1. 方案概述
1.1 方案介绍
基于欧拉操作系统的开源高可用容器云解决方案,采用欧拉服务器操作系统 openEuler 24.03 作为操作系统的安全底座,运行 Kubernetes 进行容器应用管理和监控,通过 Haproxy + Keepalived 实现高可用负载均衡访问 kubernetes API 接口,具备高度的可扩展性和容错性,能够自动进行容器的调度和恢复,确保应用的高可用性和稳定性。该解决方案包括了多种开源工具和技术,可以帮助企业实现应用的自动化部署、扩展、监控和日志管理,降低IT成本,并通过多种插件和扩展机制,方便地进行功能扩展和定制,满足企业不同的需求。Kubeadm是一个简单易用的安装工具,可用于快速搭建Kubernetes集群,目前是比较方便和推荐的方式。
1.2 方案架构图
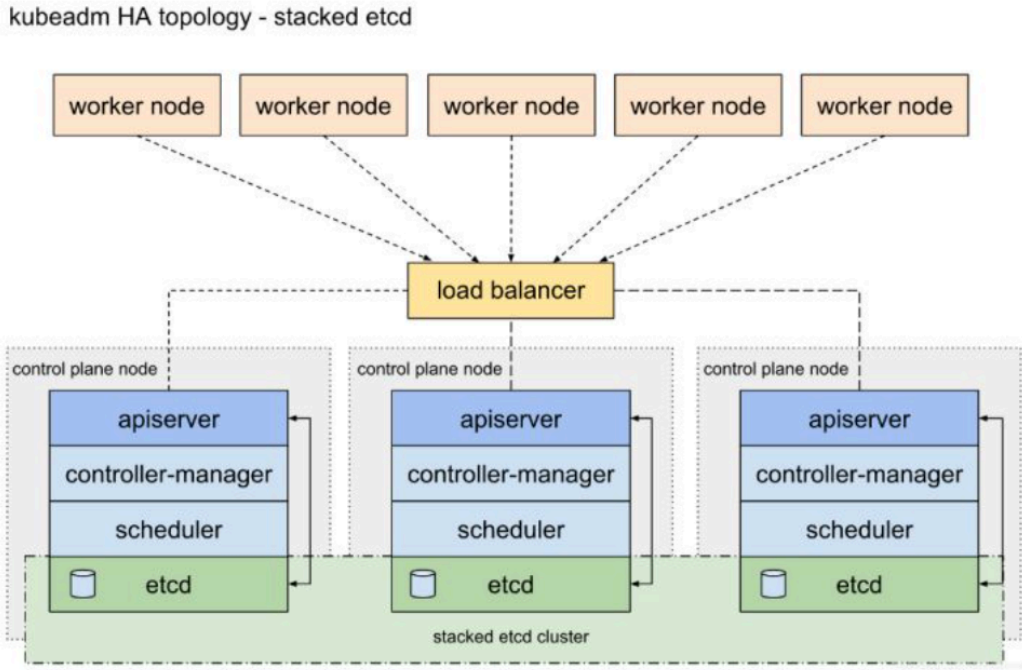
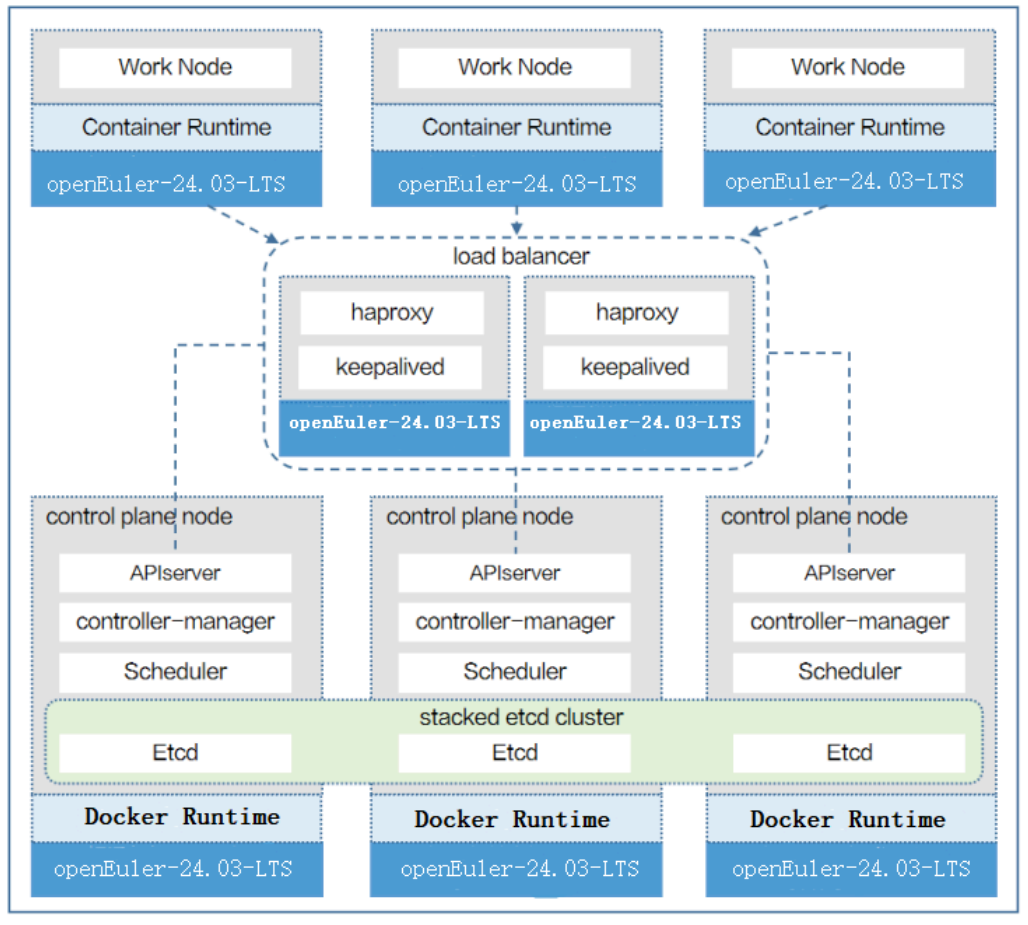
2.方案环境
2.1 操作系统环境
openEuler-24.03-LTS-x86_64-dvd.iso
2.2 硬件环境
自行准备5台具有2核CPU和4GB以上内存的服务器,硬盘大于50G,系统为openEuler-24.03,确保机器能够访问互联网。
| 主机名 | IP地址 | 说明 |
|---|---|---|
| master1 | 192.168.48.11 | master节点 |
| master2 | 192.168.48.12 | master节点 |
| master3 | 192.168.48.13 | master节点 |
| node01 | 192.168.48.14 | node节点 |
| node02 | 192.168.48.15 | node节点 |
| node02 | 192.168.48.16 | node节点 |
| 192.168.48.10 | VIP(虚拟IP) |
安装配置信息如下表所示:
| 配置信息 | 备注 |
|---|---|
| OS系统版本 | openEuler-24.03 |
| Docker版本 | 28.3.2 |
| Calico版本 | 3.29.0 |
| Kubernetes版本 | 1.32.7 |
3.方案部署
3.1 主机初始化
对所有主机进行初始化操作
3.1.1 配置IP
master1节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.11/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"master2节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.12/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"master3节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.13/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"node01节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.14/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"node02节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.15/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"node03节点:
