本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第3篇,解析跨国数仓迁移背后的性能优化技术。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
背景
作为东南亚数字经济的核心参与者,GoTerra的数据架构需支撑亿级用户规模的交易、高并发风控及跨区域物流调度。其原有BigQuery数仓虽具备强大的分析能力,但在业务规模突破临界点后,成本问题日益凸显。迁移至MaxCompute的核心目标,是通过底层架构重塑与性能优化技术体系,实现"降本"与"增效"的双重突破。在攻克 SQL 语法转换、存储格式等技术难题后,迁移进入深水区------性能优化成为项目推进的关键瓶颈,并且面临三大核心挑战:
-
业务脚本复杂性高:涉及 1万+ 生产级 SQL 脚本,覆盖支付、物流、风控等核心业务线,脚本模式丰富、性能目标及成本诉求各异,优化难度大。
-
增量功能叠加挑战大 :迁移过程中同步推出的600+新功能 (如
append2。0、unnest等)导致优化复杂度指数级上升。 -
极限交付时间窗口:需在不足 4 个月的时间内,保障所有业务平滑迁移至 MaxCompute,同时全面满足高标准 SLA,容错空间极小。
性能优化方法论:从"盲人摸象"到"精准狙击"
针对上述挑战,团队摒弃传统"粗放式"优化策略,转而建立"数据驱动、分层治理"的优化框架,其核心逻辑是通过智能分类,将有限资源投入关键瓶颈点。根据二八原则 ,80% 的问题/资源消耗来自 20% 的高频或低效查询,为了精准定位问题,我们通过一个自动化的分类工具快速识别:
-
高频查询:优化收益最大
-
低效查询:存在潜在优化空间(如全表扫描、非预期CROSS JOIN)
-
关键业务查询:需优先保障 SLA
同时在这个工具基础上:
-
建立性能基线:分类后统计各类型查询的耗时、资源消耗趋势。
-
评估优化效果:对比优化前后的同类型查询指标变化。
