AI测试环境搭建与全栈工具实战:从本地到云平台的完整指南
在AI技术快速迭代的今天,一个稳定、高效且可扩展的测试环境是保障AI模型质量的基石。无论是数据验证、模型评估还是性能测试,全栈工具链的协同工作都至关重要。
本文将从零开始,详细指导如何搭建覆盖Python、Java和Vue的全栈AI测试环境,掌握核心工具的实操技巧,并实现从本地开发到云平台部署的全流程落地。
1. 本地开发环境搭建(Windows/Mac/Linux)
搭建跨平台的本地开发环境是全栈AI测试的基础。我们需要分别配置Python、Java和Vue三大技术栈,并通过Docker Compose实现协同工作。
1.1 Python环境配置:AI模型测试的核心引擎
Python作为AI领域的主流语言,需要配置支持深度学习框架、数据处理和测试工具的完整环境。
跨平台配置方案
Python环境的搭建需要考虑操作系统差异,但核心组件一致:虚拟环境管理工具+深度学习框架+数据科学库+测试工具。
是
否
操作系统选择
选择包管理器
Windows: Anaconda
Mac: Miniforge
Linux: Conda/Mamba
安装Anaconda3
创建虚拟环境
安装PyTorch/TensorFlow
安装核心AI库
验证环境
验证通过?
Python环境就绪
排查问题
详细配置步骤
-
安装包管理器
- Windows推荐使用Anaconda(完整发行版,适合新手)
- Mac/Linux推荐使用Miniforge(轻量版,启动更快)
-
创建专用虚拟环境
使用conda创建隔离的
ai-test环境,避免版本冲突:bashconda create -n ai-test python=3.9 -y conda activate ai-test -
配置国内镜像加速
为提升下载速度,配置清华镜像源:
bashconda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --set show_channel_urls yes -
安装深度学习框架
根据GPU是否可用自动选择版本(需NVIDIA显卡支持CUDA):
bash# 检测GPU可用性 if command -v nvidia-smi &> /dev/null; then # GPU版本 conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y pip install tensorflow-gpu==2.9.1 else # CPU版本 conda install pytorch torchvision torchaudio cpuonly -c pytorch -y pip install tensorflow==2.9.1 fi -
安装核心测试库
涵盖数据处理、质量校验、模型跟踪和性能测试:
bash# 数据科学基础库 conda install pandas numpy scipy scikit-learn matplotlib seaborn jupyter -y # 数据质量工具 pip install great-expectations==0.15.15 # 数据校验规则引擎 pip install evidently==0.1.51.dev0 # 模型监控与数据漂移检测 # 模型实验跟踪 pip install mlflow==1.28.0 # 实验记录与模型版本管理 # 性能测试工具 pip install locust==2.12.1 # 轻量级压测框架 # API服务框架 pip install fastapi uvicorn pydantic # 快速构建测试接口 -
环境验证
使用以下脚本验证关键组件是否正常工作:
python# verify_python_env.py import torch import tensorflow as tf import pandas as pd import great_expectations as ge import mlflow print(f"PyTorch版本: {torch.__version__}, GPU可用: {torch.cuda.is_available()}") print(f"TensorFlow版本: {tf.__version__}, GPU可用: {len(tf.config.list_physical_devices('GPU')) > 0}") print(f"Pandas版本: {pd.__version__}") print(f"Great Expectations版本: {ge.__version__}") print(f"MLflow版本: {mlflow.__version__}")
运行脚本后,若所有组件均正常输出版本信息且GPU状态符合预期,则Python环境配置完成。
1.2 Java环境配置:企业级AI测试的稳定支撑
Java凭借其稳定性和丰富的企业级库,在AI测试的后端服务、数据质量监控和高并发测试中发挥重要作用。
环境架构与组件
Java环境需要涵盖开发工具、深度学习框架、测试工具和服务框架,形成完整的企业级测试能力:
Java AI测试环境
JDK 11
构建工具
开发IDE
AI框架
测试工具
OpenJDK 11
Java Mission Control
VisualVM
Maven 3.8+
Gradle 7+
IntelliJ IDEA Ultimate
VS Code + Java扩展
Eclipse
Deeplearning4j DL4J
Apache Griffin
Spring Boot AI
JMeter 5.6
JUnit 5
TestContainers
详细配置步骤
-
安装JDK 11
-
Linux(Ubuntu/Debian):
bashsudo apt-get update && sudo apt-get install -y openjdk-11-jdk openjdk-11-jre -
Mac(使用Homebrew):
bashbrew install openjdk@11 echo 'export JAVA_HOME=$(/usr/libexec/java_home -v 11)' >> ~/.zshrc -
Windows:手动下载Eclipse Adoptium,并配置
JAVA_HOME环境变量。
-
-
安装Maven 3.8+
Maven用于依赖管理和项目构建:
-
Linux/Mac:
bash# Linux sudo apt-get install -y maven # Mac brew install maven -
验证安装:
mvn -v应输出3.8.x版本信息。
-
-
配置Maven镜像加速
修改
~/.m2/settings.xml,使用阿里云镜像提升依赖下载速度:xml<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"> <mirrors> <mirror> <id>aliyun</id> <name>Aliyun Maven Mirror</name> <url>https://maven.aliyun.com/repository/public</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> <activeProfiles> <activeProfile>ai-test</activeProfile> </activeProfiles> </settings> -
创建Java AI测试项目
使用Spring Boot初始化项目,核心依赖包括:
xml<!-- pom.xml 核心依赖片段 --> <dependencies> <!-- Spring Boot 基础 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- 深度学习框架 --> <dependency> <groupId>org.deeplearning4j</groupId> <artifactId>deeplearning4j-core</artifactId> <version>1.0.0-M2.1</version> </dependency> <!-- 数据质量工具 --> <dependency> <groupId>org.apache.griffin</groupId> <artifactId>griffin-measure</artifactId> <version>0.7.0</version> </dependency> <!-- 性能测试 --> <dependency> <groupId>org.apache.jmeter</groupId> <artifactId>ApacheJMeter_core</artifactId> <version>5.6</version> </dependency> <!-- 单元测试 --> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter</artifactId> <scope>test</scope> </dependency> </dependencies> -