nmcli connection modify "ens33" ipv4.method manual ipv4.addresses 192.168.48.16/24 ipv4.gateway 192.168.48.2 ipv4.dns "223.5.5.5 114.114.114.114 8.8.8.8" && nmcli connection down "ens33" && nmcli connection up "ens33"3.1.2 设置主机名
根据不同主机的角色,设置相应主机名
master1节点:
hostnamectl set-hostname master1master2节点:
hostnamectl set-hostname master2master3节点:
hostnamectl set-hostname master3node01节点:
hostnamectl set-hostname node01node02节点:
hostnamectl set-hostname node02node03节点:
hostnamectl set-hostname node033.1.3 设置域名解析
所有节点都配置hosts解析
cat >> /etc/hosts <<EOF
192.168.48.11 master1
192.168.48.12 master2
192.168.48.13 master3
192.168.48.14 node01
192.168.48.15 node02
192.168.48.16 node03
EOF3.1.4 关闭防火墙
所有节点都关闭防火墙
systemctl disable --now firewalld3.1.5 禁用SELinux
所有节点都禁用SELinux
setenforce 0
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config3.1.6 禁用swap
所有节点关闭Swap分区:
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab3.1.7 配置yum源
所有节点配置Docker和默认yum源:
# 换成阿里源
sed -i 's|http://repo.openeuler.org|https://mirrors.jxust.edu.cn/openeuler/|g' /etc/yum.repos.d/openEuler.repo
yum clean all && yum makecache
# 安装docker-ce依赖
dnf install -y device-mapper-persistent-data lvm2
# 添加 docker-ce源 openEuler24.03 对标centos9
dnf config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
sed -i 's+\$releasever+9+g' /etc/yum.repos.d/docker-ce.repo
dnf makecache3.1.8 安装常用的工具
所有节点安装一些常用的工具:
dnf install wget jq psmisc vim net-tools telnet git bash-completion -y3.1.9 配置NTP时间同步
所有节点时间同步,同步后date查看和自己的主机时间是否一致。
sed -i '3 s/^/# /' /etc/chrony.conf
sed -i '4 a server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl restart chronyd.service
systemctl enable chronyd.service
chronyc sources3.1.10 配置网络
cat > /etc/NetworkManager/conf.d/calico.conf << EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*
