文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,私信获取! 麦麦大数据
编号: F051
视频
F051-企业债务分析系统解说
1 系统简介
系统简介:本系统是一个基于Vue+Flask+MySQL构建的企业债务舆情风险预测分析系统。其核心功能围绕企业债务信息的采集、处理、分析与可视化展示,通过自然语言处理(NLP)和机器学习模型实现对公开舆情数据中企业债务风险的自动识别与预警。主要功能模块包括:企业信息管理、舆情数据采集与清洗、风险评分计算、风险趋势预测、可视化展示、用户权限管理等。
2 功能设计
该系统采用前后端分离的B/S架构模式,基于Vue.js + Flask + MySQL技术栈实现。前端通过Vue.js框架搭建响应式界面,结合Element UI组件库提供友好的用户交互体验,使用Vue-Router进行页面路由管理,Axios实现与后端的异步数据交互。Flask后端负责构建RESTful API服务,通过Blueprint组织模块结构,利用SQLAlchemy操作MySQL数据库存储企业信息、舆情数据、风险评分与预测结果等结构化数据,PyMySQL作为MySQL驱动支持。
在舆情风险预测功能方面,系统采用基于BERT的文本分类模型进行情感分析与风险识别,结合LSTM时序模型对债务舆情趋势进行预测,实现对企业债务风险的动态评估。
2.1 系统架构图
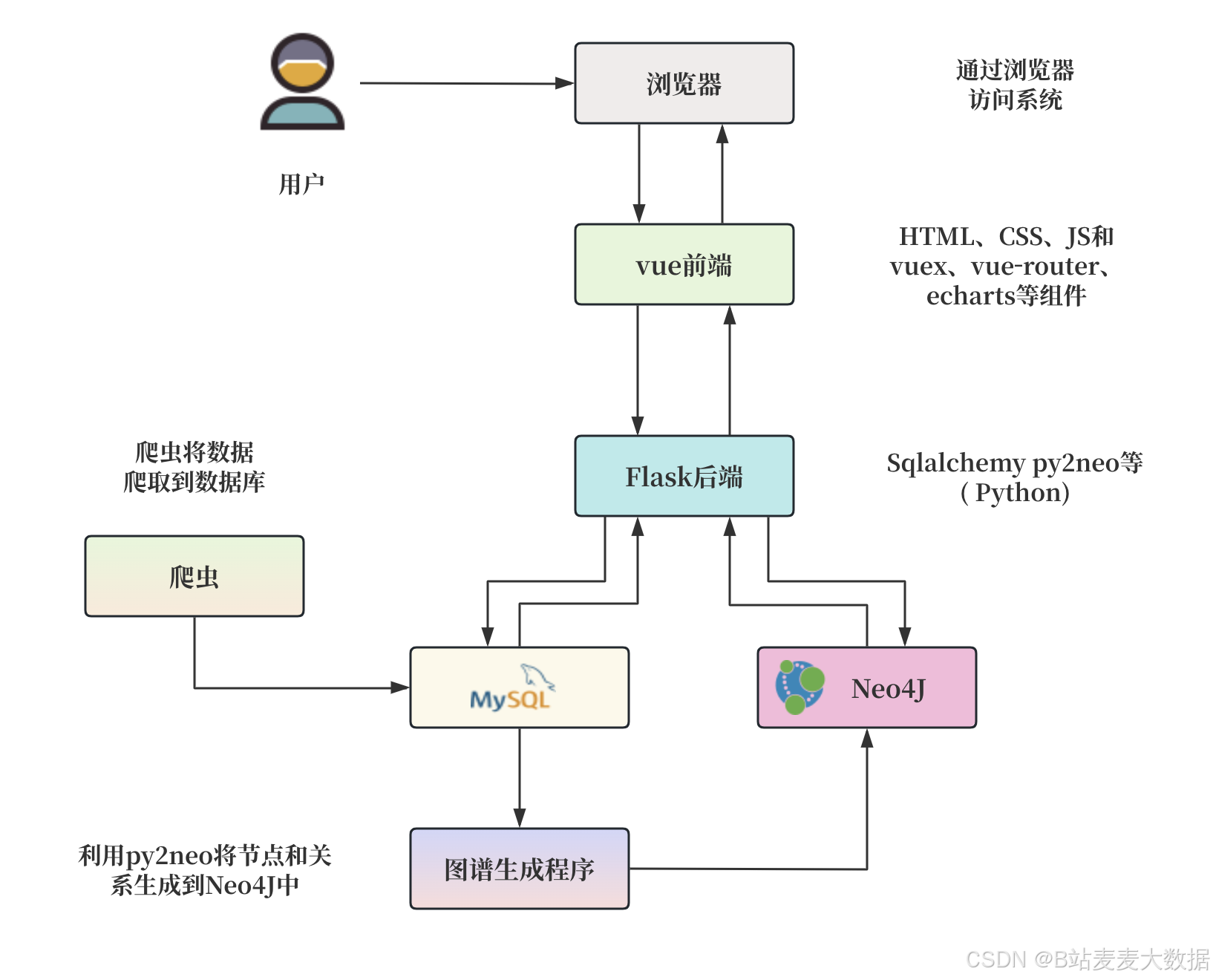
说明:系统整体分为三层------
- 前端展示层:Vue.js构建可视化界面,负责用户交互与数据展示。
- 业务逻辑层:Flask提供API接口,调用NLP模型与预测算法,完成数据处理与业务逻辑。
- 数据存储层:MySQL数据库存储实体数据,包括企业基本信息、舆情语料、风险评分、用户信息等。
2.2 功能模块图
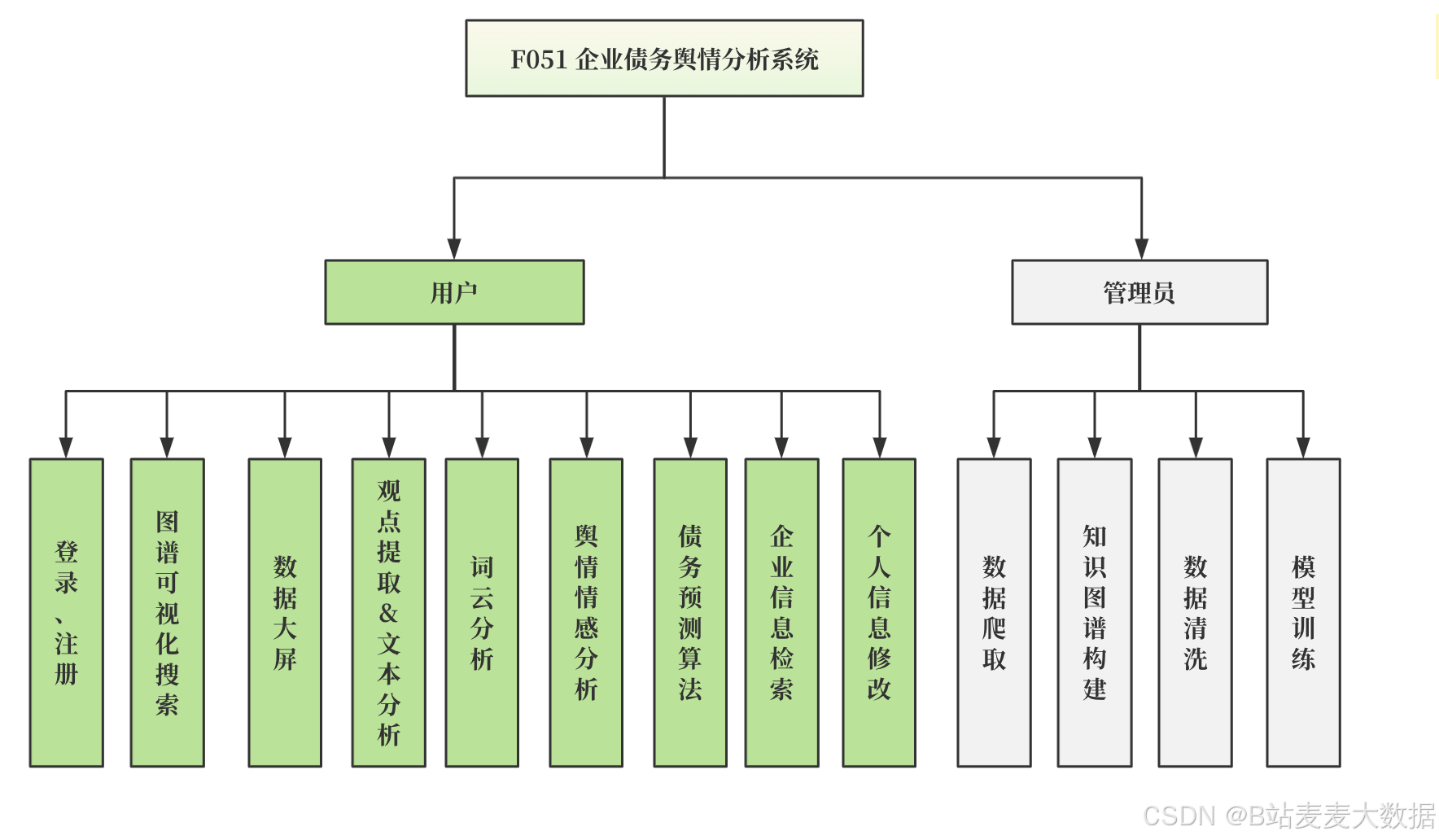
主要功能模块有:
- 企业信息管理
- 舆情数据采集与预处理
- 债务风险智能评分
- 风险趋势预测分析
- 可视化仪表盘展示
- 用户权限与登录注册
- 个人设置与消息通知
