞轮询状态)
- 进程跟踪:能监控子进程的暂停(WUNTRACED)和恢复(WCONTINUED)
waitpid () vs wait () 对比表
| 特性 | wait() | waitpid() |
|---|---|---|
| 函数原型 | wait(&status) | waitpid(pid, &status, options) |
| 等待范围 | 任意子进程 | 可指定特定子进程或进程组 |
| 阻塞行为 | 必须等子进程结束 | 能通过 WNOHANG 设成非阻塞 |
| 进程跟踪 | 只支持已终止的子进程 | 支持暂停和恢复的子进程 |
| 回收指定子进程 | 没法选,只能按系统调度顺序 | 能通过 pid 精准回收 |
| 典型场景 | 简单顺序执行,不用并发 | 复杂多进程管理(比如并发服务器、shell) |
关键代码示例
非阻塞等待(轮询模式):
cpp
#include <sys/wait.h>
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
int status;
if (pid == 0) {
sleep(5); // 子进程睡5秒
exit(0);
} else {
while (waitpid(pid, &status, WNOHANG) == 0) {
printf("子进程还在跑,父进程可以去干别的...\n");
sleep(1); // 父进程继续干活
}
printf("子进程结束了\n");
}
}等待特定子进程组:
cpp
// 等进程组ID为1234的所有子进程
waitpid(-1234, &status, 0); // pid=-1234表示进程组ID处理多个子进程(非阻塞模式):
cpp
while (1) {
pid_t pid = waitpid(-1, &status, WNOHANG);
if (pid == 0) {
// 没子进程结束,继续干别的
continue;
} else if (pid == -1) {
