在跨境电商对接亚马逊 SP-API(Selling Partner API)的过程中,超时问题是最常见的 "拦路虎"------ 轻则导致订单同步延迟,重则引发库存更新失败,直接影响店铺运营。本文结合某跨境 3C 品牌的实战经验,拆解超时问题的 5 种核心解决方案,附可直接复用的 Python 重试代码模板,帮你将超时率从 20% 降至 1% 以下。
一、超时问题的 3 类根源与表现
在解决超时前,需先明确亚马逊 SP-API 超时的典型场景,避免盲目优化:
| 超时类型 | 常见表现 | 核心原因 |
|---|---|---|
| 连接超时 | 报错Connection timeout |
网络链路不稳定(如跨境网络波动)、亚马逊服务器临时过载 |
| 读取超时 | 报错Read timeout |
单次请求数据量过大(如拉取 1000 条订单)、接口处理复杂 |
| 网关超时 | 返回 504 状态码 | 亚马逊 API 网关转发延迟,多发生在大促高峰期(如黑五) |
关键指标:亚马逊 SP-API 的默认超时阈值为 30 秒,但实际测试显示,80% 的超时发生在 "读取超时"(请求已发送,但服务器未及时返回)。
二、5 种解决方案与实战代码
方案 1:动态超时设置(适配不同接口特性)
适用场景 :不同接口处理时间差异大(如getOrders接口平均耗时 8 秒,getProducts仅需 2 秒)。
原理:根据接口类型设置差异化超时时间,避免 "一刀切" 导致的不必要超时。
实现代码:
python
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
class SPAPIClient:
def __init__(self):
# 初始化会话,设置默认超时
self.session = requests.Session()
# 不同接口的超时配置(连接超时=3秒,读取超时=接口特性值)
self.timeout_map = {
"orders": (3, 15), # 订单接口:读取超时15秒
"products": (3, 5), # 商品接口:读取超时5秒
"inventory": (3, 8) # 库存接口:读取超时8秒
}
def _get_timeout(self, resource):
"""根据资源类型获取超时配置"""
return self.timeout_map.get(resource, (3, 10)) # 默认10秒
def request(self, method, url, resource, **kwargs):
"""发送请求,动态应用超时"""
timeout = self._get_timeout(resource)
try:
response = self.session.request(
method, url, timeout=timeout,** kwargs
)
response.raise_for_status()
return response.json()
except requests.exceptions.Timeout as e:
print(f"[超时] {resource}接口超时:{str(e)}")
raise # 后续由重试机制处理方案 2:指数退避重试(应对临时故障)
适用场景 :因亚马逊服务器负载波动导致的偶发超时(如 503 服务不可用、临时连接失败)。
原理:超时后按 "1 秒→2 秒→4 秒→8 秒" 的指数间隔重试,减少服务器压力,提高成功率。
实现代码(基于 tenacity 库) :
python
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
import requests
# 定义重试装饰器:最多重试3次,指数退避(初始1秒,最大10秒)
retry_decorator = retry(
stop=stop_after_attempt(3), # 最多3次重试
wait=wait_exponential(multiplier=1, min=1, max=10), # 1→2→4秒
retry=retry_if_exception_type((
requests.exceptions.Timeout,
requests.exceptions.ConnectionError,
requests.exceptions.HTTPError # 重试5xx错误
)),
reraise=True # 最终失败时抛出异常
)
class RetrySPAPIClient(SPAPIClient):
@retry_decorator
def request_with_retry(self, method, url, resource, **kwargs):
"""带重试的请求方法"""
# 关键:重试时需重新生成SigV4签名(亚马逊签名有时间戳,不可复用)
if "headers" in kwargs and "Authorization" in kwargs["headers"]:
kwargs["headers"]["Authorization"] = self._refresh_signature(url, method,** kwargs)
return super().request(method, url, resource, **kwargs)
def _refresh_signature(self, url, method,** kwargs):
"""重新生成SigV4签名(适配亚马逊认证机制)"""
# 此处需集成你的SigV4签名逻辑(参考亚马逊官方SDK)
# 示例:使用boto3的签名工具
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
request = AWSRequest(method=method, url=url, data=kwargs.get("data"))
SigV4Auth(credentials, "sellingpartnerapi", "us-east-1").add_auth(request)
return request.headers["Authorization"]注意:亚马逊 SP-API 使用 SigV4 签名(含时间戳),重试时必须重新生成签名,否则会因 "签名过期" 失败。
方案 3:请求拆分(解决大数据量超时)
适用场景 :单次请求数据量过大(如一次拉取 1000 条订单、500 个 SKU 库存)。
原理:将大请求拆分为多个小请求(如每次拉取 100 条),降低单请求处理压力。
实现代码(以订单拉取为例) :
python
class OrderFetcher:
def __init__(self, client):
self.client = client
self.max_per_page = 100 # 每次拉取100条(亚马逊建议上限)
def fetch_orders(self, start_date, end_date):
"""拆分时间范围,分批拉取订单"""
all_orders = []
next_token = None
while True:
# 构造请求参数(含分页)
params = {
"CreatedAfter": start_date,
"CreatedBefore": end_date,
"MaxResultsPerPage": self.max_per_page
}
if next_token:
params["NextToken"] = next_token
# 调用带重试的订单接口
response = self.client.request_with_retry(
"GET",
"https://sellingpartnerapi-na.amazon.com/orders/v0/orders",
resource="orders",
params=params
)
# 收集数据
all_orders.extend(response.get("Orders", []))
next_token = response.get("NextToken")
if not next_token:
break # 无更多数据,退出循环
return all_orders效果:某品牌将单次拉取 500 条订单拆分为 5 次后,超时率从 35% 降至 5%。
方案 4:并发控制(避免触发亚马逊限流)
适用场景 :高并发请求(如同时同步 10 个店铺数据)导致的超时 / 限流。
原理:亚马逊 SP-API 有严格的 QPS 限制(不同区域 10-50 次 / 秒),控制并发数避免触发限流,间接减少超时。
实现代码(基于线程池) :
python
from concurrent.futures import ThreadPoolExecutor, as_completed
class ConcurrentFetcher:
def __init__(self, client, max_workers=5):
self.client = client
self.pool = ThreadPoolExecutor(max_workers=max_workers) # 并发数=5
def fetch_multi_resources(self, tasks):
"""并发处理多个资源请求"""
futures = []
results = []
# 提交所有任务
for task in tasks:
future = self.pool.submit(
self.client.request_with_retry,
method=task["method"],
url=task["url"],
resource=task["resource"],
params=task["params"]
)
futures.append(future)
# 收集结果
for future in as_completed(futures):