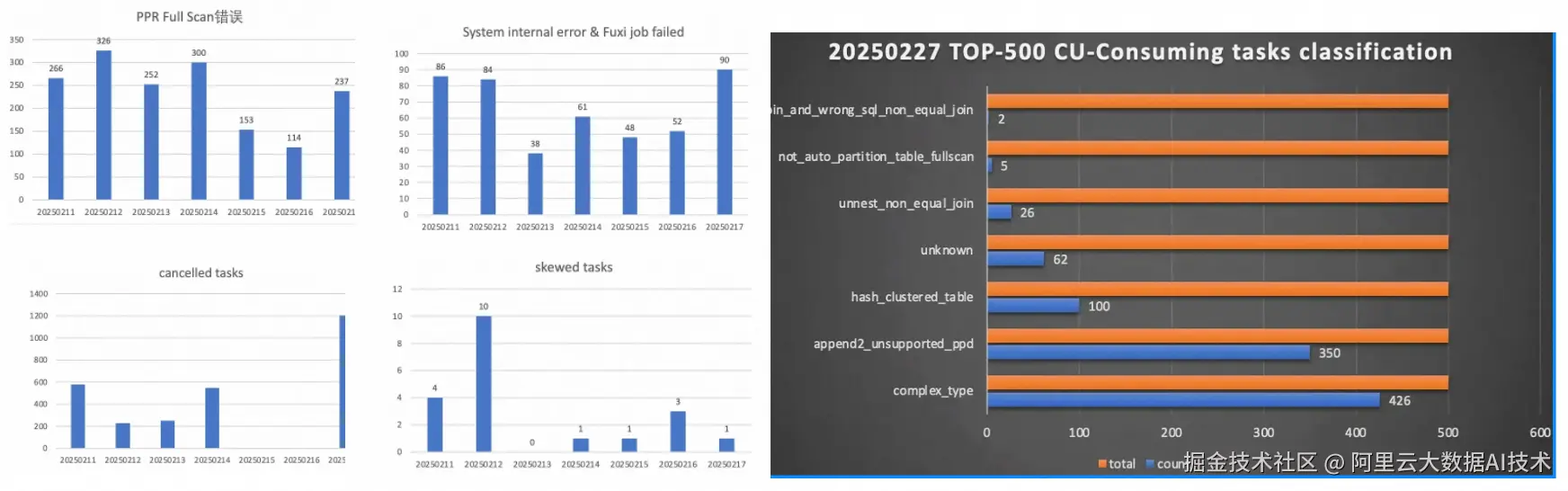
以下是性能优化初期查询分类的一个示例图,从图中我们很轻易的可以看到,分区裁剪/复杂类型/append2/unnest等是主要问题,应该着重解决。
关键优化
Auto Partition优化
痛点
MC通过Auto Partition表来实现和BQ time-unit column partitioning类似的功能。相较于传统静态分区表,Auto Partition 表通过trunc_time 函数动态生成分区列,如下图所示:
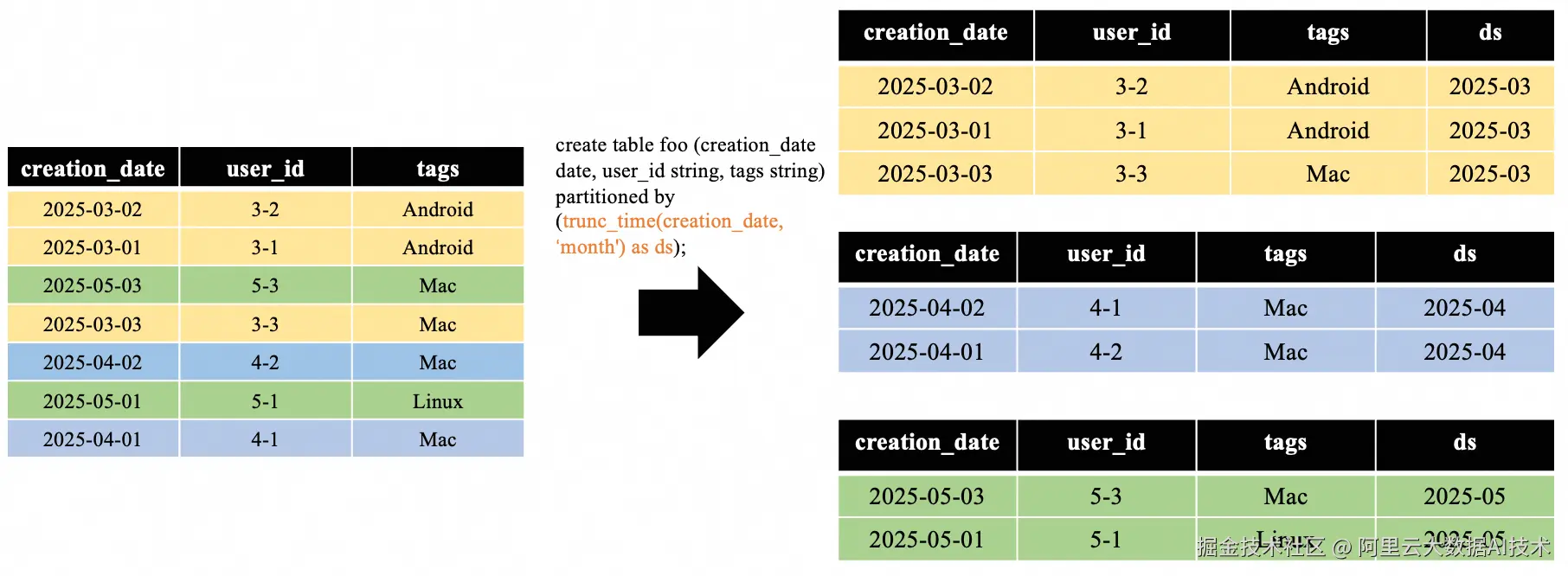
Auto Partition功能有效提升了分区管理的灵活性,但是分区列与查询条件无法直接映射导致无法直接复用静态分区表的分区裁剪流程,从而使得分区裁剪失效,引发两大核心问题:
-
读表性能劣化:查询需全量扫描所有分区,时延高
-
资源浪费严重:冗余数据扫描使计算资源消耗高
方案
为了支持Auto Partition表的分区裁剪功能,我们设计了基于表达式推导的动态分区裁剪方案,在保证查询语义正确性的前提下最大化减少数据扫描量。假设有下Auto Partition 表及其查询:
sql
create table auto_partition_table
(
key string,
value bigint,
ts timestamp
)
partitioned by trunc_time(ts, 'day') as pt
;
SELECT * FROM auto_partition_table
WHERE ts > timestamp'2024-09-25 01:12:15';从上可以看到基于ts列的过滤条件做分区裁剪的本质是进行表达式映射转换,即将ts列相关的表达式转换成pt列相关的表达式。需要注意的是转换前后的表达式不要求完全等价,但是要求过滤结果存在"包含"的关系,具体又可以分为以下3种场景。
基础裁剪场景