EOF
systemctl restart NetworkManager
# 参数解释
# 这个参数用于指定不由 NetworkManager 管理的设备。它由以下两个部分组成
# interface-name:cali*
# 表示以 "cali" 开头的接口名称被排除在 NetworkManager 管理之外。例如,"cali0", "cali1" 等接口不受 NetworkManager 管理。
# interface-name:tunl*
# 表示以 "tunl" 开头的接口名称被排除在 NetworkManager 管理之外。例如,"tunl0", "tunl1" 等接口不受 NetworkManager 管理。通过使用这个参数,可以将特定的接口排除在 NetworkManager 的管理范围之外,以便其他工具或进程可
以独立地管理和配置这些接口3.1.11 优化资源限制参数
所有节点配置
ulimit -SHn 65535
cat >> /etc/security/limits.conf << EOF
* soft nofile 100000
* hard nofile 100000
* soft nproc 65535
* hard nproc 65535
* soft memlock unlimited
* hard memlock unlimited
EOF3.1.12安装ipv相关工具
yum -y install ipvsadm ipset sysstat conntrack libseccomp
cat >> /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
# 加载模块,设置重启生效
systemctl restart systemd-modules-load.service
# 查看已加载模块
lsmod | grep --color=auto -e ip_vs -e nf_conntrack3.1.13 优化内核参数
sed -i '/net.ipv4.ip_forward/d' /etc/sysctl.conf
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
net.ipv4.conf.all.route_localnet = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
EOF
sysctl --system3.1.14 master1配置免密钥
安装过程中,生成配置文件和证书均在master1上操作,所以master1节点需要免密钥登录其他节点之后将文件传送到其他节点。
vim free-ssh.sh #!/bin/bash
# 安装 sshpass(如果未安装)
if ! command -v sshpass &> /dev/null; then
echo "正在安装 sshpass..."
dnf install -y sshpass || {
echo "安装 sshpass 失败,请检查网络或手动安装!"
exit 1
}
fi
# 定义目标主机和密码
IP_LIST=("192.168.48.11" "192.168.48.14" "192.168.48.15")
SSH_PASS="elysia123."
# 批量配置免密登录
for HOST in "${IP_LIST[@]}"; do
echo "正在配置 $HOST ..."
sshpass -p "$SSH_PASS" ssh-copy-id -o StrictHostKeyChecking=no -o ConnectTimeout=5 root@"$HOST" &> /dev/null
# 检查是否成功
if [ $? -eq 0 ]; then
echo "$HOST 配置成功!"
else
echo "$HOST 配置失败,请检查网络或密码!"
