大家好,这里是架构资源栈 !点击上方关注,添加"星标",一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
在高性能系统中,优化一个非瓶颈点是没意义的。YDB 团队在使用 gRPC 做数据库接口通信时,就真实踩中了一个性能"陷阱":明明集群空闲,延迟却越来越高,吞吐也上不去,问题竟出在 gRPC 客户端上。
这不是"背锅侠"的锅,而是架构实现中的隐藏瓶颈。本文带大家复盘整个分析过程,并给出实战解决方案。
事情是怎么被发现的?
YDB 使用 gRPC 与客户端通信,因此压力测试、基准测试都依赖 gRPC 客户端。
但在测试中他们发现:
- 集群节点越少,越难打满负载;
- 集群资源明明空闲,客户端延迟却在上升;
- 吞吐并不线性增长。
于是,他们决定动手写个微基准程序排查。
gRPC 是怎么设计的?
gRPC 是基于 HTTP/2 的远程调用框架,内部会复用 TCP 连接并通过 stream 实现多路复用。一个 gRPC channel 对应一条 TCP 连接,每个 channel 可以发多个 stream。
但实际中出现了意想不到的行为:多个看似独立的 channel,如果没有设置不同的参数,gRPC 仍然会复用同一个 TCP 连接。
这就埋下了隐患:高并发场景下,请求排队、响应等待,最终客户端变成了性能瓶颈。
实验准备:构建微基准测试
YDB 团队写了一个 C++ 实现的 gRPC Ping 工具,基于最新版 gRPC(1.72.0):
- 服务端
grpc_ping_server使用异步 API 和 Completion Queue。 - 客户端
grpc_ping_client每个 worker 维持一个 inflight=1 的 RPC 调用,属于闭环模型(并发数 = worker 数)。
环境配置:
- 服务端和客户端部署在物理机上;
- 每台机都是 2 × Intel Xeon Gold 6338,50 Gbps 网络,极低延迟;
- 使用
taskset保证线程绑定到同一 NUMA 节点,提高稳定性。
初始测试结果:瓶颈很明显
测试方式如下:
shell
taskset -c 0-31 ./grpc_ping_client \
--host server-host \
--min-inflight 1 \
--max-inflight 48 \
--warmup 5 \
--interval 10 \
--with-csv结果如下:
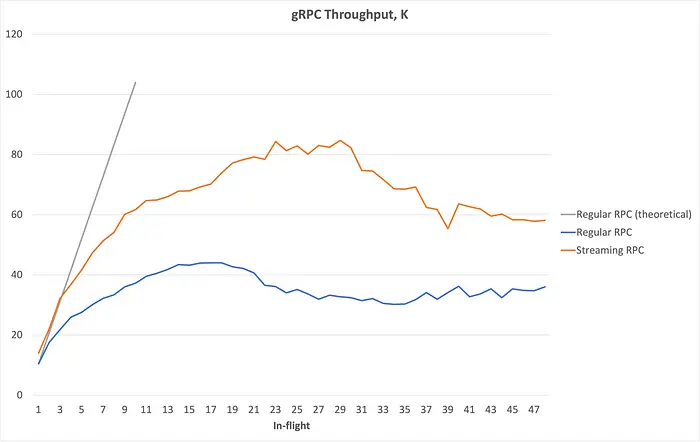
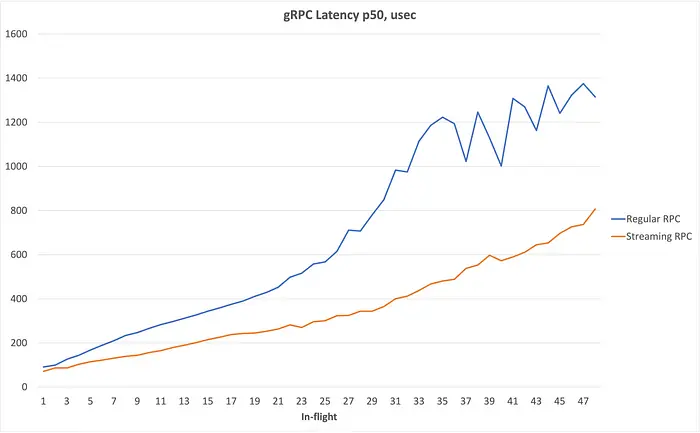
关键观察:
- 请求数翻了 10 倍,吞吐仅提升了 3.7 倍;
- 延迟几乎是线性增长;
- throughput 明显受 latency 限制。
换句话说,在超低延迟网络下,客户端变成了整个链路的拖油瓶。
问题定位过程
检查连接数
通过 lsof 发现:无论并发多大,只建立了一个 TCP 连接!
这说明:gRPC 默认行为是 channel 复用连接,即使多个线程并发也不例外。
抓包分析
使用 Wireshark 抓包,发现:
- 没有网络丢包;
- 没有 TCP 拥塞;
- TCP 窗口配置正常(64KiB);
- 请求响应都被 server 快速处理;
- 但在客户端 ACK 后,存在 150~200 微秒的空闲时间!
