最近在学习 Vue3 的源码时,发现compiler-core模块是一个非常重要的部分,其负责将 Vue 模板编译成渲染函数。这个模块的核心功能是将模板字符串转换为 JavaScript 渲染函数,这个过程涉及到解析模板、生成 AST(抽象语法树)、优化 AST 以及最终生成渲染函数。
整体理解:compiler-core是函数,输入是模板字符串,输出是渲染函数字符串
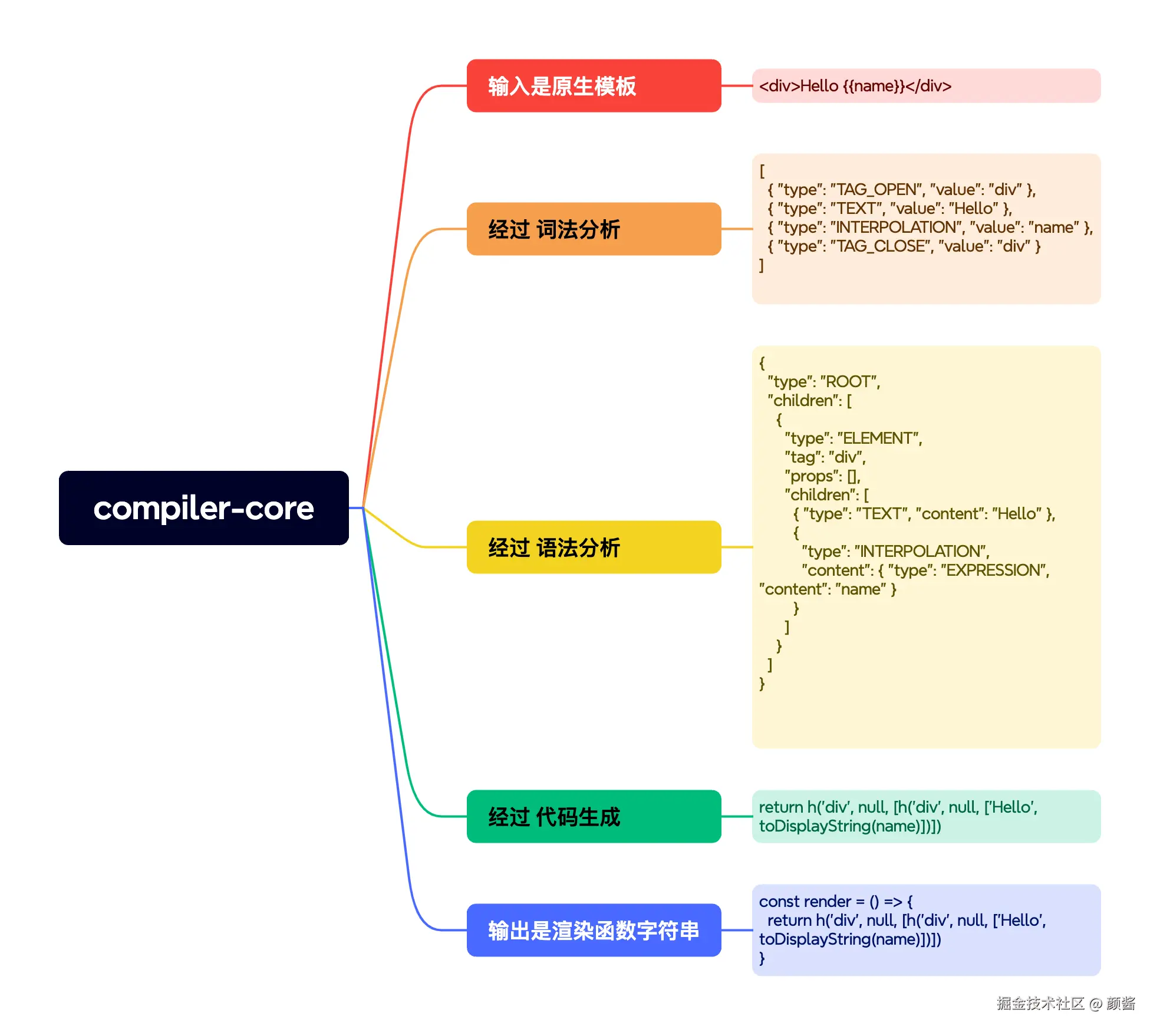
可以简单理解为,compiler-core是一个函数,输入字符串,类似下面的 Vue 模板代码:
vue
<div>Hello {{name}}</div>输出也是字符串,类似下面的渲染函数代码:
js
const render = () => { return h('div', null, [h('div', null, ['Hello', toDisplayString(name)])]) }compiler-core 的流程
compiler-core的流程可以分为以下几个主要步骤:
-
词法分析:将模板字符串转换为一系列的标记(tokens),这些标记代表了模板中的各种元素,如标签、文本、指令等。
-
语法分析:将标记转换为抽象语法树(AST),AST 是一个树形结构,表示模板的结构和内容。
-
代码生成:将优化后的 AST 转换为 JavaScript 渲染函数的代码字符串。
-
主编译函数:整合整个编译流程,接受模板字符串作为输入,返回渲染函数的代码字符串。
1.词法分析
词法分析的主要任务是将模板字符串转换为一系列的标记。Vue3 使用了一个名为parse的函数来完成这个任务。这个函数会遍历模板字符串,识别出各种元素,并生成相应的标记。
函数工作原理
- 初始化 :创建空数组 tokens 存储结果,current 变量跟踪当前解析位置。
- 主循环 :逐个字符处理输入字符串,直到处理完所有字符。 - 处理不同类型的内容 : - 空白字符 :跳过空格、换行等 - HTML 标签 :识别开始标签
<tag>和结束标签</tag>- 插值表达式 :识别{{expression}}形式的内容 - 普通文本 :识别不属于上述类型的文本内容 - 生成 token 对象 :每种类型都会生成一个包含 type 和 value 的对象,添加到 tokens 数组中。
Token 类型说明:
- TAG_OPEN: HTML 开始标签,如
<div> - TAG_CLOSE: HTML 结束标签,如
</div> - INTERPOLATION: 插值表达式,如
{{name}} - TEXT: 普通文本内容
处理流程实例
以下面的的为例:
tsx
<div>Hello, {{ name }}!</div>解析过程:
- 遇到<,开始解析标签
- 解析出 div,生成
{ type: 'TAG_OPEN', value: 'div' } - 遇到 Hello, ,生成
{ type: 'TEXT', value: 'Hello,' } - 遇到
{{,开始解析插值 - 解析出
name,生成{ type: 'INTERPOLATION', value: 'name' } - 遇到
!,生成{ type: 'TEXT', value: '!' } - 遇到
</,开始解析结束标签 - 解析出
div,生成{ type: 'TAG_CLOSE', value: 'div' } - 最终生成的
tokens数组:
js
[
{ type: 'TAG_OPEN', value: 'div' },
{ type: 'TEXT', value: 'Hello,' },
{ type: 'INTERPOLATION', value: 'name' },
{ type: 'TEXT', value: '!' },
{ type: 'TAG_CLOSE', value: 'div' },
];实现代码如下:
js
// 词法分析器 - 将模板字符串转换为token数组
function tokenize(template) {
const tokens = []; // 存储解析出的token
let current = 0; // 当前解析位置
while (current < template.length) {
let char = template[current];
// 跳过空白字符(空格、换行等)
if (/\s/.test(char)) {
current++;
continue;
}
// 解析标签开始 <
if (char === '<') {
let tag = '';
current++;
// 检查是否是结束标签 </
if (template[current] === '/') {
current++;
// 解析标签名
while (
current < template.length &&
/[a-zA-Z]/.test(template[current])
) {
tag += template[current];
