背景
有30多个前端Jenkins Pipeline类型的Job项目, 需要将webhook的配置,从Jenkins自带的webhook类型,修改为通用的webhook类型Generic Webhook Trigger, 为什么要做这样的修改呢,因为Jenkins自带的webhook类型,推送的消息内容不完整,比如想获取gitlab 分支合并请求的label标记,就无法获得。
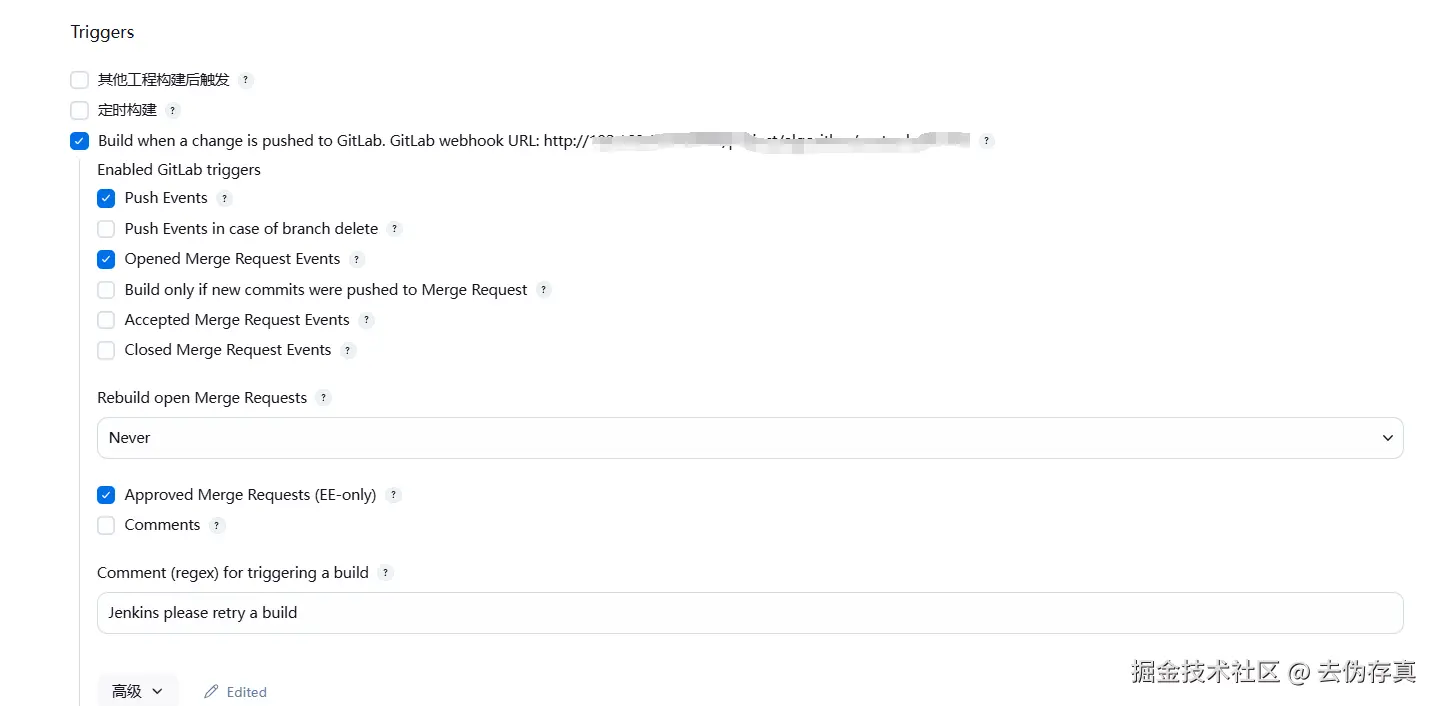
可是要改成通用的Webhook类型,面临的问题是配置参数很多,如下图所示,每个项目这样的参数有七八个,一屏都展示不全, 逐个改耗时费力。于是打算写一个脚本,批量修改Jenkins Job配置
动手实践
先说结论,总共尝试了三种脚本:
- groovy脚本,在Jenkins 服务器的console中运行, 调试了半天, 运行不报错,但修改始终不生效,最后放弃
- bash脚本, 修改Jenkins Job时遇到跨域问题, 未能解决,无奈放弃。
- Python脚本, 采用Jenkins API修改Jenkins Job配置,一路开发调试比较流畅, 实现了目标。
本文采用事后总结的方式,讲一下Python脚本方案批量修改Jenkins Job的实现过程。
step1 安装Python
去Python官网,下载最新的Python,本文选择 的是Windows installer (64-bit)这个安装包,安装时记得勾选 ☑️ Add Python 3.x to PATH(添加到环境变量), 安装完成后,执行下面两条命令, 验证安装是否成功。
js
