难懂的来了:

第一个式子误差太大,所以用很多的sigmod函数叠加来逼近原始数据的折线就得到第二个式子;第二个式子只是考虑了前一天的数值,但是多考虑前几天的数的话,效果会更好,所以我们将第三个式子引入到第二个式子中,这个时候第四个式子就出现了。
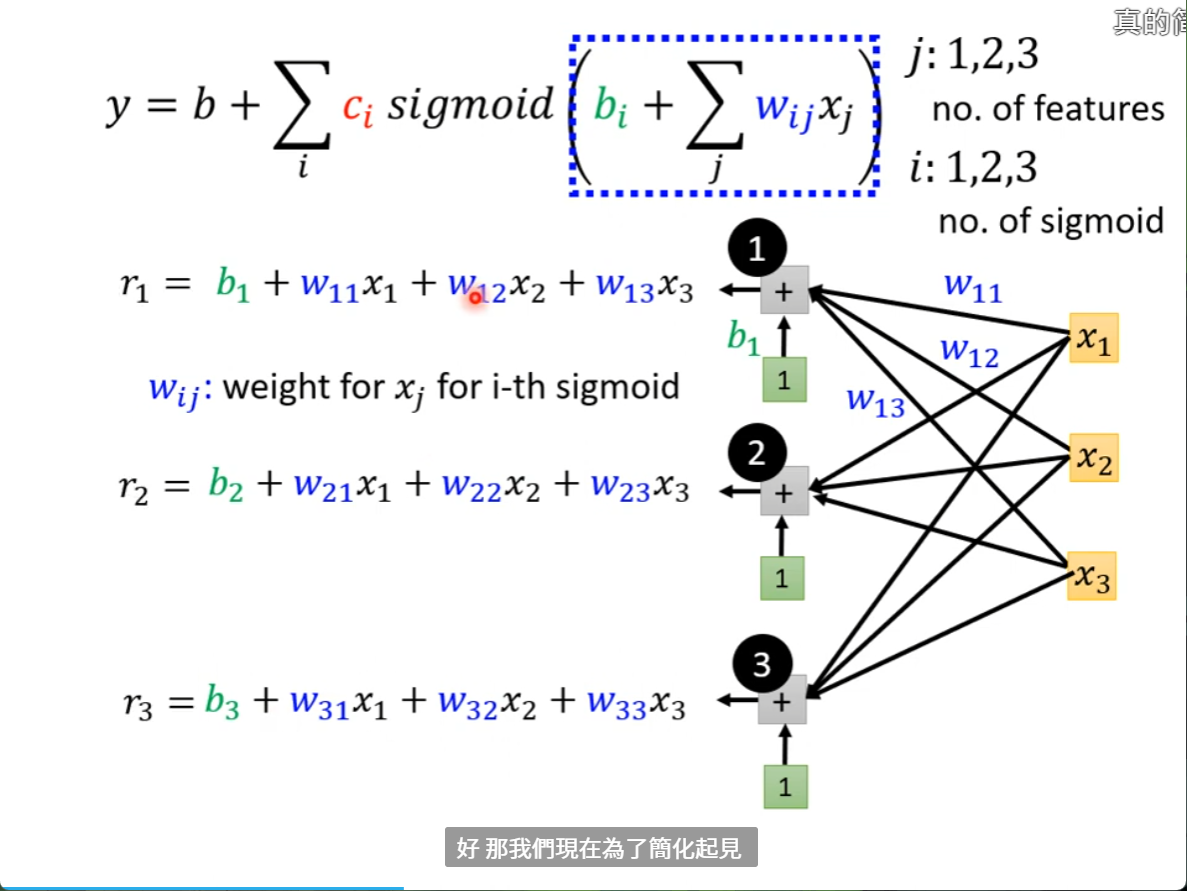
r1, r2, r3的意思是将前三天的浏览量都和一个weight乘再加上一个bias后得出的东西,