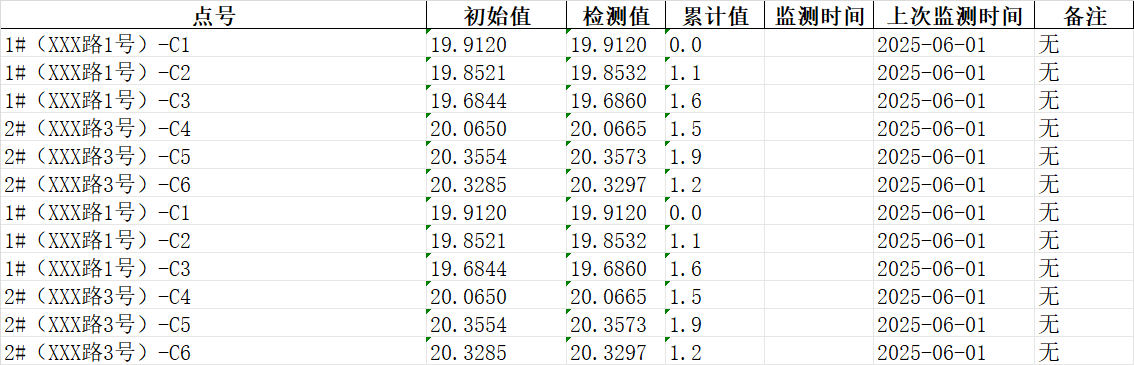
现有大量的Word文档,每个文档中有大量的表格,需要将其转换为Excel。
Python处理源码
python
# 需要安装pip install xlsxwriter
import pandas as pd
from docx import Document
from pathlib import Path
from datetime import datetime
def process_docx(filepath):
# 处理Word文档的主函数
doc = Document(filepath)
# 示例处理逻辑:提取所有段落文本
content = [p.text for p in doc.paragraphs if p.text.strip()]
print(f"成功处理文档: {filepath}")
data = []
monitor_time = ""
# 提取监测时间
for paragraph in doc.paragraphs:
# print(paragraph.text)
if "第12次:" in paragraph.text:
monitor_time = parse_monitor_time(paragraph.text)
print(f"提取监测时间: {monitor_time}")
break
# 处理所有表格
index = 0
for table in doc.tables:
# 检查是否为数据表格(包含房屋编号列)
if len(table.columns) >= 7 and "成果表" in table.cell(0,0).text:
# print(table.cell(0,0).text)
for row in table.rows[2:]: # 跳过标题行
first_cell_text = row.cells[0].text.strip() # 获取第一个单元格的文本并去除首尾空格
if "备注" in first_cell_text: # 如果第一个单元格包含"备注"
continue # 跳过该行
cells = [cell.text.replace("\n", "").replace("\r", "").strip() for cell in row.cells]
if len(cells) >= 7: # 确保数据完整
# 构建输出记录
record = {