fi
done执行脚本:
chmod +x free-ssh.sh
sh free-ssh.sh3.2 Docker部署
3.2.1 Docker作为Runtime
所有节点都安装docker-ce
dnf install -y docker-ce由于新版Kubelet建议使用systemd,因此把Docker的CgroupDriver也改成systemd:
另外配置docker加速器;
cat > /etc/docker/daemon.json << 'EOF'
{
"registry-mirrors": [
"https://jsrg2e0s.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.anyhub.us.kg",
"https://dockerhub.jobcher.com",
"https://dockerhub.icu",
"https://docker.ckyl.me",
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"storage-driver": "overlay2",
"live-restore": true
}
EOF3.2.2 安装部署cri-docker
**注意:**K8s从1.24版本后不支持docker了,所以这里需要用cri-dockererd。
下载地址 :https://github.com/Mirantis/cri-dockerd/releases/
#1、下载 cri-docker
mkdir k8s && cd k8s
wget -c https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.16/cri-dockerd-0.3.16-3.fc35.x86_64.rpm
#2、安装 cri-docker
dnf install -y cri-dockerd-0.3.16-3.fc35.x86_64.rpm
#修改cri-docker 服务文件 /usr/lib/systemd/system/cri-docker.service
#ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://
ExecStart=/usr/bin/cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --container-runtime-endpoint fd://
#3、启动 cri-docker
systemctl daemon-reload
systemctl restart docker cri-docker.socket cri-docker
systemctl enable docker cri-docker3.2.3 K8S软件安装
#1、配置kubernetes源
#添加阿里云YUM软件源
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/repodata/repomd.xml.key
EOF
#2、查看所有可用的版本
yum list kubelet --showduplicates | sort -r |grep 1.32
#3、安装kubelet、kubeadm、kubectl、kubernetes-cni
dnf install -y kubelet kubeadm kubectl kubernetes-cni
#4、配置cgroup为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性,建议修#改如下文件内容。
#vim /etc/sysconfig/kubelet [全部设置下]
#---------------------
#添加KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
#---------------------
sudo cat > /etc/sysconfig/kubelet <<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF
#设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
systemctl enable kubelet
#-------------------------3.3 高可用配置
采用的是KeepAlived和HAProxy实现的高可用,所以需要安装KeepAlived和HAProxy。KeepAlived和HAProxy的节点可以和Master在同一个节点,也可以在不同的节点。
3.3.1 安装软件
所有Master节点通过yum安装HAProxy和KeepAlived:
yum install keepalived haproxy -y3.3.2 配置haproxy
所有Master节点配置HAProxy(详细配置可参考HAProxy官方文档,所有Master节点的HAProxy配置相同):
vim haproxy.sh#!/bin/bash
export APISERVER_SRC_PORT=6443
export APISERVER_DEST_PORT=16443
export MASTER1_ADDRESS=192.168.48.11
export MASTER2_ADDRESS=192.168.48.12
export MASTER3_ADDRESS=192.168.48.13
export APISERVER_VIP=192.168.48.10
cat > /etc/haproxy/haproxy.cfg << EOF
global
log 127.0.0.1 local2 info # 日志输出到本地syslog的local2设备,级别为info
chroot /var/lib/haproxy # 安全隔离目录
pidfile /var/run/haproxy.pid # PID文件路径
user haproxy # 运行用户
group haproxy # 运行组
