点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到: Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成的内容:
- Kafka核心概念介绍
- Producer
- Consumer
- Topic
- Partition
- 等等

简单介绍
Kafka在3版本以下都是需要ZooKeeper来做协调器的,在3版本以上,Kafka实现了自己的协议去做高可用,但是大家也没有都切换到这个新的方案上,还是比较保守的(如果在生产环境上 )。
Kafka 2.X 深度解析
Kafka 2.X 是 Apache Kafka 的一个重要版本系列,包含了从 2.0.0 到 2.8.0 等多个子版本。这一系列版本为 Kafka 引入了许多革命性的新特性和改进,使 Kafka 在大规模数据处理、实时流处理和企业级应用方面更加强大和可靠。
Core 新特性详解
Kafka Streams 全面升级
Kafka 2.X 对 Kafka Streams 进行了重大增强,使其成为更强大的流处理框架:
- KStream-KTable 外连接:支持左外连接(LEFT JOIN)和全外连接(FULL OUTER JOIN),例如可以轻松实现用户行为事件流与用户资料表的关联分析
- 全局表(Global Tables):允许将参考数据完整复制到所有应用实例,特别适合维表关联场景
- 交互式查询(Interactive Queries):可直接从本地状态存储查询实时处理结果,无需额外数据库
- 改进的Exactly-Once语义:提供了更可靠的端到端精确一次处理保证
性能优化突破
- Broker性能提升 :
- 日志管理系统重构,写入吞吐量提升30%
- 改进的内存管理,减少GC停顿时间
- 零拷贝优化,网络吞吐提升20%
- Producer增强 :
- 批量发送大小自动调节
- 更智能的压缩算法选择
- 减少元数据请求频率
动态配置革命
- 实时配置更新 :
- Broker参数:如
log.retention.ms、max.connections等 - Topic配置:如
retention.ms、max.message.bytes - 客户端配额:可动态调整生产/消费速率限制
- Broker参数:如
- 配置方式:
- 通过Kafka AdminClient API
- 使用kafka-configs.sh命令行工具
- 示例:
bin/kafka-configs.sh --alter --entity-type topics --entity-name test --add-config retention.ms=86400000
Kafka Connect 企业级增强
REST API 全面升级
- 新增端点:
/connectors/{name}/status获取连接器详细状态/connectors/{name}/config/validate配置验证/connector-plugins/{name}/config/validate插件配置验证
- 改进的监控指标:
- 任务级吞吐量统计
- 详细的错误计数和分类
跨数据中心复制优化
-
增量镜像任务(MirrorMaker 2.0) :
- 基于消费位移的增量复制
- 自动topic创建和配置同步
- 支持双向复制场景下的防循环
-
典型配置示例:
propertiesclusters=primary,secondary primary.bootstrap.servers=broker1:9092 secondary.bootstrap.servers=broker2:9092 primary->secondary.enabled=true primary->secondary.topics=.*
企业级安全增强
Kerberos 深度集成
- 多域支持:
- 单个集群支持多个Kerberos域
- 跨域信任配置简化
- 组件级认证:
- Broker间通信SASL/GSSAPI
- 客户端认证可单独配置
- ZooKeeper连接安全加固
ACL 精细化控制
-
新增权限类型:
- DESCRIBE_CONFIGS:查看配置
- ALTER_CONFIGS:修改配置
- IDEMPOTENT_WRITE:幂等生产
-
权限管理示例:
bash# 授予用户Alice对test-topic的管理权限 bin/kafka-acls.sh --add --allow-principal User:Alice \ --operation ALL --topic test-topic
智能日志管理
基于时间的日志保留策略
-
新增功能:
- 支持按小时/天/周保留日志
- 可配置多个时间段的保留策略
- 与大小限制策略协同工作