'点号': f"{cells[0].replace(" ", "")}-{cells[1]}",
'初始值': cells[2],
'检测值': cells[3],
'累计值': cells[4],
'监测时间': monitor_time,
'上次监测时间': "2025/6/17 03:00" # 根据备注补充
}
# print(record)
data.append(record)
return data
def generate_excel(data, output_path):
# 生成标准格式Excel
df = pd.DataFrame(data)
# 补充固定字段
df['备注'] = '无'
# 字段顺序调整
columns_order = [ '点号', '初始值', '检测值', '累计值', '监测时间', '上次监测时间', '备注' ]
df = df.reindex(columns=columns_order)
# 填充空值
df['上次监测时间'] = '2025-06-01'
# 保存Excel
# df.to_excel(output_path, index=False)
with pd.ExcelWriter(output_path, engine='xlsxwriter') as writer:
df.to_excel(writer, index=False, sheet_name='Sheet1') # 导出数据
worksheet = writer.sheets['Sheet1']
# 手动设置列宽(单位:字符宽度)
worksheet.set_column('A:A', 38) # 设置A列为15字符宽度
worksheet.set_column('B:B', 12) # 设置B列为10字符宽度
print(f"Excel文件已生成: {output_path}")
print(f"Excel开始生成")
filepath=r"C:\Users\admin\Desktop\test.docx"
output_path=r"C:\Users\admin\Desktop\test.xlsx"
data = process_docx(filepath)
generate_excel(data, output_path)
print(f"Excel生成结束")输入Word文档
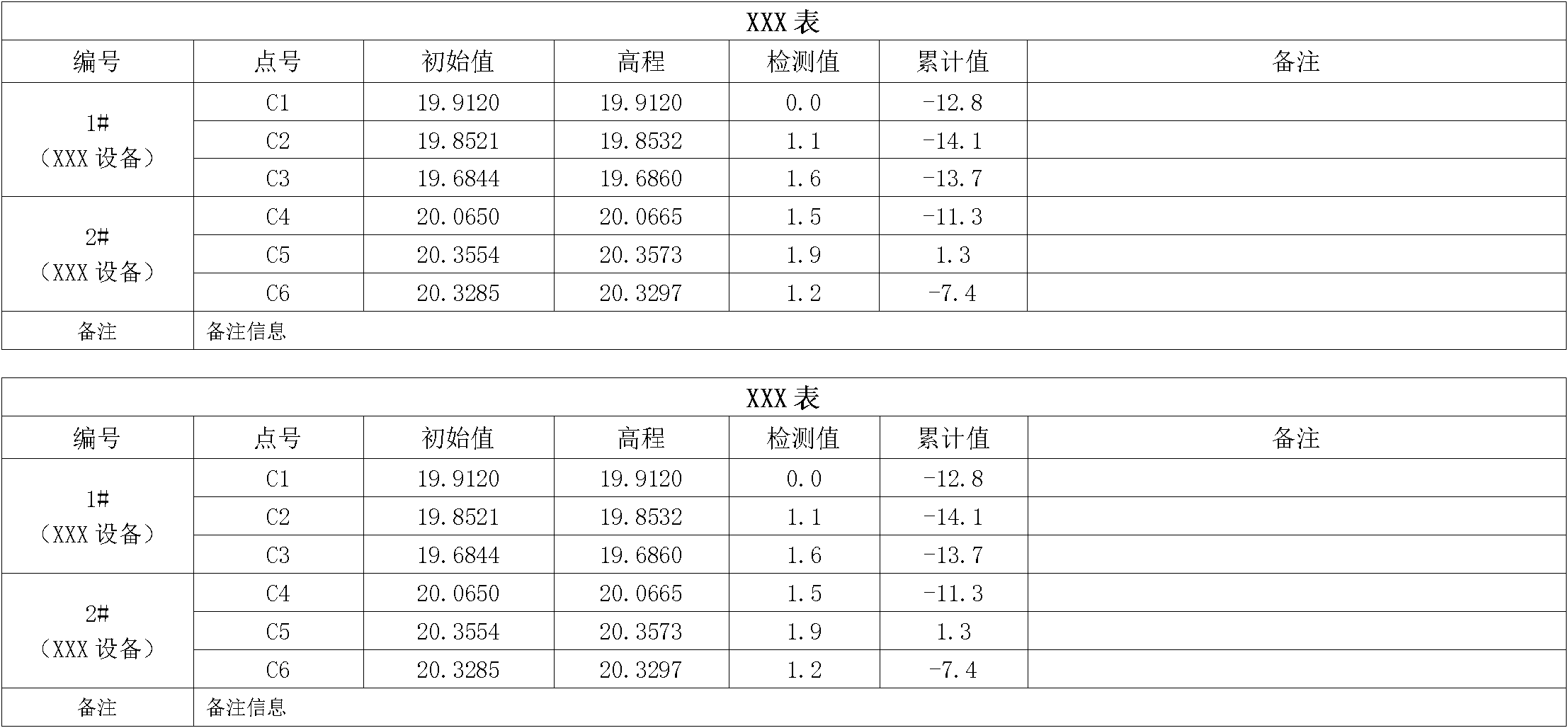
word文档格式如下所示
输出Excel文档