Ollama是一个开源的本地大语言模型(LLM)运行框架,专注于简化和优化大型语言模型在个人设备上的部署与管理,支持主流模型的快速运行与集成。借助Ollama 强大的功能我们无需关注本地模型部署的各种复杂的依赖。如何在SparkX中使用Ollama呢?
开源地址:
github.com/nick-bai/Sp...
gitee.com/shop-sparke...
本文以macos 环境为例,其他环境除了装Ollama略有不同,其余的均一致
安装 ollama
1、下载Ollama
打开 ollama的官网 ollama.com/
点击下载,根据自己系统选择对应的版本。
正常情况下,系统会自动检测当前的操作系统,默认选择对应的版本。点击下载即可。
2、安装ollama
没有啥特殊的配置的话,一路下一步。
3、验证是否安装完毕
打开命令行输入
ollama -v出现如下的画面,表示安装完成。

在SparkX中使用Ollama
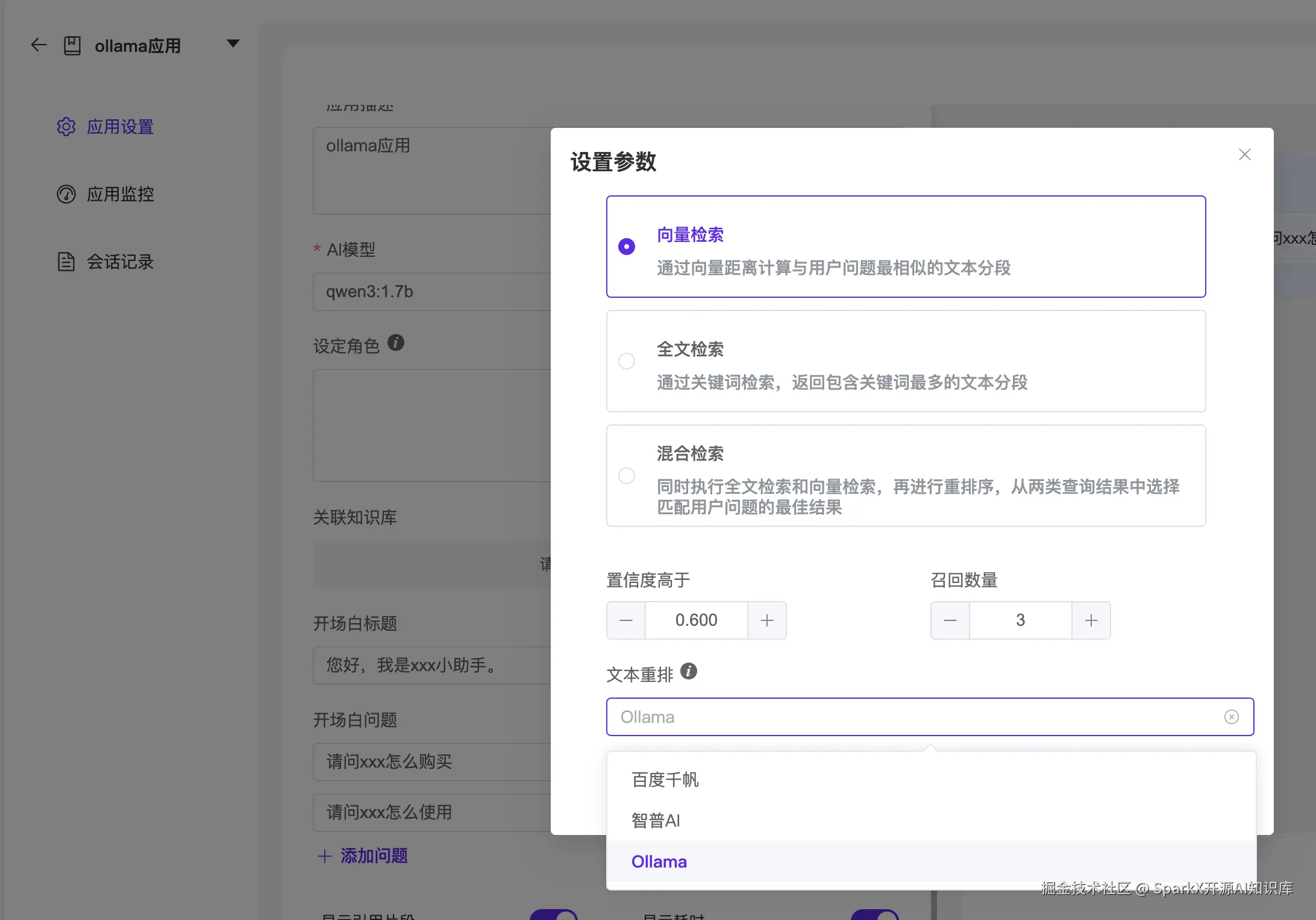
1、语言模型
我们选择一个自己系统可以部署的模型,打开 Ollama官网,点击Models
ollama.com/search
我们选择一个 qwen3 模型
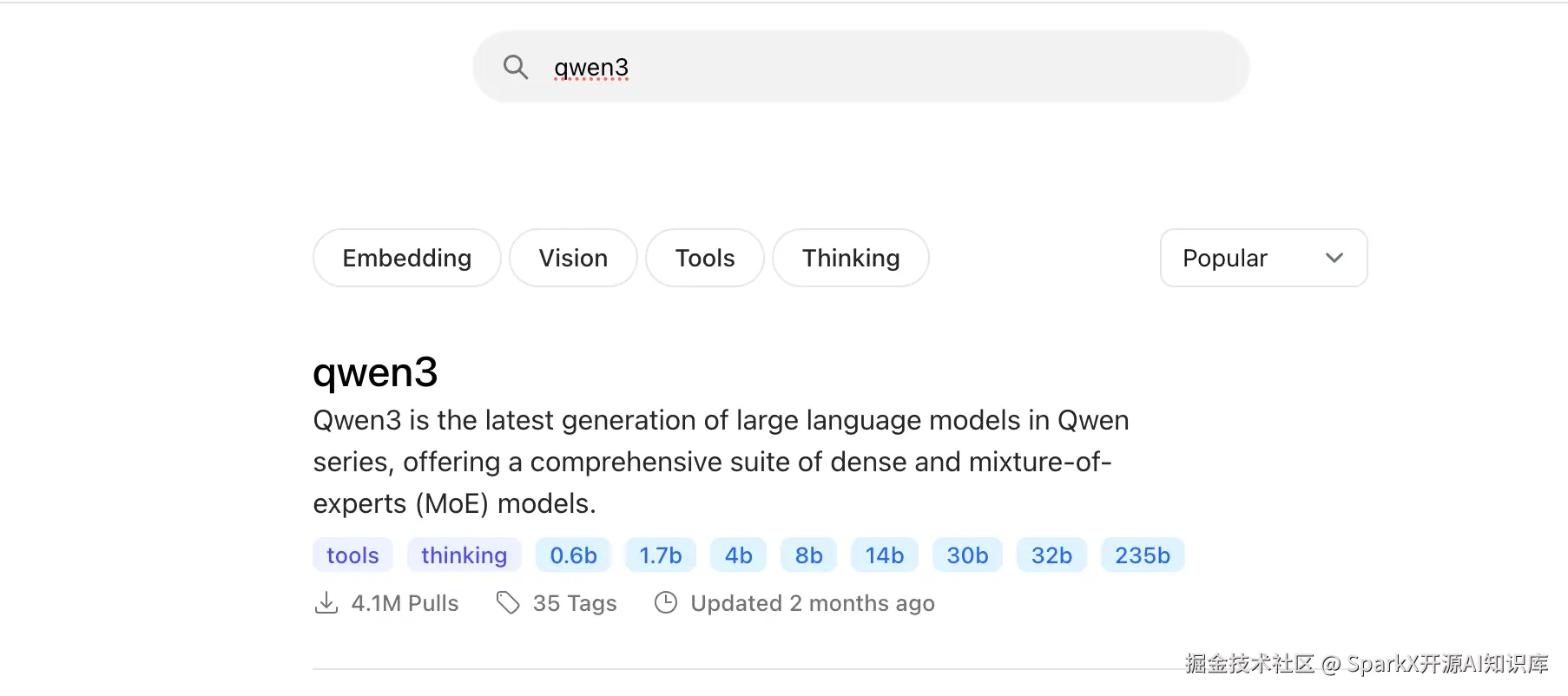