环境验证
创建测试类验证DL4J环境是否正常:
java// AiTestExample.java import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertTrue; public class AiTestExample { @Test void testDL4JEnvironment() { try { org.nd4j.linalg.factory.Nd4j.create(1); // 初始化DL4J System.out.println("DL4J环境初始化成功"); assertTrue(true); } catch (Exception e) { System.err.println("DL4J环境异常: " + e.getMessage()); assertTrue(false); } } }
运行测试若通过,则Java环境配置完成。
1.3 Vue环境配置:AI测试结果的可视化前端
Vue3作为现代化前端框架,能快速构建交互式测试结果展示界面,结合可视化库实现数据指标的直观呈现。
前端测试架构
Vue环境需要整合UI组件库、可视化工具和测试框架,形成完整的前端测试平台:
Vue3 AI测试前端
开发工具
核心框架
UI组件库
可视化库
测试工具
构建工具
Node.js 16+
Vue CLI 5
VS Code + Volar
Vite 4
Vue 3.2+
Composition API
Vue Router 4
Pinia 2
Element Plus
Naive UI
Ant Design Vue
ECharts 5
Vue-ECharts
D3.js
Vue Test Utils
Jest
Cypress 12
Vitest
Vite
Webpack 5
Rollup
详细配置步骤
-
安装Node.js与包管理工具
使用nvm(Node版本管理器)安装Node.js 18(LTS版本):
bash# 安装nvm curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh | bash # 加载nvm并安装Node.js export NVM_DIR="$HOME/.nvm" [ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" nvm install 18 && nvm use 18 -
配置npm镜像加速
使用淘宝镜像提升依赖下载速度:
bashnpm config set registry https://registry.npmmirror.com/ -
创建Vue3项目
使用Vite快速构建项目(比Vue CLI启动更快):
bashnpm create vite@latest vue-ai-test -- --template vue-ts cd vue-ai-test npm install -
安装核心依赖
包括UI组件、可视化库、状态管理和路由:
bash# UI组件库 npm install element-plus @element-plus/icons-vue # 可视化库 npm install echarts vue-echarts # 状态管理与路由 npm install pinia vue-router@4 # HTTP客户端 npm install axios -
配置测试工具
安装单元测试和端到端测试工具:
bash# 单元测试 npm install -D jest @vue/test-utils # 端到端测试 npm install -D cypress @cypress/vue -
创建示例可视化组件
实现AI测试指标的图表展示(以ECharts为例):
vue<!-- TestMetricsChart.vue --> <template> <div ref="chartRef" style="width: 100%; height: 400px;"></div> </template> <script setup lang="ts"> import { ref, onMounted } from 'vue' import * as echarts from 'echarts' const chartRef = ref<HTMLElement>() onMounted(() => { if (chartRef.value) { const chart = echarts.init(chartRef.value) // 配置图表数据(AI测试指标:准确率、响应时间等) chart.setOption({ title: { text: 'AI模型测试指标' }, xAxis: { type: 'category', data: ['模型A', '模型B', '模型C'] }, yAxis: [{ type: 'value', name: '准确率(%)' }], series: [{ name: '准确率', type: 'bar', data: [89.2, 92.5, 91.8] }] }) } }) </script> -
启动开发服务器
bashnpm run dev访问
http://localhost:3000,若能看到测试页面和图表,则Vue环境配置完成。
1.4 协同环境:Docker Compose全栈工作台
通过Docker Compose可以将Python、Java、Vue服务及依赖的中间件(数据库、缓存、消息队列)编排为一个整体,实现"一键启动"全栈测试环境。
全栈架构设计
完整的AI测试平台包含前端展示、后端服务、AI计算、数据存储和监控等模块:
Docker Compose Stack
AI测试平台
前端服务
Java后端服务
Python AI服务
数据库服务
消息队列服务
缓存服务
监控服务
Vue 3 + Vite
Nginx
Spring Boot
DL4J
JMeter
FastAPI
PyTorch/TensorFlow
MLflow
MySQL 8
MongoDB
Kafka
Redis Stream
Redis
Memcached
Prometheus
Grafana
Jaeger
Docker Compose配置
创建docker-compose.yml文件,定义所有服务:
yaml
version: '3.8'
# 网络配置
networks:
ai-test-network:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16
# 数据卷(持久化存储)
volumes:
mysql_data:
redis_data:
kafka_data:
mlflow_data:
grafana_data:
services:
# 1. 前端服务(Vue)
vue-frontend:
build: ./vue-frontend
ports:
- "3000:80"
environment:
- VUE_APP_API_URL=http://localhost:8080/api
- VUE_APP_PYTHON_API_URL=http://localhost:5000
depends_on:
- java-backend
- python-ai-service
networks:
ai-test-network:
ipv4_address: 172.20.0.10
# 2. Java后端服务
java-backend:
build: ./java-backend
ports:
- "8080:8080"
environment:
- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/ai_test