对于ts列的过滤条件中不包括函数的场景,可以直接做表达式的推导转换,但是转换前后的表达式过滤范围不等价,因而原始表达式需要保留,推导过程如下所示:
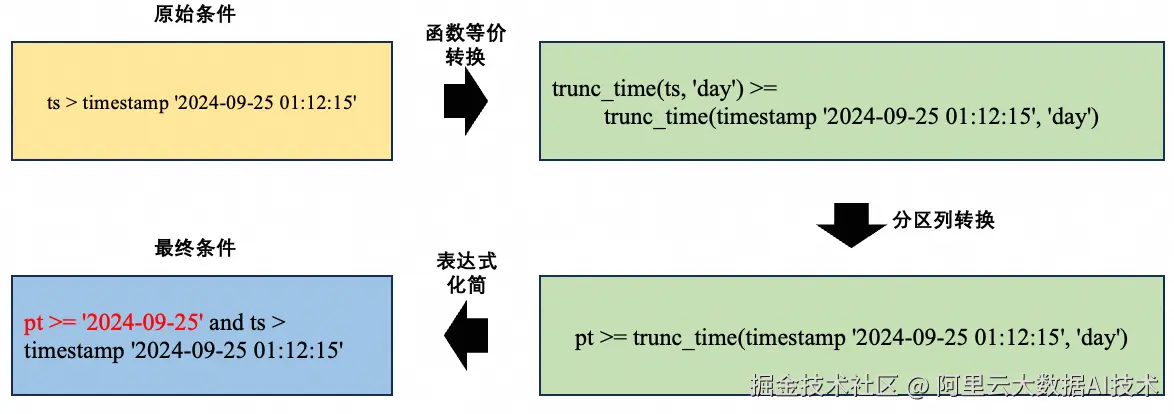
函数非等价转换场景
对于查询条件包含时区转换、日期格式函数等操作时,对于ts列的过滤条件无法直接做表达式的映射转换,因此我们引入了内置函数理解的能力,将表达式中的函数fold掉。假设有如下查询:
csharp
select * from auto_partition_table
where TODATE(FROM_UTC_TIMESTAMP(ts, 'Asia/Jakarta')) = date '2024-09-14'在分区裁剪过程中,过滤条件会做如下推导:
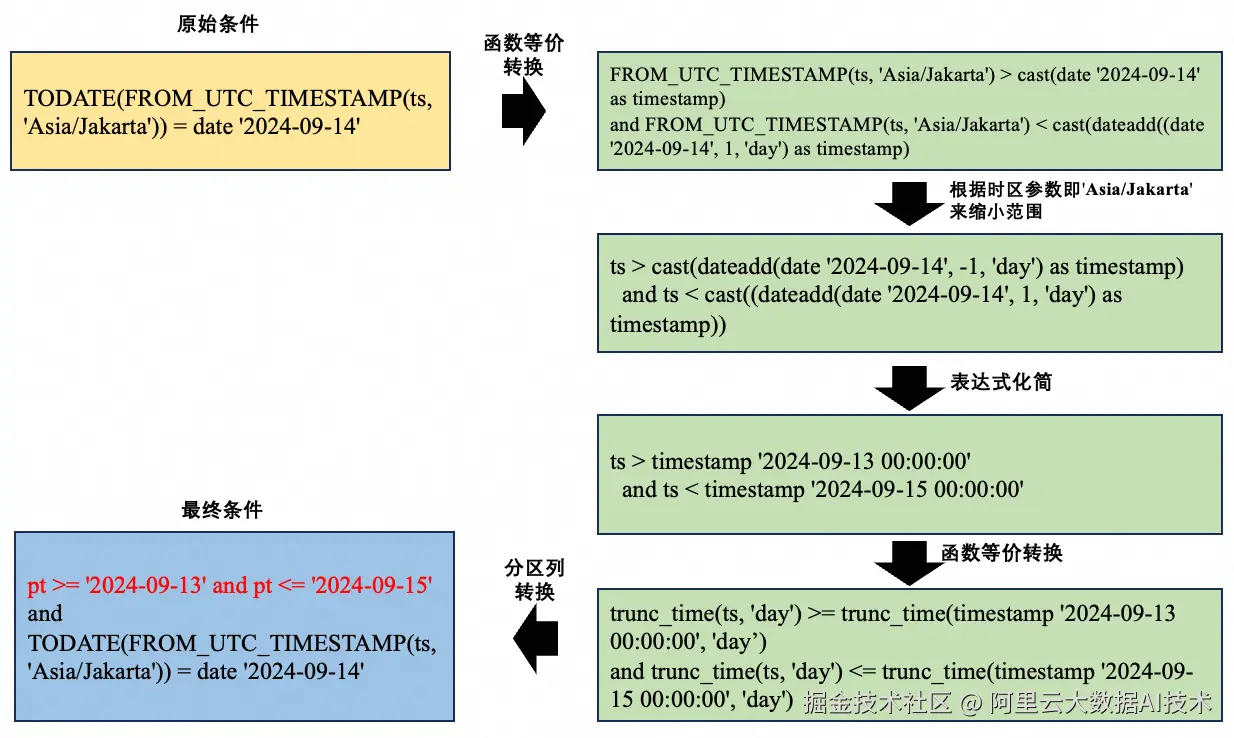
需要注意的是,原始过滤条件的结果是分区裁剪结果的子集,所以推导的过程只能应用在分区裁剪内部,原始的过滤条件会保留。
函数等价转换场景
如果查询条件中的函数与分区键定义函数语义完全等价,如datetrunc(ts, 'day')与trunc_time(ts, 'day'),那么对于ts列的过滤条件可以做等价转换,这个过程也依托内置函数理解框架来实现。
csharp
select * from auto_partition_table
where datetrunc(ts, 'day') >= timestamp '2024-09-14 10:01:01';上述查询中datetrunc(ts, 'day') 语义上和trunc_time(ts, 'day')相同,因而可以做如下推导转换:
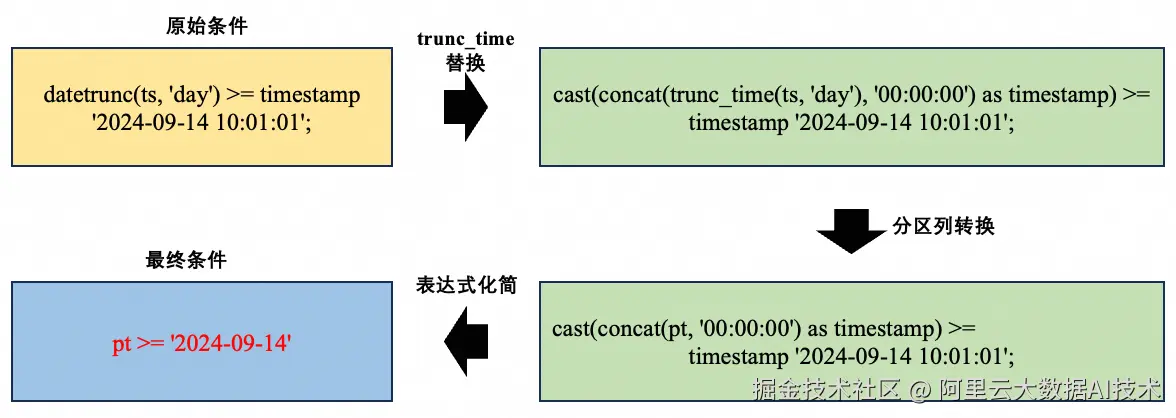
这个过程中的表达式转换是等价的,因此,分区裁剪完成后,原始的过滤条件不需要再保留。
价值
通过基于表达式推导的动态分区裁剪方案,MaxCompute 在保持分区管理灵活性的同时,实现了与静态分区表同级的 高性能、低成本的数据处理能力。