点击进去,这里我 选择 1.7b 模型,复制拉取命令
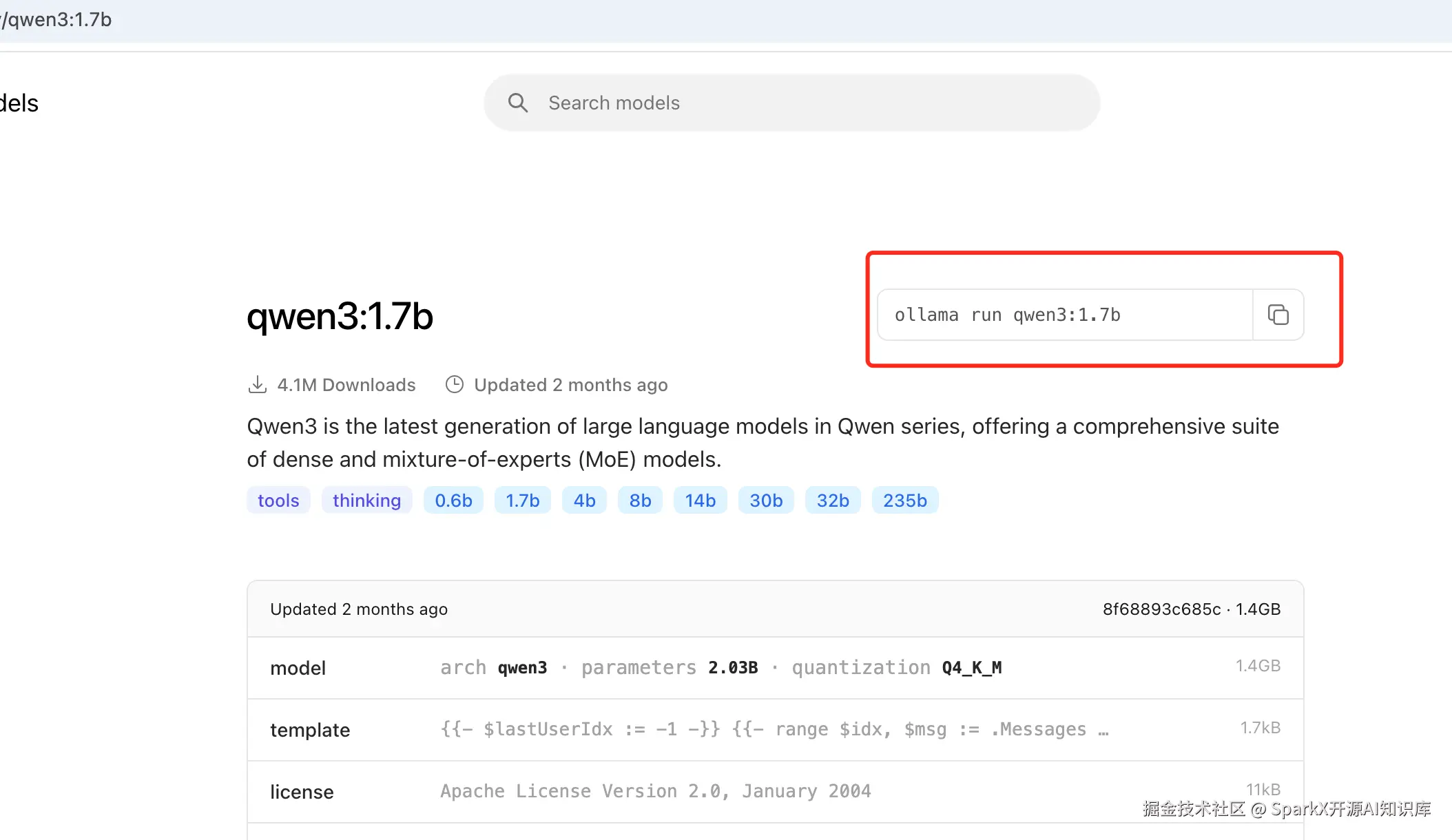
arduino
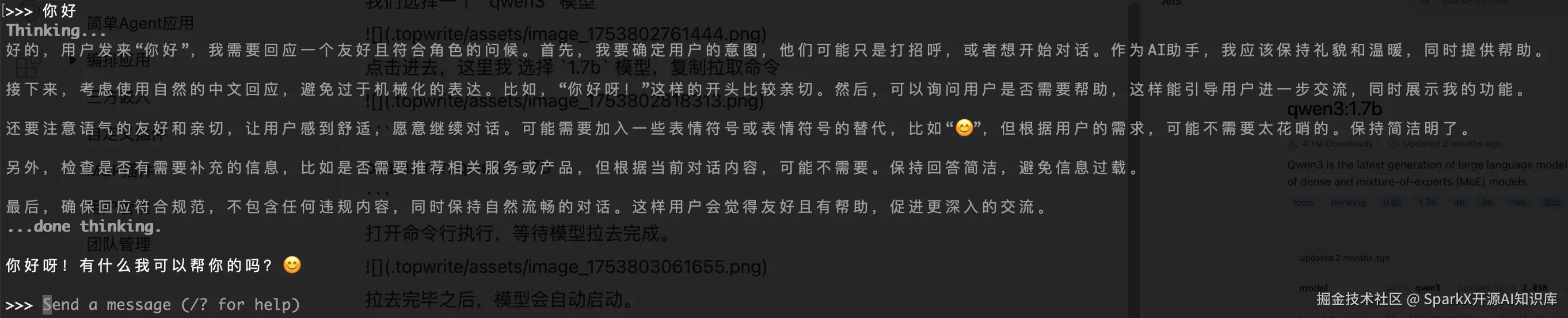
ollama run qwen3:1.7b打开命令行执行,等待模型拉去完成。

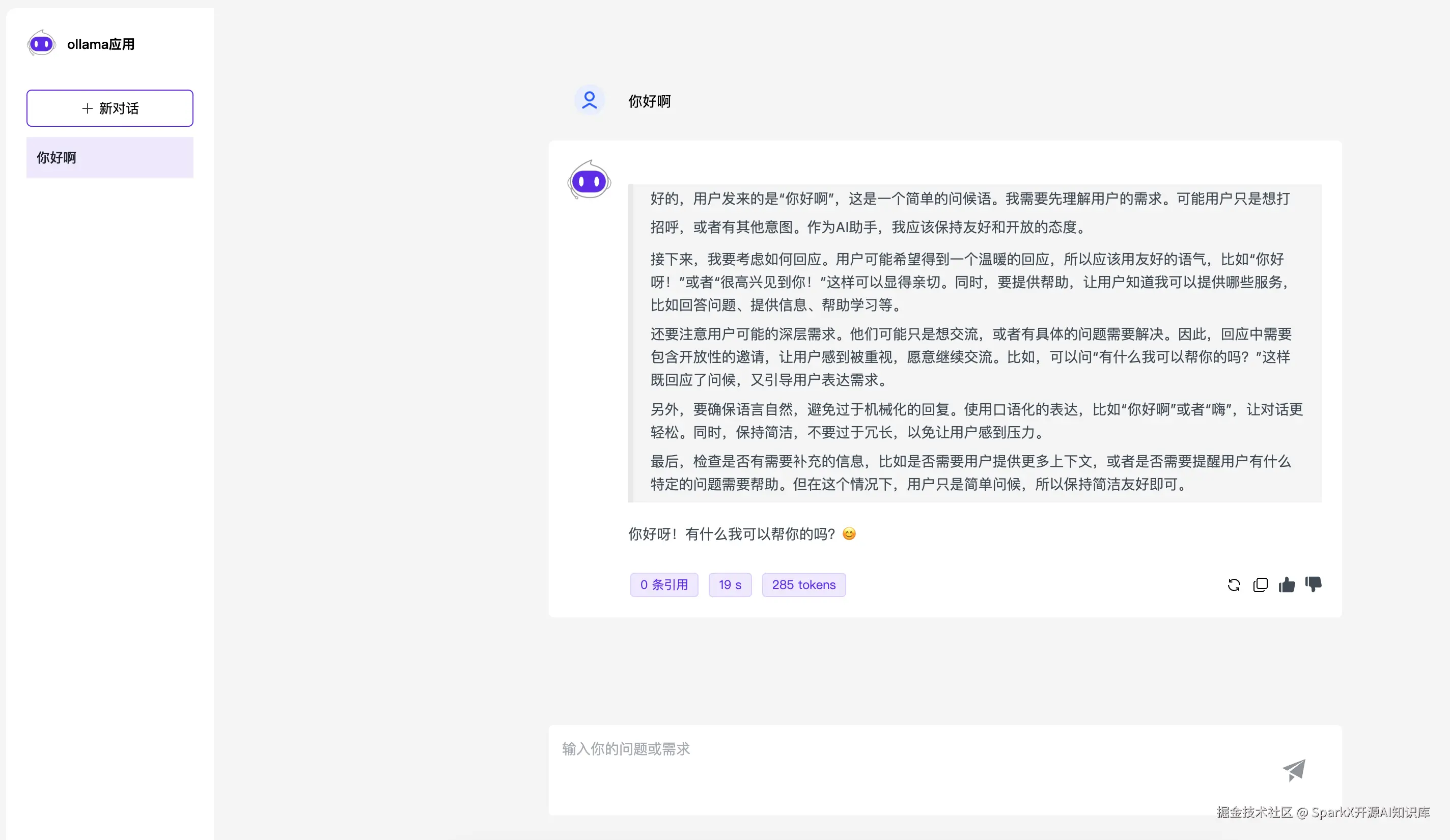