这个和前一节课讲的一样,可以降低10%的loss左右,就得到r1,r2,r3,如果没有用前三天的数据,只用了前一天的数据,那么这里的 r 也就是 bi+wix1
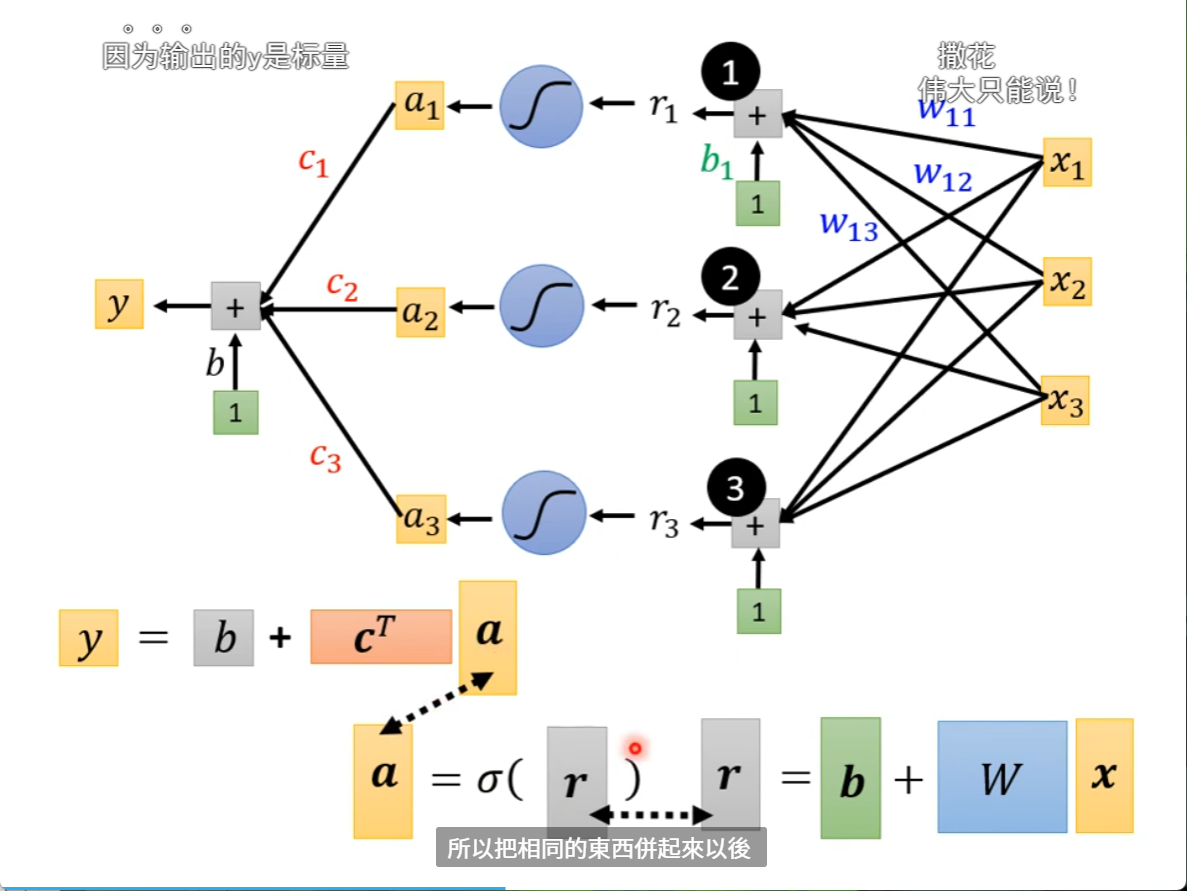
我们再将这个公式简化为矩阵的形式

我们再将r1,r2,r3通过sigmod 就得到了y 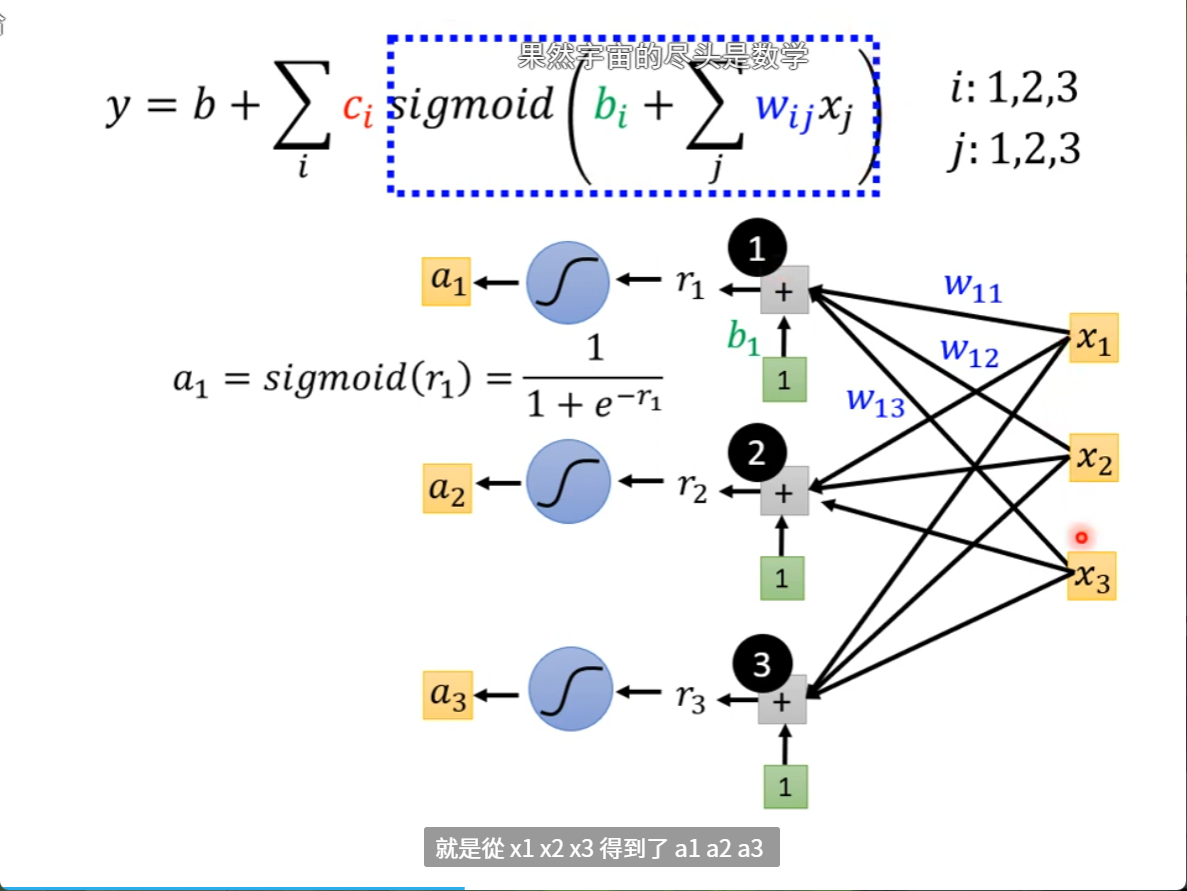
