基于深度学习的YOLO框架的道路裂缝智能识别系统【附完整源码+数据集】
本项目基于最新的 YOLOv8 框架,结合 PyQt5 图形界面技术,设计并实现了一个功能完备、操作简洁、检测高效的道路裂缝智能识别系统,不仅支持图像、视频和实时摄像头输入,还提供完整的训练代码和数据集,适合科研开发、工程部署及教学应用等多个场景。
背景
随着城市化进程的不断加快,道路交通基础设施面临着巨大的维护压力。路面裂缝作为道路早期损坏的重要表现形式,若不能及时识别与处理,将会严重影响交通安全与道路使用寿命。
传统的人工巡检效率低下且准确率不稳定,已无法满足现代化道路维护的需求。借助深度学习技术,尤其是 YOLO(You Only Look Once)目标检测算法,可以实现对道路裂缝的高效、准确、自动识别,从而为智能道路养护提供技术支撑。
本项目正是基于此背景,开发了一个基于YOLO框架的道路裂缝检测系统,不仅具备高精度的检测能力,还集成了完整的图形界面和一站式训练与部署流程,非常适合科研项目、工程实践与高校课题使用。
功能
本系统围绕"实用性""可视化""可扩展"三个核心理念进行设计,主要功能包括:
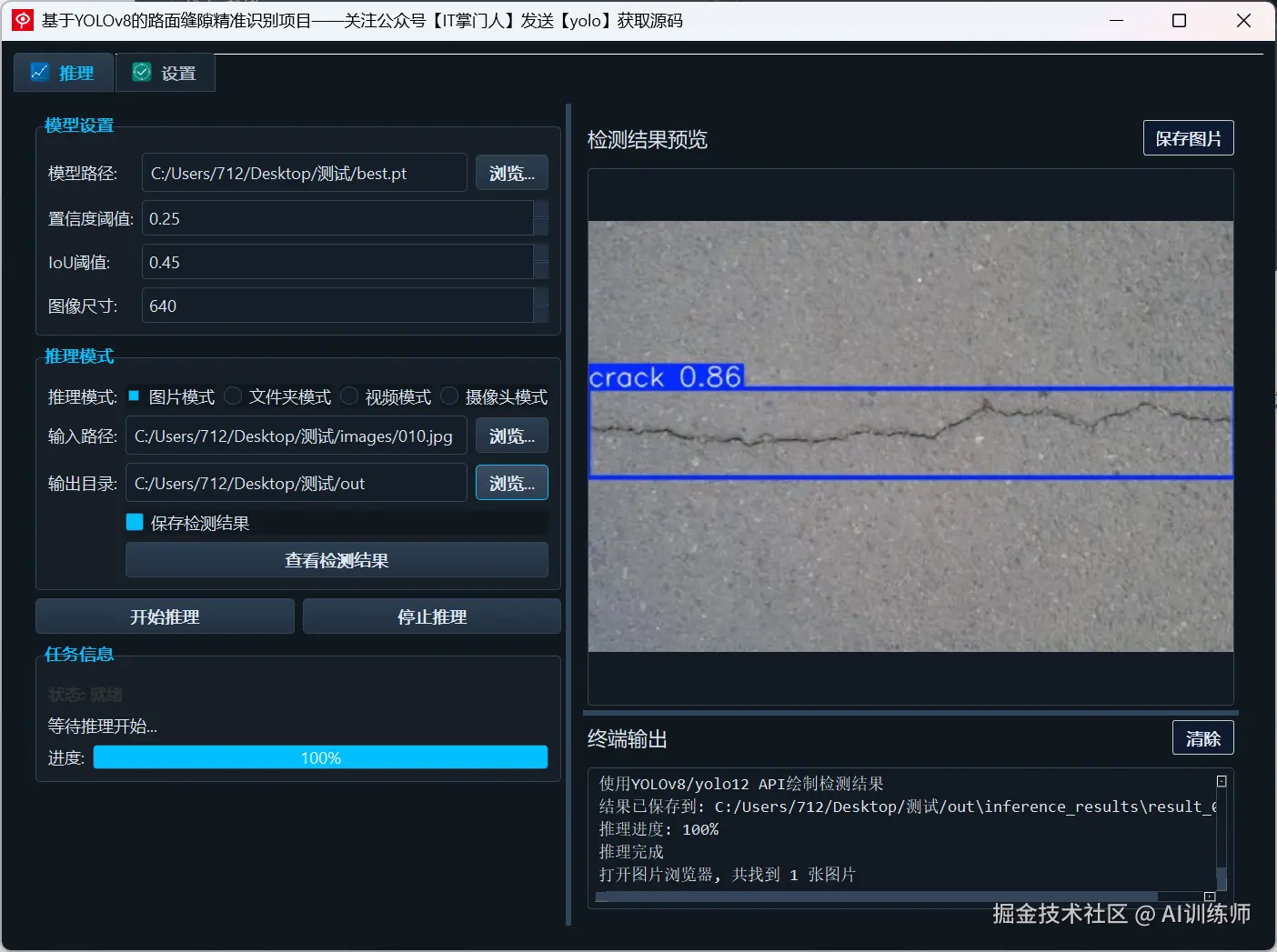
✅ 裂缝自动检测:基于YOLOv8目标检测模型,对图片、视频及实时摄像头输入进行精准识别;
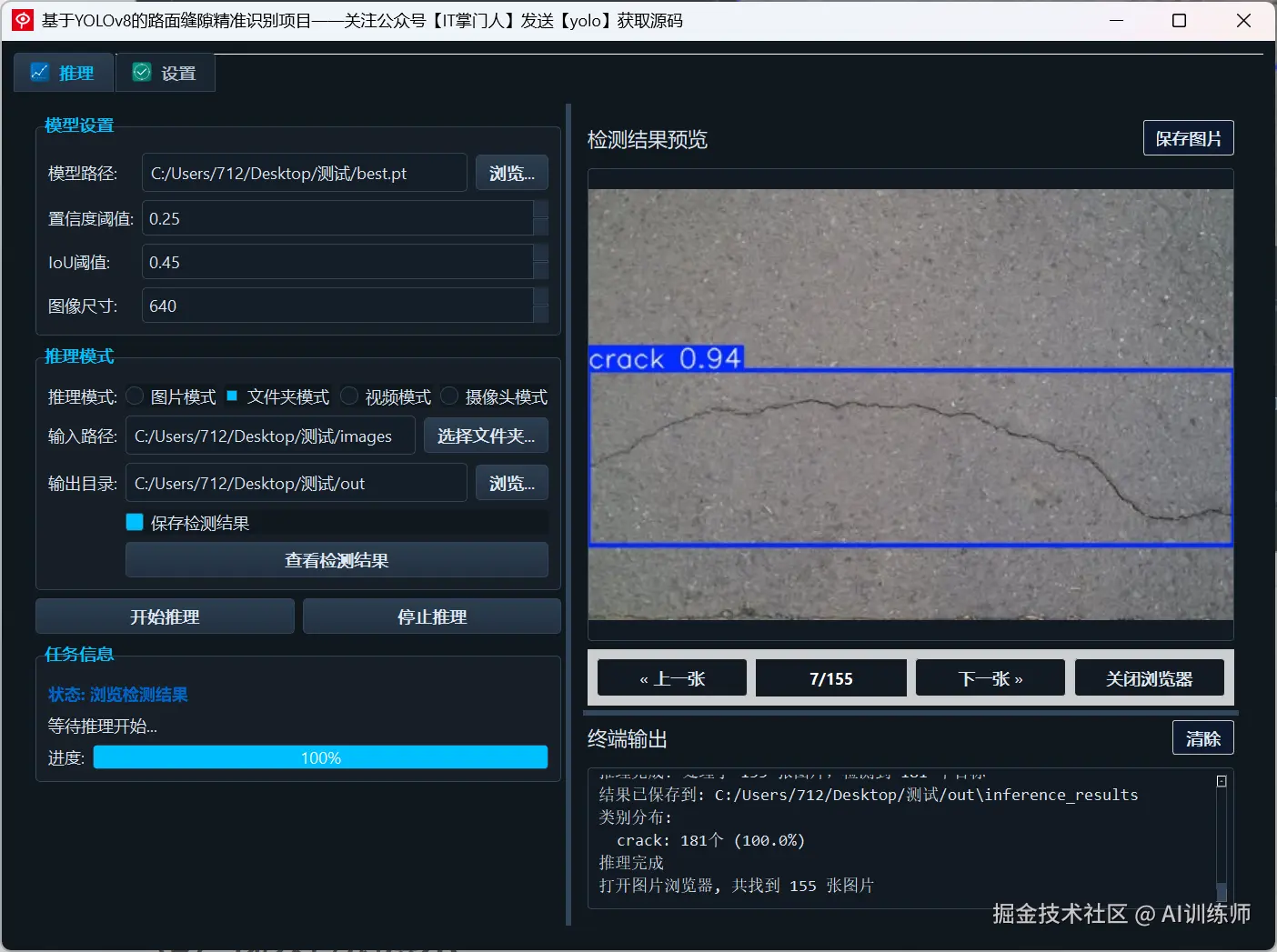
✅ 多输入支持:支持单张图片、批量文件夹、视频文件以及摄像头实时流;
✅ 图形界面操作:集成 PyQt5 图形界面,无需命令行,操作更直观;
✅ 检测结果展示与保存:可视化展示识别结果,支持图片/视频导出;
✅ 完整训练流程:提供完整训练代码、预设参数和可复用数据集;