拉去完毕之后,模型会自动启动。我们输入 你好,能看到模型正常的回复了。
接下来我们打开 SparkX的模型管理,填写 Ollama 的可用模型 qwen3:1.7b
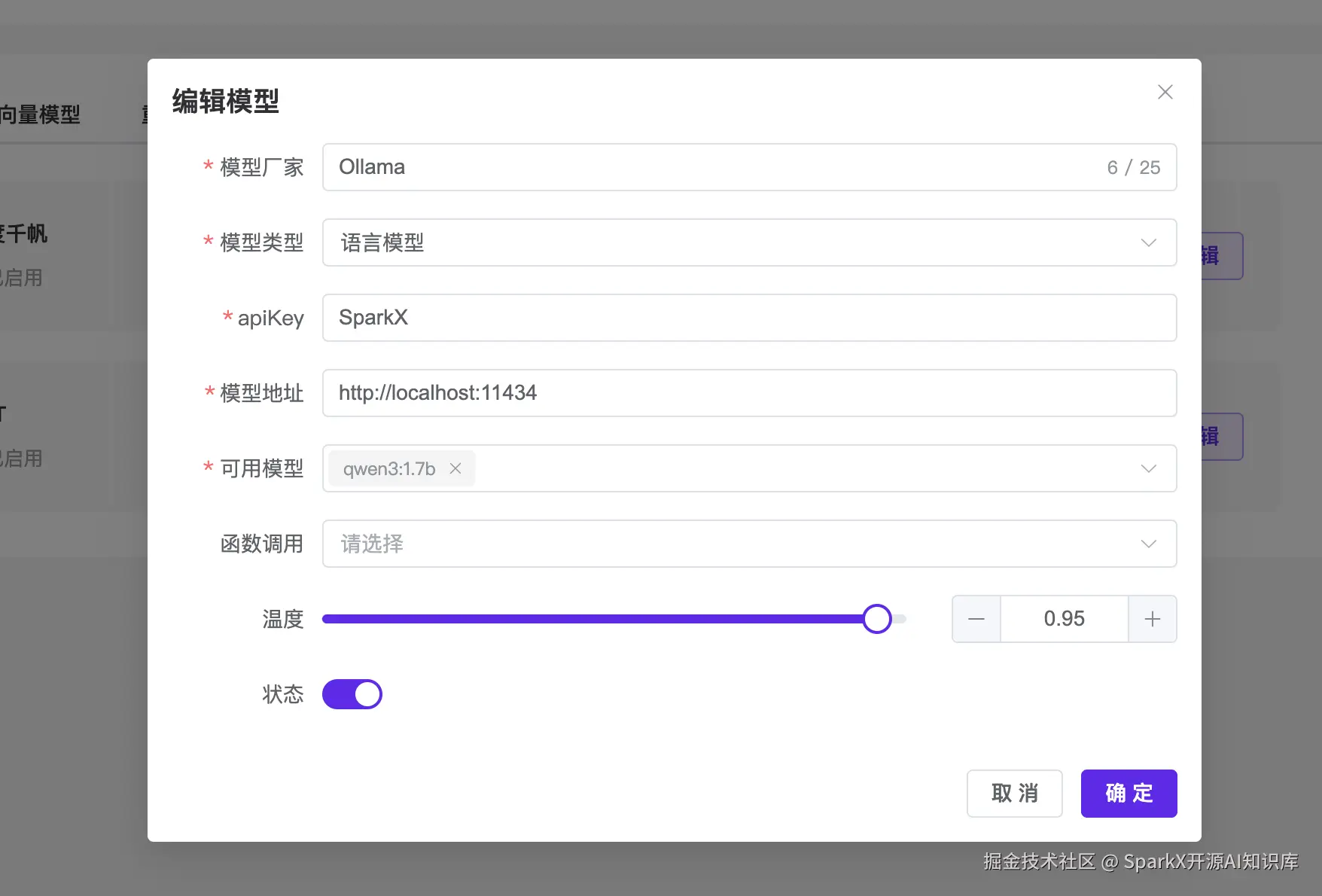
保存提交。然后在应用中选择我们设置的 模型

此时,就可以在应用中使用 Ollama 中的 qwen3 模型了
2、向量模型