// 所有子进程都回收完了,或者出错了
break;
} else {
// 处理已结束的子进程状态
if (WIFEXITED(status)) {
printf("子进程 %d 退出,状态码:%d\n", pid, WEXITSTATUS(status));
}
}
}注意事项
- 资源泄漏风险:用 WNOHANG 的时候,要是没正确循环回收所有子进程,可能会堆一堆僵尸进程
- 信号干扰:信号可能会打断 waitpid (),这时候得检查 errno 是不是 EINTR,是的话就重新调用
- 状态解析:跟 wait () 完全一样,得用宏函数解析 status
总结
- 选 wait ():简单场景,就等任意子进程结束,不用啥复杂控制
- 选 waitpid ():复杂场景,比如需要:
- 等特定子进程或进程组
- 非阻塞轮询(比如并发服务器)
- 跟踪子进程的暂停 / 恢复状态
再深入说说函数调用的详细过程
子进程的 PCB 里,有两个成员变量:int exit_code(退出码)和int exit_signal(退出信号)。
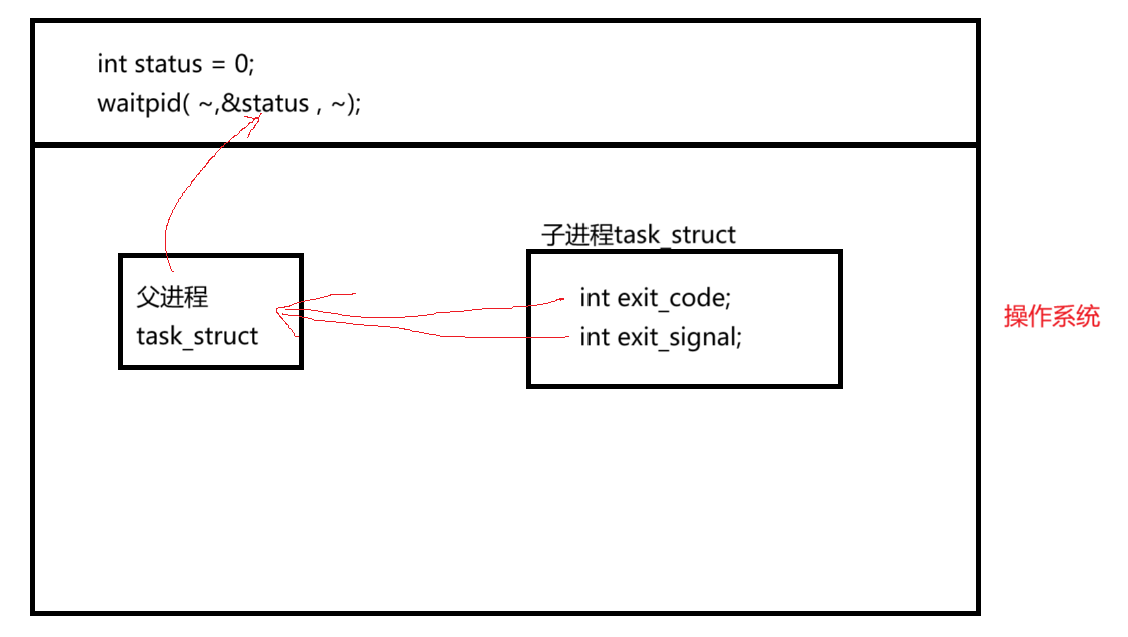
子进程退出时,会把这俩数字写到自己的 PCB 里。父进程调用 waitpid () 的时候,就会拿到这俩数字;调用完了,OS 才会释放目标 task_struct------ 这就是为啥进程结束时不能直接把 task_struct 删了。
waitpid () 不同模式的返回值:
- 第三个参数是 0:父进程阻塞着等子进程返回退出信息
- 第三个参数是 WNOHANG:非阻塞轮询等待。如果拿到了已退出子进程的状态,返回子进程 PID;拿到未退出的,返回 0;函数自己失败了,返回 - 1。
要是代码里只等一次,比如这样:
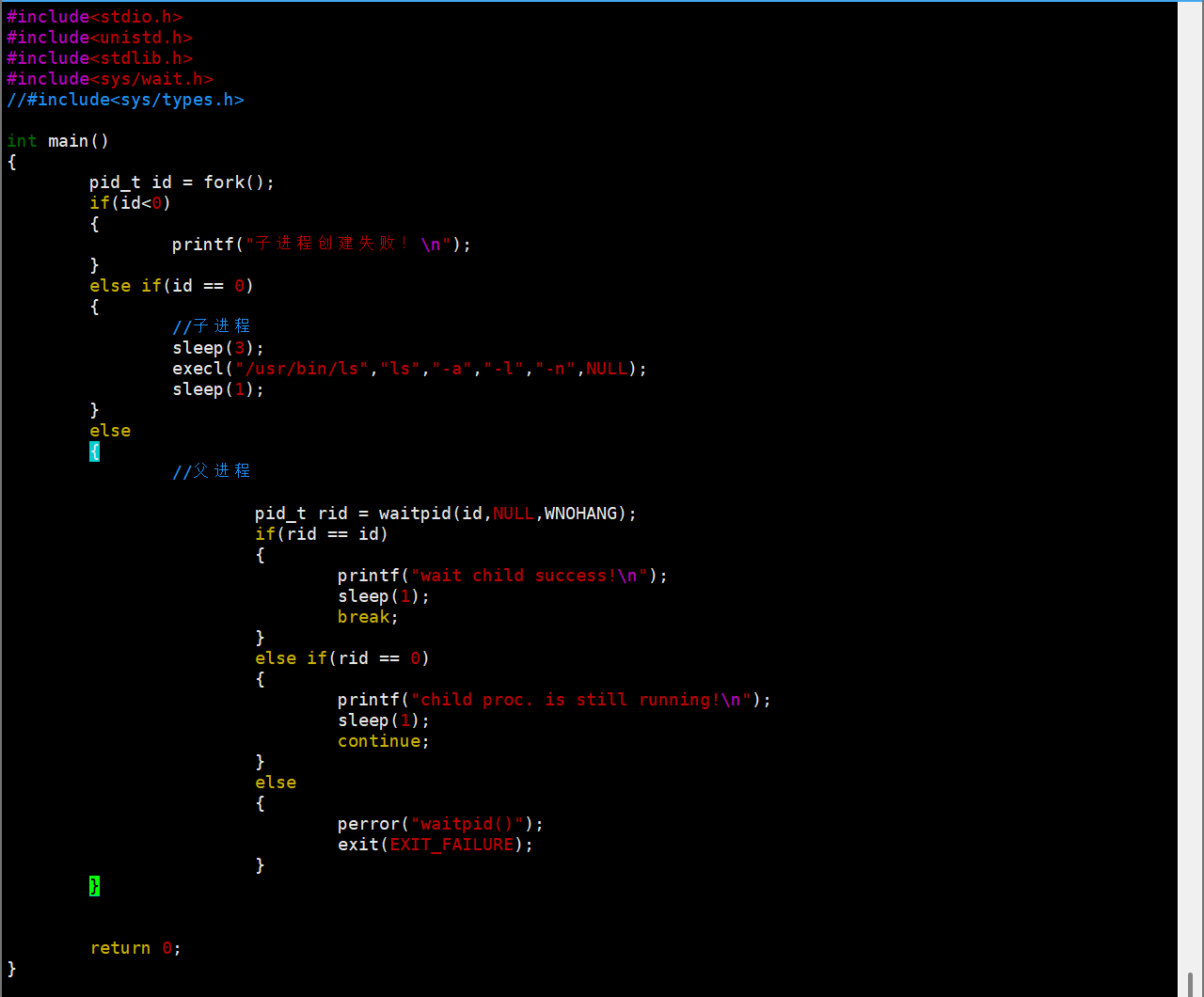
就会发现父进程问了一次就走了,子进程变成孤儿进程,被 init 程序领养了。所以要实现轮询,得程序员自己加循环!