daemon # 以守护进程运行
maxconn 100000 # 最大连接数
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin # 管理统计socket
defaults
log global # 继承全局日志配置
option dontlognull # 不记录空连接日志
option http-server-close # 允许HTTP连接复用
option forwardfor # 添加X-Forwarded-For头
option redispatch # 连接失败时重新分配
retries 3 # 失败重试次数
timeout http-request 10s # HTTP请求超时
timeout queue 1m # 请求排队超时
timeout connect 10s # 连接后端超时
timeout client 1m # 客户端超时
timeout server 1m # 服务端超时
timeout http-keep-alive 10s # Keep-Alive超时
timeout check 10s # 健康检查超时
maxconn 100000 # 每个进程最大连接数
listen kubernetes-apiserver
bind ${APISERVER_VIP}:${APISERVER_DEST_PORT}
mode tcp # TCP模式(非HTTP)
option tcplog # 记录TCP日志
log global # 继承全局日志
balance roundrobin # 轮询负载均衡算法
server master1 ${MASTER1_ADDRESS}:6443 check inter 3s rise 5 fall 2
server master2 ${MASTER2_ADDRESS}:6443 check inter 3s rise 5 fall 2
server master3 ${MASTER3_ADDRESS}:6443 check inter 3s rise 5 fall 2
listen stats
mode http # HTTP模式(统计页面)
bind *:1080 # 监听所有IP的1080端口
stats enable # 启用统计页面
log global # 继承全局日志
stats refresh 5s # 页面自动刷新间隔
stats realm HAProxy\ Statistics # 认证域提示信息
stats uri /haproxyadmin?stats # 统计页面URI
stats auth admin:admin # 登录凭据(用户名:密码)
EOF执行脚本:
chmod +x haproxy.sh
sh haproxy.sh3.3.3 允许绑定不存在地址
允许服务绑定一个本机不存在的IP地址
cat >> /etc/sysctl.conf << EOF
net.ipv4.ip_nonlocal_bind = 1
EOF
sysctl --system3.3.4 开启 haproxy
systemctl enable --now haproxy
systemctl status haproxy3.3.5 配置keepalived
所有Master节点配置KeepAlived,由于KeepAlived需要配置自身的IP地址和网卡名称,因此每个
KeepAlived节点的配置不一样。
这里使用脚本自动生成配置文件,不再为每个节点单独配置/etc/keepalived/keepalived.conf,注意,这里master1为主master节点,其他为备master节点。也就是说,在k8s的master节点都健康的情况下,虚拟IP(VIP)一般在master1节点的ens33网卡上。
vim keepalived.sh#!/bin/bash
# =============================================
# Keepalived 自动配置脚本
# 功能:根据当前节点IP自动配置MASTER/BACKUP角色
# 版本:1.1
# =============================================
# ----------------------------
# 网络配置部分
# ----------------------------
# 获取本机IP地址(适配不同Linux发行版)
export IP_ADDRESS=$(ip -o -4 addr show dev ens33 | awk '{print $4}' | cut -d'/' -f1)
# 集群配置参数
export MASTER_IP="192.168.48.11" # 主Master节点固定IP
export APISERVER_VIP="192.168.48.10" # 虚拟IP(VIP)
export INTERFACE="ens33" # 监听的网卡名称
# ----------------------------
# 角色判断逻辑
# ----------------------------
if [[ "$IP_ADDRESS" == "$MASTER_IP" ]]; then
# 主节点配置
ROLE="MASTER"
PRIORITY=200 # 主节点需要最高优先级
echo "[INFO] 当前节点被指定为MASTER节点 (优先级: ${PRIORITY})"
else
# 备份节点配置
ROLE="BACKUP"
PRIORITY=100 # 备份节点优先级应低于MASTER
echo "[INFO] 当前节点被指定为BACKUP节点 (优先级: ${PRIORITY})"
fi
# ----------------------------
# 生成Keepalived配置文件
# ----------------------------
cat > /etc/keepalived/keepalived.conf <<EOF