- SPRING_REDIS_HOST=redis
- KAFKA_BOOTSTRAP_SERVERS=kafka:9092
depends_on:
- mysql
- redis
- kafka
networks:
ai-test-network:
ipv4_address: 172.20.0.20
# 3. Python AI服务
python-ai-service:
build: ./python-ai-service
ports:
- "5000:5000" # FastAPI接口
- "5001:5001" # MLflow跟踪服务器
environment:
- MYSQL_HOST=mysql
- REDIS_HOST=redis
- MLFLOW_TRACKING_URI=http://localhost:5001
volumes:
- ai_models:/app/models # 模型存储
- mlflow_data:/app/mlflow # 实验数据
deploy:
resources:
reservations:
devices:
- driver: nvidia # 启用GPU支持
count: all
capabilities: [gpu]
networks:
ai-test-network:
ipv4_address: 172.20.0.30
# 4. 数据库(MySQL)
mysql:
image: mysql:8.0
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=ai_test_password
- MYSQL_DATABASE=ai_test
volumes:
- mysql_data:/var/lib/mysql
networks:
ai-test-network:
ipv4_address: 172.20.0.40
# 5. 缓存(Redis)
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
networks:
ai-test-network:
ipv4_address: 172.20.0.50
# 6. 消息队列(Kafka + Zookeeper)
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
environment:
- ZOOKEEPER_CLIENT_PORT=2181
networks:
ai-test-network:
ipv4_address: 172.20.0.60
kafka:
image: confluentinc/cp-kafka:7.3.0
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092
volumes:
- kafka_data:/var/lib/kafka/data
networks:
ai-test-network:
ipv4_address: 172.20.0.70
# 7. 监控服务(Grafana + Prometheus)
prometheus:
image: prom/prometheus:v2.42.0
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
networks:
ai-test-network:
ipv4_address: 172.20.0.80
grafana:
image: grafana/grafana:9.4.7
ports:
- "3001:3000"
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
networks:
ai-test-network:
ipv4_address: 172.20.0.90启动与验证
在docker-compose.yml所在目录执行:
bash
# 构建并启动所有服务
docker-compose up -d --build
# 查看服务状态
docker-compose ps
# 查看日志(例如Python服务)
docker-compose logs -f python-ai-service所有服务启动后,可通过以下地址访问各组件:
- 前端界面:
http://localhost:3000 - Java后端API:
http://localhost:8080/api - Python AI服务:
http://localhost:5000 - MLflow实验跟踪:
http://localhost:5001 - Grafana监控:
http://localhost:3001
2. 核心工具入门实操(全栈并行)
全栈AI测试需要多工具协同工作,覆盖数据质量、模型评估、性能测试和前端验证等全流程。
2.1 数据质量工具:确保AI输入的可靠性
数据质量是AI模型效果的基础,需要通过规则定义、血缘追踪和可视化配置实现全链路管控。
工具链协同流程
数据源
Great Expectations
Python: 定义校验规则
规则存储
MySQL
Apache Griffin
Java: 血缘追踪与批量校验
校验结果
Kafka消息队列
Vue前端
配置界面与结果展示
数据质量报告
实操步骤
-
Great Expectations:定义数据校验规则
用Python定义数据期望(如字段范围、非空校验等):
python# data_validation.py import great_expectations as ge import pandas as pd # 加载数据 df = pd.read_csv("test_data.csv") df_ge = ge.from_pandas(df) # 定义期望(规则) df_ge.expect_column_values_to_not_be_null("user_id") # user_id非空 df_ge.expect_column_values_to_be_between( "age", min_value=0, max_value=120 # age在0-120之间 ) df_ge.expect_column_unique("email") # email唯一 # 执行校验 result = df_ge.validate() # 输出结果 if result["success"]: print("数据质量校验通过") else: print("数据质量问题:") for error in result["results"]: if not error["success"]: print(f"- {error['expectation_config']['expectation_type']} 失败") # 保存规则到JSON(供后续复用) df_ge.save_expectation_suite("data_expectations.json") -
Apache Griffin:数据血缘与批量校验
用Java实现分布式数据质量监控,追踪数据流转链路:
java// DataQualityChecker.java import org.apache.griffin.measure.context.MeasureContext; import org.apache.griffin.measure.context.streaming.StreamingContext; import org.apache.griffin.measure.job.builder.MeasureJobBuilder; public class DataQualityChecker { public static void main(String[] args) { // 初始化Griffin上下文 MeasureContext context = new StreamingContext("ai-test-quality"); // 加载Great Expectations规则(JSON格式) String expectationJson = readExpectationFile("data_expectations.json"); // 构建质量校验任务 MeasureJobBuilder jobBuilder = new MeasureJobBuilder(context); jobBuilder.buildFromJson(expectationJson); // 执行批量校验(可对接Kafka/Spark) context.submit(); // 输出校验结果到Kafka context.getResultSender().sendResults(); } } -