# 查看Python版本
python --version
# 查看Python包管理器版本
pip --versionstep2 获取调用Jenkins API的Token
调用Jenkins的API, 需要一个凭据,才能正常调用。 Jenkins API调用凭证的获取方法是:
前提是你得有Jenkins 服务器管理员权限, 否则下面的菜单你看不到。进入系统管理==>全局安全配置 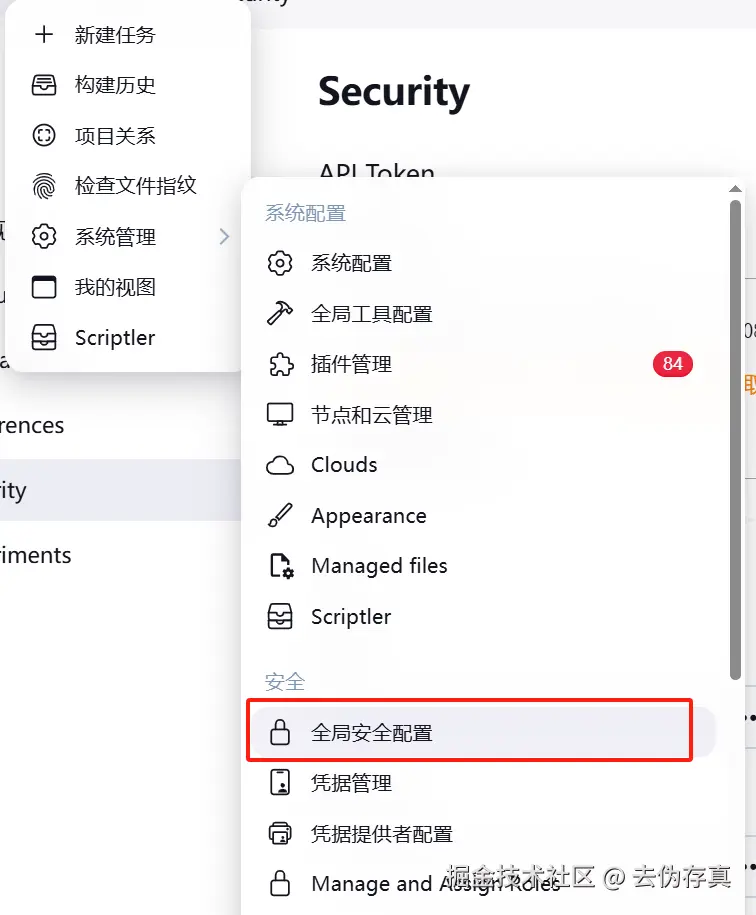
找到 API Token配置项,勾选 为每个新创建的用户生成一个遗留的 API token复选框 
接着点击页面右上角显示登录用户名称旁边的下拉箭头,进入 Security子项菜单
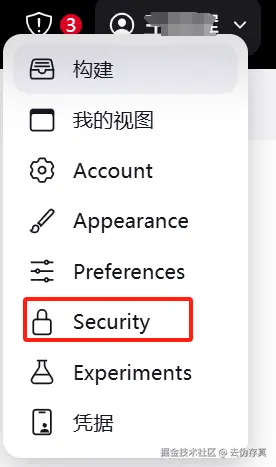
进入新页面后,点击添加新Token按钮,再点击输入框旁边的生成按钮,就能生成调用Jenkins API所需的Token

step3 配置一个Jenkins Job修改参照模版
业务要求Jenkins需要监听的Gitlab Webhook事件是:
- 每个开发迭代周期创建新的发布分支时
- 有特性分支发起合并发布分支请求时
这就需要对Gitlab Webhook推送过来的事件数据进行解析, 判断是否满足条件。
- Post content parameters表示解析的是请求体部分的数据
- Header parameters 表示解析的是请求头部分的数据
- Request parameters表示解析的是请求URL中的查询参数
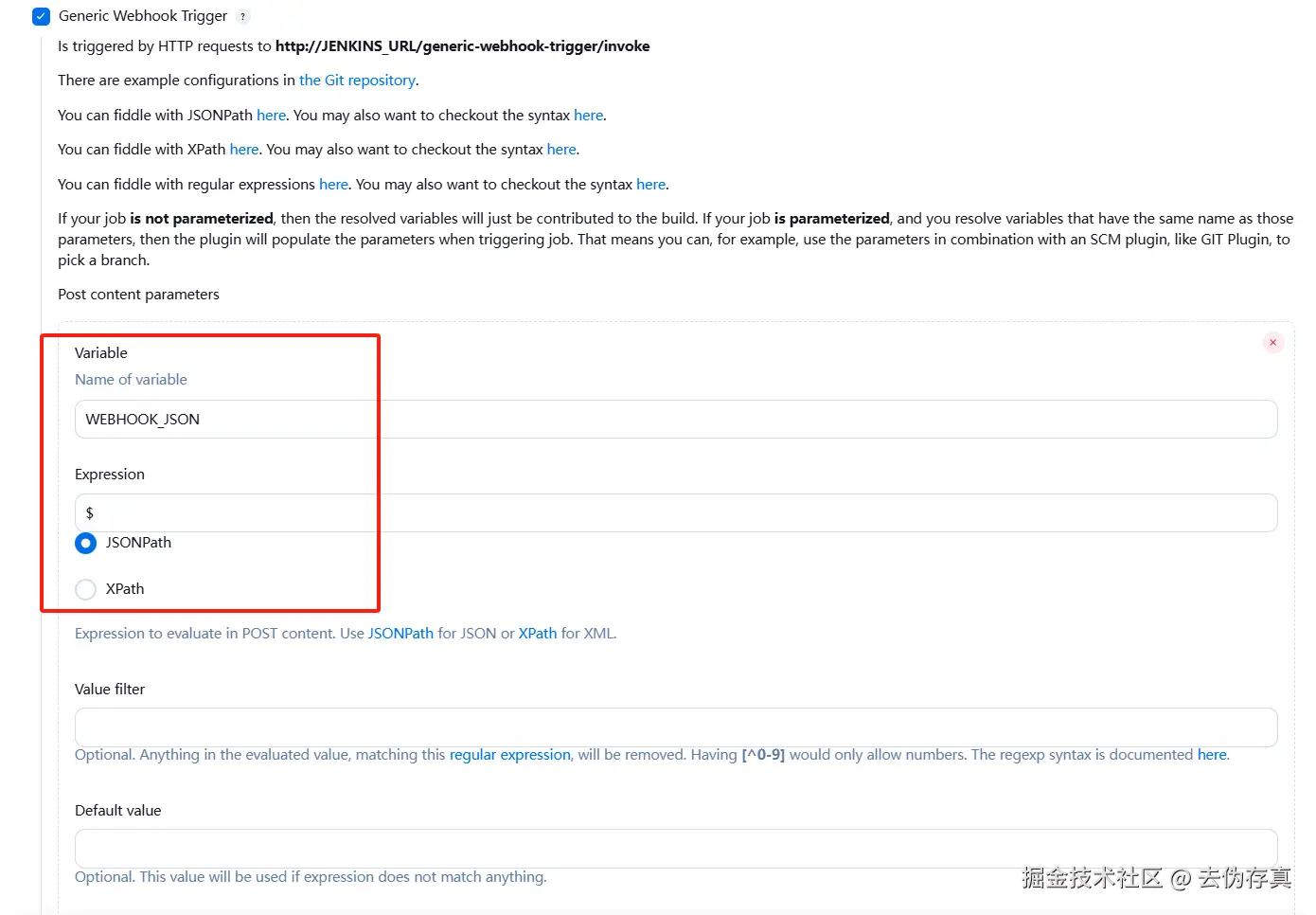