-
配置示例:
propertieslog.retention.hours=168 # 保留7天 log.segment.bytes=1073741824 # 1GB/段 log.cleanup.policy=delete,compact # 混合策略 -
运维优势:
- 更可预测的磁盘使用
- 简化容量规划
- 符合数据保留法规要求
Kafka 2.X 系列通过这些重大改进,使Kafka在企业关键业务场景中的适用性大幅提升,为后续3.0版本的创新奠定了坚实基础。
Kafka 3.X 深度解析
Kafka 3.X 是 Apache Kafka 发展历程中的一个重要里程碑版本系列,代表了分布式消息系统的重大演进。随着 Kafka 进入 3.X 时代,系统在稳定性、性能和功能特性方面都实现了显著提升,同时引入了一些革命性的架构变革。
KRaft (Kafka Raft) 元数据管理
KRaft 模式详解
Kafka 3.X 首次正式引入了 KRaft(Kafka Raft)模式,这是一项革命性的控制平面架构创新。KRaft 使用 Raft 共识算法来管理集群元数据,完全取代了原先依赖 ZooKeeper 的设计。在实际部署中,KRaft 模式通过以下方式工作:
- 集群元数据(如主题配置、分区分配等)通过 Raft 协议进行复制
- 选举机制确保集群控制器的自动故障转移
- 元数据存储在 Kafka 内部,不再需要外部依赖
Zookeeper 逐步废弃路线图
Kafka 3.X 版本标志着从 Zookeeper 依赖到 KRaft 模式的过渡期:
- 3.0.x 版本:引入 KRaft 作为实验性功能
- 3.3.x 版本:KRaft 进入生产就绪状态
- 3.5.x 版本:ZooKeeper 模式被标记为"已弃用"
- 预计 4.0 版本:完全移除 ZooKeeper 支持
性能与可扩展性增强
延迟优化实现
Kafka 3.X 引入了多项底层优化来提升性能:
- 批量处理改进:优化了消息批处理机制,减少网络往返
- 零拷贝增强:改进了数据传输路径,降低 CPU 开销
- 日志压缩优化:减少了压缩操作对生产性能的影响
分区管理革新
- 分区数量上限提升:单个集群支持的分区数从 20 万提升到 200 万
- 智能分区再平衡:引入优化算法减少分区迁移时的资源消耗
- 动态分区分配:支持运行时分区再分配而不需要重启 Broker