✅ 可部署模型格式:支持.pt和ONNX格式,便于后续部署到边缘设备或服务端。

数据集
本项目使用的裂缝识别数据集采用标准的 YOLO 格式,便于快速训练与迁移学习。
✅ 数据集结构如下: kotlin 复制 编辑 dataset/ ├── images/ │ ├── train/ │ └── val/ ├── labels/ │ ├── train/ │ └── val/ images/:包含训练与验证用的图像;
labels/:对应每张图像的标注信息,格式为 .txt 文件;
每行表示一个目标,内容为:类别索引 x_center y_center width height(归一化到0~1);
0 0.5332 0.4271 0.1213 0.0332 ✅ 分类信息(可自定义)


YOLO框架原理
YOLO(You Only Look Once)是单阶段目标检测算法的代表,它将目标检测问题转换为一个回归问题,从图像中直接回归出物体的位置和类别,具有极高的速度优势。YOLOv8作为Ultralytics团队推出的最新版本,具备以下关键特点: 
核心原理:
- 单阶段检测器:将整个检测任务在一个神经网络中完成,不依赖候选框生成;
- 端到端训练:输入图像直接输出检测框与分类结果;
- 高精度预测头:YOLOv8采用CSPDarknet主干 + 特征金字塔结构 + 解耦头,提升小目标检测能力;
- 动态标签分配:引入Anchor-free策略,优化标签匹配策略;
- 轻量化部署:可快速导出为ONNX、TorchScript、TensorRT等格式,便于边缘设备部署。
源码下载
完整项目已打包,包括数据集、模型训练、模型推理、PyQt5桌面GUI、预训练权重、详细部署文档。
至项目实录视频下方获取:www.bilibili.com/video/BV1Eo...