复杂类型之unnest优化
痛点
在 Google BigQuery 中,UNNEST 是处理数组(ARRAY) 类型数据的核心操作,用于将嵌套的数组结构展开为多行平铺数据,如下所示:
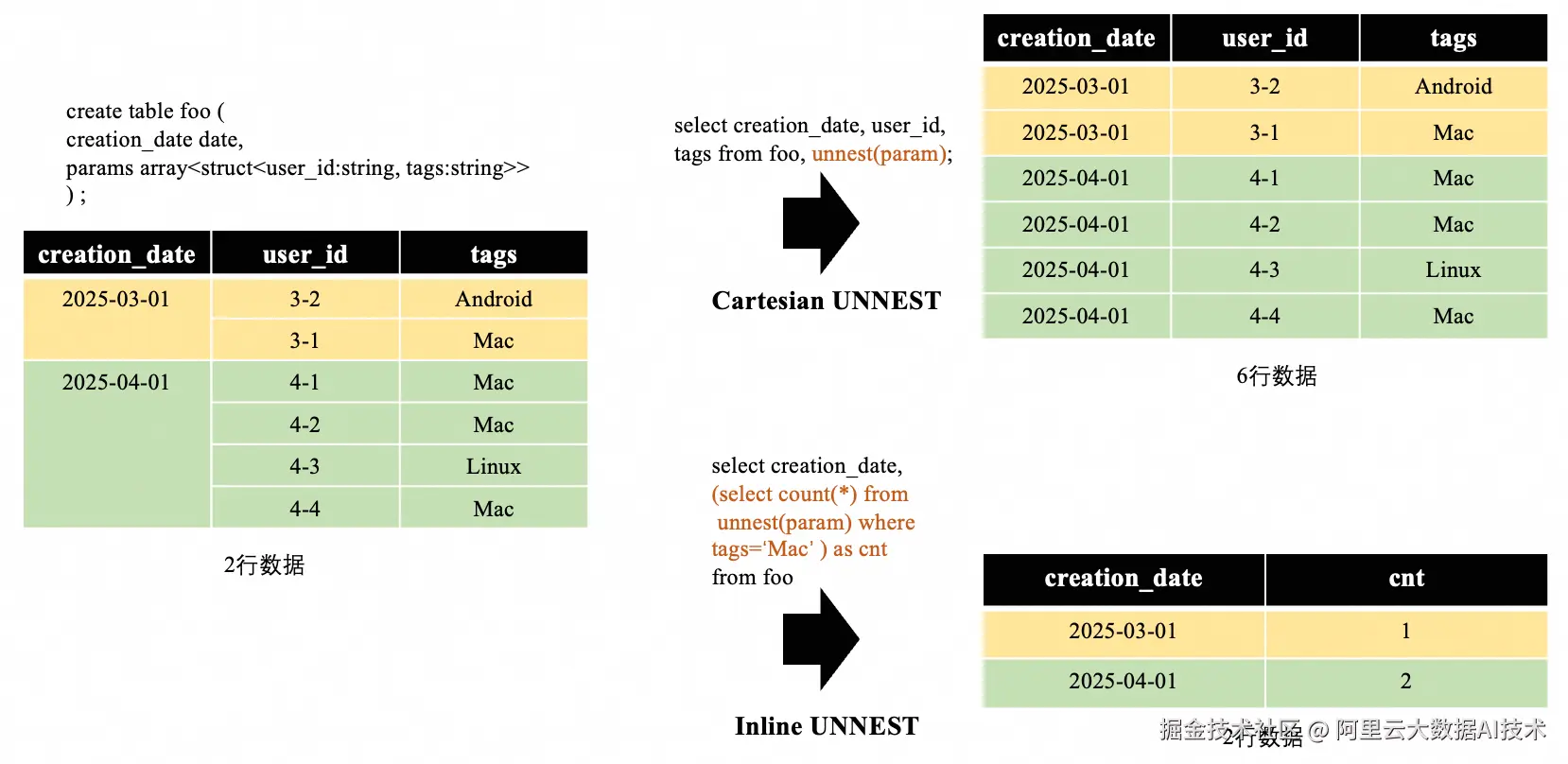
GoTerra的查询大量使用UNNEST,这些查询迁移至 MaxCompute 后,需通过LATERAL VIEW+EXPLODE 或CROSS JOIN 模拟此功能,导致以下性能问题:
-
执行计划冗余:单次
UNNEST被拆解为 多次 TableScan 和 Join,资源消耗激增。 -
数据膨胀风险:笛卡尔积引发中间结果爆炸。
-
功能局限:无法高效处理 多层嵌套 ARRAY
以下是一个简化的case:
csharp
create table foo (
creation_date date,
params array<struct<user_id:string, tags:string>>
) ;
select creation_date,
(select count(*) from
unnest(param) where tags='Mac' ) as m_cnt,
(select count(*) from
unnest(param) where tags='Linux' ) as l_cnt
from foo;其执行计划如下:
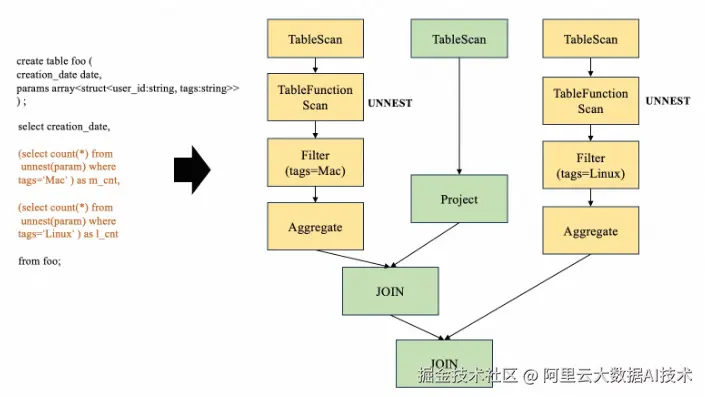
从上图可以看到,执行计划有以下问题:
-
对同一个table有3次Scan
-
对同一个column执行了2次同样的explode操作
-
执行了多次join
方案
针对上述问题,我们重新设计了unnest的支持框架,采用了通用的框架,即支持执行sub plan的apply算子,以便具备通用的subquery执行能力和更强的扩展性。在新的框架下,unnest相关的查询计划如下所示:
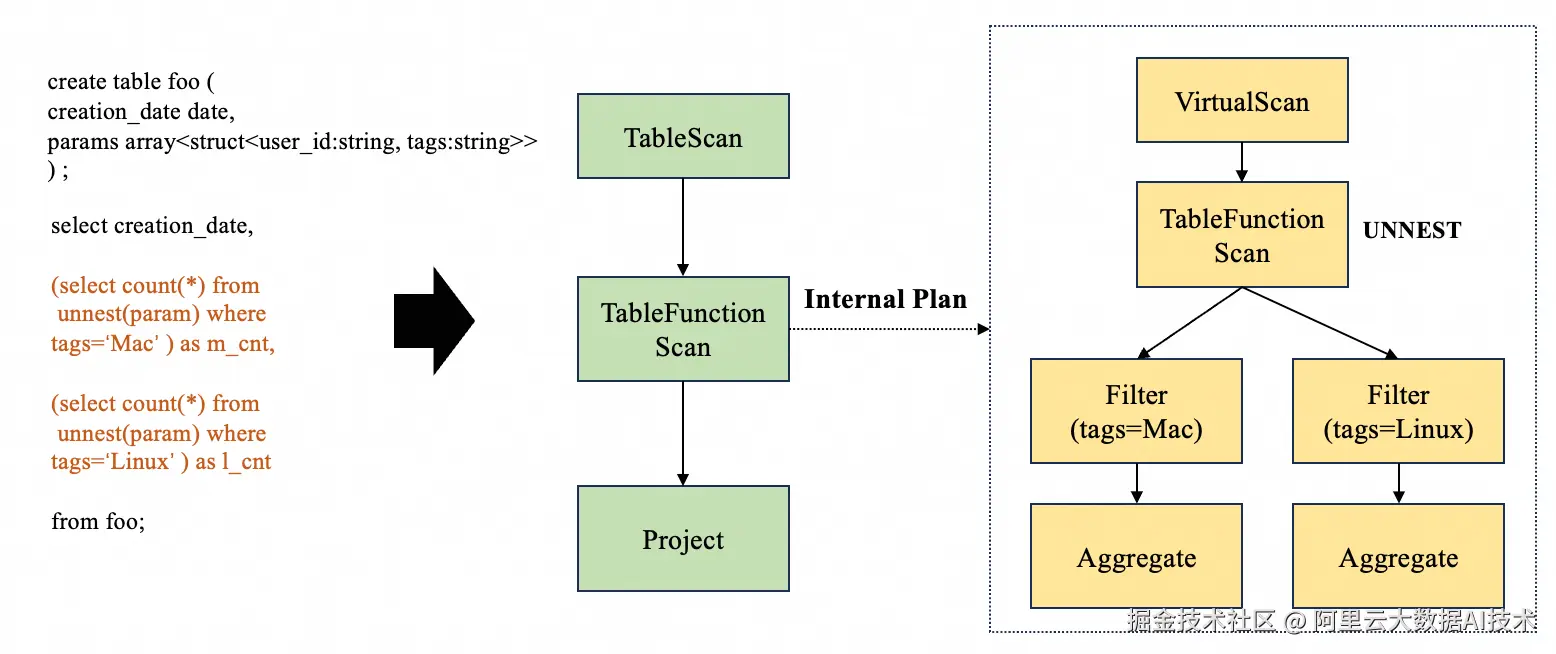
整个优化过程可以概述为下面几个步骤:
-
引入了Internal plan的概念,Internal plan也是一颗算子树,代表外层中对每一行数据的内部计算逻辑,编译器会按照上述要求生成初始的plan。
-
优化器需要做进一步优化,关键的步骤包含:
-
Internal plan不能影响外部plan的优化,包括下推、列裁剪等。
-
外部plan优化完成后,需要对Internal plan做优化。
-
优化过程中需要对相邻TableFunctionScan做合并,之后对合并后的Internal plan做SubtreeMerge
-
执行器需要根据外层和内层执行计划执行。
价值
通过对UNNEST执行框架的重构和升级,MaxCompute 的 Unnest 能力在性能、稳定性上方面都有突破:1)性能提升1-10倍;2)避免了大型嵌套UNNEST场景下导致的OOM错误,为复杂数据分析场景打下了坚实的基础
超大型查询优化
痛点
GoTerra的查询中存在大量超大型查询,这些超大型查询出来的执行计划体量远大于一般大型查询计划, 其特征为算子多, 子查询深度嵌套, 单行类型信息中 单列的 STRUCT 内部列达数千个。

超大型查询计划会使得优化器在处理计划过程中出现大量内存使用, 遍历图缓慢等问题。针对超大型查询计划, 我们开发了以下技术解决。
方案
图优化
每一个查询计划都是由关系算子组成的有向无环图, 图的遍历方向为从输出到输入。
而优化器主要的工作是对图中的算子模式进行匹配, 并且使用新的算子结构替换图中旧的算子结构。
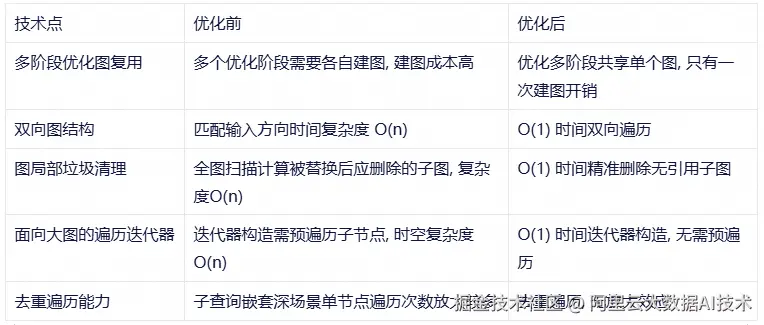
Digest 全局复用
Digest(完整摘要) 表达了关系算子的任意部分的完整信息, 是优化器识别关系算子的关键。 每次变换生成新的关系算子, 都需要构造关系算子整体 Digest, 包含类型信息 Digest/标量函数Digest 等。