Vue配置界面:可视化规则管理
实现数据校验规则的增删改查界面,与后端API交互:
vue<!-- DataQualityRules.vue --> <template> <el-card> <el-table :data="rules"> <el-table-column prop="id" label="规则ID"></el-table-column> <el-table-column prop="type" label="规则类型"></el-table-column> <el-table-column prop="column" label="校验字段"></el-table-column> <el-table-column prop="status" label="状态"></el-table-column> <el-table-column label="操作"> <template #default="scope"> <el-button @click="editRule(scope.row)">编辑</el-button> <el-button type="danger" @click="deleteRule(scope.row.id)">删除</el-button> </template> </el-table-column> </el-table> <!-- 规则编辑弹窗 --> <el-dialog v-model="dialogVisible" title="编辑规则"> <el-form :model="currentRule"> <el-form-item label="规则类型"> <el-select v-model="currentRule.type"> <el-option label="非空校验" value="not_null"></el-option> <el-option label="范围校验" value="range"></el-option> <el-option label="唯一性校验" value="unique"></el-option> </el-select> </el-form-item> <!-- 其他表单字段 --> </el-form> <template #footer> <el-button @click="dialogVisible = false">取消</el-button> <el-button type="primary" @click="saveRule">保存</el-button> </template> </el-dialog> </el-card> </template> <script setup> import { ref, onMounted } from 'vue' import axios from 'axios' const rules = ref([]) const dialogVisible = ref(false) const currentRule = ref({}) // 加载规则列表 const loadRules = async () => { const res = await axios.get('/api/data-quality/rules') rules.value = res.data } // 保存规则 const saveRule = async () => { await axios.post('/api/data-quality/rules', currentRule.value) dialogVisible.value = false loadRules() } onMounted(loadRules) </script>
2.2 模型评估工具:量化AI模型的性能
模型评估需要跟踪实验过程、计算关键指标,并通过可视化报告直观呈现模型效果。
工具链协同流程
训练数据
模型训练
PyTorch/TensorFlow
MLflow
Python: 实验跟踪
模型指标
准确率/召回率等
DL4J Evaluation
Java: 指标计算
评估结果存储
MySQL/MongoDB
Vue前端
评估报告可视化
实操步骤
-
MLflow:实验跟踪与模型版本管理
记录模型训练过程中的参数、指标和 artifacts:
python# model_training.py import mlflow import torch from sklearn.metrics import accuracy_score, precision_score # 初始化MLflow mlflow.set_tracking_uri("http://localhost:5001") mlflow.set_experiment("credit-risk-model") # 启动实验跟踪 with mlflow.start_run(run_name="random-forest-v1"): # 记录参数 mlflow.log_param("n_estimators", 100) mlflow.log_param("max_depth", 5) # 模拟模型训练(实际项目中替换为真实训练逻辑) X_train, y_train = load_data() model = train_model(X_train, y_train) # 评估模型 y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred) # 记录指标 mlflow.log_metric("accuracy", accuracy) mlflow.log_metric("precision", precision) # 保存模型 mlflow.sklearn.log_model(model, "model") print(f"训练完成 - 准确率: {accuracy:.4f}") -
DL4J Evaluation:Java模型指标计算
对Java部署的模型进行评估,计算标准化指标:
java// ModelEvaluator.java import org.deeplearning4j.eval.Evaluation; import org.nd4j.linalg.api.ndarray.INDArray; import org.nd4j.linalg.dataset.DataSet; public class ModelEvaluator { public static void evaluateModel(MyDL4JModel model, DataSet testData) { // 初始化评估器 Evaluation eval = new Evaluation(10); // 10个类别 // 迭代测试数据 INDArray features = testData.getFeatures(); INDArray labels = testData.getLabels(); // 模型预测 INDArray predictions = model.output(features); // 更新评估结果 eval.eval(labels, predictions); // 输出指标 System.out.println("准确率: " + eval.accuracy()); System.out.println("精确率: " + eval.precision()); System.out.println("召回率: " + eval.recall()); // 保存评估结果到数据库 saveEvaluationResults(eval.stats()); } } -
Vue评估报告:可视化模型对比
展示不同模型版本的指标对比,支持交互式分析:
vue<!-- ModelEvaluationReport.vue --> <template> <el-row> <el-col :span="12"> <el-card> <template #header>模型准确率对比</template> <div ref="accuracyChart" style="height: 300px;"></div> </el-card> </el-col> <el-col :span="12"> <el-card> <template #header>混淆矩阵</template> <div ref="confusionMatrix" style="height: 300px;"></div> </el-card> </el-col> </el-row> </template> <script setup> import { ref, onMounted } from 'vue' import * as echarts from 'echarts' import axios from 'axios' const accuracyChart = ref() const confusionMatrix = ref() onMounted(async () => { // 获取模型评估数据 const res = await axios.get('/api/model-evaluation/latest') const data = res.data // 绘制准确率对比图 const accChart = echarts.init(accuracyChart.value) accChart.setOption({ xAxis: { type: 'category', data: data.modelVersions }, yAxis: { type: 'value', max: 1 }, series: [{ name: '准确率', type: 'line', data: data.accuracyScores }] }) // 绘制混淆矩阵 const cmChart = echarts.init(confusionMatrix.value) cmChart.setOption({ tooltip: { trigger: 'item' }, series: [{ type: 'heatmap', data: data.confusionMatrix, label: { show: true } }] }) }) </script>
2.3 性能测试工具:验证AI系统的稳定性
AI系统不仅需要高精度,还需要在高并发场景下保持稳定,性能测试工具可模拟真实负载并分析瓶颈。
工具链协同流程
测试场景定义
Locust
Python: 轻量API压测
JMeter
Java: 高并发场景
压测结果
响应时间/吞吐量
结果聚合
Kafka/Redis
Vue前端
性能指标可视化
性能瓶颈分析报告
实操步骤
-
Locust:Python轻量级API压测
编写简单脚本模拟用户请求,测试AI服务接口:
python# locustfile.py from locust import HttpUser, task, between class AIServiceUser(HttpUser): wait_time = between(1, 3) # 每次请求间隔1-3秒 @task(3) # 权重3,执行频率更高 def predict_single(self): # 单个预测请求 self.client.post( "/api/predict", json={"feature1": 0.5, "feature2": 0.3, "feature3": 0.8} ) @task(1) # 权重1,执行频率较低 def batch_predict(self): # 批量预测请求 self.client.post( "/api/batch-predict", json={ "features": [ {"feature1": 0.5, "feature2": 0.3, "feature3": 0.8}, {"feature1": 0.2, "feature2": 0.7, "feature3": 0.1} ] } )启动Locust服务:
bashlocust -f locustfile.py --host=http://localhost:5000访问
http://localhost:8089配置并发用户数和增长率,开始压测。 -
JMeter:Java高并发场景测试
对于复杂场景(如分布式压测、协议级测试),使用JMeter:
- 创建测试计划,添加线程组(设置并发用户数)
- 配置HTTP请求默认值(目标服务器:
http://python-ai-service:5000) - 添加HTTP请求采样器(路径:
/api/predict,方法:POST) - 添加监听器(如"汇总报告"、"响应时间图表")
- 运行测试并分析结果
也可通过Java代码调用JMeter引擎:
java// JMeterTestRunner.java import org.apache.jmeter.engine.StandardJMeterEngine; import org.apache.jmeter.save.SaveService; import org.apache.jmeter.util.JMeterUtils; import org.apache.jorphan.collections.HashTree; public class JMeterTestRunner { public static void runTest(String testPlanPath) throws Exception { // 初始化JMeter JMeterUtils.loadJMeterProperties("jmeter.properties"); JMeterUtils.setJMeterHome("/path/to/jmeter"); // 加载测试计划 HashTree testPlanTree = SaveService.loadTree(new File(testPlanPath)); // 运行测试 StandardJMeterEngine jmeter = new StandardJMeterEngine(); jmeter.configure(testPlanTree); jmeter.run(); } } -
Vue性能看板:实时监控压测指标
实时展示响应时间、吞吐量、错误率等关键指标:
vue<!-- PerformanceDashboard.vue --> <template> <el-card> <template #header>AI服务性能指标</template> <el-row :gutter="20"> <el-col :span="6"> <el-statistic title="平均响应时间" :value="avgResponseTime" :precision="2" value-style="{ color: avgResponseTime > 500 ? 'red' : 'green' }" > <template #suffix>ms</template> </el-statistic> </el-col> <el-col :span="6"> <el-statistic title="吞吐量" :value="throughput" suffix="req/sec"></el-statistic> </el-col> <el-col :span="6"> <el-statistic title="错误率" :value="errorRate" :precision="2" suffix="%"></el-statistic> </el-col> <el-col :span="6"> <el-statistic title="并发用户" :value="concurrentUsers"></el-statistic> </el-col> </el-row> <div ref="performanceChart" style="height: 400px; margin-top: 20px;"></div> </el-card> </template> <script setup> import { ref, onMounted, watch } from 'vue' import * as echarts from 'echarts' import { useWebSocket } from '@/composables/useWebSocket' // 性能指标 const avgResponseTime = ref(0) const throughput = ref(0) const errorRate = ref(0) const concurrentUsers = ref(0) const