把东西连起来以后就是下面的这个式子
回到机器学习的三个步骤
我们现在改写了第一步,将一个简单的一元一次方程变成了现在这个由多个sigmod函数拼出来的函数而成
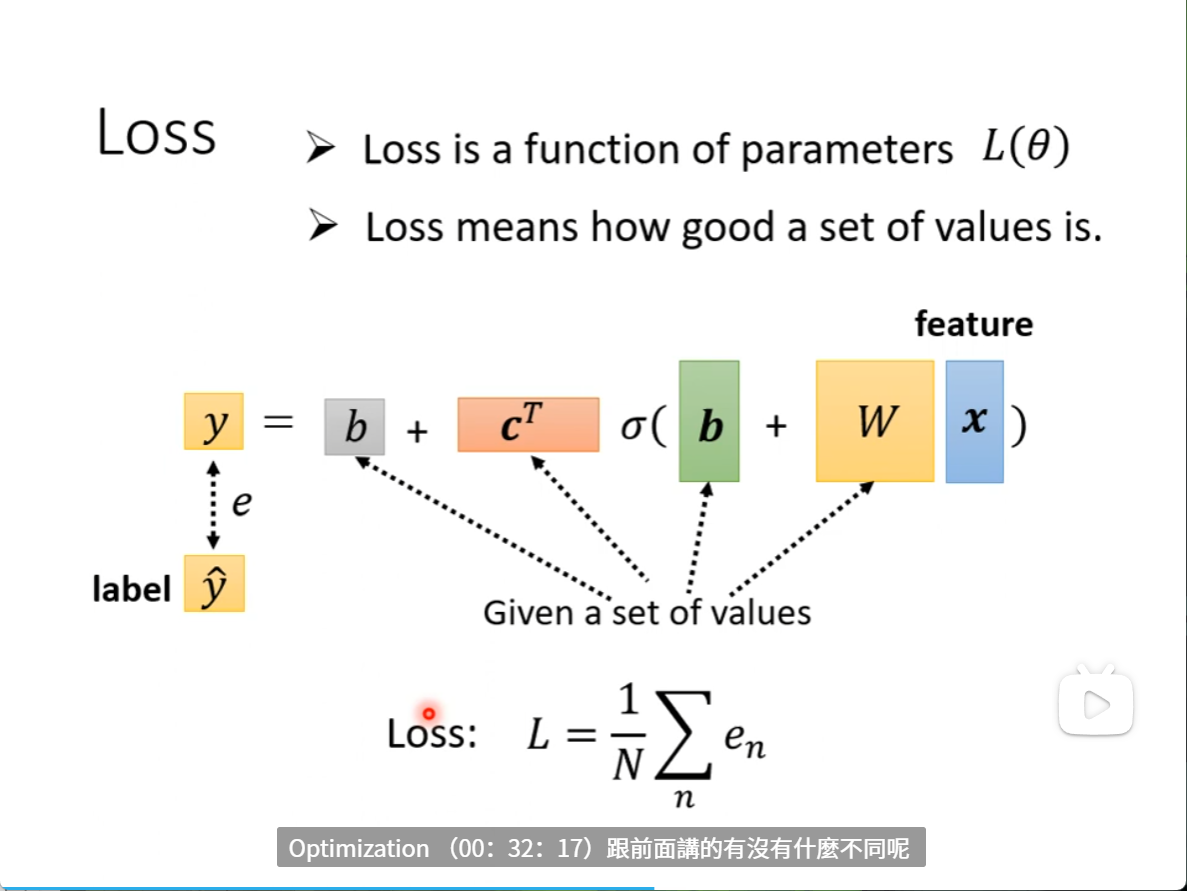
来到第二步,我们要定Loss
和之前都是一样的,将这些参数给定一个初始值,写进去,然后把一组feature带进去,估算一下是多少,再看和真实值差多少,差值平均就是Loss
