 上一节我们列举了LangGraph的基本节点类型,但是只是知道,并不知道怎么组装和使用,先列举下来,后面讲如何组装:
上一节我们列举了LangGraph的基本节点类型,但是只是知道,并不知道怎么组装和使用,先列举下来,后面讲如何组装:
- Node:一个函数(LLM调用、工具、判断)。
- Edge:跳转规则(普通边 + 条件边)。
- State:共享状态(情绪、记忆、亲密度等),支持Reducer自动合并。
- Checkpoint:自动持久化(内存/SQLite/Postgres),支持崩溃恢复 + 时间旅行调试。
- Interrupt:原生Human-in-the-loop(用户中途纠正、审批、回滚)。
一、状态机思维
在 LangChain 早期版本(包括 LCEL)中,绝大多数工作流本质上是 有向无环图(DAG) 或简单的线性流水线(Pipeline)。数据像流水一样从 A 流到 B 再流到 C,但很难 "回头"。
LangGraph 最核心的突破就是它是支持环的有向图,相比于LangChain古早的链式版本极大的增强了灵活性。
假设,我们现在有这样一个业务,理想状态下希望LLM依次执行:
- 调用工具查询数据
- 格式化数据
- 打印结果
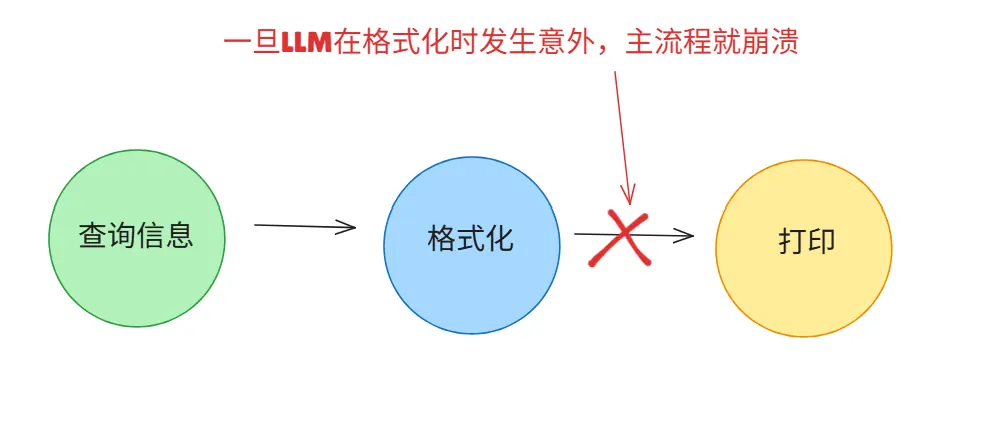
对,这就是早期的链式思维,一旦LLM因为其随机性出错,整个流程就会轰然倒塌。
因此,事实证明,链式操作救不了Agent开发。
一种更稳健,更方便影对随机性的设计哲学被LangGraph选中:状态机。
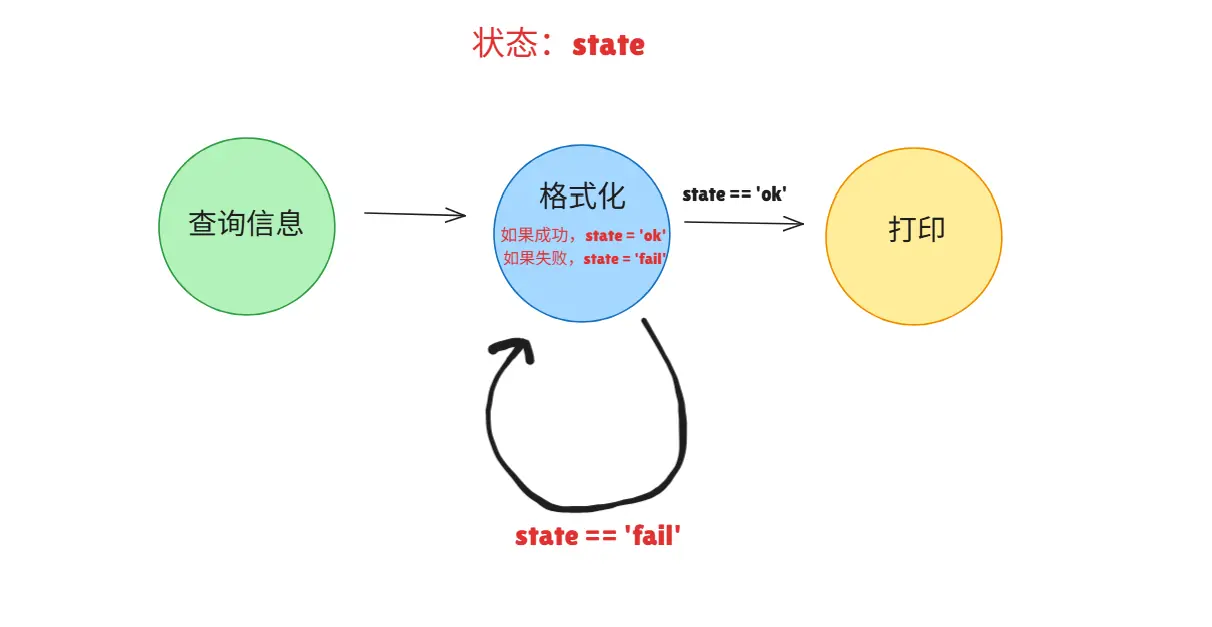
状态:可以理解为一组能被所有节点读取和更新的变量。
对状态的使用通常遵循这样的规则:
- 在Node中更新状态
- 在选择连线时读取状态
以上图为例,如果格式化失败,那么state='fail',而在选择连线时,因为 state == 'fail',因此进入了格式化自循环的连线。