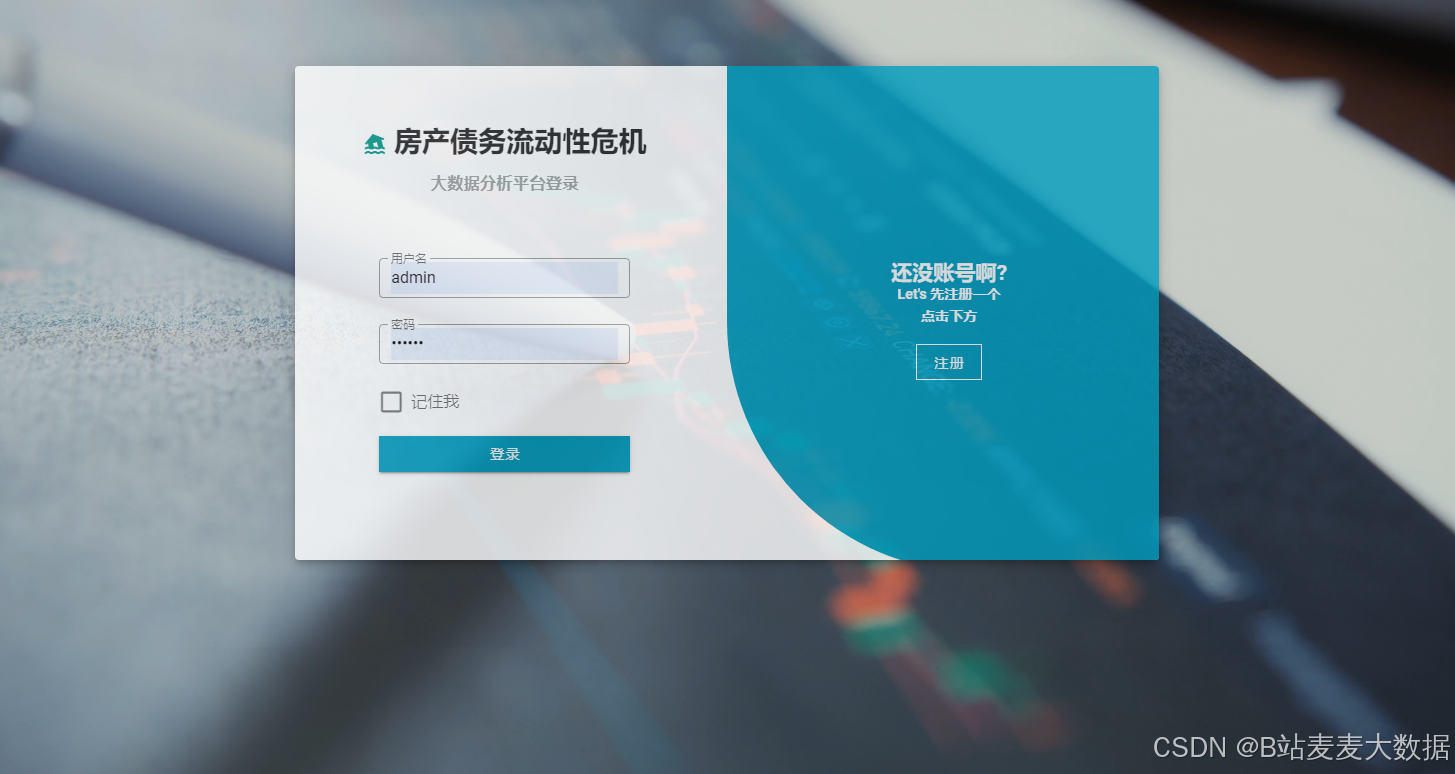
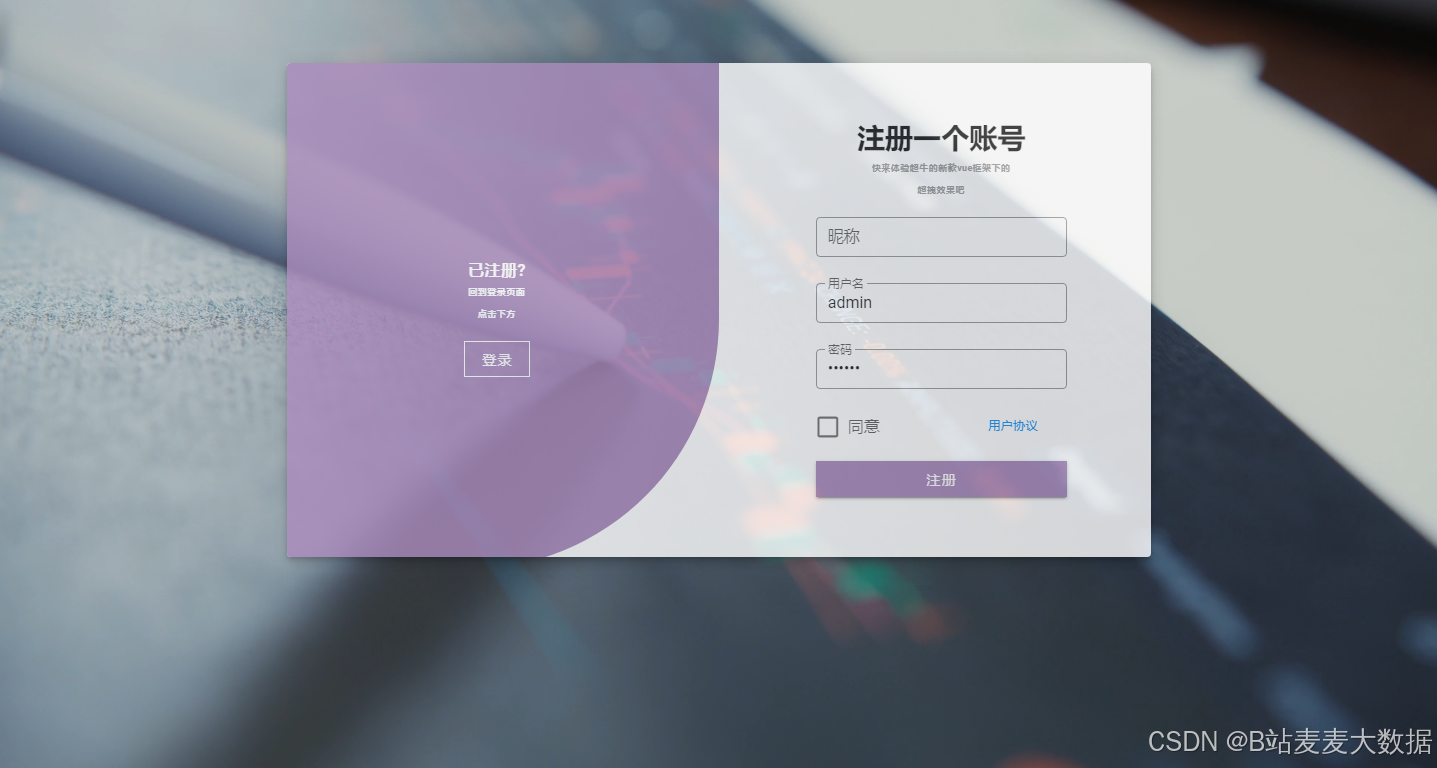
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击"去登录"或"去注册"可切换对应页面。
登录需要输入用户名和密码,系统后台对用户身份进行验证,通过后跳转至系统主界面。
注册功能允许新用户创建账号,需提供邮箱、用户名、密码等基本信息,并完成邮箱验证以确保账户真实性。
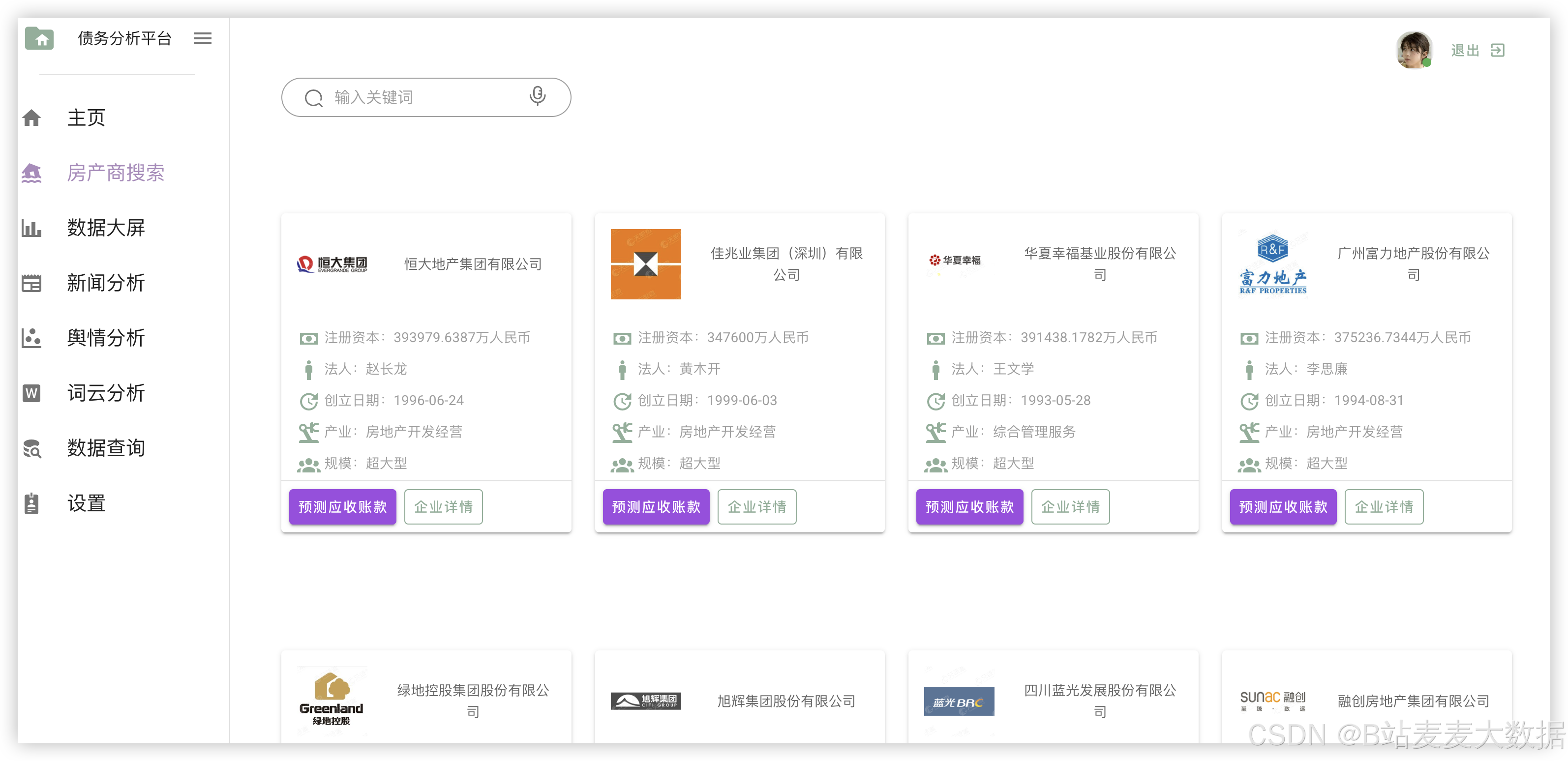
3.2 企业信息查询
企业信息管理模块用于维护企业基本信息,如企业名称、统一社会信用代码、行业类别、所在地区、注册资本等。用户可通过该模块进行企业信息的添加、查询、修改与删除操作。管理员还可导出企业信息为Excel文件,用于外部数据分析。
3.3 舆情数据采集与预处理