current++;
}
// 添加结束标签token
tokens.push({ type: 'TAG_CLOSE', value: tag });
// 跳过 > 字符
while (current < template.length && template[current] !== '>') {
current++;
}
current++;
continue;
}
// 解析开始标签名
while (current < template.length && /[a-zA-Z]/.test(template[current])) {
tag += template[current];
current++;
}
// 添加开始标签token
tokens.push({ type: 'TAG_OPEN', value: tag });
// 跳过标签属性部分(简化处理,不解析属性)
while (current < template.length && template[current] !== '>') {
current++;
}
current++;
continue;
}
// 解析插值表达式 双大括号左边
if (char === '{' && template[current + 1] === '{') {
let expression = '';
current += 2; // 跳过 双大括号右边
// 收集表达式内容,直到遇到 双大括号右边 结束
while (
current < template.length &&
!(template[current] === '}' && template[current + 1] === '}')
) {
expression += template[current];
current++;
}
// 添加插值表达式token
tokens.push({ type: 'INTERPOLATION', value: expression.trim() });
current += 2; // 跳过 双大括号右边
continue;
}
// 解析普通文本内容
let text = '';
while (
current < template.length &&
template[current] !== '<' && // 不是标签开始
!(template[current] === '{' && template[current + 1] === '{')
) {
// 不是插值开始
text += template[current];
current++;
}
// 如果文本不为空,添加文本token
if (text.trim()) {
tokens.push({ type: 'TEXT', value: text.trim() });
}
}
return tokens;
}2. 语法分析
语法分析的主要任务是将标记转换为抽象语法树(AST)。
Vue3 使用了一个名为parse的函数来完成这个任务。这个函数会遍历标记数组,识别出各种元素,并生成相应的 AST 节点。
函数工作原理:
- 初始化阶段 :
- 创建AST根节点,类型为
ROOT,包含一个空的children数组 - 初始化
current指针为0,用于跟踪当前处理的token位置
- 创建AST根节点,类型为
- **核心解析函数
parseNode**:- 这是一个递归函数,负责解析单个节点
- 根据当前token类型进行不同处理:
- **文本节点(TEXT)**:创建简单文本节点
- **插值表达式(INTERPOLATION)**:创建表达式节点
- **开始标签(TAG_OPEN)**:创建元素节点并递归解析其子节点
- 主循环 :
- 从根节点开始,循环调用
parseNode解析所有子节点 - 将解析出的节点添加到AST的
children数组中
- 从根节点开始,循环调用
处理流程示例
假设我们有如下token数组(来自模板<div>Hello {{name}}</div>):
javascript
[
{ type: 'TAG_OPEN', value: 'div' },
{ type: 'TEXT', value: 'Hello' },
{ type: 'INTERPOLATION', value: 'name' },
{ type: 'TAG_CLOSE', value: 'div' }
]解析过程如下:
- 遇到
TAG_OPEN,创建div元素节点 - 进入div的子节点解析:
- 遇到
TEXT,创建文本节点"Hello" - 遇到
INTERPOLATION,创建插值表达式节点name
- 遇到
- 遇到匹配的
TAG_CLOSE,结束div元素的解析 - 最终生成的AST结构:
javascript
{
type: 'ROOT',
children: [
{
type: 'ELEMENT',
tag: 'div',
props: [],
children: [