在正式生产中,我们还可以加入 fail_count 这样的状态,来保证自循环的上限次数。
二、定义状态
你可以这样定义状态:
python
from typing import TypedDict, Annotated
class AgentState(TypedDict):
input_text: str
messages: Annotated[list[BaseMessage], operator.add]
result: dict
status: str # 状态标识"success" 或 "error"这个定义很好解释,AgentState 继承自 TypedDict,有4个基本属性。
其中i比较难理解的是这一行:
python
messages: Annotated[list[BaseMessage], operator.add] 简单来说,这是python的注解写法,它规定了 messages的类型是listBaseMessage,并且注明其更新逻辑只能是add,而不能是覆盖。
后续LangChain在操作该属性时,必须遵守以下方法:
csharp
state["messages"] = operator.add(旧的messages列表, 新返回的messages列表)这就保证了老的聊天历史不会被覆盖。
如果你希望messages只保留最新的5条,可以这样自定义一个合并逻辑:
python
# 1. 自己写一个合并逻辑(Reducer)
def keep_last_5_messages(old_messages: list, new_messages: list) -> list:
"""这是一个自定义的 Reducer 函数:合并消息,但只保留最后 5 条"""
# 先把旧的和新的加起来
combined = old_messages + new_messages
# 然后切片,只取最后 5 个元素
return combined[-5:]
# 2. 把你的函数塞进 Annotated 里!
class AgentState(TypedDict):