这说明,客户端在处理响应后,并没有立即发起下一次调用,即存在"内部空档期"。
探索优化方案:换多连接模式
尝试了如下两种改进方案:
- 每个 worker 拥有独立 gRPC channel;
- 使用不同参数初始化 channel,避免连接复用。
命令如下:
shell
taskset -c 0-31 ./grpc_ping_client \
--host server-host \
--min-inflight 1 \
--max-inflight 48 \
--warmup 5 \
--interval 10 \
--with-csv \
--local-pool其中 --local-pool 实际设置了 GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL 参数。
测试结果:
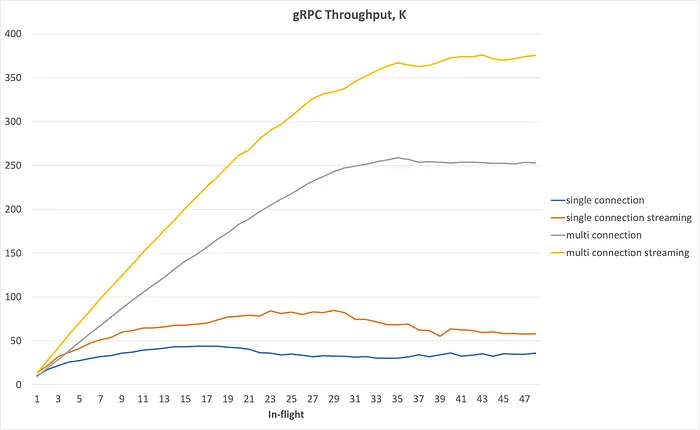
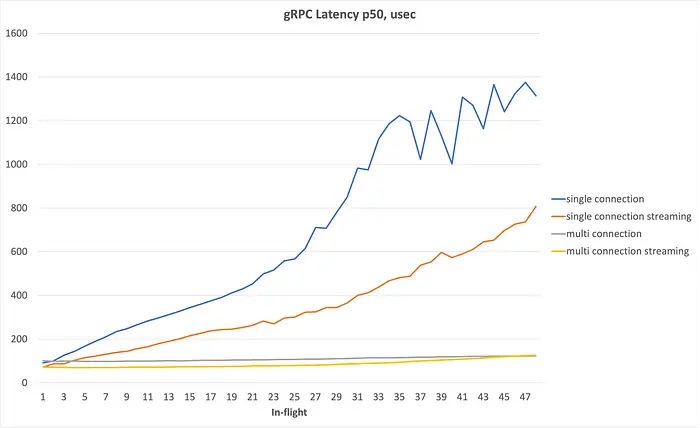
性能对比:
- 吞吐直接提升 6 倍;
- 延迟随着并发提升,仅小幅增长;
- CPU 使用率更高但更稳定。
这说明,问题确实出在 gRPC 的连接复用逻辑。
那高延迟网络下呢?
YDB 团队又在一个 5ms 延迟的网络中复测:
text
rtt min/avg/max/mdev = 5.100/5.246/5.336/0.048 ms对比结果如下:
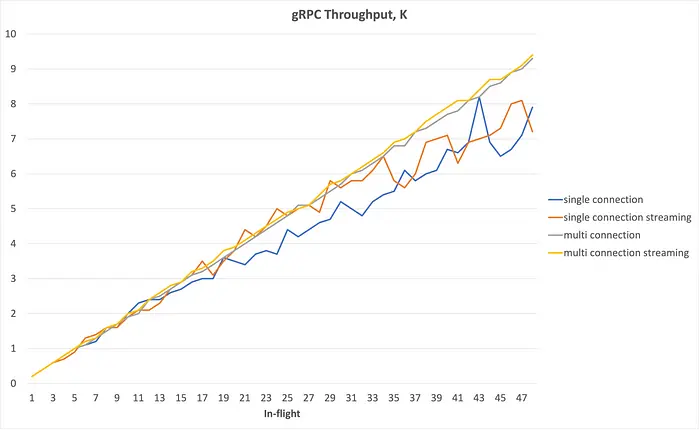
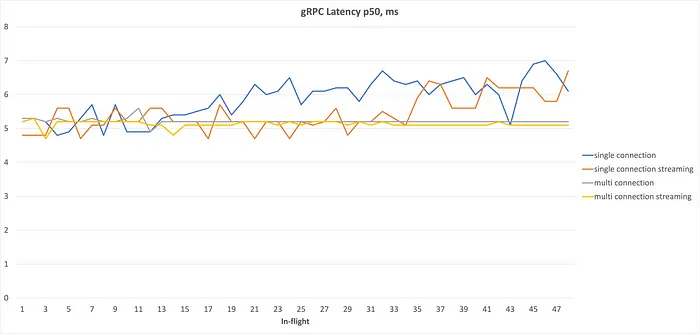
结论:
- 高延迟下的吞吐主要受 RTT 限制;
- 多连接的优势在低延迟网络中体现更明显。
最终结论:多连接才是真解
gRPC 官方文档提到的"多 channel"与"channel 池"优化方案,看似是两种策略,但实际是同一问题的两种不同表述:
- 如果你只用一个 channel,无论你怎么调参,它背后只有一个 TCP 连接;
- 想真正并发,需要多个 channel,并设置不同参数,或者使用
GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL避免连接复用。
这不是"技巧",而是性能调优的刚需。
总结:gRPC 客户端优化的硬核建议
- 别指望 gRPC 默认配置能打满你的服务端;
- 多个 channel、不同参数、不同连接,是高性能通信的前提;
- 在低延迟网络下,客户端瓶颈极其显著,必须关注;
- gRPC 的连接复用设计,在高性能场景中是一把双刃剑;
- 使用微基准(如本文中的 grpc_ping)做压力验证,是性能优化第一步。
谁能想到,在一个号称高性能的框架下,还能被"客户端只有一个连接"拖垮性能。
下次你写压测工具,别忘了检查连接数。否则,你不是在压服务,而是在压你自己。
更多架构实战、底层调优干货,欢迎关注:架构资源栈
本文由博客一文多发平台 OpenWrite 发布!