这里我们用到的是Post content parameters类型,每个变量的配置项有4项,我们以WEBHOOK_JSON(在Jenkins主流程解析webhook推送数据时要用到)为例,说明一下配置变量时每个配置项的含义:
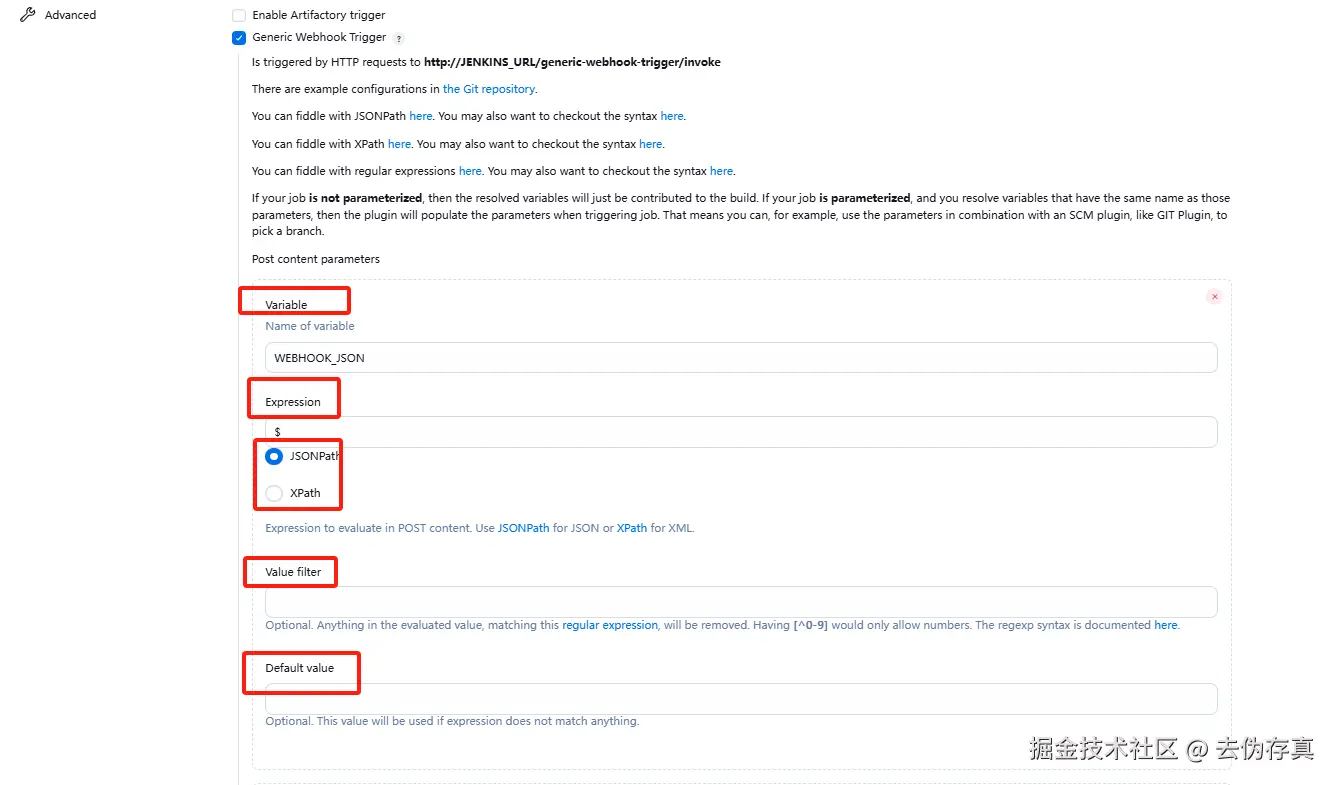 1. Variable
1. Variable
- 定义一个变量名(图中是
WEBHOOK_JSON),用于接收和存储 webhook 的请求体内容。 - 这个变量在后续的构建步骤中可以引用,比如作为参数传递给脚本或其他插件。
2. Expression
-
指定从请求体中提取数据的表达式类型。图中选择的是
JSONPath,意味着会从 JSON 数据中解析目标字段。 -
用于定位 webhook payload 中具体的字段,比如
$.ref或$.commits[*].id等。 -
JSONPath 通常用于 REST API 返回的 JSON 数据,比如 GitLab webhook payload、Kubernetes config、CI/CD 参数传递。
-
XPath 多用于 XML 文档,如旧版 SOAP 接口、Jenkins Job config.xml、自定义插件配置等。
3. Value Filter
- 对提取结果应用过滤规则。支持使用正则表达式进行匹配或替换。
- 示例正则:
[^0-9]表示过滤掉非数字字符,只保留数字。这在提取数字 ID、版本号等时尤其有用。
4. Default Value
- 如果表达式无法匹配任何字段或值为空时,系统将使用这个默认值作为变量的内容。