input_text: str
# 告诉 LangGraph,更新 messages 时用我的函数!
messages: Annotated[list[BaseMessage], keep_last_5_messages]
status: str三、构建节点 Node
本文开头陈列了,Node的本质就是一个函数。
如果我们想按上面梳理的结果,实现一个最简单的例子:
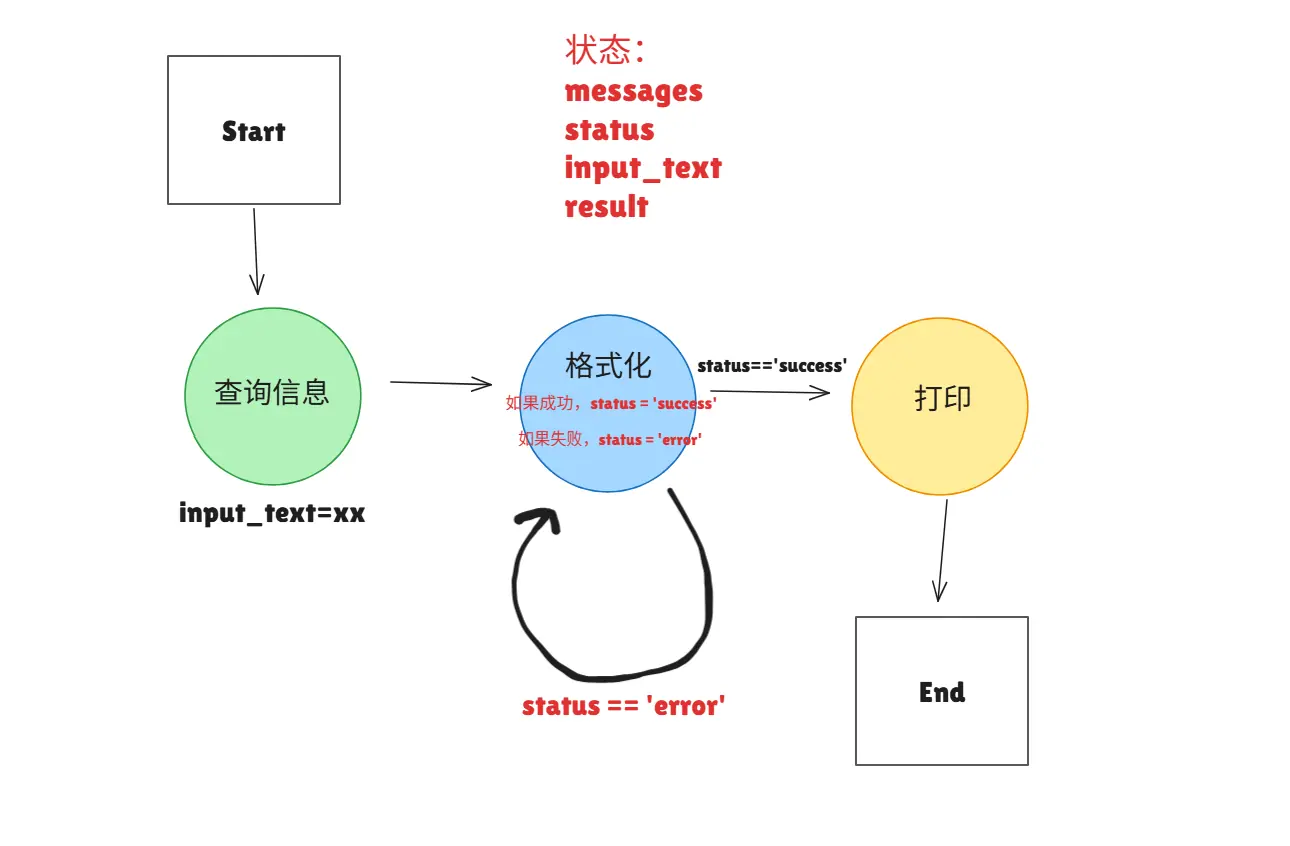
那我们至少需要构建三个函数:
- node_a_input:返回一段文本
- node_b_llm:用LLM格式化文本,但有概率失败
- node_c_print:打印状态中的result值
在langgraph中,一个节点Node大概长这样:
python
def node_a_input(state: AgentState):
"""节点A:负责接收初始输入"""
text = "张三18岁。"
print(f"\n▶ [Node A] 初始化输入: {text}")
# 将初始数据写到状态黑板上
return {"input_text": text}- 它可以读取入参 state 上的状态值
- 它的return值对象可以更新 state的最新信息