# =========================================
# Keepalived 主配置文件
# 自动生成时间:$(date)
# 当前节点角色:${ROLE}
# =========================================
global_defs {
router_id LVS_DEVEL_$(hostname) # 使用主机名作为唯一标识
script_user root # 脚本执行用户
enable_script_security # 启用脚本安全模式
}
# HAProxy健康检查脚本定义
vrrp_script check_haproxy {
script "killall -0 haproxy" # 检查haproxy进程是否存在
interval 1 # 检查间隔(秒)
weight -20 # 检查失败时优先级降低值
fall 3 # 连续3次失败视为故障
rise 2 # 连续2次成功恢复
}
# VRRP实例配置
vrrp_instance VI_1 {
state ${ROLE} # 实例角色(MASTER/BACKUP)
interface ${INTERFACE} # 绑定的物理网卡
virtual_router_id 100 # 虚拟路由ID(集群内必须一致)
priority ${PRIORITY} # 选举优先级(值越大优先级越高)
advert_int 1 # 通告间隔(秒)
# 认证配置
authentication {
auth_type PASS # 认证类型(PASS/AH)
auth_pass 1111 # 认证密码(集群内必须一致)
}
# 虚拟IP配置
virtual_ipaddress {
${APISERVER_VIP} dev ${INTERFACE} label ${INTERFACE}:1 # VIP绑定到网卡
}
# 跟踪脚本
track_script {
check_haproxy # 关联健康检查脚本
}
}
EOF
# ----------------------------
# 后续操作提示
# ----------------------------
echo "[SUCCESS] Keepalived配置已生成: /etc/keepalived/keepalived.conf"
echo "[NOTICE] 请执行以下命令启动服务:"
echo " systemctl restart keepalived && systemctl enable keepalived"
echo "[TIP] 检查VIP是否绑定: ip addr show ${INTERFACE}"执行脚本:
chmod +x keepalived.sh
sh keepalived.sh3.3.6 开启 keepalived
systemctl enable --now keepalived
systemctl status keepalived3.4 K8S集群配置
3.4.1 K8S集群初始化
只在master1节点上操作,创建初始化文件 kubeadm-init.yaml
kubeadm config print init-defaults > kubeadm-init.yamlvim kubeadm-init.yaml
修改如下配置:
- advertiseAddress:为控制平面地址,( Master 主机 IP )
advertiseAddress: 1.2.3.4
修改为 advertiseAddress: 192.168.48.11
- criSocket:为 containerd 的 socket 文件地址
criSocket: unix:///var/run/containerd/containerd.sock
修改为 criSocket: unix:///var/run/cri-dockerd.sock
- name: node 修改node为 master1
name: node
修改为 name: master1
- imageRepository:阿里云镜像代理地址,否则拉取镜像会失败
imageRepository: registry.k8s.io
修改为:imageRepository: registry.aliyuncs.com/google_containers
- kubernetesVersion:为 k8s 版本
kubernetesVersion: 1.32.0
修改为:kubernetesVersion: 1.32.7
注意:一定要配置镜像代理,否则会由于防火墙问题导致集群安装失败
文件末尾增加启用ipvs功能
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs根据配置文件启动 kubeadm 初始化 k8s
kubeadm init --config=kubeadm-init.yaml --upload-certs --v=6#以下为成功输出
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join 192.168.48.10:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:22c8a8a58a99b311d5c0ec8226fa13c4ce44ec62b784bda930ea92c31b41e207 \
--control-plane --certificate-key bc9ff7662cb9e3d01fc7f9ee35f3cadc878df3bce55ead7344a12c6261485f81
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.48.10:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:22c8a8a58a99b311d5c0ec8226fa13c4ce44ec62b784bda930ea92c31b41e207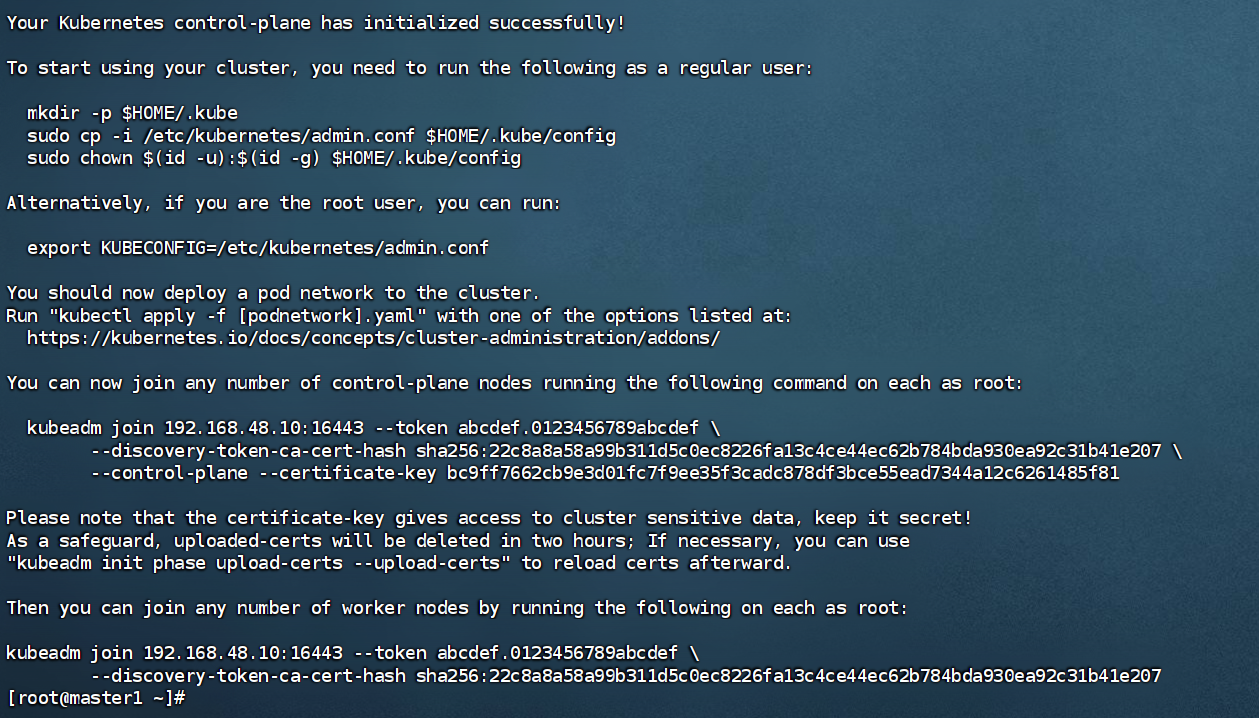
3.4.2 配置kubectl
只在master1上操作
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config3.4.3 配置证书