打开 Ollama 官网,选择 embedding 模型

这里我们选择 一个,以 bg3-m3 为例子,复制拉去命令

ollama pull bge-m3
拉去完毕之后,我们打开 SparkX 的向量模型配置,输入可用模型为 bge-m3
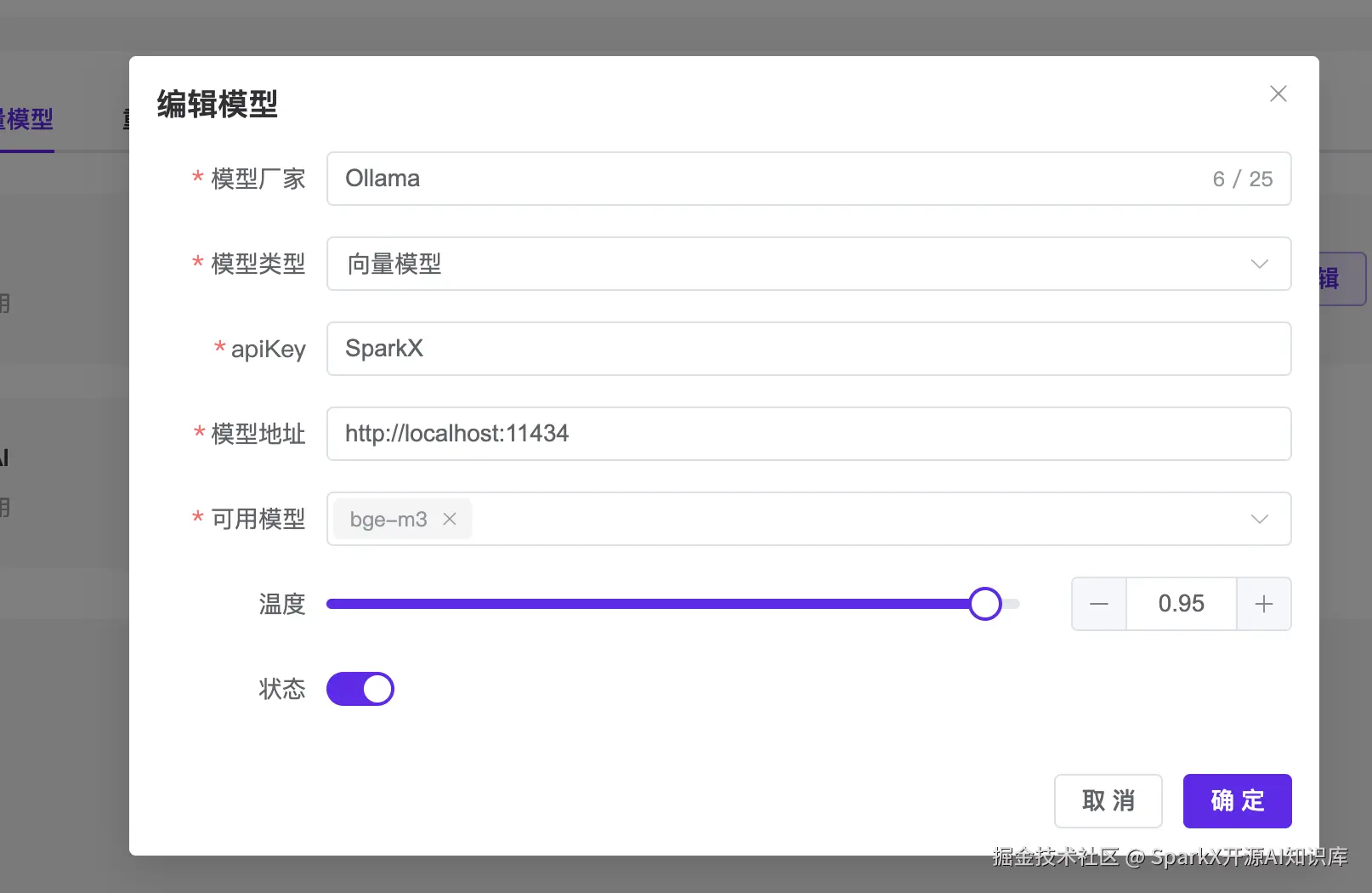
知识库就可以配置 bge-m3 模型了
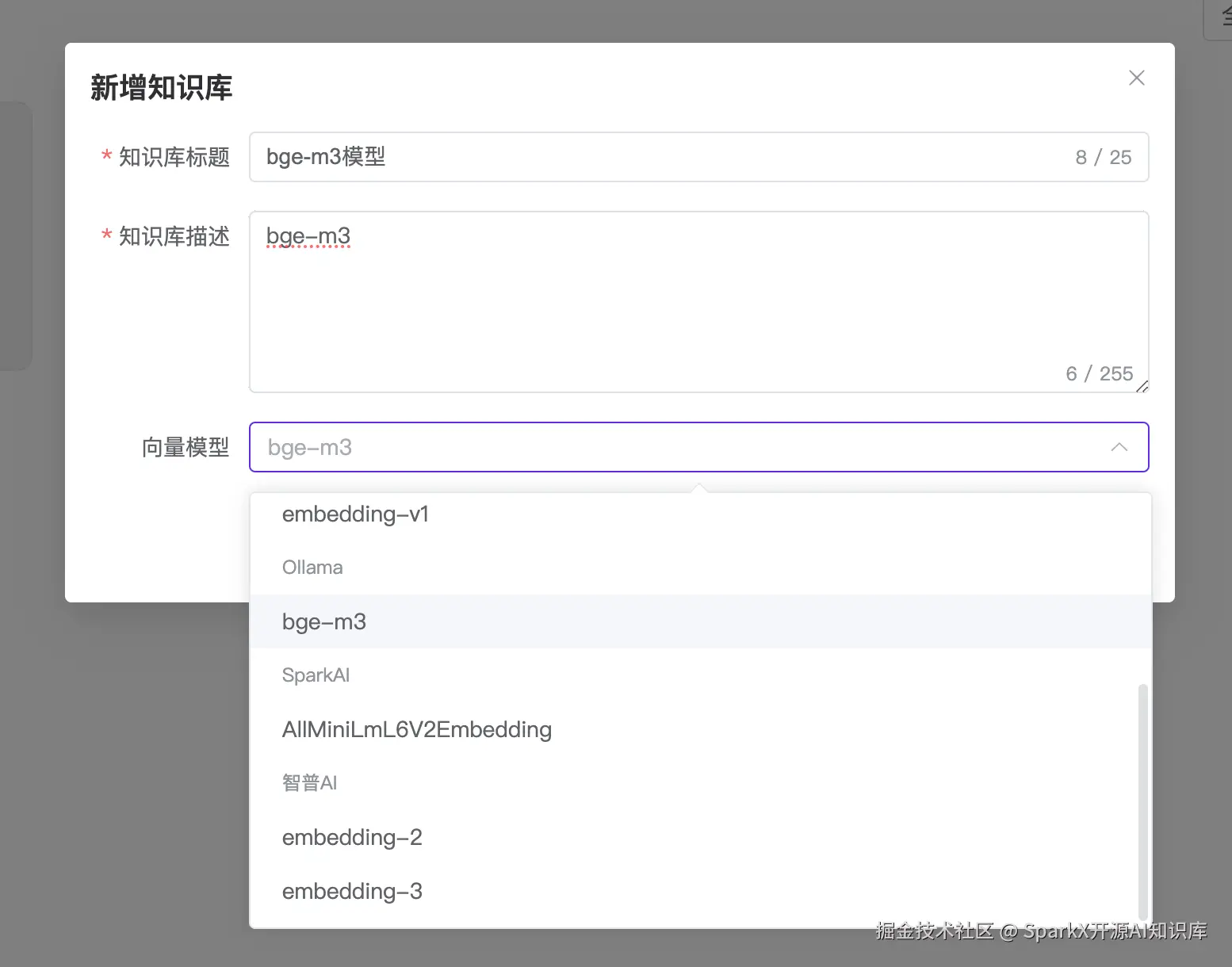