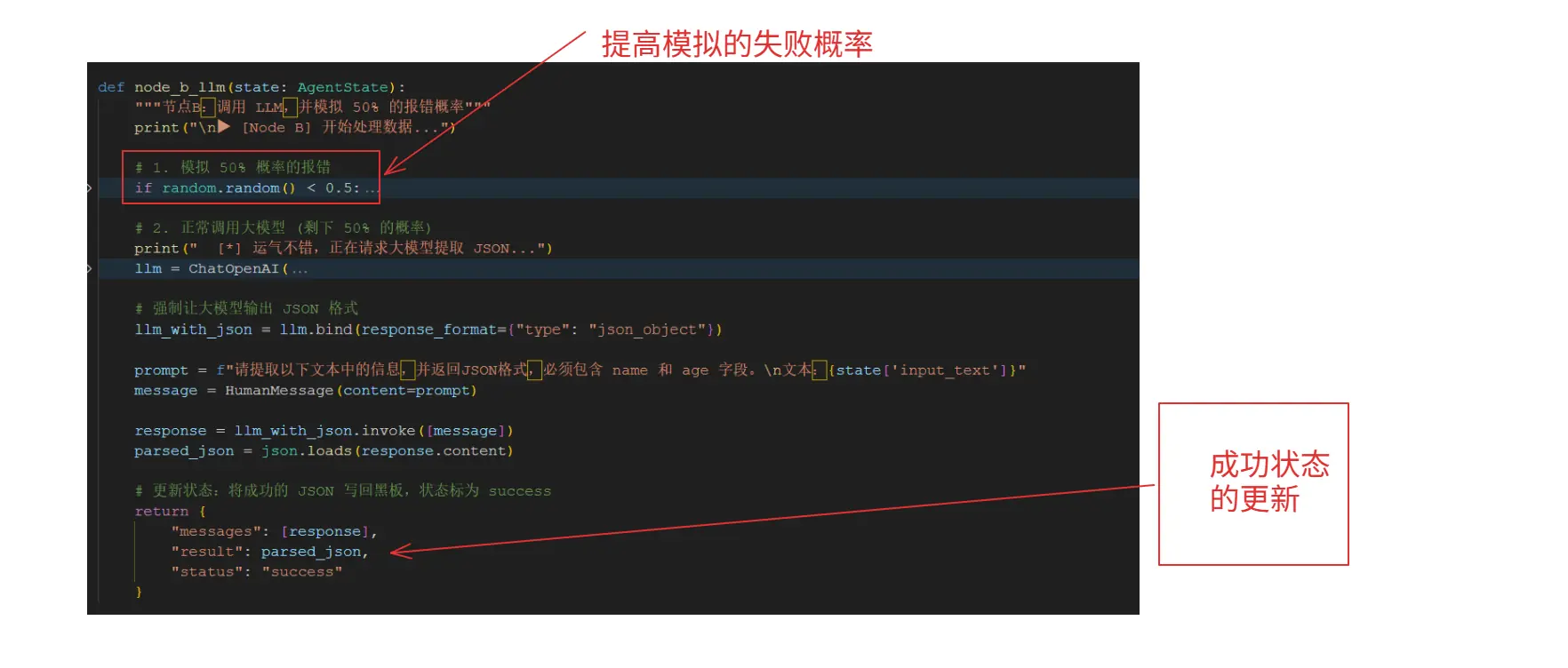
非常好理解,我们可以根据这个来撰写核心的node_b_llm的逻辑:
四、构建有向图
尝试以下代码:
python
from langgraph.graph import StateGraph, START, END
workflow = StateGraph(AgentState)
# 添加所有节点
workflow.add_node("node_a", node_a_input)
workflow.add_node("node_b", node_b_llm)
workflow.add_node("node_c", node_c_print)
# 定义流转规则
workflow.add_edge(START, "node_a")
workflow.add_edge("node_a", "node_b")
def router_edge(state: AgentState):
"""条件边:读取 status 字段决定去向"""
if state["status"] == "error":
print(" ↳ [Edge 路由] 发现错误状态,打回 Node B 重试!")