- 能有效防止构建因 webhook 内容异常而失败。
掌握了变量的配置方法之后, 需要依次配置下面五个变量
| 变量 | 含义 | 取webhook推送的值 |
|---|---|---|
| ref | 推送的引用路径,示例值:refs/heads/main | $.ref |
| event_name | webhook事件类型标识 | $.event_name |
| before | 推送前的 commit SHA,如果 before 是全 40 位 0 值,表示新建分支 |
$.before |
| target_branch | 合并时的目标分支 | $.object_attributes.target_branch |
| merge_state | 合并状态,示例值:opened, merged | $.object_attributes.state |
现在配置Jenkins Job只处理新建release分支和合并目标为release分支的webhook事件, 配置如下:
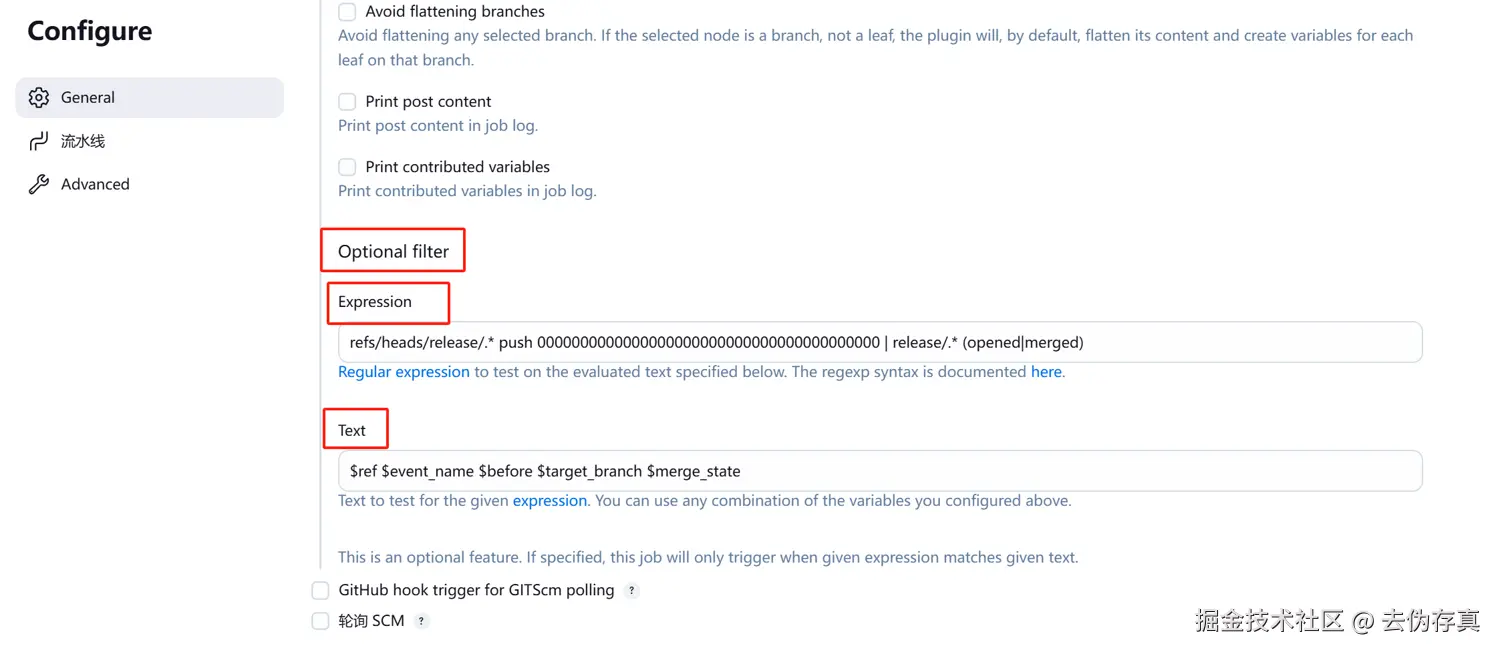
下面解释一下每项配置含义:
1. Optional filter
表示这是一个"可选"过滤器,只有当 webhook payload 中的内容满足特定的规则时,才会触发 Job 构建。如果不配置这个过滤器,所有 webhook 请求都会触发构建;配置后会按表达式进行判断。
2. Expression(正则表达式)
refs/heads/release/.* push 0000000000000000000000000000000000000000 | release/.* (opened|merged) 这条正则用于匹配特定的分支、事件类型、提交 ID 和合并状态。 举例说明:
refs/heads/release/.* push 0000000000000000000000000000000000000000是检测是否为 新创建 release 分支事件;release/.* (opened|merged)是检测是否为 release 分支的合并请求打开或合并事件。
3. Text
$ref $event_name $before $target_branch $merge_state
用于构造供表达式匹配的实际字符串。会将 webhook 中的变量值依次拼接,比如:
$ref: 提交的分支路径,例如refs/heads/release/v1.2$event_name: webhook 事件类型,如push、merge_request$before: 提交前的 SHA 值,常用于检测删除操作(如全 0)$target_branch: 目标分支(用于合并请求)$merge_state: 合并请求状态,如opened或merged
step4 编写批量修改Jenkins Job脚本
前面已经把实现批量修改JenkinsJob功能的外围障碍扫清了,现在来编写主逻辑功能。主体思路是:
- 配置一个模版项目和待批量修改的项目列表
- 读取模版项目的Trigger部分
Generic Webhook Trigger配置,保存到一个临时变量中 - 遍历待批量修改的项目列表,除了Token属性要修改成每个项目的job名称之外,其它参数全部照搬模版,改完之后进行保存提交。
- 为了避免改错丢失项目原有配置,改之前需要对原来的配置进行备份
- 最后,需要在Gitlab中给每个项目配置webhook,不存在则创建,存在则修改成统一配置
新建replace_trigger.py文件,内容如下:
python
import requests
from lxml import etree
import copy
import os
import json
# Jenkins 凭证
JENKINS_USER = "登录名称"
JENKINS_TOKEN = "第二步获取的API-Token"
JENKINS_URL = "http://192.168.10.91:8080"
// 模版job
TEMPLATE_JOB = f"{JENKINS_URL}/view/prod-algorithm/job/prod-algorithm/job/travel-ai/"
HEADERS = {"Content-Type": "application/xml; charset=UTF-8"}
# GitLab 配置
GITLAB_TOKEN = "Gitlab API Token"
GITLAB_URL = "https://git.xxx.com"
WEBHOOK_URL = "http://192.168.10.91:8080/generic-webhook-trigger/invoke?WEBHOOK_DEBUG=N"
# 项目映射:{Jenkins job 路径: GitLab 项目 ID}
target_job_map = {
"prod-data/proj1": 654,
// ...