流式处理能力升级
Kafka Streams 2.0
Kafka 3.X 配套的 Streams API 带来重大改进:
- 新增
flatTransform操作符支持复杂事件处理 - 优化的时间窗口计算,减少状态存储开销
- 改进的交互式查询性能,查询延迟降低 40%
大规模流处理支持
- 状态存储引擎重构,支持 TB 级状态数据
- 改进的任务调度算法,提升资源利用率
- 增强的容错机制,故障恢复时间缩短 50%
兼容性与升级策略
向后兼容性保障
Kafka 3.X 保持以下兼容性:
- 协议兼容:支持 2.8+ 版本的所有客户端协议
- API 兼容:所有公共 API 保持向后兼容
- 配置兼容:核心配置项保持相同语义
滚动升级最佳实践
推荐的升级步骤:
- 先升级所有 Broker 到 3.X 版本
- 然后逐步升级 Connect 集群
- 最后更新客户端库版本
- 建议在非高峰期执行,监控关键指标
Kafka Connect 增强
错误处理机制改进
- 死信队列增强:支持消息级错误处理策略
- 自动重试策略:可配置的指数退避重试机制
- 错误隔离:单个任务失败不会影响其他任务
监控与管理提升
- 新增 30+ 监控指标,包括:
- 任务级延迟指标
- 连接器状态变化历史
- 资源使用详情
- 增强的 REST API 支持:
- 批量操作接口
- 配置验证端点
- 连接器健康检查
这些改进使得 Kafka 3.X 成为构建现代化数据流平台的首选,特别适合需要高吞吐、低延迟和强一致性的场景。
ZooKeeper
环境变量
shell
# 我们要确保有ZooKeeper环境,之前已经安装过了。最好确认一下你的ZooKeeper环境是正确的。
vim /etc/profile检查你的环境变量是否配置完毕,我这里是 3台云服务器都配置好了。
shell
# zookeeper
export ZOOKEEPER_HOME=/opt/servers/apache-zookeeper-3.8.4-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin配置的结果大致如下: 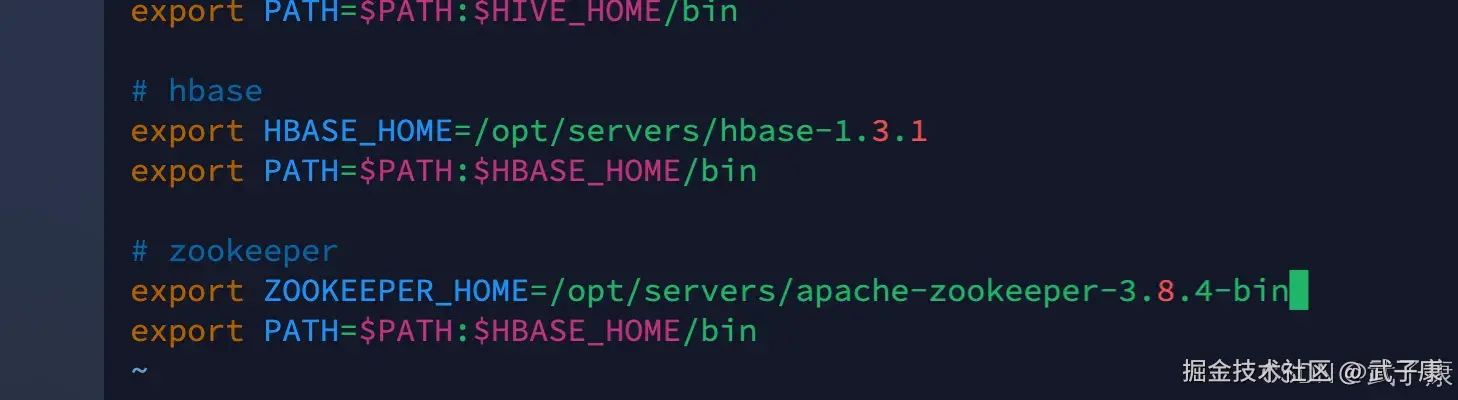 记得刷新环境变量
记得刷新环境变量
shell
source /etc/profile验证环境
如果你已经启动了ZooKeeper,那么进行下面的服务测试:
shell
zkServer.sh status如果你出现下图的样子,你的ZK是没有问题的。 可以从下图中看到,我这台是 Follower 节点。主节点好像是 h122 节点。 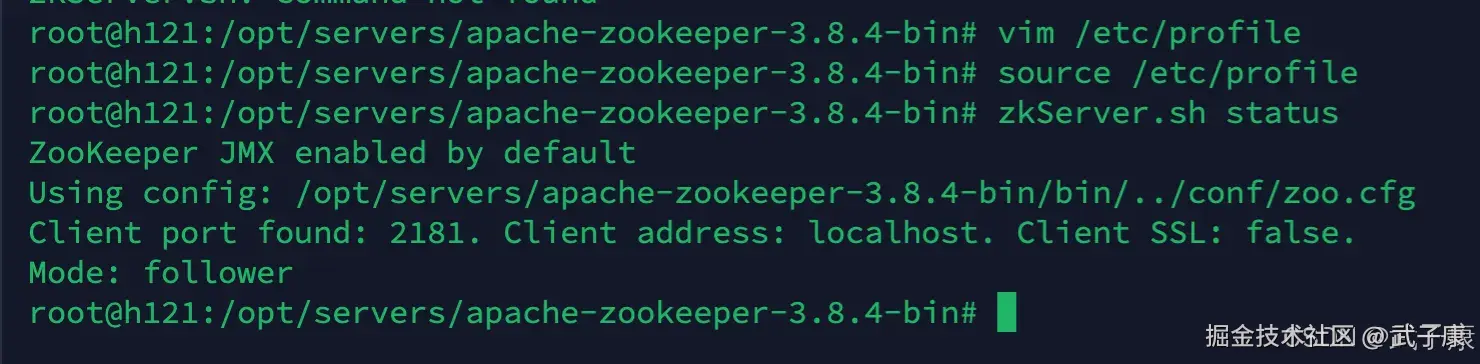
Kafka
下载项目
我这里选择的是 2.7 的版本,你可以到 GitHub 或者 官方下载
shell
https://github.com/apache/kafka/releases/tag/2.7.2
https://kafka.apache.org/downloadsGitHub是源码,需要自己编译!!! 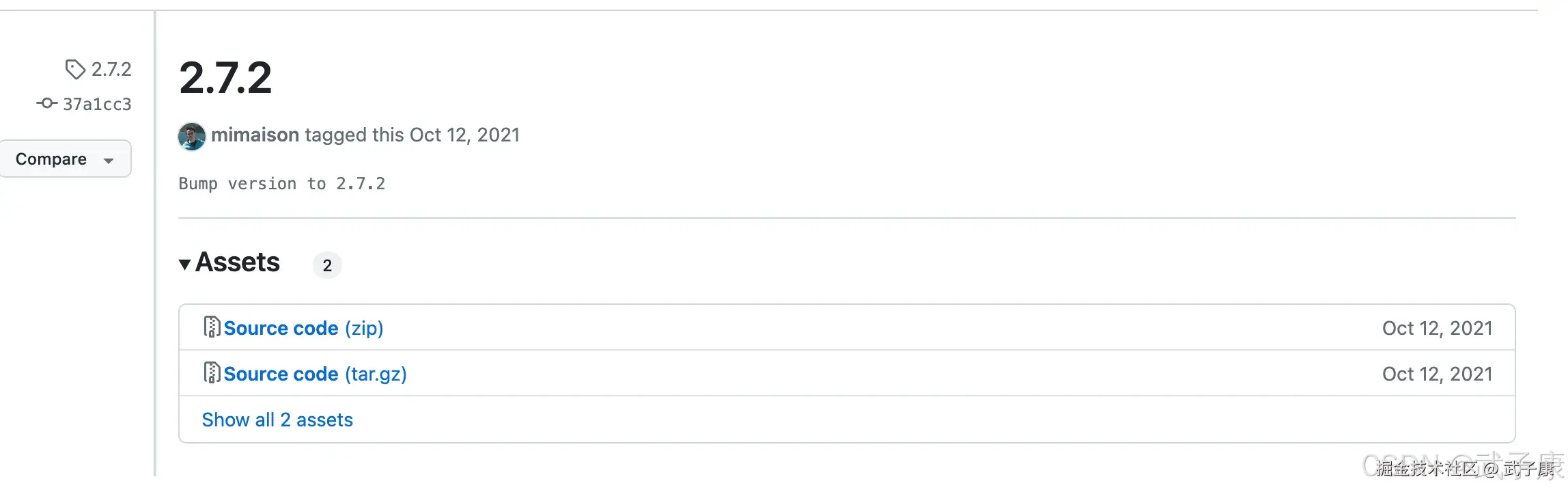
官方下载地址是编译的: 
解压配置
下载好之后,上传到服务器上,或者直接在服务器上 wget 进行下载。
shell
tar -zxvf kafka_2.12-2.7.2.tgz 按照之前的规范,我们需要进行移动处理:
按照之前的规范,我们需要进行移动处理:
shell
mv kafka_2.12-2.7.2 ../servers环境变量
shell
vim /etc/profile写入如下的环境变量内容
shell
# kafka
export KAFKA_HOME=/opt/servers/kafka_2.12-2.7.2
export PATH=$PATH:$KAFKA_HOME/bin记得刷新环境变量 
启动配置
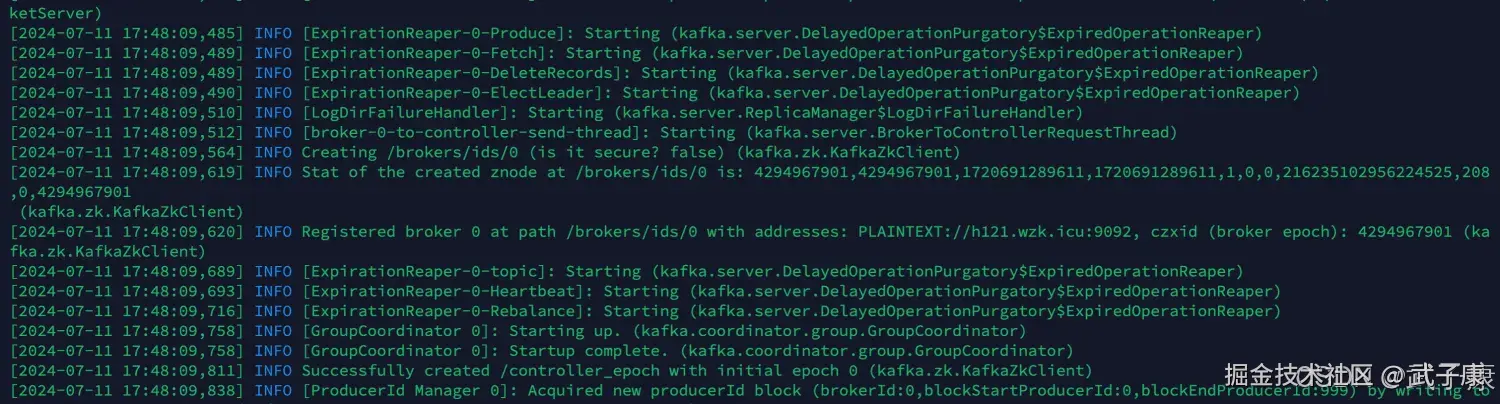
Kafka是需要连接ZooKeeper的,所以我们需要修改Kafka的配置。
shell
vim /opt/servers/kafka_2.12-2.7.2/config/server.propertiesZK配置
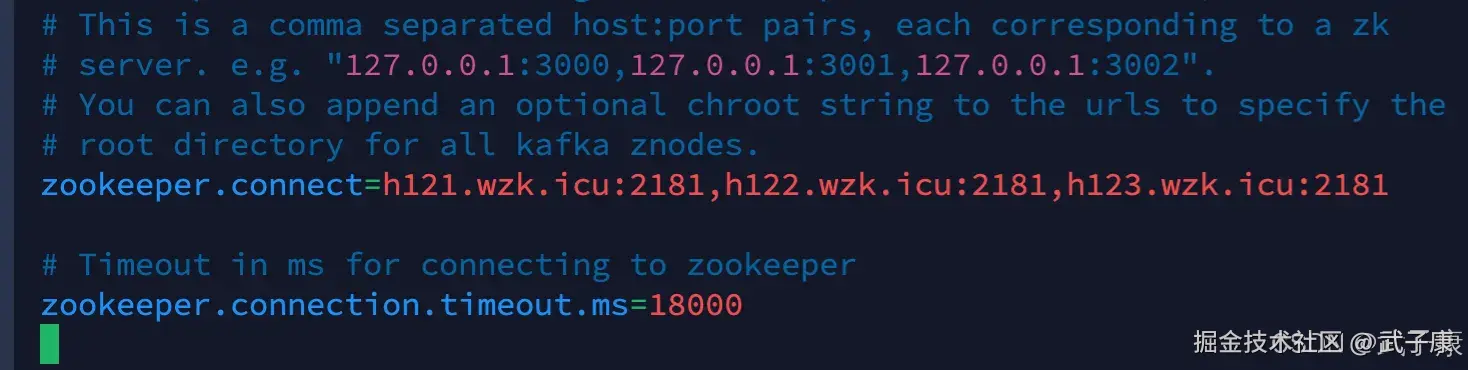
修改 zookeeper.connet 这一行:
shell
log配置
这里注意修改一下,同时记得把文件夹创建出来 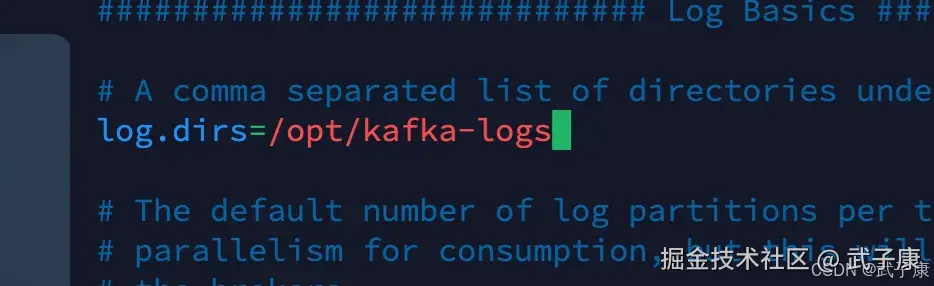
启动服务
shell
kafka-server-start.sh /opt/servers/kafka_2.12-2.7.2/config/server.properties