performanceChart = ref() let chartInstance = null // 通过WebSocket实时获取性能数据 const { data } = useWebSocket('ws://localhost:8080/ws/performance') watch(data, (newData) => { if (newData) { avgResponseTime.value = newData.avgResponseTime throughput.value = newData.throughput errorRate.value = newData.errorRate concurrentUsers.value = newData.concurrentUsers // 更新图表 updateChart(newData) } }) const updateChart = (data) => { if (!chartInstance) return chartInstance.appendData({ seriesIndex: 0, data: [[data.timestamp, data.avgResponseTime]] }) // 保持图表只显示最近100个数据点 if (chartInstance.getOption().series[0].data.length > 100) { chartInstance.setOption({ series: [{ data: chartInstance.getOption().series[0].data.slice(-100) }] }) } } onMounted(() => { chartInstance = echarts.init(performanceChart.value) chartInstance.setOption({ xAxis: { type: 'time' }, yAxis: { type: 'value', name: '响应时间(ms)' }, series: [{ type: 'line', data: [] }] }) }) </script>
2.4 前端测试工具:保障UI交互的稳定性
前端作为用户直接接触的层,需要通过单元测试和端到端测试确保交互逻辑正确。
工具链与测试类型
Vue前端测试
单元测试
Vue Test Utils + Jest
组件测试
Vitest
端到端测试
Cypress
组件逻辑测试
工具函数测试
组件渲染测试
事件响应测试
用户流程测试
跨页面交互测试
实操步骤
-
Vue Test Utils:组件单元测试
测试组件的渲染逻辑和交互行为:
javascript// AiTestDashboard.spec.js import { mount } from '@vue/test-utils' import AiTestDashboard from '@/components/AiTestDashboard.vue' describe('AiTestDashboard', () => { it('渲染正确的标题', () => { const wrapper = mount(AiTestDashboard) expect(wrapper.find('h1').text()).toBe('AI测试平台') }) it('包含4个菜单项', () => { const wrapper = mount(AiTestDashboard) const menuItems = wrapper.findAll('.el-menu-item') expect(menuItems.length).toBe(4) expect(menuItems[0].text()).toContain('数据质量') }) it('点击菜单项触发路由跳转', async () => { const mockRouterPush = jest.fn() const wrapper = mount(AiTestDashboard, { global: { mocks: { $router: { push: mockRouterPush } } } }) // 点击第二个菜单项 await wrapper.findAll('.el-menu-item')[1].trigger('click') // 验证路由跳转是否正确 expect(mockRouterPush).toHaveBeenCalledWith('/model-evaluation') }) }) -
Cypress:端到端测试
模拟真实用户操作,测试完整业务流程:
javascript// model_evaluation.spec.cy.js describe('模型评估流程', () => { it('访问评估页面并查看报告', () => { // 访问登录页并登录 cy.visit('/login') cy.get('input[name=username]').type('admin') cy.get('input[name=password]').type('password') cy.get('button[type=submit]').click() // 导航到模型评估页面 cy.get('.el-menu-item').contains('模型评估').click() // 验证页面元素 cy.url().should('include', '/model-evaluation') cy.get('h2').should('contain', '模型评估报告') // 选择模型版本并查看详情 cy.get('.el-select').click() cy.get('.el-select-dropdown__item').contains('v2.1').click() cy.get('.accuracy-score').should('exist') // 导出报告 cy.get('button').contains('导出报告').click() cy.verifyDownload('model-evaluation-report.pdf') }) })
2.5 容器化工具:标准化部署与环境一致性
通过Docker将各组件打包为容器,确保开发、测试和生产环境的一致性。
容器化流程
源代码
编写Dockerfile
Python/Java/Vue
构建镜像
docker build
本地测试
docker run
推送镜像仓库
Docker Hub/私有仓库
部署到环境
docker-compose/k8s
实操步骤
-
Python服务Dockerfile
dockerfile# python-ai-service/Dockerfile FROM python:3.9-slim # 设置工作目录 WORKDIR /app # 安装依赖 COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 复制代码 COPY . . # 暴露端口 EXPOSE 5000 5001 # 启动命令(同时启动FastAPI和MLflow) CMD ["sh", "-c", "mlflow server --host 0.0.0.0 --port 5001 & uvicorn main:app --host 0.0.0.0 --port 5000"] -
Java服务Dockerfile
dockerfile# java-backend/Dockerfile # 构建阶段 FROM maven:3.8-openjdk-11 AS builder WORKDIR /app COPY pom.xml . COPY src ./src RUN mvn package -DskipTests # 运行阶段 FROM openjdk:11-jre-slim WORKDIR /app COPY --from=builder /app/target/*.jar app.jar EXPOSE 8080 CMD ["java", "-jar", "app.jar"] -
Vue前端Dockerfile