{ type: 'TEXT', content: 'Hello' },
{
type: 'INTERPOLATION',
content: { type: 'EXPRESSION', content: 'name' }
}
]
}
]
}实现代码如下:
js
// 3. 语法分析器 - 将token数组转换为AST(抽象语法树)
function parse(tokens) {
// 创建AST根节点
const ast = {
type: NodeTypes.ROOT,
children: []
}
let current = 0 // 当前解析的token位置
// 解析单个节点的递归函数
function parseNode() {
if (current >= tokens.length) return null
const token = tokens[current]
// 处理文本节点
if (token.type === 'TEXT') {
current++
return {
type: NodeTypes.TEXT,
content: token.value
}
}
// 处理插值表达式节点
if (token.type === 'INTERPOLATION') {
current++
return {
type: NodeTypes.INTERPOLATION,
content: {
type: 'EXPRESSION',
content: token.value
}
}
}
// 处理元素节点
if (token.type === 'TAG_OPEN') {
// 创建元素节点
const element = {
type: NodeTypes.ELEMENT,
tag: token.value,
props: [], // 简化处理,不解析属性
children: []
}
current++ // 跳过开始标签
// 解析子节点,直到遇到对应的结束标签
while (current < tokens.length) {
const nextToken = tokens[current]
// 遇到匹配的结束标签,结束当前元素的解析
if (nextToken.type === 'TAG_CLOSE' && nextToken.value === token.value) {
current++
break
}
// 递归解析子节点
const child = parseNode()
if (child) {
element.children.push(child)
}
}
return element
}
return null
}
// 从根节点开始解析所有子节点
while (current < tokens.length) {
const node = parseNode()
if (node) {
ast.children.push(node)
}
}
return ast
}3. 代码生成
代码生成的主要任务是将AST转换为可执行的JavaScript代码。 使用了一个名为generate的函数来完成这个任务。
函数原理:
- **核心函数
genNode**:- 递归处理AST节点,根据节点类型生成不同的代码
- 处理三种主要节点类型:
- **文本节点(TEXT)**:直接转换为字符串字面量
- **插值表达式(INTERPOLATION)**:转换为
toDisplayString()函数调用 - **元素节点(ELEMENT)**:转换为
h()函数调用(虚拟DOM创建函数)
- 主生成逻辑 :
- 遍历AST的
children数组,对每个子节点调用genNode - 将生成的子节点代码用逗号连接
- 最终返回一个完整的渲染函数字符串,默认包裹在
div中
- 遍历AST的
代码生成示例
假设我们有如下AST(来自模板<div>Hello {{name}}</div>):
js
{
type: 'ROOT',
children: [
{
type: 'ELEMENT',
tag: 'div',
props: [],
children: [
{ type: 'TEXT', content: 'Hello' },
{
type: 'INTERPOLATION',
content: { type: 'EXPRESSION', content: 'name' }
}
]
}
]
}生成过程如下:
-
处理根节点的子节点(div元素):
- 调用
genNode处理div元素 - div元素的子节点:
- 文本节点"Hello" →
'Hello' - 插值表达式
name→toDisplayString(name)
- 文本节点"Hello" →
- 组合div子节点代码:
'Hello', toDisplayString(name) - 生成div元素代码:
h('div', null, ['Hello', toDisplayString(name)])
- 调用
-
最终生成的代码:
jsreturn h('div', null, [h('div', null, ['Hello', toDisplayString(name)])])
实现代码如下:
js
// 代码生成器 - 将AST转换为可执行的JavaScript代码
function generate(ast) {
// 生成单个节点的代码
function genNode(node) {
switch (node.type) {
case NodeTypes.TEXT:
// 文本节点直接返回字符串
return `'${node.content}'`
case NodeTypes.INTERPOLATION:
// 插值表达式调用toDisplayString函数
return `toDisplayString(${node.content.content})`
case NodeTypes.ELEMENT:
// 元素节点调用h函数创建虚拟DOM
const children = node.children.map(genNode).join(', ')
return `h('${node.tag}', null, [${children}])`
default:
return ''
}
}
// 生成所有子节点的代码
const children = ast.children.map(genNode).join(', ')
// 返回根节点的渲染函数代码
return `return h('div', null, [${children}])`
}4. 主编译函数
主编译函数 ,其实就是compile函数,是整个模板编译器的入口函数,负责整合词法分析、语法分析和代码生成三个阶段。
函数原理:
- 日志输出 :
- 打印编译过程各个阶段的输出,方便调试和理解
- 包括原始模板、词法分析结果、语法分析结果和生成的代码
- 三个阶段调用 :
- **词法分析(tokenize)**:将模板字符串转换为token数组
- **语法分析(parse)**:将token数组转换为AST
- **代码生成(generate)**:将AST转换为可执行JavaScript代码
- 返回值 :
- 返回最终生成的JavaScript代码字符串
编译过程示例
假设我们有以下模板字符串:
html
<div>Hello {{name}}</div>编译过程如下:
-
原始模板:
html<div>Hello {{name}}</div> -
词法分析结果:
json[ { "type": "TAG_OPEN", "value": "div" }, { "type": "TEXT", "value": "Hello" }, { "type": "INTERPOLATION", "value": "name" }, { "type": "TAG_CLOSE", "value": "div" } ] -
**语法分析结果(AST)**:
json{ "type": "ROOT", "children": [ { "type": "ELEMENT", "tag": "div", "props": [], "children": [ { "type": "TEXT", "content": "Hello" }, { "type": "INTERPOLATION", "content": { "type": "EXPRESSION", "content": "name" } } ] } ] } -
生成的JavaScript代码:
javascriptconst render = () => { return h('div', null, [h('div', null, ['Hello', toDisplayString(name)])]) }
实现代码如下:
js
// 主编译函数 - 整合整个编译流程
function compile(template) {
console.log('=== 编译过程 ===')
console.log('1. 原始模板:')
console.log(template)
console.log()
// 词法分析阶段
const tokens = tokenize(template)
console.log('2. 词法分析结果:')
console.log(JSON.stringify(tokens, null, 2))
console.log()
// 语法分析阶段
const ast = parse(tokens)
console.log('3. 语法分析结果 (AST):')
console.log(JSON.stringify(ast, null, 2))
console.log()
// 代码生成阶段
const code = generate(ast)
console.log('4. 生成的 JavaScript 代码:')
console.log(`const render = () => {\n ${code}\n}`)
console.log()
return code
}