我们支持了对这三类信息的缓存以及局部复用。 由于实际计划中存在大量相似信息结构, 在实际优化过程中将相关对象哈希和相等比较计算复杂度, 以及所需内存空间降低了几个数量级。
以类型信息为例

价值
通过超大规模查询优化技术,MaxCompute 突破优化器瓶颈,实现 深度嵌套、复杂类型、百万级算子 执行计划的高效处理。在典型大型查询中, 优化耗时从15分钟+降至1分钟, 峰值内存从 5GB+ 降低至 1GB。
Intelligent Tuning
痛点
在大数据计算场景下,因为统计信息的缺失、大量存在的UDF优化黑盒、作业复杂度高(如GoTerra的SQL经常有几千行)等等因素,使得优化器很难做准确的基数估计,产生最优的执行计划,以及难以事先给定一个理想的各stage资源分配计划。
这就导致一方面系统miss了大量的优化机会,另一方面用户对关心的作业往往需要进行手动调优,如调整各stage并发度、添加调优flag等,费时费力门槛高,并且当数据和作业发生变化时,还需要进行相应的调整。
Intelligent Tuning就是要解决这一系统和用户的痛点,对于计算逻辑基本相似的recurring job,能够充分利用历史执行信息,来对未来执行起到指导作用,从而能够做到系统自动优化,提升作业整体性能。
方案
我们的主要思路是收集作业实际运行的丰富的统计信息,经过实时的feedback或者离线的更加复杂的training和分析后,使得优化器能够学习到作业的历史执行状态,更加聪明地"理解数据、理解作业",一方面将历史统计信息注入到CBO框架中产生全局最优的执行计划,另一方面根据每个stage的计算量、运行速度等,智能地调整并发度,避免worker资源的浪费,以及自动对并发度偏低的stage进行加速。
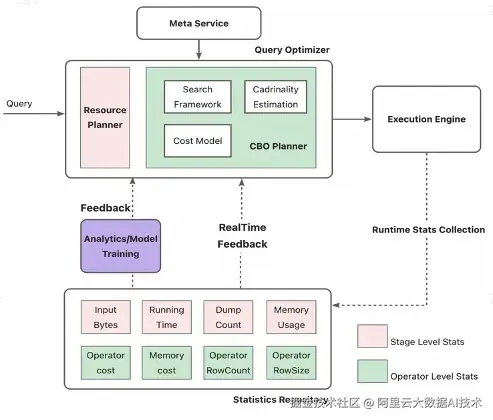
架构图