return "retry"
else:
print(" ↳ [Edge 路由] 状态成功,放行到 Node C。")
return "continue"
# 添加条件边:离开 node_b 时,用 router_edge 进行判断
workflow.add_conditional_edges(
"node_b",
router_edge,
{
"retry": "node_b", # 如果 router_edge 返回 "retry",跳回 node_b
"continue": "node_c" # 如果 router_edge 返回 "continue",跳到 node_c
}
)
workflow.add_edge("node_c", END)这部分代码其他部分都非常好理解,无需多言,只有关于边的条件判断的部分需要解释下:
python
workflow.add_conditional_edges(
"node_b",
router_edge,
{
"retry": "node_b",
"continue": "node_c"
}
)对 node_b 的出口增加择线逻辑 router_edge,如果它返回 retry回到 node_b 进行自循环,如果返回 continue 则跳转到 node_c。
而 router_edge 也是个和 Node类似的方法,可以有效消费 state进行状态机的流转判断。
五、执行脚本
在本系列课程的开源demo项目里,你可以拿到本节课我们讲解的 demo 源码,地址:
让我们尝试执行以下命令:
bash
python .\lesson_16\02_state_demo.py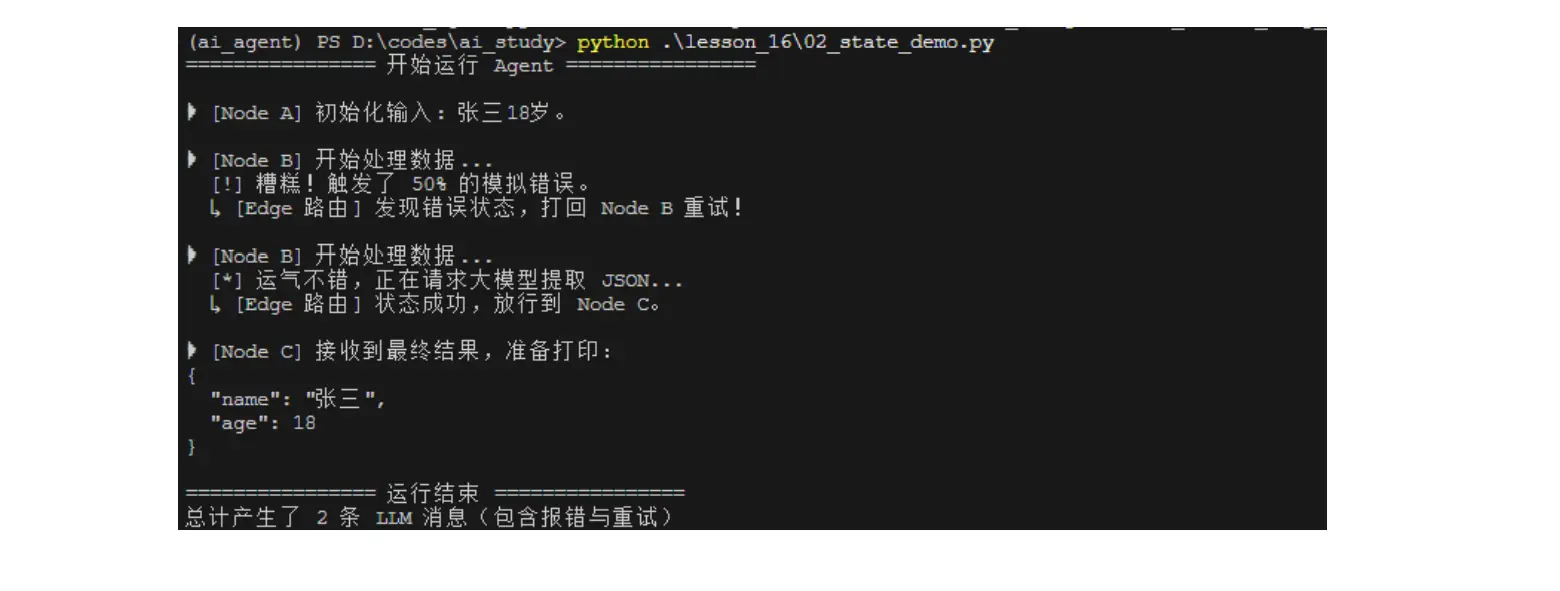
哪怕第一次出错了,整个程序依然可以自动完成重试,并输出期望中的结构。
没错,这就是新版本LangChain的核心思维转变:
- 忘记链式
- 拥抱状态机思维
你需要不停地维护一组全局状态,直到你放弃任务或者完成任务。
六、小结
本章,我们学习了新版LangChain和LangGraph的状态机思维。
接下来,我们还需要了解一下langchain的其他基本能力。
敬请期待!