补充个小知识
- *.cc 是 C++ 代码文件格式
- *.hpp 是头文件,允许把类、函数的声明和实现写在一起,能直接用 include 包含
用代码模拟非阻塞等待的场景
非阻塞等待的时候,父进程在等的同时能去执行其他任务,这样系统效率更高。咋模拟呢?
先定义个工具箱(Tool.hpp):里面放方法集的定义,比如新方法的写入、执行方式。
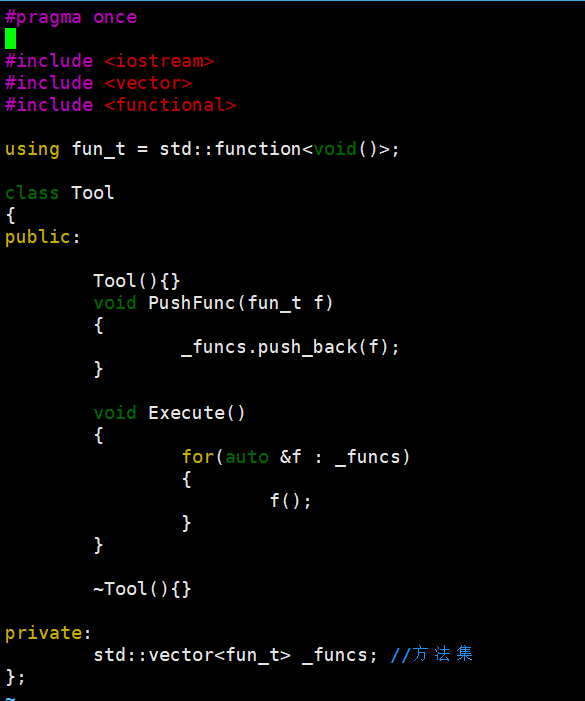
再定义个工具执行器(Task.hpp):这个头文件里写各个方法的具体实现。
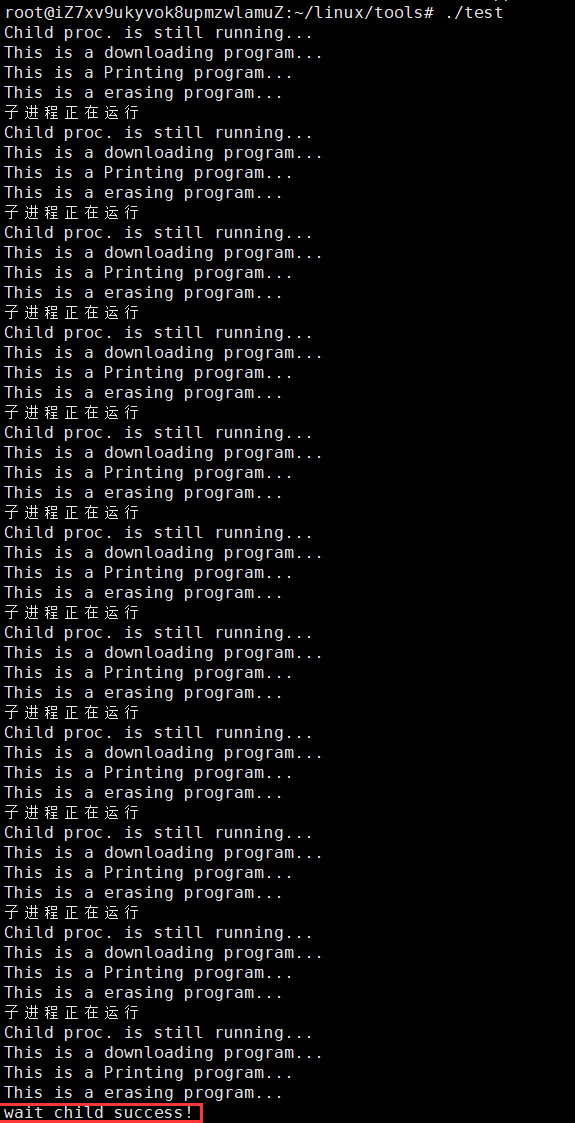
然后把这俩加到之前的轮询代码里 ------ 运行之后就能看到,父进程最终成功回收了子进程。
四、进程程序替换