optimization也和之前一样,没有什么不同,就算我们换了一个模型,演算法还是梯度下降
步骤是初始一个值 ,再对每一个未知数计算微分,把微分集合起来以后作为一个向量g,
倒三角形的意思是所有的参数对L做微分,

更新参数和之前的更新是一样的。
我们从所有N拿出来算loss 换成一个batch1拿出来算loss ,叫L1
再算出gradient,拿这个gradient更新参数
再拿另一个batch2,算出来loss,叫L2
再算出gradient,拿这个gradient更新参数
所有的batch更新完了,就叫一个epoch
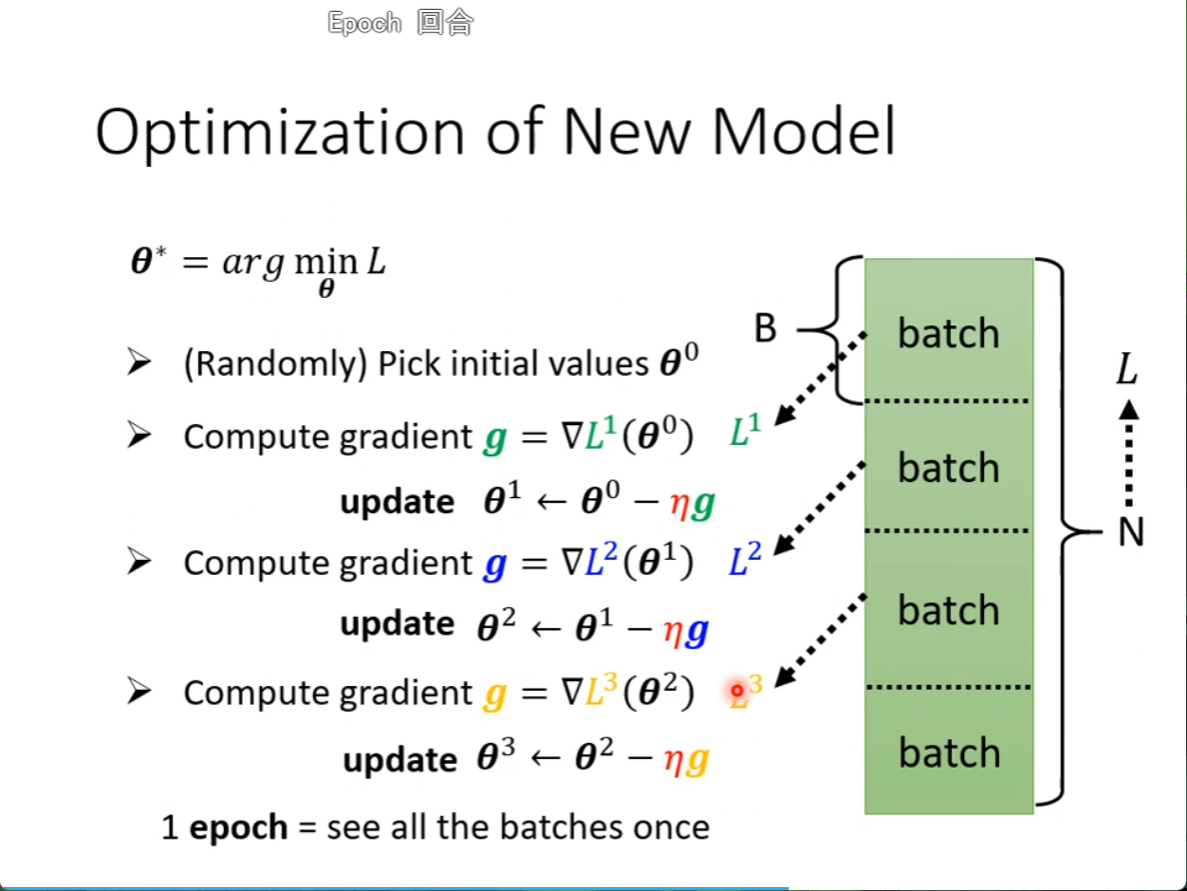
为什么要分一个一个batch,我们下周才学
超参数就是自己设置的东西,Learning rate,sigmod ,batch 都是超参数
我做了一个epoch训练不知道更新了几次参数,要看batch size有多大
不止有sigmod函数,还有一个叫ReLU这个东西,其实也就是pytorch里面的非线性激活就是这么来的