dockerfile# vue-frontend/Dockerfile # 构建阶段 FROM node:18-alpine AS builder WORKDIR /app COPY package*.json ./ RUN npm install COPY . . RUN npm run build # 运行阶段(Nginx) FROM nginx:alpine COPY --from=builder /app/dist /usr/share/nginx/html COPY nginx.conf /etc/nginx/conf.d/default.conf EXPOSE 80 CMD ["nginx", "-g", "daemon off;"] -
构建与测试镜像
bash# 构建Python镜像 docker build -t ai-test-python-service:v1 ./python-ai-service # 构建Java镜像 docker build -t ai-test-java-service:v1 ./java-backend # 构建Vue镜像 docker build -t ai-test-vue-frontend:v1 ./vue-frontend # 测试Python服务 docker run -p 5000:5000 ai-test-python-service:v1
3. 云环境部署:弹性扩展的AI测试平台
本地环境适合开发和小规模测试,而云平台能提供弹性GPU资源、高可用架构和全球化部署能力。
3.1 云平台选择与架构设计
三大主流云平台(AWS、Azure、GCP)均提供完善的AI测试支持,核心架构如下:
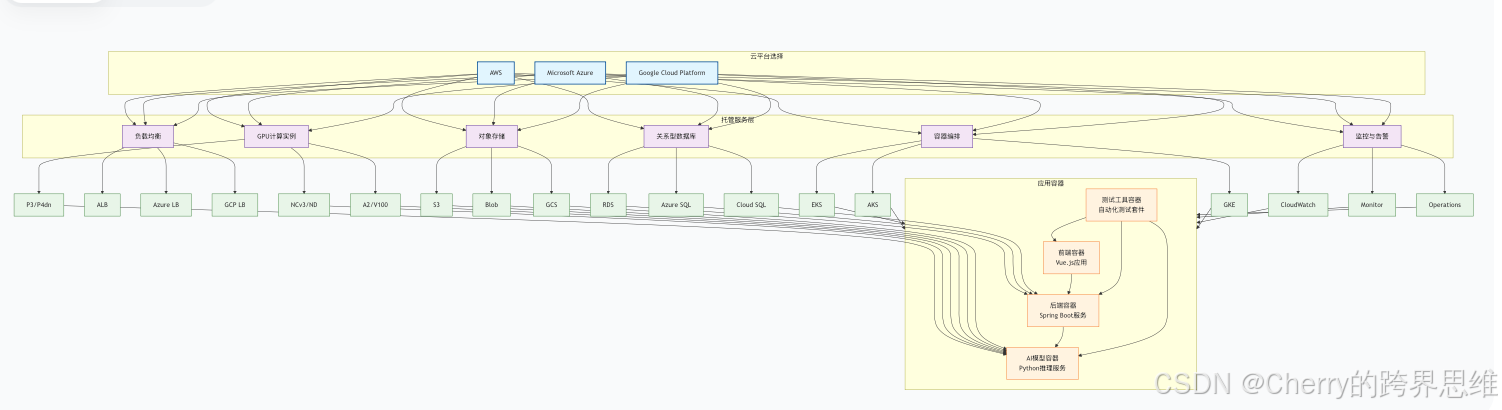
核心云服务选择
| 服务类型 | AWS | Azure | GCP |
|---|---|---|---|
| 容器编排 | Amazon EKS | Azure AKS | Google GKE |
| GPU实例 | P3/V3实例 | NC/ND系列虚拟机 | A2/N1实例 |
| 托管数据库 | Amazon RDS for MySQL | Azure Database for MySQL | Cloud SQL for MySQL |
| 对象存储 | Amazon S3 | Azure Blob Storage | Google Cloud Storage |
| 监控 | CloudWatch | Azure Monitor | Cloud Monitoring |
| CI/CD | AWS CodePipeline | Azure DevOps | Cloud Build |
3.2 部署流程(以AWS为例)
-
准备基础设施(Terraform)
使用Terraform定义AWS资源,实现基础设施即代码(IaC):
hcl# main.tf provider "aws" { region = "cn-northwest-1" } # VPC与网络配置 module "vpc" { source = "terraform-aws-modules/vpc/aws" name = "ai-test-vpc" cidr = "10.0.0.0/16" azs = ["cn-northwest-1a", "cn-northwest-1b"] private_subnets = ["10.0.1.0/24", "10.0.2.0/24"] public_subnets = ["10.0.101.0/24", "10.0.102.0/24"] } # EKS集群(容器编排) module "eks" { source = "terraform-aws-modules/eks/aws" cluster_name = "ai-test-eks" cluster_version = "1.24" vpc_id = module.vpc.vpc_id subnet_ids = module.vpc.private_subnets # 节点组配置(包含GPU节点) node_groups = { general = { desired_capacity = 2 instance_types = ["m5.large"] } gpu = { desired_capacity = 1 instance_types = ["p3.2xlarge"] # GPU实例 labels = { role = "gpu-worker" } } } } # RDS MySQL数据库 resource "aws_db_instance" "ai_test_db" { allocated_storage = 50 storage_type = "gp2" engine = "mysql" engine_version = "8.0" instance_class = "db.t3.medium" db_name = "ai_test" username = "admin" password = "secure_password" vpc_security_group_ids = [aws_security_group.db.id] skip_final_snapshot = true } -
部署应用到EKS
使用Kubernetes manifests定义应用部署:
yaml# k8s/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: python-ai-service spec: replicas: 2 selector: matchLabels: app: python-ai template: metadata: labels: app: python-ai spec: nodeSelector: role: gpu-worker # 调度到GPU节点 containers: - name: python-ai image: ${ECR_REPO}/ai-test-python-service:v1 resources: limits: nvidia.com/gpu: 1 # 请求1个GPU ports: - containerPort: 5000 env: - name: MYSQL_HOST valueFrom: secretKeyRef: name: db-credentials key: host --- # 其他服务部署(Java、Vue等)类似 -
配置自动扩展
根据CPU/内存使用率自动调整Pod数量:
yaml# k8s/hpa.yaml apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: python-ai-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: python-ai-service minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Resource resource: name: memory target: type: Utilization averageUtilization: 80 -
配置CI/CD流水线
使用AWS CodePipeline实现代码提交后自动构建、测试和部署:
- 源代码存储:GitHub/AWS CodeCommit
- 构建阶段:CodeBuild编译代码并推送到ECR
- 部署阶段:更新EKS中的应用镜像
4. 实战:一键启动全栈AI测试环境
通过Docker Compose实现"数据校验+模型评估+性能测试+前端展示"的全流程自动化,只需一条命令即可启动完整环境。
4.1 实战环境架构
启动命令
docker-compose up
初始化服务
数据库/缓存/消息队列
启动后端服务
Python+Java
数据校验流程
Great Expectations+Griffin
模型评估流程
MLflow+DL4J
性能测试流程
Locust+JMeter
结果存储
MySQL/Redis
前端服务
Vue展示
全栈测试平台就绪
4.2 完整操作步骤
-
准备项目结构
ai-test-platform/ ├── docker-compose.yml # 服务编排配置 ├── python-ai-service/ # Python AI服务 │ ├── Dockerfile │ ├── main.py # FastAPI接口 │ ├── data_validation.py # Great Expectations逻辑 │ └── model_training.py # MLflow实验跟踪 ├── java-backend/ # Java后端服务 │ ├── Dockerfile │ ├── pom.xml │ └── src/ # Griffin+DL4J逻辑 ├── vue-frontend/ # Vue前端 │ ├── Dockerfile │ └── src/ # 可视化界面 ├── mysql/ # 数据库初始化脚本 │ └── init.sql └── prometheus.yml # 监控配置 -