咱们之前说,fork 之后子进程执行的是父进程的一部分代码。那要是想让子进程执行一段全新的程序咋办?这就得用到 "进程程序替换" 了。
1. 程序替换原理
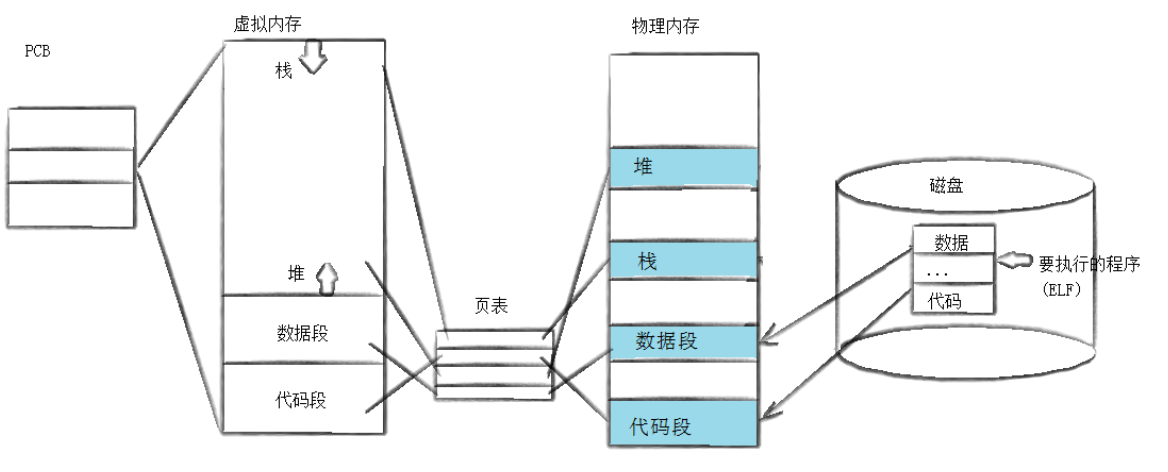
说白了就是把物理内存里的代码和数据,换成磁盘里新程序的 ------ 注意,这期间不会创建新进程(PID 不变),只是代码和数据换了,页表映射可能会因为代码 / 数据大小变化而调整。
而且子进程替换代码的时候,会触发类似写时拷贝的操作:系统给子进程新开辟代码段和数据段,把新程序的代码和数据导进去。这样才能保证父子进程相互独立,毕竟进程间独立性是很重要的性质!
说到这你肯定能联想到:咱们用 shell 的时候,其实一直在做进程替换!每次在命令行输个命令,shell 就 fork 一个子进程,子进程通过 exec 系列函数执行命令;父进程(bash)就用 waitpid 等子进程完事,回收它的退出信息 ------ 这就是为啥echo $?