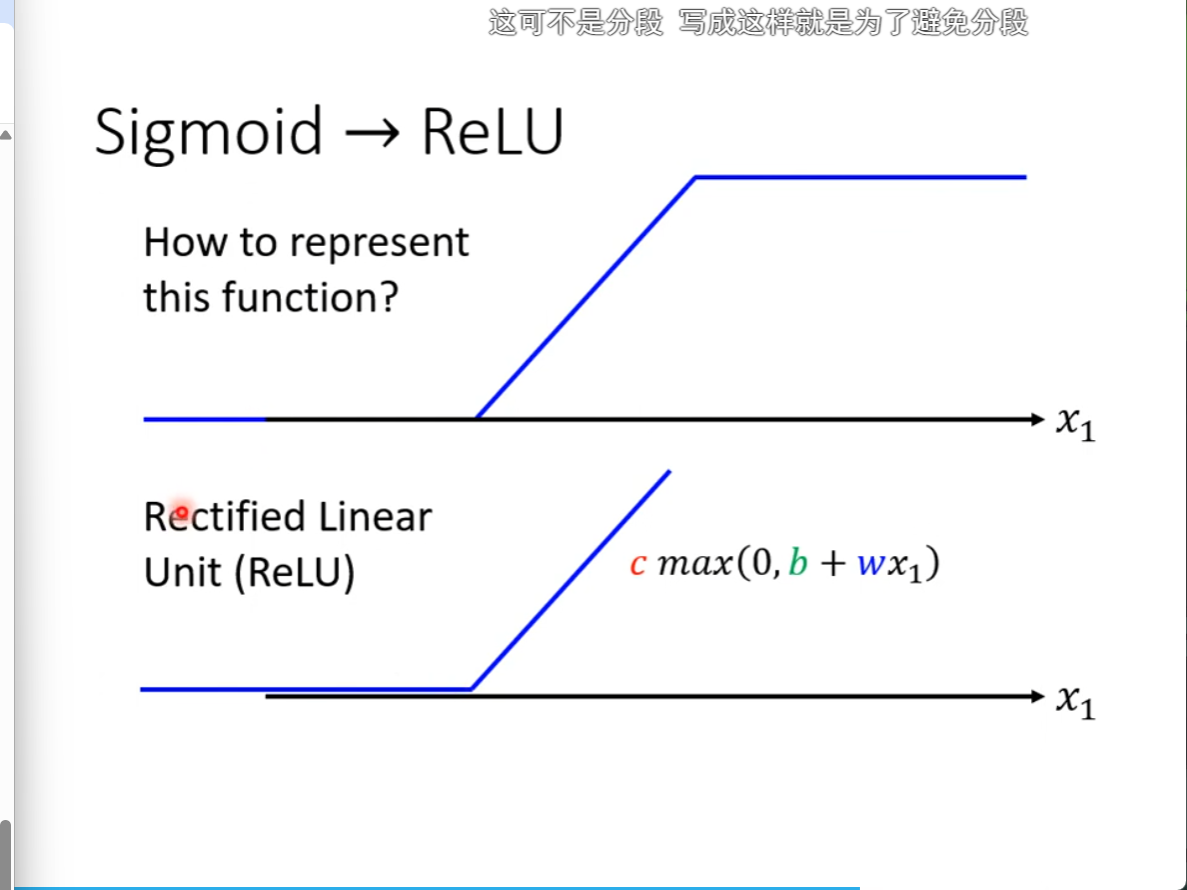
把下面的ReLU加起来,就是上面的sigmod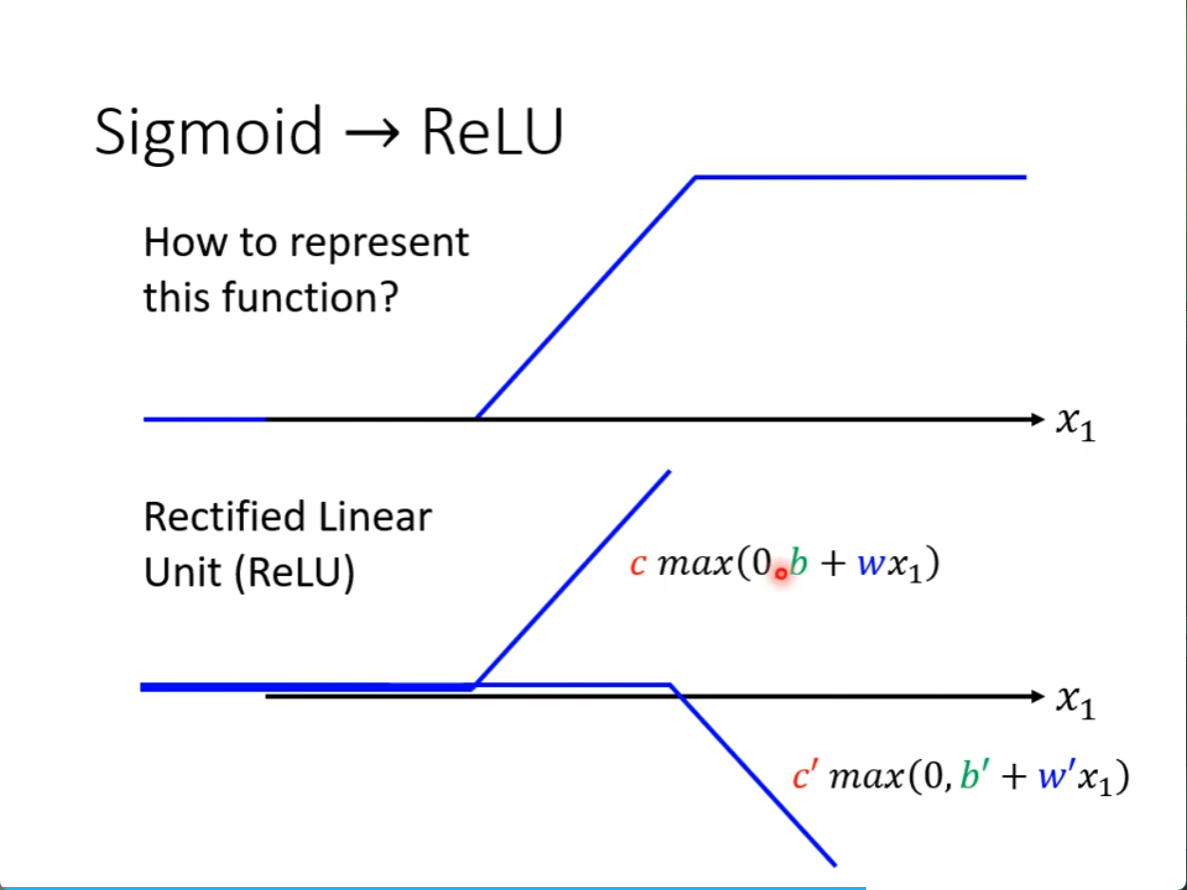
不想用sigmod,想用ReLU的话,也可以,但是两个ReLU才可以变成一个sigmod,所以求和下面就是两倍,他们都叫做 Activation function(激活函数)