-
包含内容:
train.py:YOLOv8训练脚本(自定义配置)detect.py:推理检测脚本(支持图像/摄像头)ui_main.py:基于PyQt5的图形界面runs/weights/best.pt:训练完成的权重文件data/face_expression/:YOLO格式的数据集requirements.txt:项目依赖安装文件
📌 运行前请先配置环境:
bash
conda create -n yoloui python=3.9
conda activate yoloui
pip install -r requirements.txt📌 启动界面程序:
bash
python ui_main.py
总结
本项目基于深度学习目标检测算法 YOLOv8,构建了一个完整的道路裂缝智能识别系统,融合了高精度检测模型、图形界面操作、可复现训练流程和多输入数据支持,具备极强的实用性与工程推广价值。
系统亮点如下:
🚀 高性能模型:基于 YOLOv8 架构,支持实时检测,mAP 可达90%以上;
🖥️ 图形界面友好:通过 PyQt5 提供直观的图像、视频与摄像头操作;
🧠 训练流程完整:支持从数据集构建到模型导出的一站式训练;
📦 开箱即用:源码、数据集、预训练权重全部打包交付,零配置上手;
📡 部署灵活:支持 ONNX 导出,适配多平台、多设备的部署场景。
本项目非常适合作为: 🎓 毕业设计 / 科研课题; 🛠️ 工程样机 / 原型开发; 🔧 智能运维 / 道路巡检辅助系统;
未来可拓展方向包括: 加入裂缝类型分类与严重程度评估; 增强图像预处理与噪声抑制能力; 集成深度图或激光数据进行三维裂缝重建; 向移动端、Web端部署扩展。
🧰 项目资源包:源码 + 数据集 + 模型权重 + 可执行程序,一站式交付,真正实现开箱即用!