能拿到上一条命令的退出码。
2. 进程切换接口(exec 系列函数)
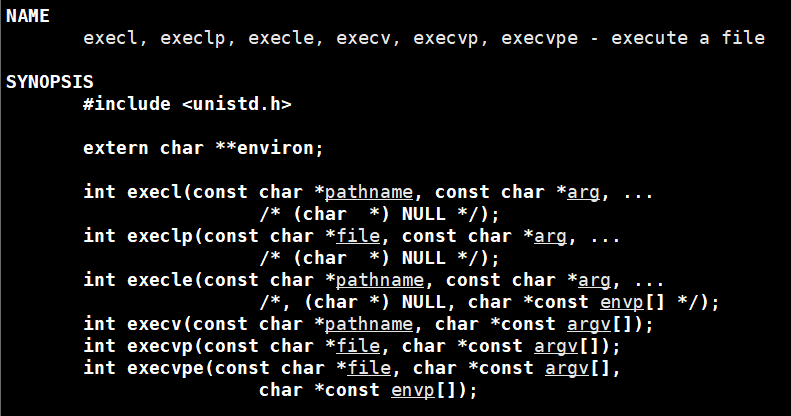
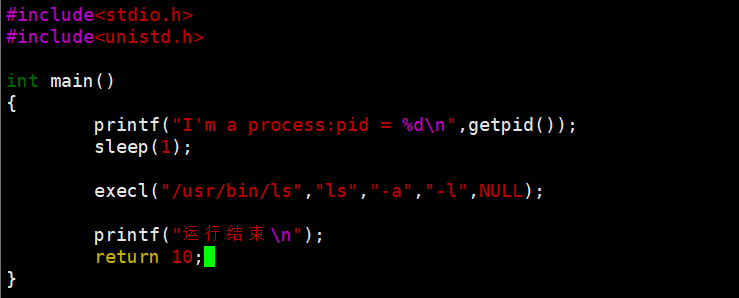
2.1 execl()

- 特点:第一个参数是程序路径,后面跟命令参数,最后得用 NULL 结尾
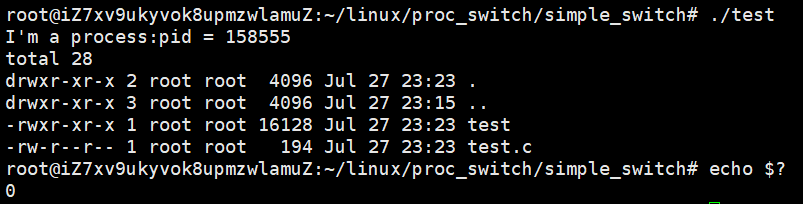
- 示例:
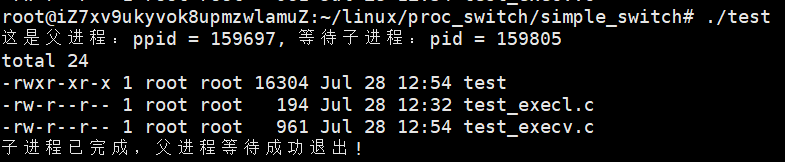
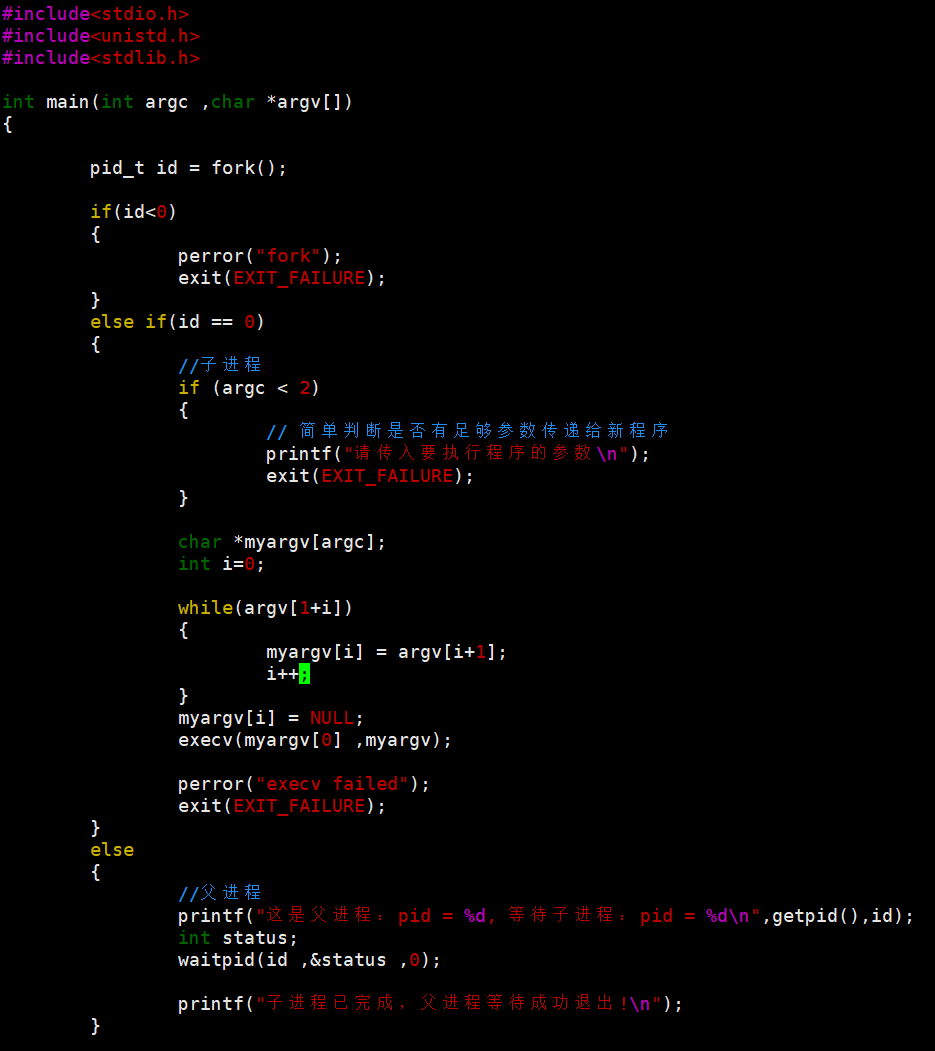
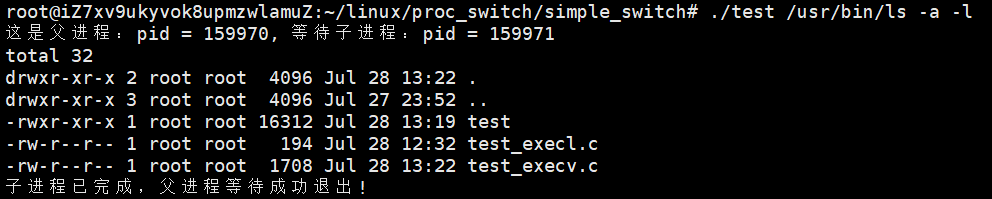