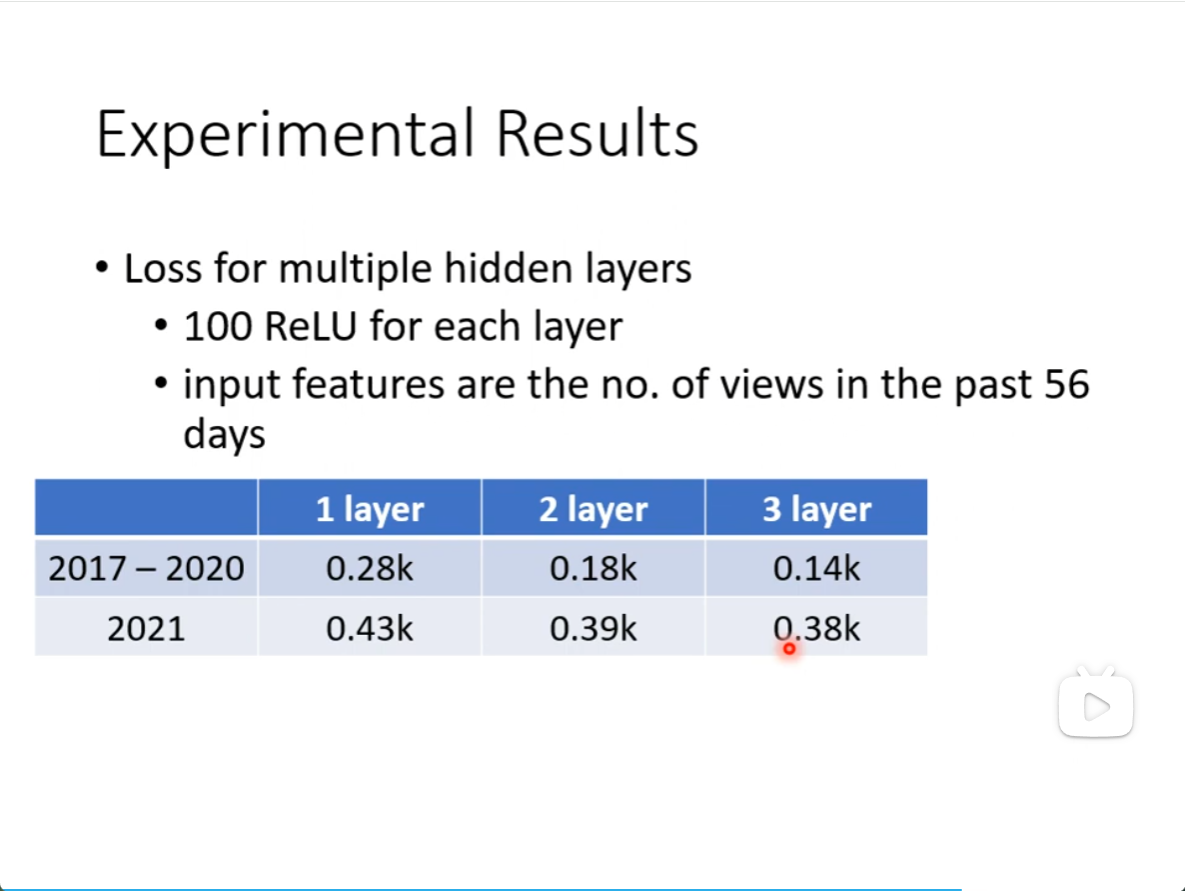
真实的资料上,100个ReLU有显著差别

接下来我们可以继续改我们的模型
我么可以经过一连串的变换产生a,再将a再做一连串的变换产生a撇,多做几次
要做几次?这又是一个超参数,第二轮的参数也第一轮的参数也不一样。
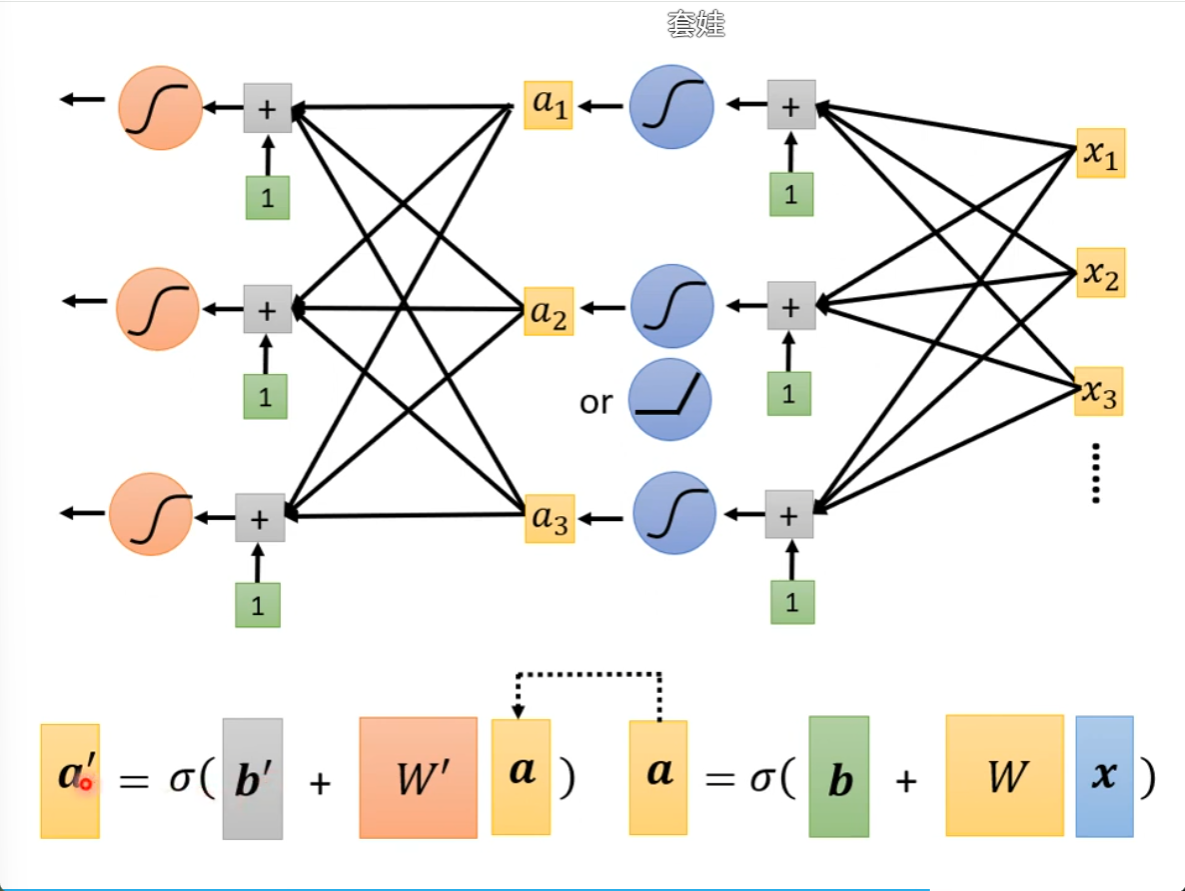
再加几层,多做几次ReLU,看起来是有进步的