把主master1节点证书分别复制到其他2个master节点
scp /etc/kubernetes/pki/ca.* root@master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.* root@master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@master2:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.* root@master3:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@master2:/etc/kubernetes/
scp /etc/kubernetes/admin.conf root@master3:/etc/kubernetes/
把主master01节点证书分别复制到其他 node节点
scp /etc/kubernetes/admin.conf root@node01:/etc/kubernetes/
scp /etc/kubernetes/admin.conf root@node02:/etc/kubernetes/3.4.5 其他master节点加入集群
分别在master1 和 master2 上执行:
kubeadm join 192.168.48.10:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:22c8a8a58a99b311d5c0ec8226fa13c4ce44ec62b784bda930ea92c31b41e207 \
--control-plane --certificate-key bc9ff7662cb9e3d01fc7f9ee35f3cadc878df3bce55ead7344a12c6261485f81 \
--cri-socket unix:///var/run/cri-dockerd.sock
本文使用docker 需要添加 --cri-socket unix:///var/run/cri-dockerd.sock
# 配置kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config3.4.6 node节点加入集群
在node01,node02,node03上执行
kubeadm join 192.168.48.10:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:22c8a8a58a99b311d5c0ec8226fa13c4ce44ec62b784bda930ea92c31b41e207 \
--cri-socket unix:///var/run/cri-dockerd.sock3.4.7 查看集群状态
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane 164m v1.32.7
master2 Ready control-plane 151m v1.32.7
master3 Ready control-plane 150m v1.32.7
node01 Ready <none> 149m v1.32.7
node02 Ready <none> 148m v1.32.7
node03 Ready <none> 148m v1.32.7
# 查看容器运行时
[root@master1 ~]# kubectl describe node | grep Runtime
Container Runtime Version: docker://28.3.2
Container Runtime Version: docker://28.3.2
Container Runtime Version: docker://28.3.2
Container Runtime Version: docker://28.3.2
Container Runtime Version: docker://28.3.2
Container Runtime Version: docker://28.3.2
3.5 K8S集群网络插件使用
3.5.1 下载calico.yaml
只在master1上操作,此次可能需要科学上网
curl -O -L https://raw.githubusercontent.com/projectcalico/calico/v3.29.0/manifests/calico.yaml3.5.2 拉取镜像
查看安装calico需要的镜像
[root@master1 3.29]# grep -i image: calico.yaml
image: docker.io/calico/cni:v3.29.0
image: docker.io/calico/cni:v3.29.0
image: docker.io/calico/node:v3.29.0
image: docker.io/calico/node:v3.29.0
image: docker.io/calico/kube-controllers:v3.29.0提前拉取这三个镜像:
image: docker.io/calico/cni:v3.29.0
image: docker.io/calico/node:v3.29.0
image: docker.io/calico/kube-controllers:v3.29.0docker pull docker.io/calico/cni:v3.29.0
docker pull docker.io/calico/node:v3.29.0
docker pull docker.io/calico/kube-controllers:v3.29.03.5.3 部署calico网络
kubectl apply -f calico.yaml这里要等待一段时间,5分钟左右吧,取决于你的网络环境。切记,科学上网后一定要及时关闭有关的http代理,因为k8s的apiserver也是通过http协议通信的,错误的http代理设置有可能导致集群通信异常。