2.2 execv()

- 特点:第一个参数是程序路径,第二个参数是参数数组(得用 NULL 结尾)
- 示例:
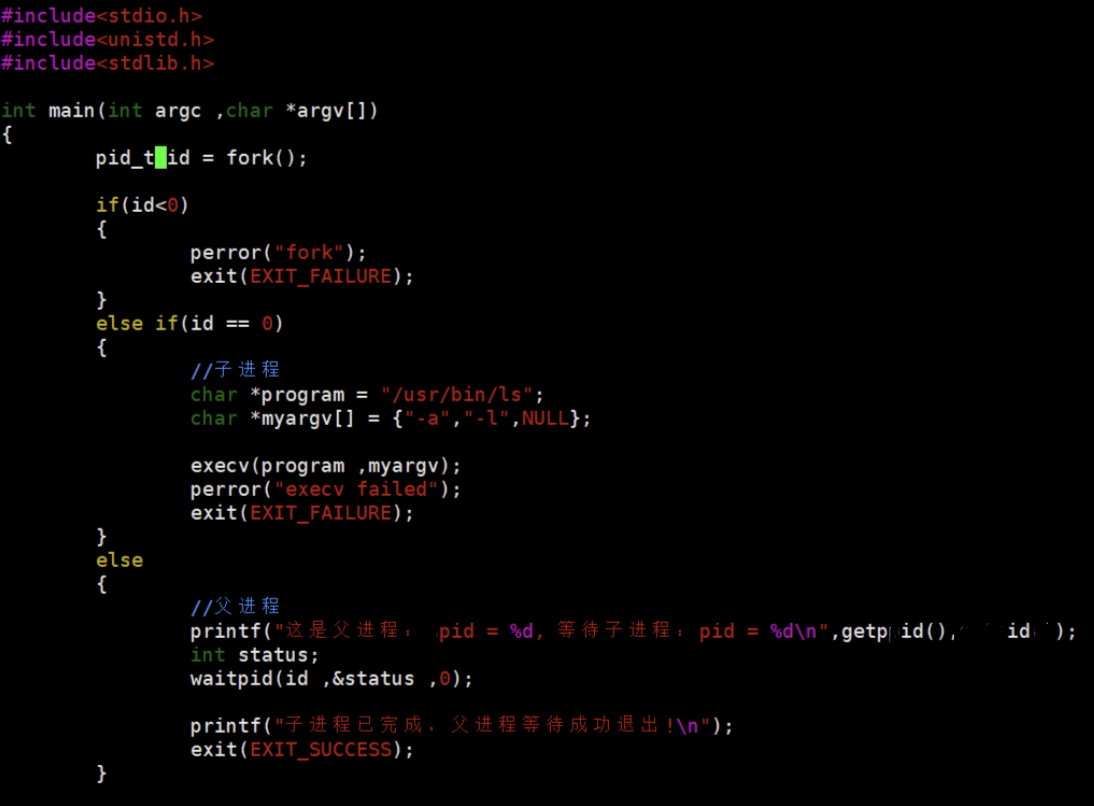
还记得 main 函数的参数不?咱们可以借助它们,在命令行里完成进程转换。
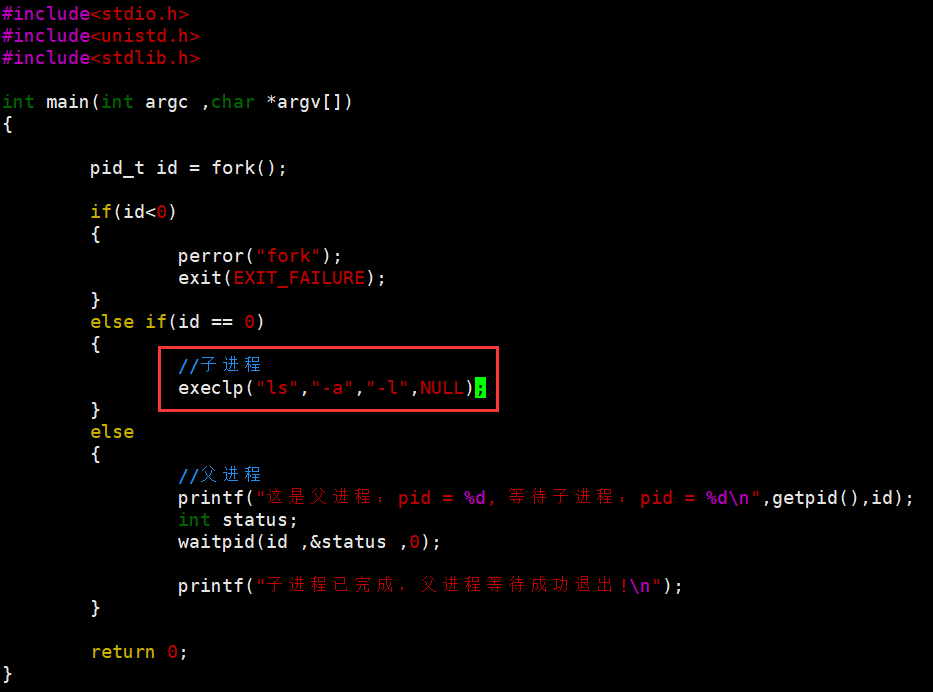
2.3 execlp()

- 特点:更方便,第一个参数直接写命令名,它会自己去环境变量 PATH 里找程序路径;第二个参数还是命令选项,用 NULL 结尾
- 示例:
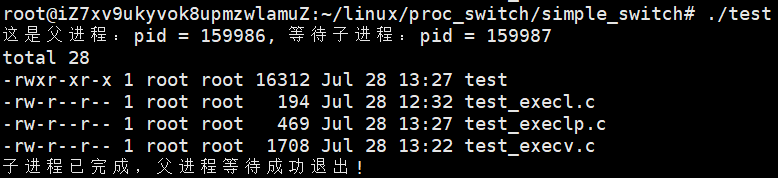
2.4 execvp()

- 特点:结合了 execv 和 execlp 的优点,第一个参数是命令名(会去 PATH 里找),第二个参数是参数数组