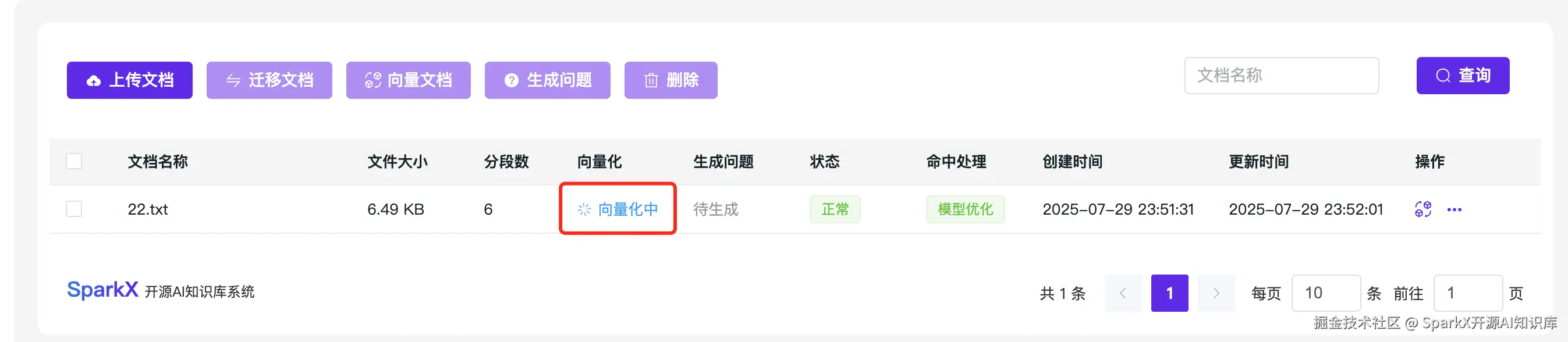
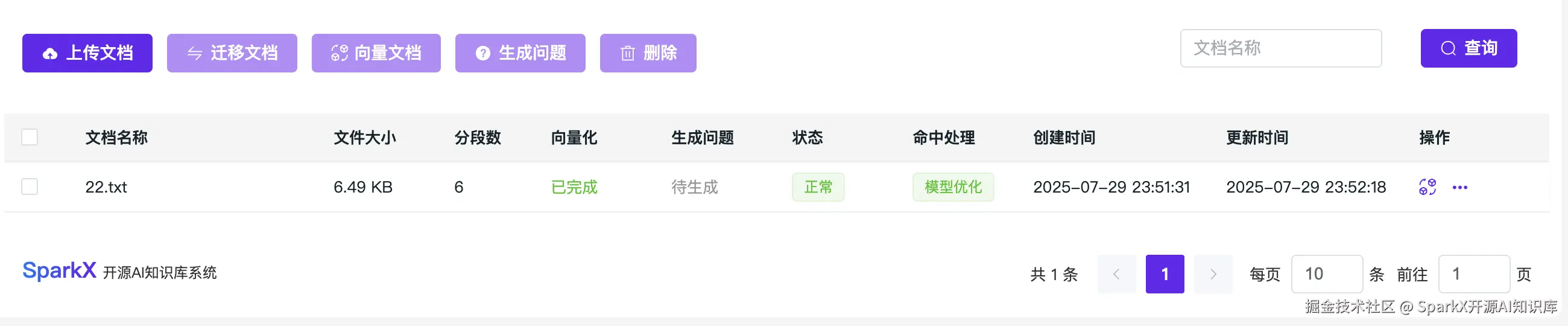
传入文本,选择向量化
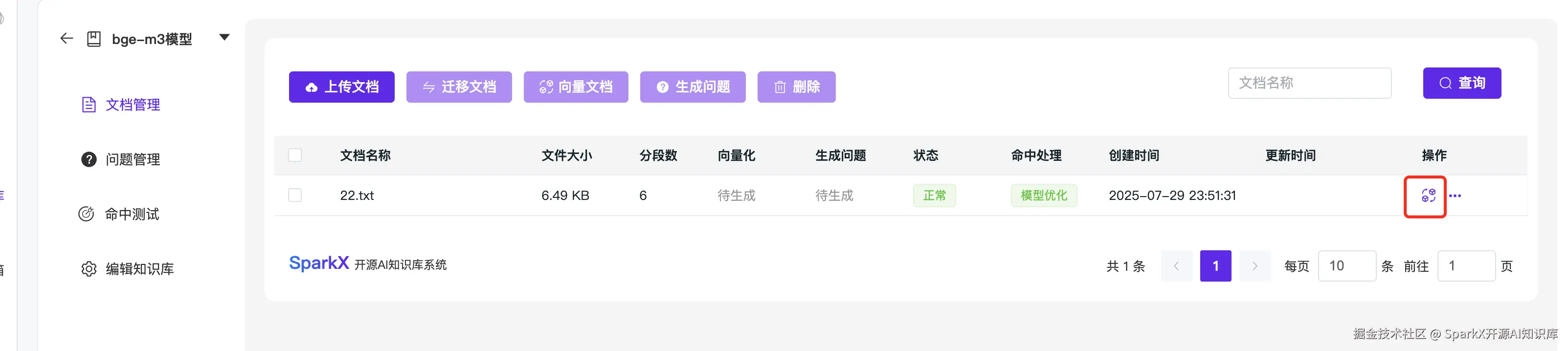
等待完成向量化
3、重排模型
打开 Ollama 官网,选择 搜索 rerank 模型