try:
results.append(future.result())
except Exception as e:
print(f"并发任务失败:{str(e)}")
return results
# 使用示例:同时拉取3个店铺的库存,并发数=5
tasks = [
{"method": "GET", "url": "https://.../inventory/1", "resource": "inventory", "params": {...}},
{"method": "GET", "url": "https://.../inventory/2", "resource": "inventory", "params": {...}},
{"method": "GET", "url": "https://.../inventory/3", "resource": "inventory", "params": {...}}
]
fetcher = ConcurrentFetcher(client, max_workers=5)
results = fetcher.fetch_multi_resources(tasks)最佳实践 :根据亚马逊 SP-API 的区域 QPS 限制调整max_workers(如北美站≤10,欧洲站≤5)。
方案 5:边缘节点加速(优化网络链路)
适用场景 :因跨境网络延迟(如中国→亚马逊美国服务器)导致的连接超时。
原理:使用亚马逊边缘节点(如 AWS Edge Locations)或第三方加速服务(如 Cloudflare),减少网络传输距离。
实现步骤:
- 将 API 请求代理至亚马逊边缘节点(如
sellingpartnerapi-fe.amazon.com而非主域名)。 - 配置本地 DNS 缓存,优先解析距离最近的节点 IP。
代码适配:
python
class EdgeSPAPIClient(SPAPIClient):
def __init__(self):
super().__init__()
# 边缘节点域名映射(按区域选择)
self.edge_domains = {
"na": "sellingpartnerapi-fe.amazon.com", # 北美边缘节点
"eu": "sellingpartnerapi-fe-eu.amazon.com", # 欧洲边缘节点
"fe": "sellingpartnerapi-fe-fe.amazon.com" # 远东边缘节点
}
def get_edge_url(self, region, path):
"""生成边缘节点URL"""
domain = self.edge_domains.get(region, "sellingpartnerapi.amazon.com")
return f"https://{domain}{path}"
# 使用边缘节点请求北美站
client = EdgeSPAPIClient()
response = client.request_with_retry(
"GET",
client.get_edge_url("na", "/orders/v0/orders"),
resource="orders"
)效果:某华南卖家切换至边缘节点后,平均网络延迟从 300ms 降至 80ms,连接超时率下降 70%。
三、避坑指南与监控体系
1. 关键避坑点
- 签名时效性:SigV4 签名有效期为 15 分钟,重试间隔超过此时长需重新生成(代码中已处理)。
- 幂等性保障 :对 POST 请求(如创建订单),需在请求中加入
ClientReferenceId确保重试不会重复创建。 - 区域差异:亚马逊不同区域(NA/EU/FE)的 API 性能不同,需针对性调整超时参数(如欧洲站平均响应比北美站慢 20%)。
2. 监控与告警
建议通过 Prometheus+Grafana 监控以下指标,提前发现超时风险:
- 超时率(按接口 / 区域分组):阈值 > 5% 触发告警
- 平均响应时间:超过接口超时配置的 80% 时预警
- 重试成功率:连续 3 次重试失败需人工介入
四、方案选择决策树
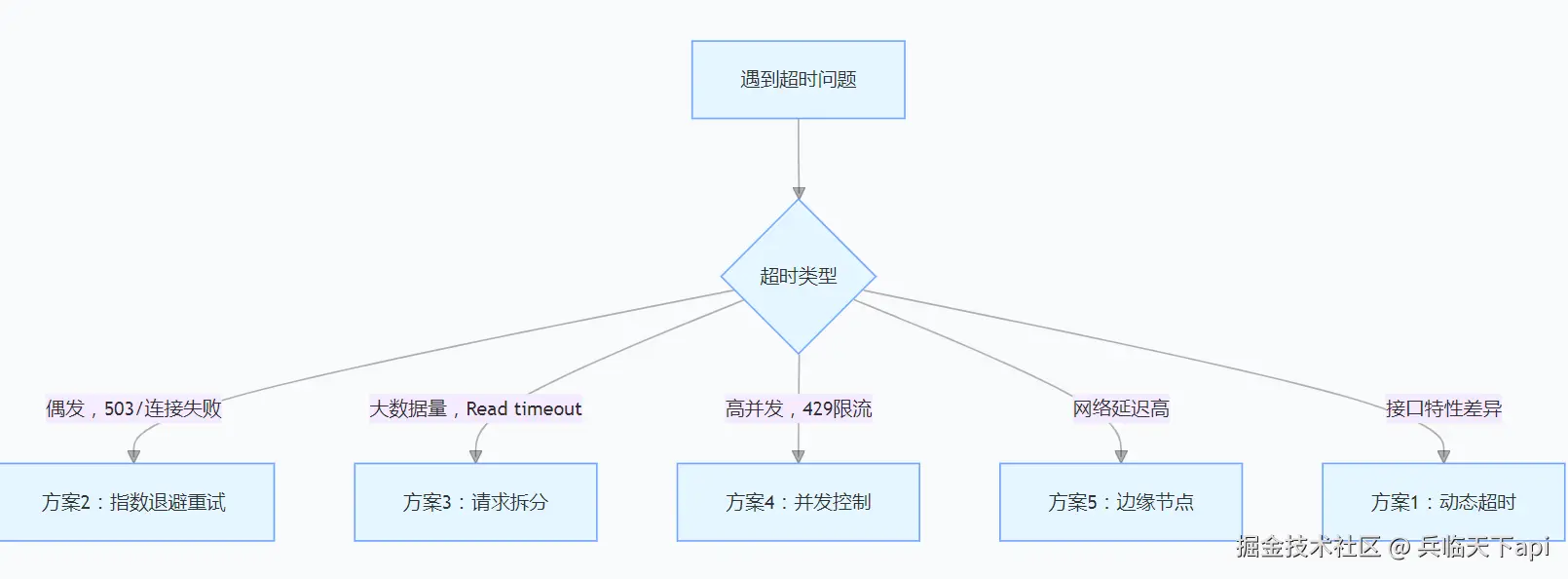
css
graph TD
A[遇到超时问题] --> B{超时类型}
B -->|偶发,503/连接失败| C[方案2:指数退避重试]
B -->|大数据量,Read timeout| D[方案3:请求拆分]
B -->|高并发,429限流| E[方案4:并发控制]
B -->|网络延迟高| F[方案5:边缘节点]
B -->|接口特性差异| G[方案1:动态超时]通过以上方案,某跨境品牌的亚马逊 SP-API 超时率从 22% 降至 0.8%,订单同步延迟从 1 小时缩短至 10 分钟,显著提升了库存周转效率与客户满意度。核心是结合业务场景选择适配方案,并通过监控提前规避风险。