- 示例:
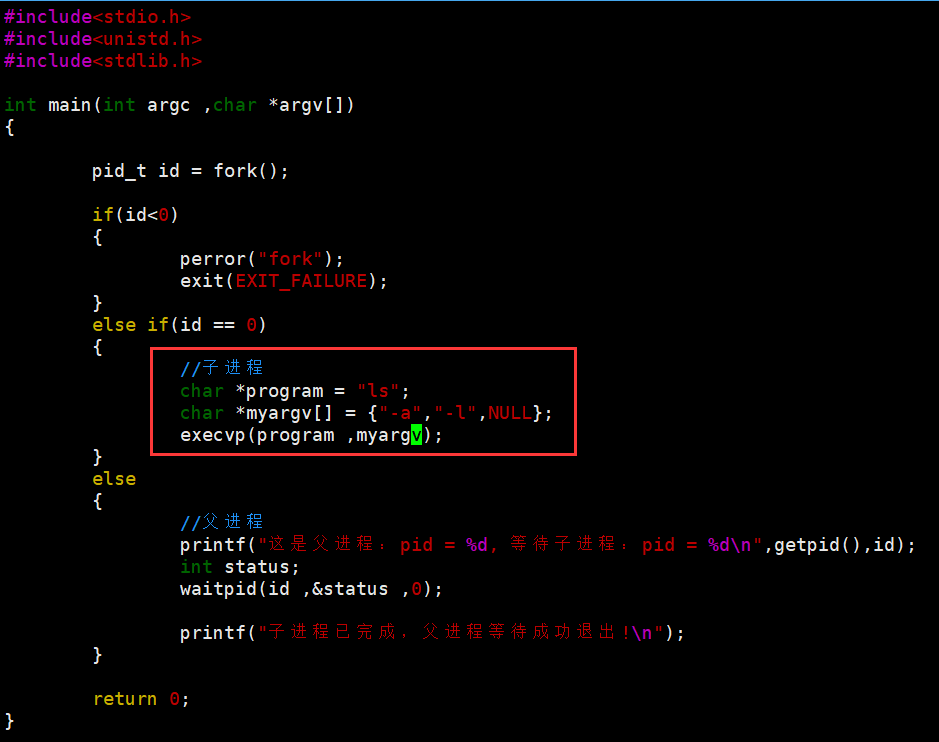
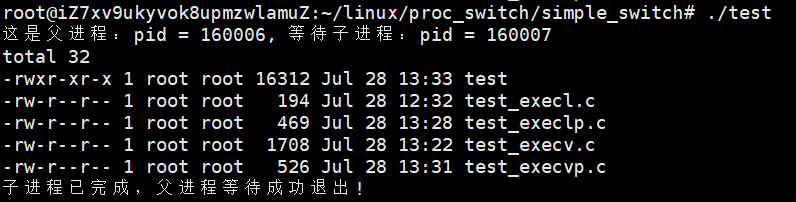
用这些函数,子进程既能执行系统命令,也能执行咱们自己写的程序 ------ 只要保证能正确找到可执行文件的路径和名称就行。
甚至还能在.c 文件里执行其他语言的代码!比如:
- 创建 mypy.py,写点 Python 代码
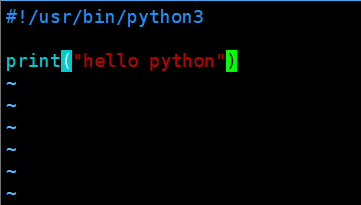
- 用 python 解释器执行这个脚本

- 在.c 文件里这么写:
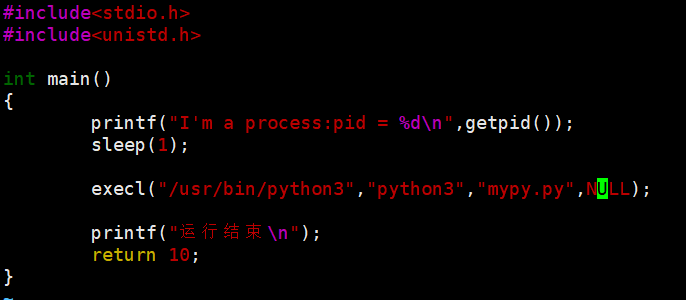
这样就能在 C 文件里跑 Python 代码了!