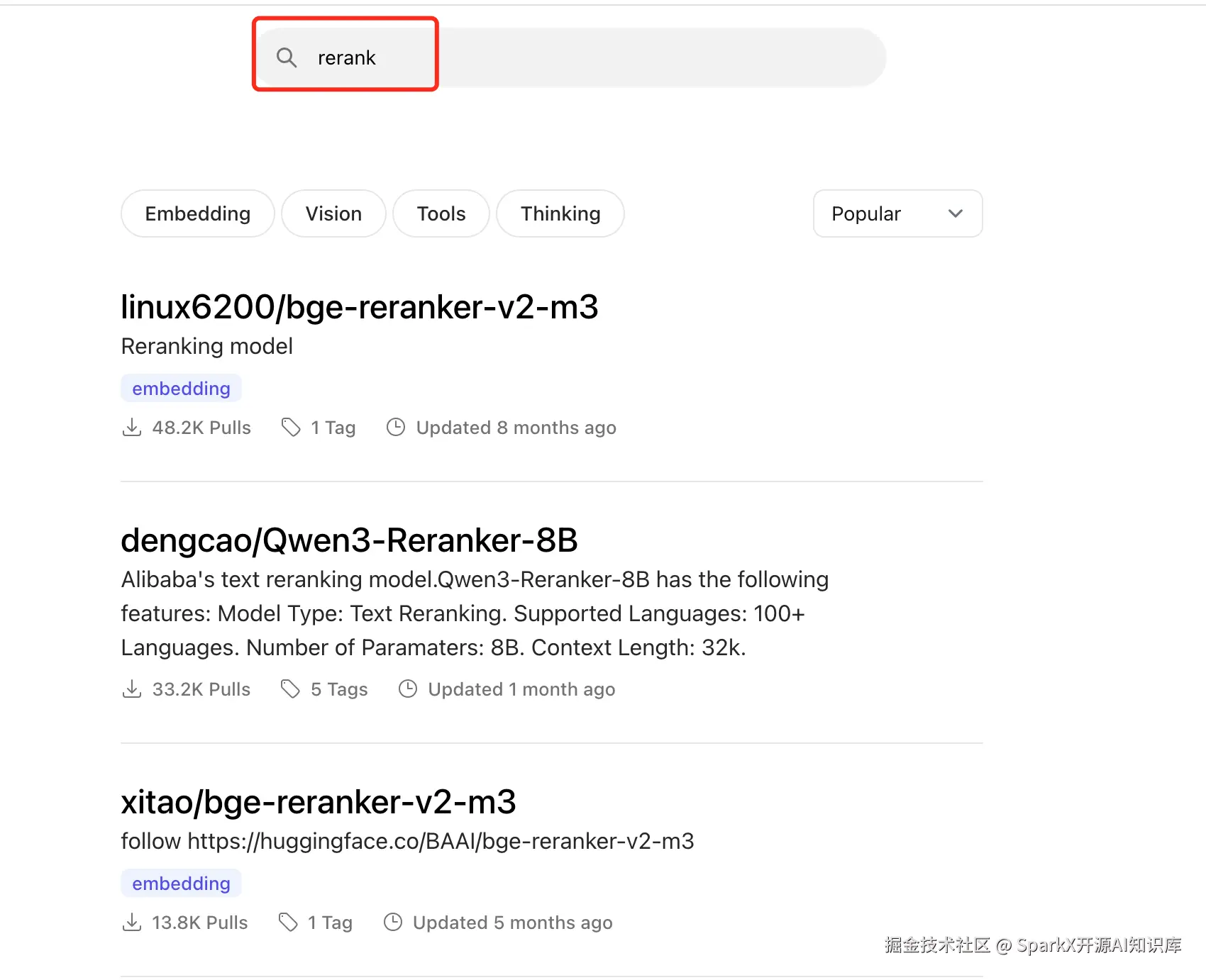
我们选择拉去 bge-reranker-v2-m3,复制 拉去命令
bash
ollama pull linux6200/bge-reranker-v2-m3
打开 SparkX 的重排模型,输入重排名称
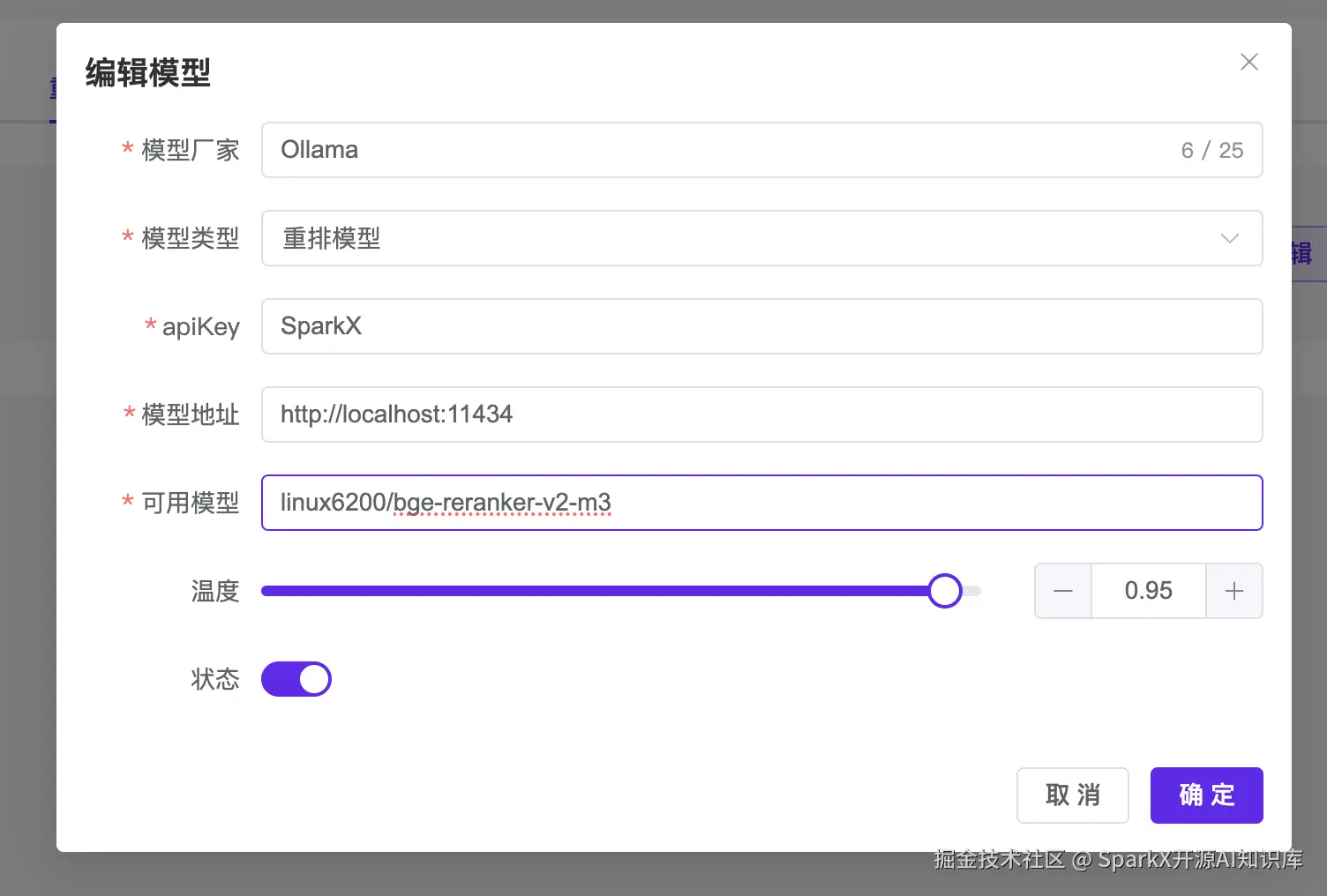
在应用中就可以选择这个重排模型了