系统通过爬虫程序定期从新闻网站、社交媒体平台等渠道抓取企业相关的公开舆情数据。采集的数据包含文章标题、正文、发布时间、来源等信息。前端通过Vue调用Flask接口触发爬虫任务,爬虫将数据存储于MySQL数据库,并通过文本清洗(去除HTML标签、停用词、分词处理)预处理,为后续分析做准备。
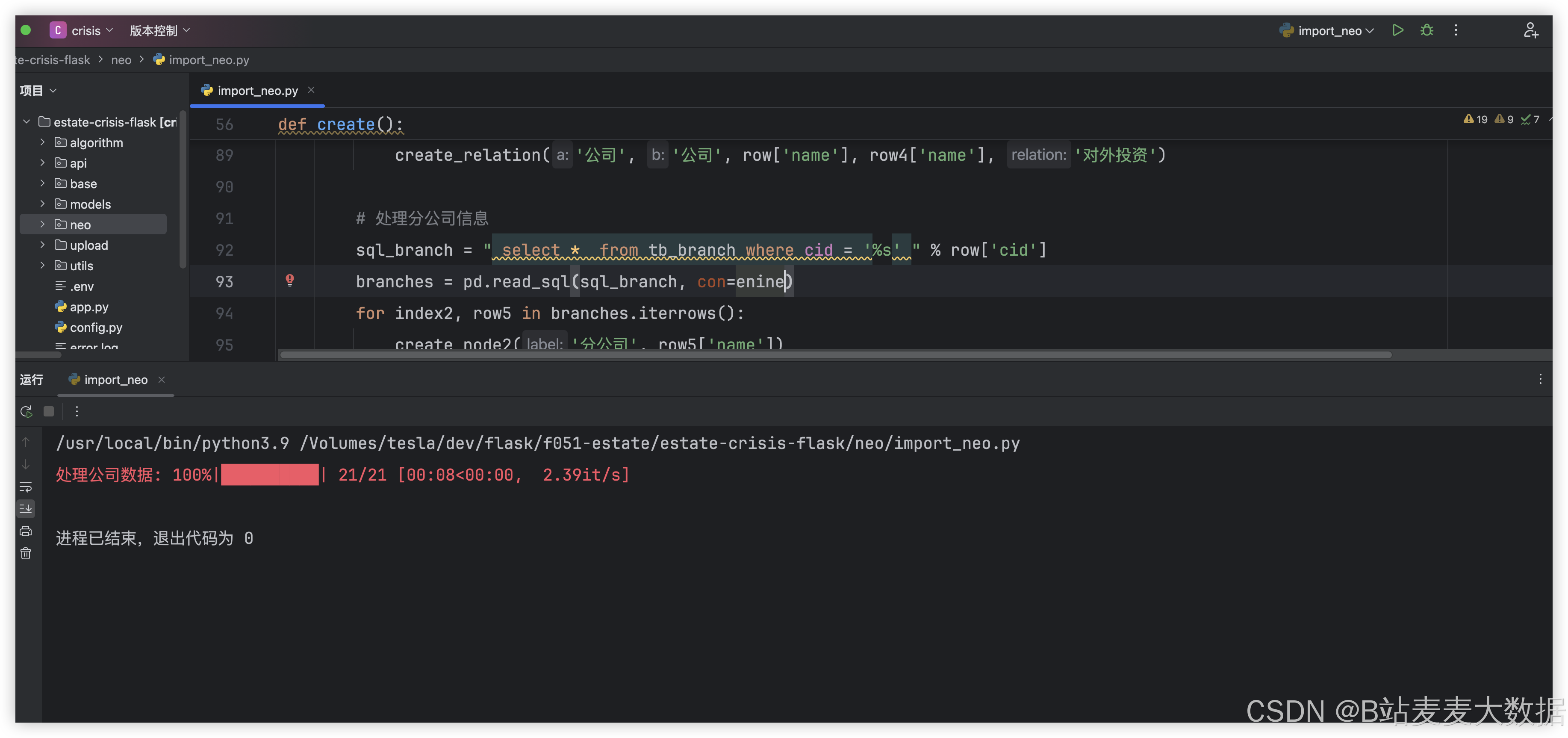
3.4 债务风险智能评分
系统利用NLP技术对清洗后的舆情文本进行情感分析和主题识别,判断内容是否与企业债务相关,并据此生成每条舆情的风险指数。结合BERT模型进行语义分类,综合历史舆情数据,最终计算出企业的总债务风险评分,分为低、中、高三个等级,便于用户快速评估。
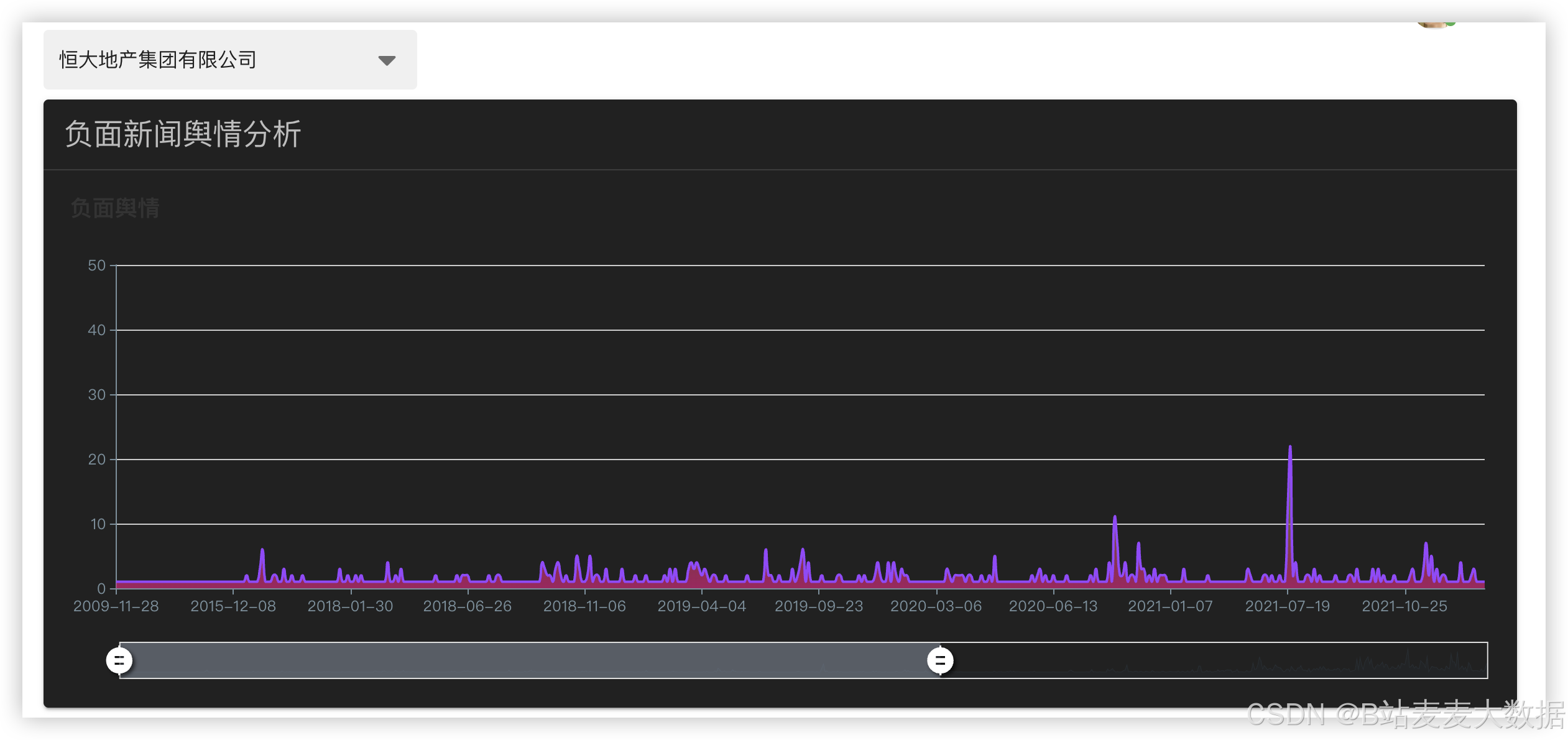

3.5 风险趋势预测分析
基于时间序列分析方法(如LSTM神经网络),系统对历史舆情风险评分进行建模,预测未来一段时间内企业债务风险的变化趋势。通过训练模型识别出风险上升或下降的潜在信号,为风险预警提供科学依据。
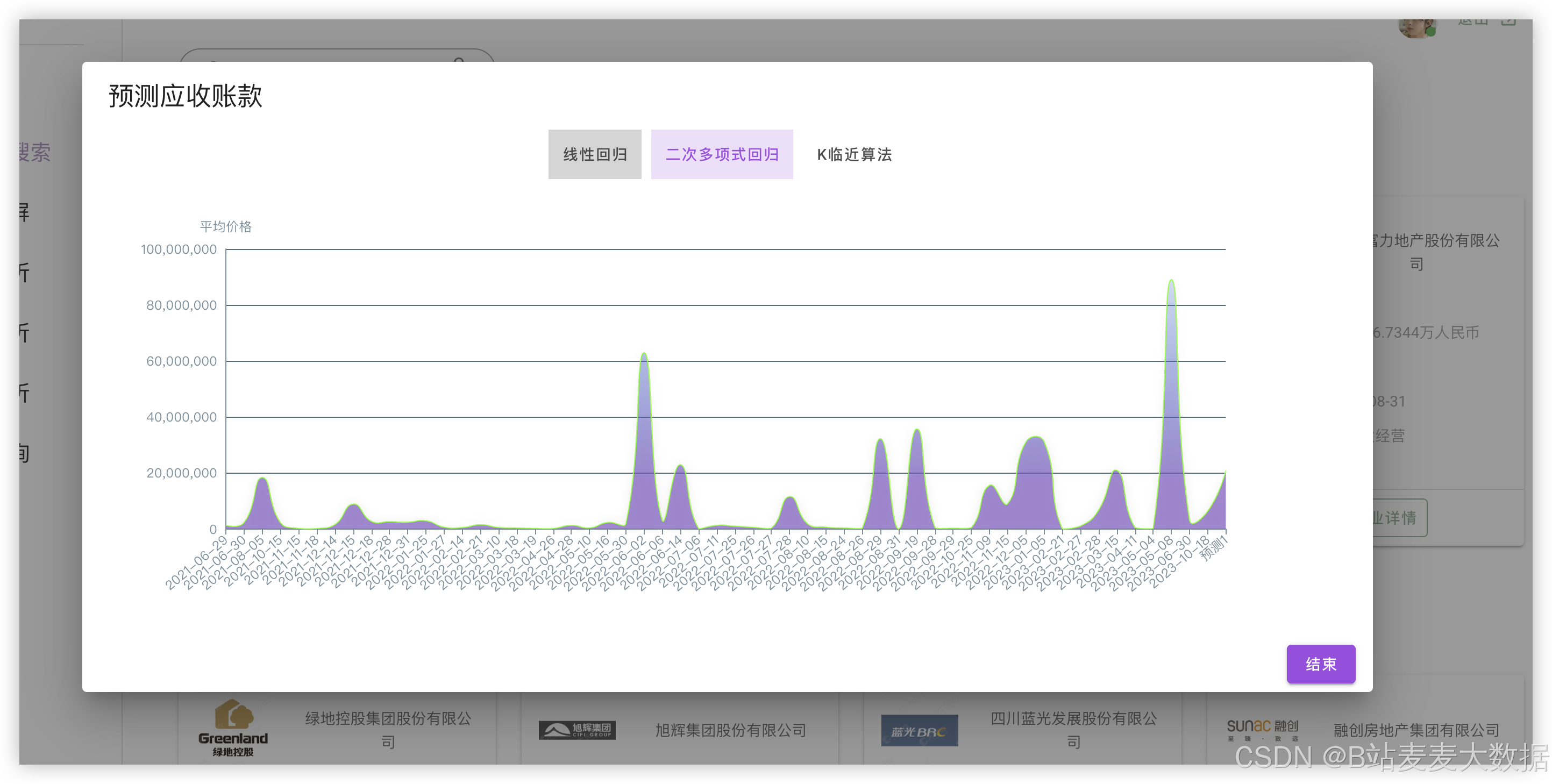