2.5 execvpe()

这个函数跟 execvp 唯一的区别是:最后要加个环境变量表。默认传用户自己定义的,也能直接传系统的 env。
要是想传改过后的系统环境变量表,还得用putenv()函数。
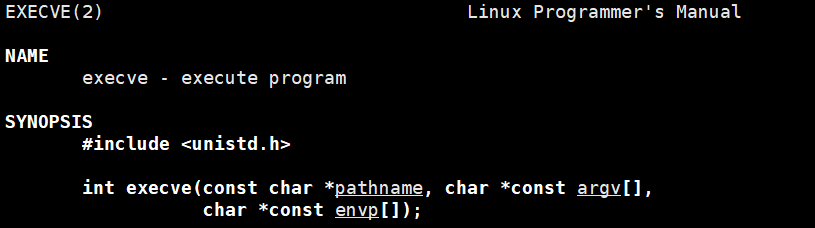
其实上面说的这些都是库函数,系统调用里有个execve------ 所有 exec 系列库函数里都封装了它。
最后一个问题:有时候没给 main 函数传对应的参数,为啥还能拿到需要的信息?
因为这些信息在你的地址空间里,就像全局变量一样,就算不通过参数传,子进程照样能拿到!
那么以上就是本次学习分享的所有内容了~
非常感谢你能够看到这里!
如果感觉本文对你有帮助的话还请给个三连 这将会给我莫大的鼓舞!
后续我依旧会继续更新Linux的学习分享~
就让我们 下次再见!