3.5.4 检查
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane 166m v1.32.7
master2 Ready control-plane 154m v1.32.7
master3 Ready control-plane 153m v1.32.7
node01 Ready <none> 152m v1.32.7
node02 Ready <none> 151m v1.32.7
node03 Ready <none> 151m v1.32.7
[root@master1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5c58b547d5-4fv2t 1/1 Running 8 (98m ago) 139m
calico-node-4g6f4 1/1 Running 2 (99m ago) 139m
calico-node-7dkh5 1/1 Running 1 (98m ago) 139m
calico-node-86lgk 1/1 Running 0 139m
calico-node-f8r8d 1/1 Running 0 139m
calico-node-jb7xs 1/1 Running 4 (105m ago) 139m
calico-node-tznf4 1/1 Running 0 139m
coredns-6766b7b6bb-gh7zn 1/1 Running 4 (105m ago) 167m
coredns-6766b7b6bb-twg78 1/1 Running 4 (105m ago) 167m
etcd-master1 1/1 Running 4 (105m ago) 167m
etcd-master2 1/1 Running 2 (99m ago) 154m
etcd-master3 1/1 Running 1 (98m ago) 154m
kube-apiserver-master1 1/1 Running 6 (98m ago) 167m
kube-apiserver-master2 1/1 Running 3 (98m ago) 154m
kube-apiserver-master3 1/1 Running 3 (98m ago) 154m
kube-controller-manager-master1 1/1 Running 5 (99m ago) 167m
kube-controller-manager-master2 1/1 Running 2 (99m ago) 154m
kube-controller-manager-master3 1/1 Running 2 (98m ago) 154m
kube-proxy-5wgsl 1/1 Running 4 (105m ago) 167m
kube-proxy-j7fn6 1/1 Running 0 152m
kube-proxy-nzjxr 1/1 Running 0 152m
kube-proxy-st449 1/1 Running 2 (99m ago) 154m
kube-proxy-vr22m 1/1 Running 0 152m
kube-proxy-vtqss 1/1 Running 1 (98m ago) 154m
kube-scheduler-master1 1/1 Running 4 (105m ago) 167m
kube-scheduler-master2 1/1 Running 2 (99m ago) 154m
kube-scheduler-master3 1/1 Running 2 (98m ago) 154m
node节点为ready,k8s核心组件全部running。
到此,k8s已经大致安装完毕了,还有常用组件比如helm,dashboard,Metrics-Server,ingress等按需求到官网安装即可。
4.方案验证
关闭任意master节点,vip漂移,k8s集群正常运行。
4.1 关闭master1节点
init 0登录haproxy
http://192.168.48.10:1080/haproxyadmin?stats
用户:admin
密码:admin
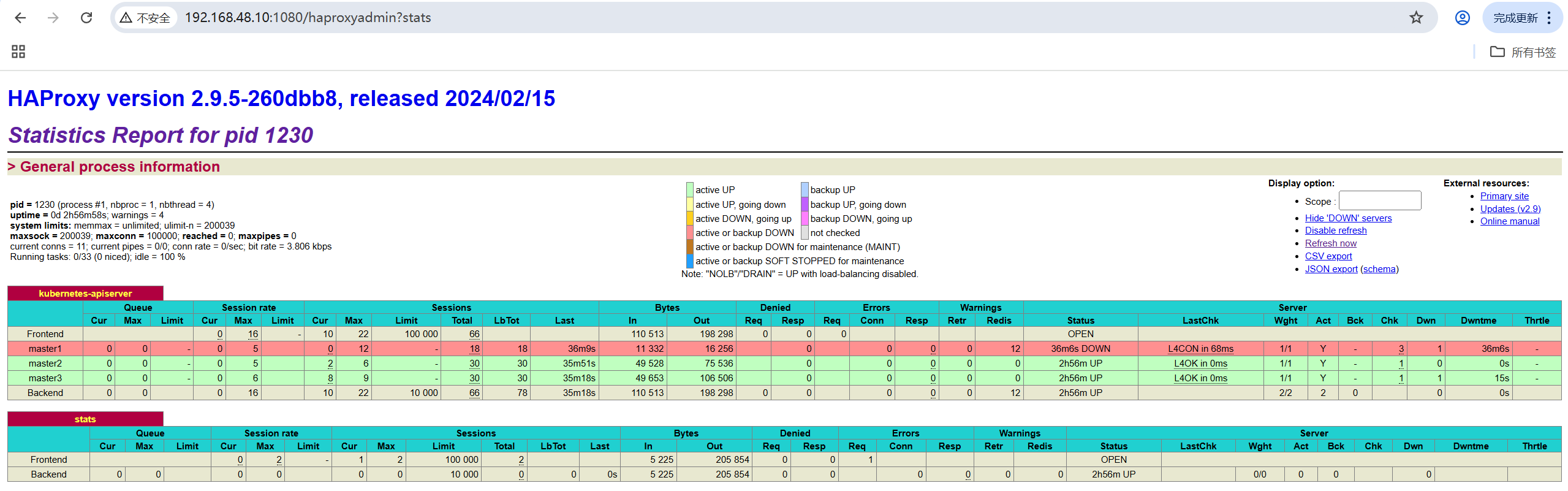
4.2 验证VIP漂移
VIP漂移至其他master节点,本次为master3。
VIP漂移至master3:
[root@master3 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:c9:d5:e4 brd ff:ff:ff:ff:ff:ff
inet 192.168.48.13/24 brd 192.168.48.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.48.10/32 scope global ens33:1
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fec9:d5e4/64 scope link noprefixroute
valid_lft forever preferred_lft forever4.3 验证高可用
master2节点验证:
[root@master2 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane 3h30m v1.32.7
master2 Ready control-plane 3h18m v1.32.7
master3 Ready control-plane 3h17m v1.32.7
node01 Ready <none> 3h15m v1.32.7
node02 Ready <none> 3h15m v1.32.7
node03 Ready <none> 3h15m v1.32.7master1j节点状态为NotReady,符合预期,openeuler24.03,k8s1.32.7高可用集群(三主三从)部署完毕。