下图列举了Intelligent Tuning整体的优化能力,包括执行计划优化、资源分配优化、执行模式选择优化、以及runtime算子执行优化。Intelligent Tuning具备框架性的优化扩展能力,一方面能够自动利用CBO框架去让一些优化规则生效,另一方面也能不断拓展作业运行方方面面的优化。
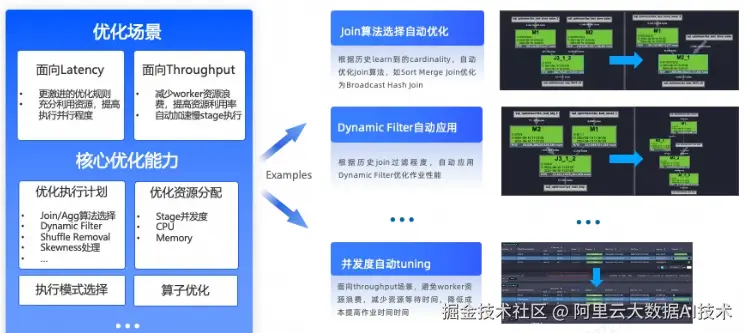
价值
Intelligent Tuning是性能优化的"第二增长曲线",极大地避免了人工作业调优,同时使得系统自动优化能力大大增强。在GoTerra项目中,应用Intelligent Tuning的资源分配优化后,典型项目能够节省87%资源,通过更加智能的执行模式选择,避免online job回退offline job带来的损耗,典型作业提速45%。Intelligent Tuning的优化能力还在扩展中,将不断提升引擎的性能和易用性。
总结及未来展望
对MaxCompute而言,_GoTerra_的迁移不仅是亚太区头部客户的标杆实践,更是一次超大规模负载下的性能极限验证。在4个月的性能攻坚中,我们通过内核级重构和升级,实现了资源效率与计算性能的范式级突破:
- 资源效率突破
-
金融ETL场景:CU消耗仅为 BigQuery 的 50%
-
BI 分析场景:E2E 端到端查询耗时相比初始减少 83%,完全满足业务需求
- 技术突破
-
新增包括Auto Partition/Unnest/Append2。0等600+功能,语法/性能方面无缝对接BigQuery
-
超大规模计划优化:支持百万级算子的执行计划解析,典型查询优化耗时从15分钟+降至1分钟
-
复杂类型深度优化:支持/完善复杂类型列裁剪/谓词下推/零拷贝等优化,典型case性能提升20倍
回顾本次GoTerra迁移至MaxCompute的性能优化过程,我们通过分阶段、分场景的持续优化,有效提升了BI、ETL等场景下的查询性能,圆满完成了迁移目标。面向未来,我们将结合 GoTerra 的业务需求和业界技术发展趋势,继续围绕"更快、更省、更稳"的目标,重点聚焦以下几个方向:
更快:持续深挖性能潜力,极致性能优化
-
增量更新:持续推进数据的增量更新机制,显著降低计算资源消耗,加快数据可用速度,提升用户操作体验。
-
地理类型原生支持:加强对地理空间数据类型的原生支持,结合空间索引,大幅提升时空数据复杂查询的执行效率,增强地理类业务的核心竞争力。
-
异构计算融合:探索异构计算(如GPU等)与MaxCompute的深度融合场景,进一步加快关键分析任务处理速度。
更省:精细化资源管理与成本优化
-
智能弹性伸缩:开发并完善基于实时负载的弹性资源调度机制,在业务波峰波谷场景下,实现资源的自动扩容和缩减,显著提升资源利用率,降低用户成本。
-
按需计费与成本监控:引入更为精细化的多维度资源计量体系和主动式成本告警,帮助用户按需选型,合理分配预算,避免资源浪费。
更稳:面向未来的高可用性和可观测性
-
容灾与高可用:构建多区域、多活的数据冗余与容错机制,提升系统面对硬件故障、大规模流量和异常情况时的业务连续性和可靠性。
-
完善可观测性:加强全链路的性能监控、SQL诊断和自动健康检查能力,实现故障早发现、早定位、快速自愈,保障核心业务稳定运行。
结语
GoTerra 跨国数仓迁移不仅为行业树立了数据平台升级与性能优化的技术标杆,也为 MaxCompute 实现世界一流性能奠定了坚实基础。在整个项目过程中,团队积累了针对大规模复杂场景的性能优化方法论、自动化工具链及通用实战经验,为后续跨地域、超大规模数据仓库系统的迁移提供了成熟范本和可复用经验。展望未来,MaxCompute 将持续深化性能驱动的技术创新。一方面,聚焦 AI 驱动的智能调优和自动化运维,不断提升系统的自适应资源调度、性能监控和异常自愈能力,进一步提高开发和运维效率;另一方面,将积极推动数据湖与数仓融合、原生地理类型/非结构化类型和增量计算等新方向,不断拓展性能优化的边界。通过持续的技术演进,MaxCompute 将为大规模数据场景下的企业提供更强的性能保障和更高的运维效率,加速业务价值释放,助力客户应对未来更为复杂的大数据挑战。