启动全栈环境
bash# 克隆项目(假设已存在) git clone https://github.com/your-org/ai-test-platform.git cd ai-test-platform # 启动所有服务 docker-compose up -d --build # 查看启动日志 docker-compose logs -f -
执行完整测试流程
- 数据校验 :访问
http://localhost:3000/data-quality,上传测试数据并执行校验 - 模型评估 :在
http://localhost:3000/model-evaluation选择模型版本,生成评估报告 - 性能测试 :进入
http://localhost:3000/performance-test,配置并发用户并启动压测 - 查看监控 :访问
http://localhost:3001(Grafana),查看系统资源使用情况
- 数据校验 :访问
-
停止环境
bash# 停止服务(保留数据) docker-compose down # 停止服务并删除数据卷 docker-compose down -v
5. 踩坑指南:常见问题与解决方案
全栈AI测试环境搭建涉及多语言、多工具协同,容易出现版本冲突、配置错误等问题,以下是常见坑点及解决方法。
5.1 工具版本冲突
问题1:Python TensorFlow与Java DL4J版本不兼容
- 现象:模型在Python中训练后,无法在Java DL4J中加载
- 原因:TensorFlow与DL4J支持的模型格式版本不匹配
- 解决方案:
-
使用统一的ONNX格式进行模型转换:
python# Python中导出为ONNX import tf2onnx tf.saved_model.save(model, "tf_model") !python -m tf2onnx.convert --saved-model tf_model --output model.onnx -
DL4J加载ONNX模型:
javaONNXParser parser = new ONNXParser(); MultiLayerNetwork model = new MultiLayerNetwork(parser.parseModel(new File("model.onnx"))); -
参考DL4J官方兼容性矩阵选择匹配版本
-
问题2:Vue依赖版本冲突
- 现象:
npm install时报错,或运行时出现module not found - 解决方案:
-
删除
node_modules和package-lock.json,重新安装 -
锁定核心依赖版本:
json// package.json "dependencies": { "vue": "3.2.45", // 固定版本号 "vue-router": "4.1.6", "element-plus": "2.3.4" }
-
5.2 GPU驱动配置
问题1:NVIDIA驱动与CUDA版本不匹配
- 现象:PyTorch/TensorFlow无法识别GPU,报错
CUDA driver version is insufficient - 解决方案:
-
查看CUDA要求的驱动版本:
bash# 例如CUDA 11.3需要465.19.01及以上驱动 -
安装匹配的驱动:
- Ubuntu:
sudo apt-get install nvidia-driver-470 - Windows:通过NVIDIA官网下载对应驱动
- Ubuntu:
-
问题2:Docker容器无法访问GPU
- 现象:容器内
nvidia-smi命令找不到,PyTorch显示cuda.is_available()=False - 解决方案:
-
安装NVIDIA Container Toolkit:
bashdistribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker -
启动容器时添加
--gpus all参数:bashdocker run --gpus all -p 5000:5000 ai-test-python-service:v1
-
5.3 跨语言网络通信问题
问题1:Python与Java服务通信超时
- 现象:Java后端调用Python API时超时,报
Connection refused - 解决方案:
-
检查Docker网络配置,确保服务在同一网络:
yaml# docker-compose.yml中所有服务加入同一网络 networks: - ai-test-network -
使用服务名而非IP地址通信(Docker内部DNS解析):
java// 错误:使用localhost(容器内localhost不等于宿主机) // String url = "http://localhost:5000/api/predict"; // 正确:使用服务名(docker-compose中定义的service名称) String url = "http://python-ai-service:5000/api/predict";
-
问题2:跨域请求被拦截
- 现象:Vue前端调用后端API时,浏览器报
Access to fetch at '...' from origin '...' has been blocked by CORS policy - 解决方案:
-
Java后端配置CORS:
java@Configuration public class CorsConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/**") .allowedOrigins("http://localhost:3000") .allowedMethods("GET", "POST", "PUT", "DELETE") .allowCredentials(true); } } -
Python FastAPI配置CORS:
pythonfrom fastapi.middleware.cors import CORSMiddleware app = FastAPI() app.add_middleware( CORSMiddleware, allow_origins=["http://localhost:3000"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], )
-
5.4 Vue部署后接口访问异常
问题1:生产环境接口地址错误
- 现象:开发环境正常,部署后前端无法访问后端API
- 原因:Vue环境变量未正确配置,仍使用开发环境地址
- 解决方案:
-
配置多环境变量:
# .env.development VITE_API_URL=http://localhost:8080/api # .env.production VITE_API_URL=https://api.ai-test-platform.com/api -
代码中使用环境变量:
javascript// api/client.js import axios from 'axios' const api = axios.create({ baseURL: import.meta.env.VITE_API_URL })
-
问题2:Nginx部署后刷新404
-
现象:Vue路由使用history模式,刷新页面报404
-
解决方案:配置Nginx支持SPA路由:
nginx# nginx.conf location / { root /usr/share/nginx/html; index index.html; # 关键配置:所有请求转发到index.html try_files $uri $uri/ /index.html; }
总结
搭建全栈AI测试环境是一项系统工程,需要协调Python、Java、Vue三大技术栈,并结合Docker实现环境一致性。
本文从本地开发环境入手,详细介绍了各组件的配置方法、核心工具的实操技巧、云平台部署方案和一键启动的实战案例,同时提供了常见问题的解决方案。