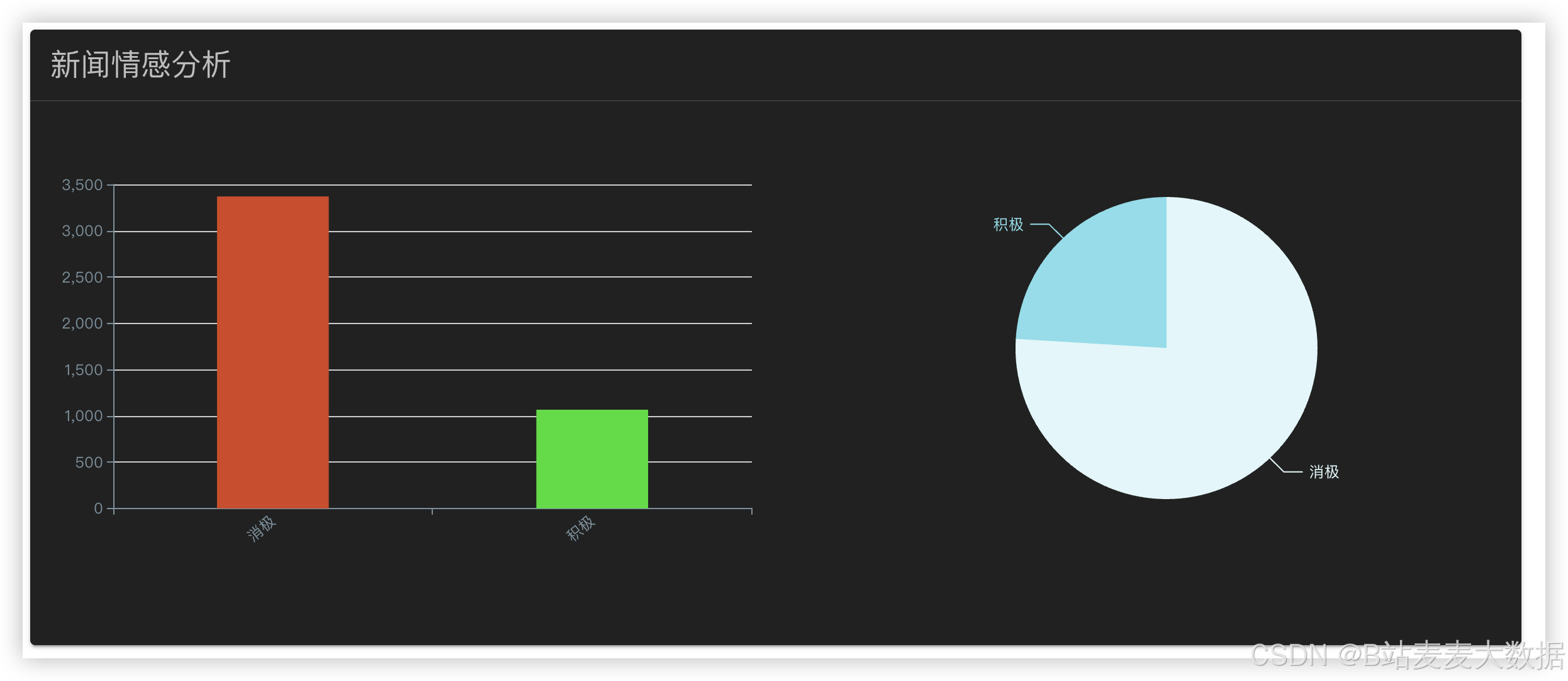
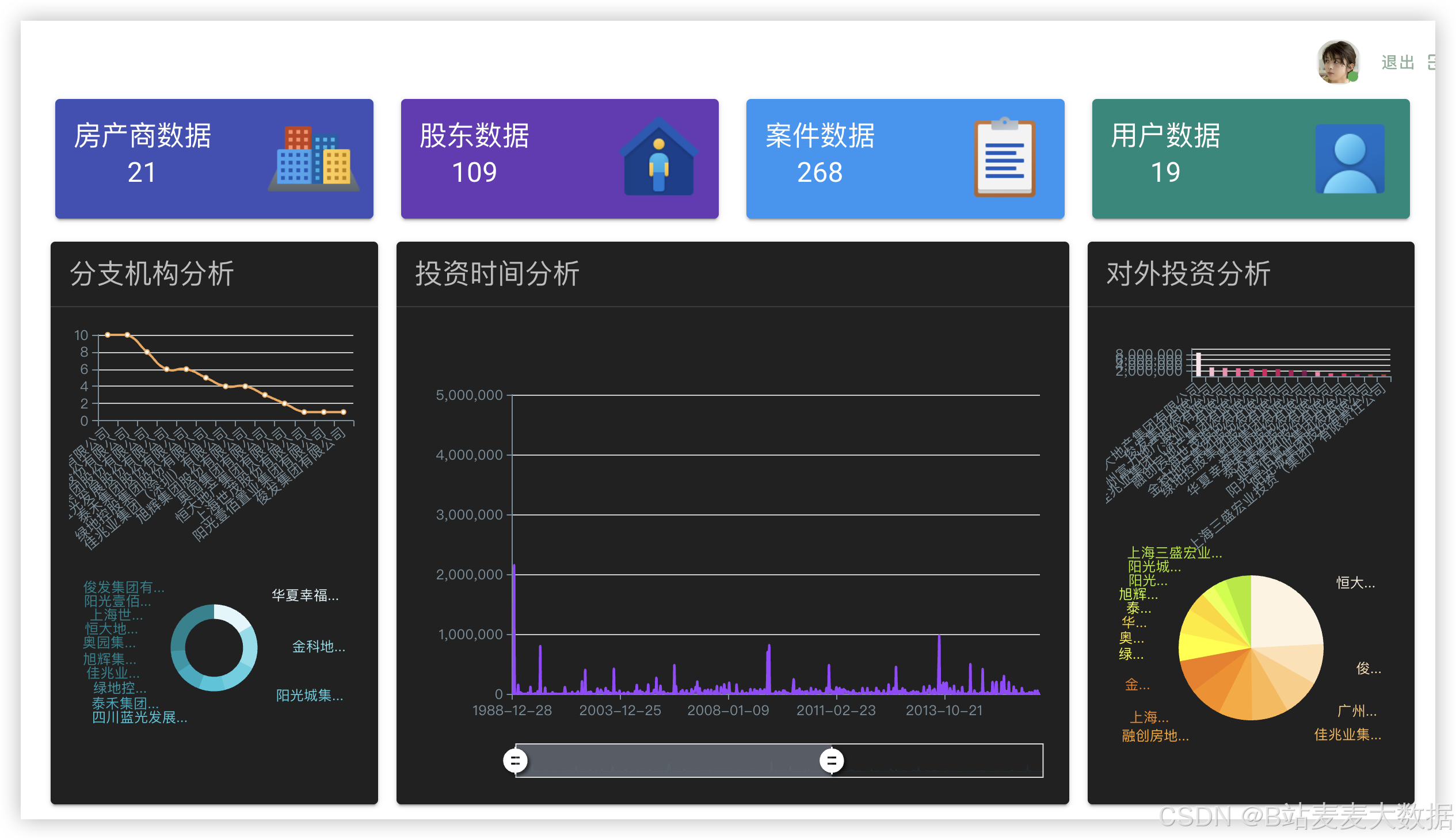
3.6 可视化仪表盘展示
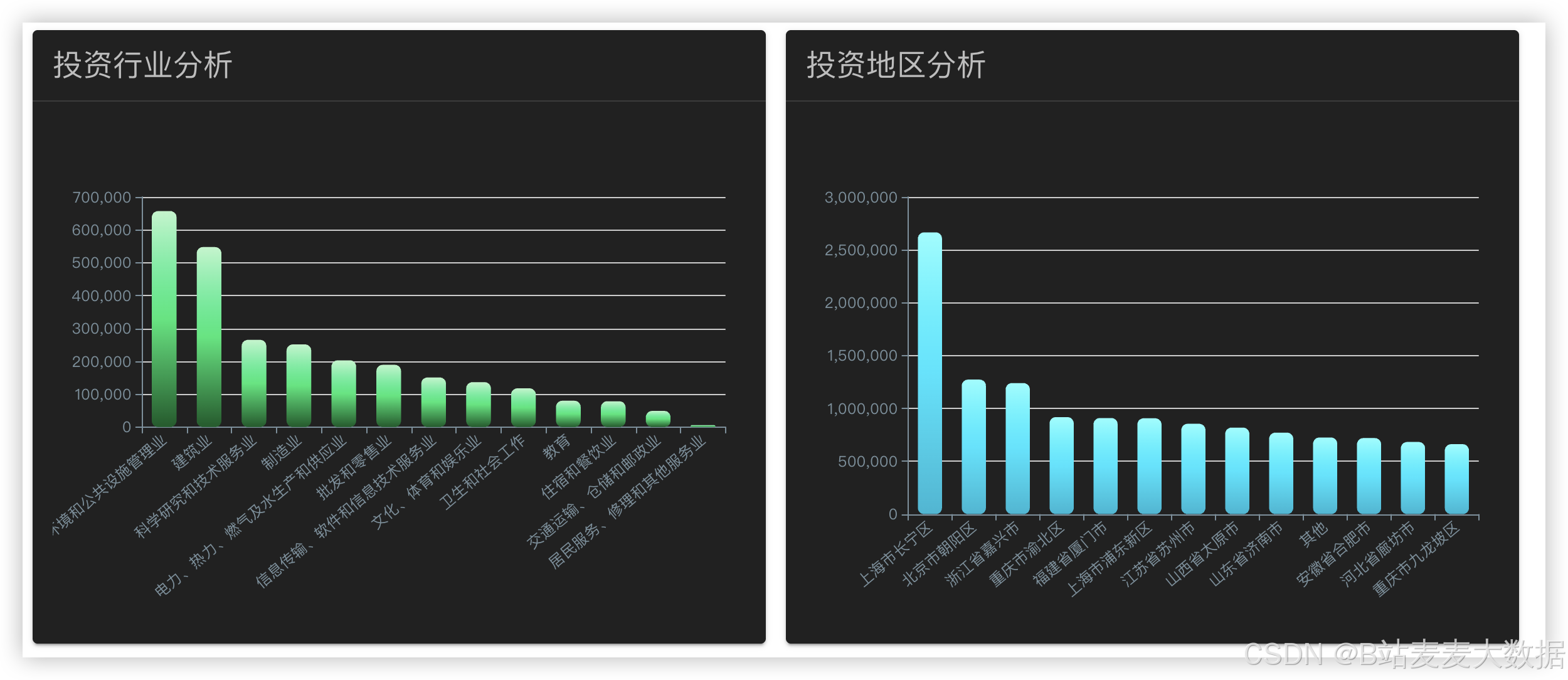
系统提供数据可视化功能,通过ECharts图表展示企业债务风险评分变化折线图、风险分布饼图、舆情热点词云图、预测趋势图等,帮助用户直观理解风险演化过程。用户可根据时间范围、企业名称等条件筛选数据,实现个性化分析。
3.7 个人设置
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息,如昵称、邮箱等。
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
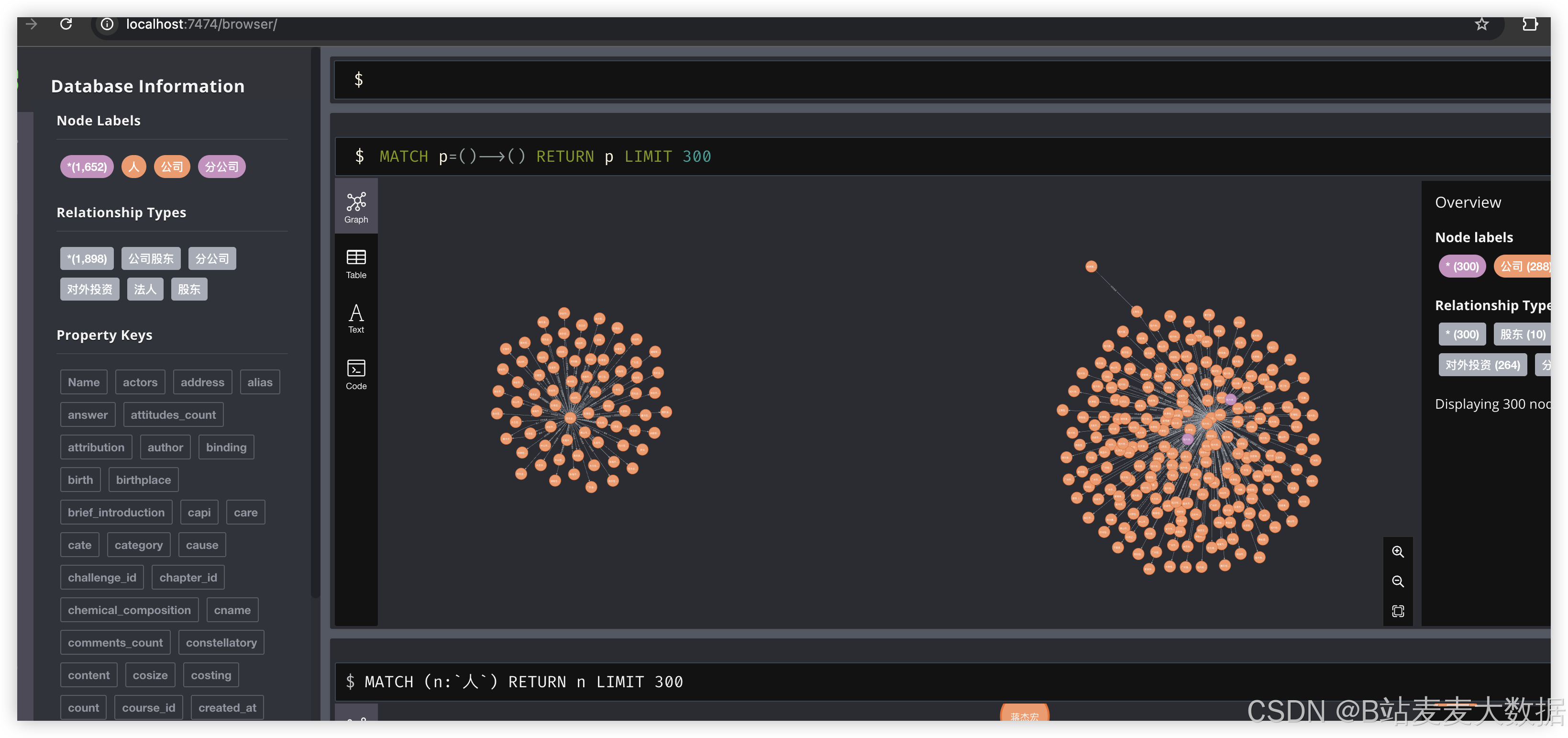
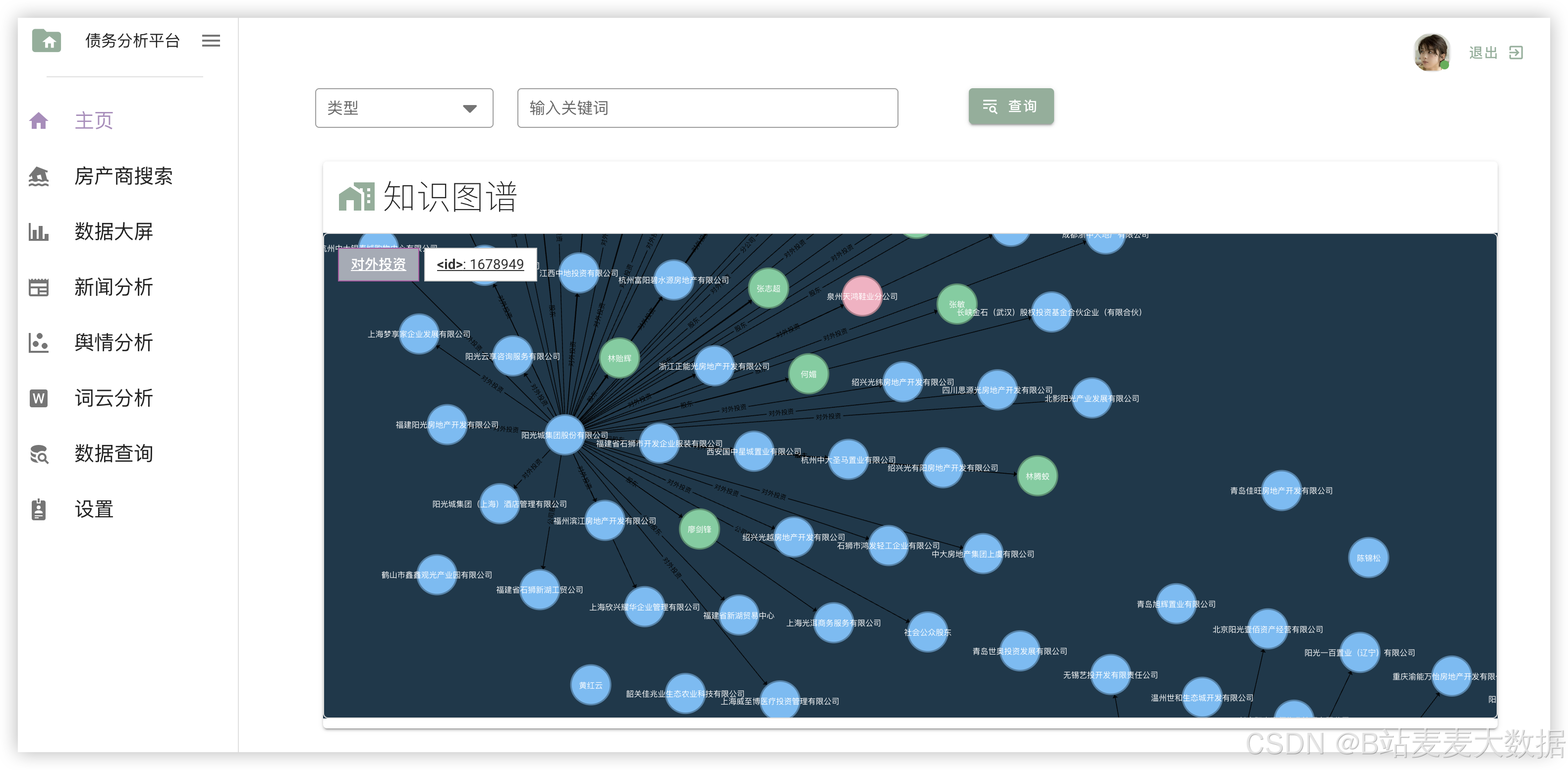
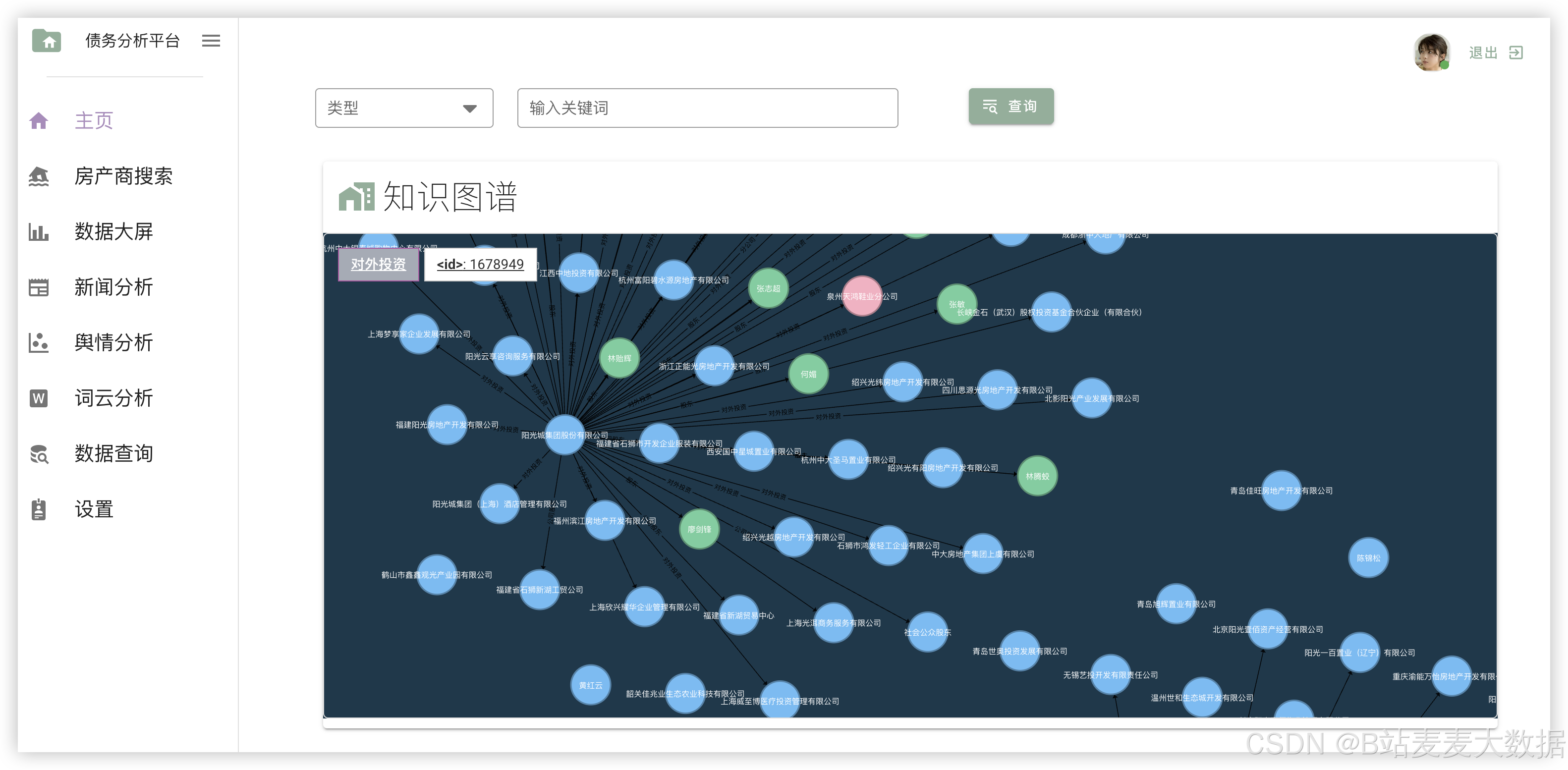