}
def get_crumb():
url = f"{JENKINS_URL}/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)"
resp = requests.get(url, auth=(JENKINS_USER, JENKINS_TOKEN))
parts = resp.text.strip().split(":", 1)
return {parts[0]: parts[1]}
def fetch_config(url):
resp = requests.get(f"{url}/config.xml", auth=(JENKINS_USER, JENKINS_TOKEN))
xml = resp.text.replace("<?xml version='1.1'", "<?xml version='1.0'")
return etree.fromstring(xml.encode("utf-8"))
def extract_pipeline_trigger_property(template_tree, token_value,job_path):
props = template_tree.find("properties")
if props is None:
return None
pipeline_prop = props.find("org.jenkinsci.plugins.workflow.job.properties.PipelineTriggersJobProperty")
if pipeline_prop is None:
return None
cloned = copy.deepcopy(pipeline_prop)
for token in cloned.findall(".//token"):
token.text = token_value
# if job_path.startswith("prod-"):
# for regexpFilterExpression in cloned.findall(".//regexpFilterText"):
# regexpFilterExpression.text = "$merge_state $target_branch"
# for regexpFilterExpression in cloned.findall(".//regexpFilterExpression"):
# regexpFilterExpression.text = "^(opened|merged) release/.*$"
return cloned
def replace_trigger_in_target(target_tree, new_prop):
if new_prop is None:
return
props = target_tree.find("properties")
if props is None:
props = etree.Element("properties")
target_tree.insert(0, props)
existing = props.find("org.jenkinsci.plugins.workflow.job.properties.PipelineTriggersJobProperty")
if existing is not None:
props.remove(existing)
props.append(new_prop)
def extract_definition(template_tree):
original_def = template_tree.find("definition")
if original_def is None:
return None
return copy.deepcopy(original_def)
def replace_definition_in_target(target_tree, new_def):
if new_def is None:
return
existing_def = target_tree.find("definition")
if existing_def is not None:
target_tree.remove(existing_def)
target_tree.append(new_def)
def upload_config(job_url, xml_str, crumb):
resp = requests.post(f"{job_url}/config.xml",
auth=(JENKINS_USER, JENKINS_TOKEN),
headers={**HEADERS, **crumb},
data=xml_str.encode("utf-8"))
print(f"🔧 Jenkins 上传 → {job_url}/config.xml → 状态码:{resp.status_code}")
def webhook_exists(project_id, webhook_url):
url = f"{GITLAB_URL}/api/v4/projects/{project_id}/hooks"
headers = {"PRIVATE-TOKEN": GITLAB_TOKEN}
try:
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
for hook in resp.json():
if hook.get("url") == webhook_url:
hook_id = hook.get("id")
print(f"🔍 webhook 已存在(ID: {hook_id}):{webhook_url}")
return hook_id
else:
print(f"⚠️ 获取 webhook 列表失败:{resp.status_code}")
except Exception as e:
print(f"❌ 获取 webhook 时出错:{e}")
return None
def ensure_gitlab_webhook(project_id, job_name):
hook_id = webhook_exists(project_id, WEBHOOK_URL)
if hook_id:
# webhook 已存在,执行更新
method = "put"
url = f"{GITLAB_URL}/api/v4/projects/{project_id}/hooks/{hook_id}"
action = "更新"
else:
# webhook 不存在,执行创建
method = "post"
url = f"{GITLAB_URL}/api/v4/projects/{project_id}/hooks"
action = "创建"
payload = {
"url": WEBHOOK_URL,
"push_events": True,
"push_events_branch_filter": "release*",
"merge_requests_events": True,
"token": job_name
}
headers = {
"PRIVATE-TOKEN": GITLAB_TOKEN,
"Content-Type": "application/json"
}
try:
resp = getattr(requests, method)(url, headers=headers, json=payload)
if resp.status_code in [200, 201]:
print(f"✅ 成功{action} GitLab webhook:{WEBHOOK_URL}")
else:
print(f"❌ {action} webhook 失败,状态码:{resp.status_code}")
print(resp.text)
except Exception as e:
print(f"❌ {action} webhook 时出错:{e}")
def job_url_from_path(job_path):
return f"{JENKINS_URL}/job/" + "/job/".join(job_path.split("/"))
def job_name_from_path(job_path):
return job_path.split("/")[-1]
def main():
print("🚀 批量配置 Jenkins Job + GitLab webhook ...")