这就是神经网络,就是deep learning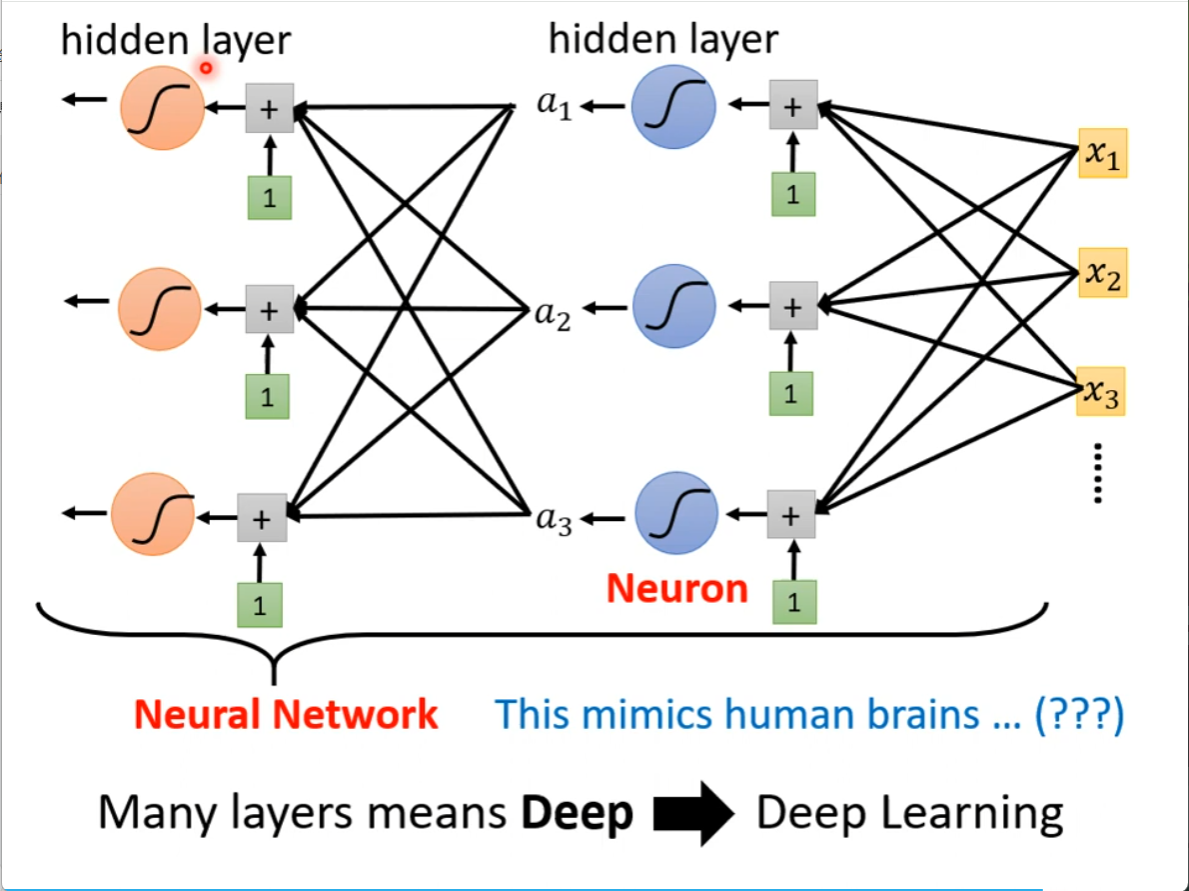
有很多层
为什么要有那么多层而不把这些都集中在一层呢?这个问题后面会讲
现在开始讲 Overfitting 过拟合
什么是over fitting 就是在看过的资料上表现更好,在没看过的资料是表现更差

用训练出来的预测新的东西,用三层的还是四层的,当然用三层的,用没有看过的资料上训练的最好的