3.8 模型训练与知识图谱构建
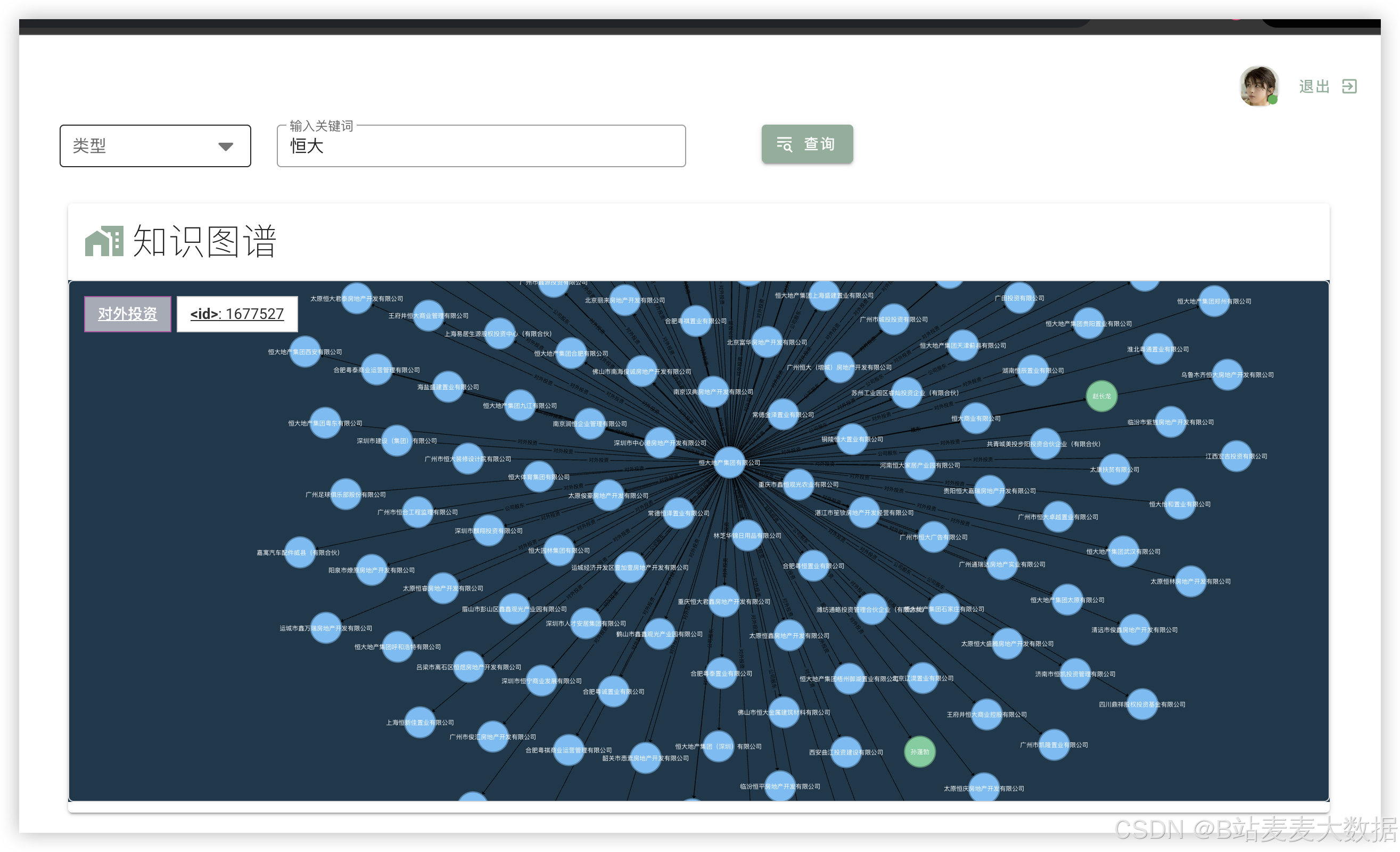
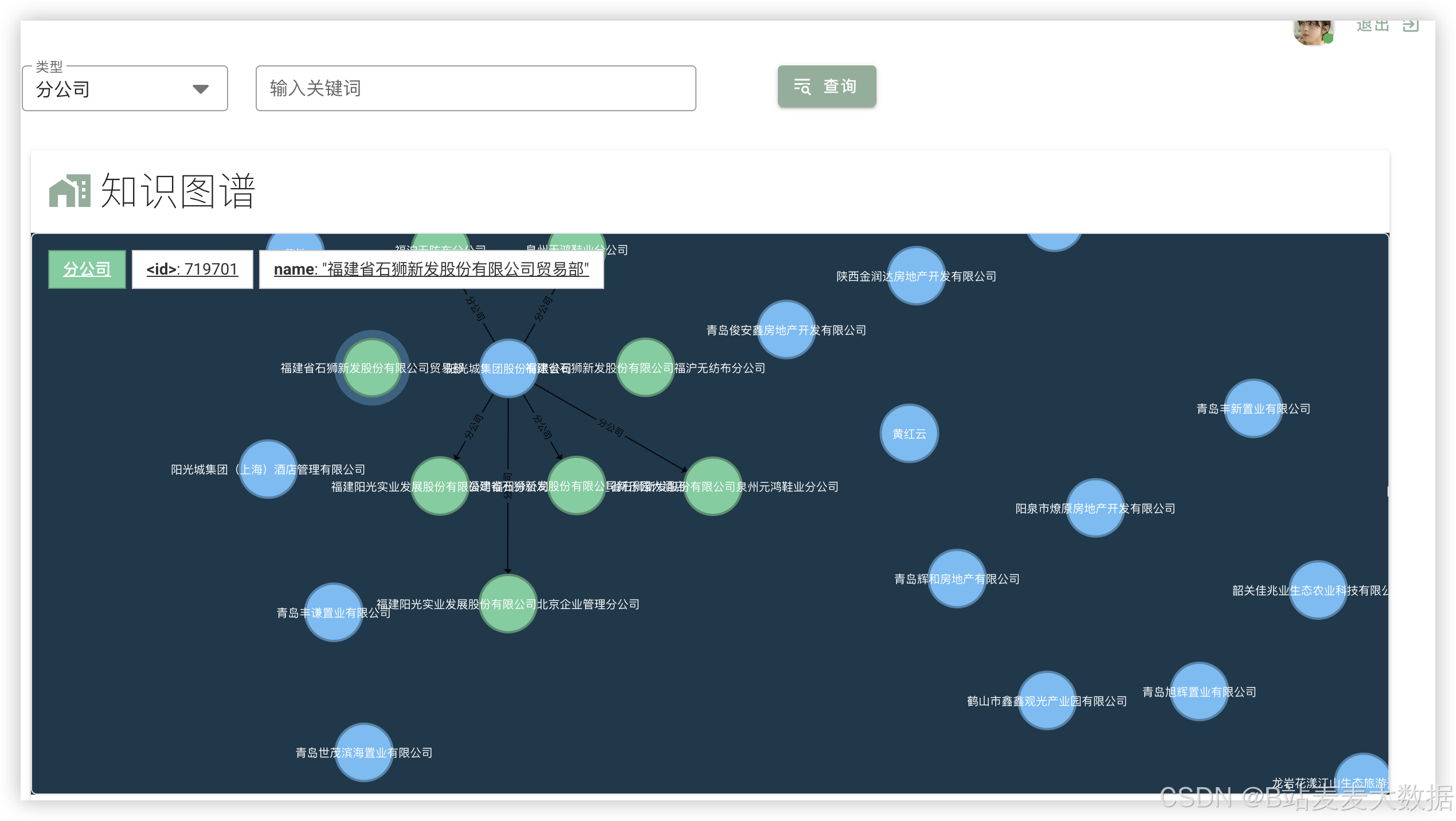
后端通过Python脚本(如图中所示的"图谱生成程序")对处理后的数据进行知识图谱构建,将企业、事件、关联实体等抽象为图结构。同时,支持用户在后台触发模型重新训练(如更新BERT分类器或LSTM预测模型),以提升预测精度。
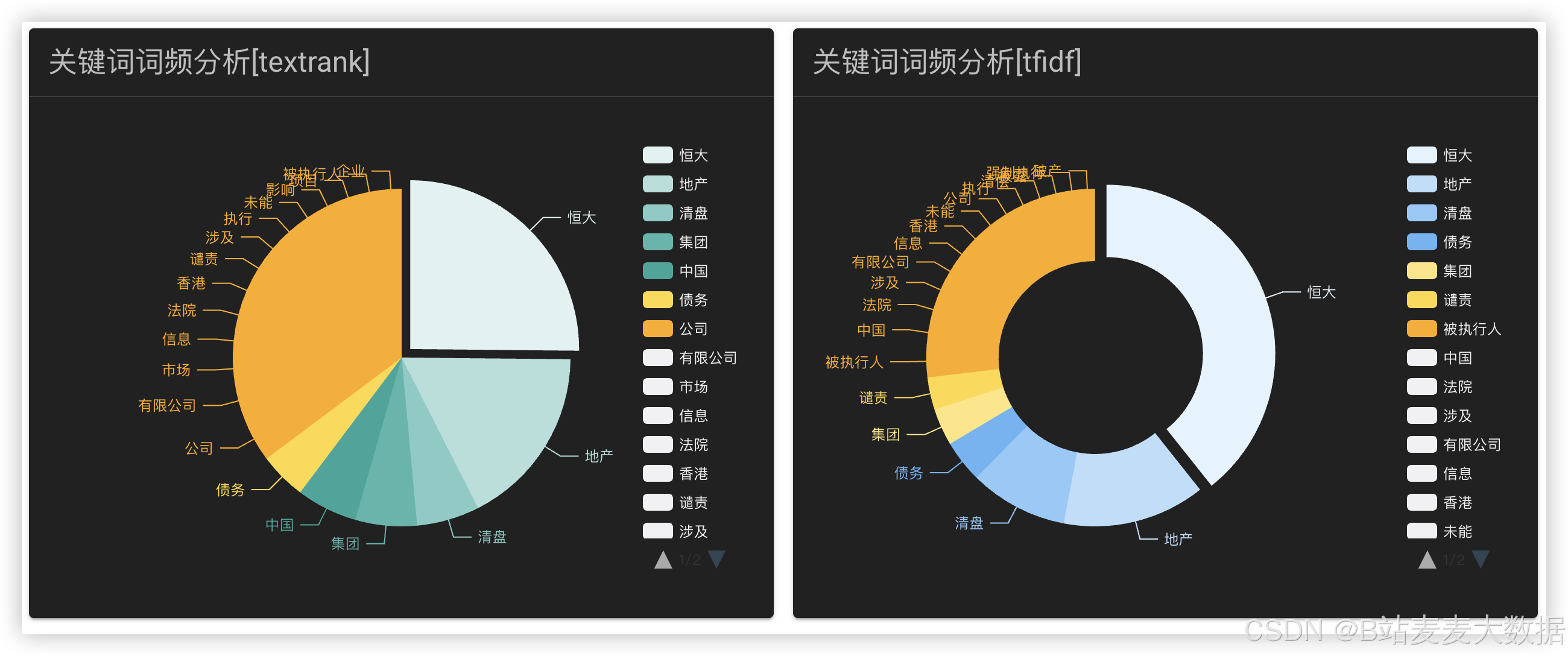
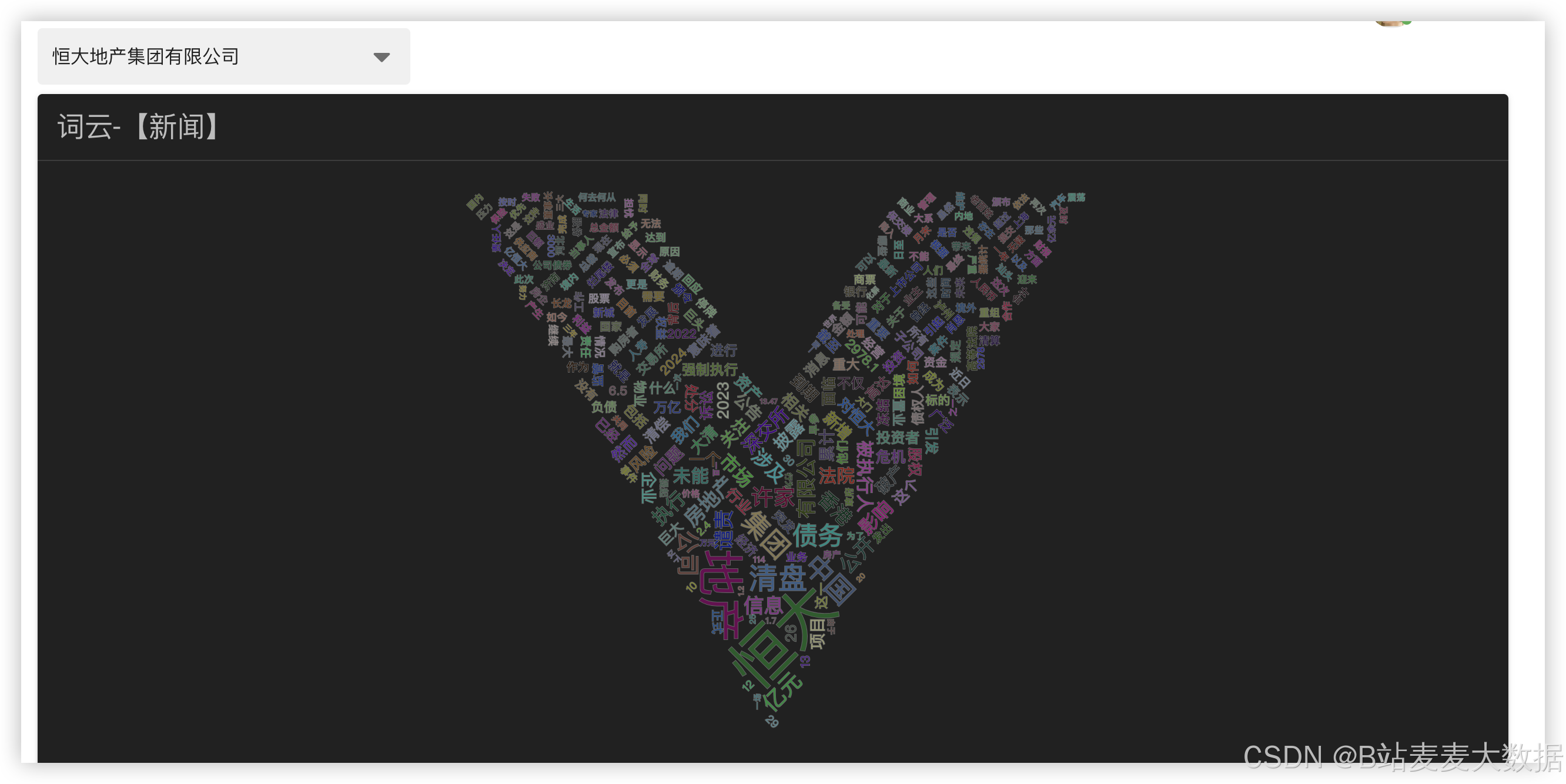
3.9 词云分析
系统通过知识图谱技术,将企业债务相关的关键词、事件、人物、地点等关联起来,形成结构化知识网络。词云图展示高频出现的债务相关词汇,帮助用户快速定位关注点。
4 程序核心算法代码
4.1 代码说明
代码介绍:系统核心算法包括舆情文本分类与风险预测两部分。
- 文本分类:使用Hugging Face Transformers库中的BERT模型,对舆情文本进行二分类(风险/非风险),并给出风险概率。
- 趋势预测:运用LSTM模型对连续时间点的债务风险评分进行建模,预测未来风险走向。
4.2 流程图
(此处插入核心算法流程图)
4.3 代码实例
python
# 使用BERT进行文本分类的示例代码
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载预训练模型
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 预处理输入文本
text = "某企业因债务违约被法院强制执行"
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
# 预测
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
print("风险预测结果:", "高风险" if predictions.item() == 1 else "低风险")
sql
-- 创建企业信息表
CREATE TABLE enterprises (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
credit_code VARCHAR(50) UNIQUE,
industry VARCHAR(50),
region VARCHAR(50),
capital DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建舆情数据表
CREATE TABLE舆情_data (
id INT PRIMARY KEY AUTO_INCREMENT,
enterprise_id INT,
title TEXT,
content TEXT,
source VARCHAR(100),
publish_time DATETIME,
risk_score FLOAT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (enterprise_id) REFERENCES enterprises(id)
);