crumb = get_crumb()
print("✅ Jenkins crumb 获取成功")
template_tree = fetch_config(TEMPLATE_JOB)
print("📥 模版配置加载完成")
for job_path, project_id in target_job_map.items():
job_url = job_url_from_path(job_path)
job_name = job_name_from_path(job_path)
print(f"\n🔄 正在处理 Jenkins Job:{job_path} → GitLab 项目 ID:{project_id}")
try:
target_tree = fetch_config(job_url)
print("📥 Jenkins Job 配置已加载")
# 备份
backup_str = etree.tostring(target_tree, encoding="unicode", pretty_print=True)
backup_str = "<?xml version='1.0' encoding='UTF-8'?>\n" + backup_str
backup_file_name = f"prod_backup_{job_name}.xml" if 'prod' in job_path else f"backup_{job_name}.xml"
with open(backup_file_name, "w", encoding="utf-8") as f:
f.write(backup_str)
print(f"📦 备份完成:{backup_file_name}")
# 替换触发器与脚本
new_prop = extract_pipeline_trigger_property(template_tree, job_name,job_path)
if new_prop is not None and len(new_prop):
replace_trigger_in_target(target_tree, new_prop)
print("🔧 Jenkins Trigger 替换完成")
new_def = extract_definition(template_tree)
if new_def is not None and len(new_def):
replace_definition_in_target(target_tree, new_def)
print("📄 Jenkins Definition 替换完成")
# 保存修改后的 XML
updated_str = etree.tostring(target_tree, encoding="unicode", pretty_print=True)
updated_str = "<?xml version='1.0' encoding='UTF-8'?>\n" + updated_str
modified_file_name = f"prod_modified_{job_name}.xml" if 'prod' in job_path else f"modified_{job_name}.xml"
with open(modified_file_name, "w", encoding="utf-8") as f:
f.write(updated_str)
print(f"✅ 修改保存:{modified_file_name}")
# 上传到 Jenkins
upload_config(job_url, updated_str, crumb)
# 创建 GitLab webhook
create_gitlab_webhook(project_id, job_name)
except Exception as e:
print(f"❌ 错误处理 Job {job_path}:{e}")
if __name__ == "__main__":
main()由于脚本中用到了一些第三方依赖,所以创建一个requirements.txt文件,管理项目所需的第三方依赖库。写入内容:
js
requests
lxml执行安装命令,进行依赖的安装
bash
pip install -r requirements.txt然后执行:
js
python replace_trigger.py执行完之后,登录Jenkins和Gitlab查看修改是否生效,笔者看到修改均生效。
最后
在日常的系统运维与持续集成实践中,我们经常面对大量重复性的配置修改、接口调用及数据变更。这类工作耗时、易错,且严重制约了团队的效率与响应速度。与其每次都手动修改,不如彻底转变思维方式:让脚本成为你最可靠的助手。通过将操作流程标准化、脚本化,不仅能避免人为疏漏,还能快速适配环境变化与需求迭代。自动化脚本既是技术沉淀的体现,也是架构可靠性与可维护性的重要保障。当你开始习惯用代码解决问题,你会发现,那些原本繁琐重复的工作已悄然化为一行行优雅的逻辑。最终,我们不只是写脚本去省事,更是在构建一个更稳定、更智能、更可预期的技术生态------这是每一位技术人应有的追求,也体现了技术人的核心价值。