提起群消息的已读回执啊,搞过IM的朋友估计或多或少的遇到过一些弯路。尤其是群里有几百号人甚至上千人的时候,要是还傻huhu地给每个人存一份消息副本?那简直就是给自己找罪受!前阵子用户量蹭蹭涨的时候,数据库直接扛不住了,动不动就超时报警,搞得大家真的是头皮发麻。
吭哧吭哧折腾了好半拉多月,最后总算捣鼓出一个「一份消息存到底 + 记录阅读进度」的法子。今天就跟大伙儿唠唠这事儿,希望能给同样被这事儿折磨的兄弟们能有一点儿启发。
问题到底出在哪儿?动手改之前,咱还是得先搞清楚原来的路子为啥不行了。
简单粗暴,群里发一条消息,就给群里每个人存一条记录。查谁没读倒是挺快,但坏处也秃噜皮地往外冒。首先就是存得太多太狠了,你想想,一个500人的群发一条消息,啪!500条记录就怼进数据库了,这谁受得了啊?赶上高峰期,群里消息嗖嗖地发,数据库写操作直接成了瓶颈,吭哧瘪肚的卡的跟PPT似的。人一多立刻就趴窝了,群越大,这方案就越拉胯,根本撑不住。
我们的设计思路
经过团队内部的几次讨论和技术调研,我们确定了四个核心设计原则:
1. 单一存储策略
群消息只存一份,彻底告别数据冗余。这个想法其实很简单,但实现起来需要重新设计整个数据结构。
2. 偏序记录机制
通过last_ack_msgid字段来记录每个用户的阅读进度。这样我们就能快速计算出哪些消息是未读的。
3. 推拉结合模式
人在线?直接给他推过去,又快又及时。人要是掉线了或者刚上线?别急,等他上线了自己主动来拉消息。这样既不会漏消息,又不会把服务器压垮。
4. 批量优化策略
客户端不是每收到一条消息就立即ACK,而是攒够一定数量再批量提交。这个优化效果非常明显。
技术选型的考虑
在技术栈的选择上,我们主要考虑了稳定性和开发效率:
java
┌─────────────────┬──────────────────────────────────
│ 组件 │ 选择理由
├─────────────────┼──────────────────────────────────
│ Redis │ 处理在线状态,性能出色
│ WebSocket │ 双向通信,实时性强
│ JPA + Hibernate │ ORM方便,减少SQL编写
└─────────────────┴──────────────────────────────────
说实话,选择这些技术主要还是考虑到团队的技术栈熟悉度。毕竟再好的方案,如果团队hold不住也是白搭。
数据库设计的思考
数据库设计是整个方案的核心,我们设计了三张表来支撑整个业务:
群消息表 (group_msgs)
这张表是核心,存储所有的群消息。我们特别注意了索引的设计:
sql
CREATE TABLE group_msgs (
msgid BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '消息ID',
gid BIGINT NOT NULL COMMENT '群ID',
sender_uid BIGINT NOT NULL COMMENT '发送者用户ID',
time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '发送时间',
content TEXT COMMENT '消息内容',
msg_type INT NOT NULL DEFAULT 1 COMMENT '消息类型:1-文本 2-图片 3-语音',
status INT NOT NULL DEFAULT 1 COMMENT '消息状态:1-正常 0-已删除',
INDEX idx_group_time (gid, time),
INDEX idx_sender (sender_uid),
INDEX idx_group_msgid (gid, msgid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;这里面有个小细节,我们使用了自增的msgid而不是UUID,主要是考虑到后续按消息ID范围查询的性能。
群成员表 (group_users)
这张表记录了群成员信息,最关键的是last_ack_msgid字段:
sql
CREATE TABLE group_users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
gid BIGINT NOT NULL COMMENT '群ID',
uid BIGINT NOT NULL COMMENT '用户ID',
last_ack_msgid BIGINT NOT NULL DEFAULT 0 COMMENT '最后确认的消息ID',
join_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
status INT NOT NULL DEFAULT 1 COMMENT '状态:1-正常 0-已退群',
role INT NOT NULL DEFAULT 1 COMMENT '角色:1-普通成员 2-管理员 3-群主',
UNIQUE KEY uk_group_user (gid, uid),
INDEX idx_user_groups (uid, status)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;通过last_ack_msgid,我们可以很容易地计算出用户的未读消息:所有msgid大于这个值的消息都是未读的。
消息回执表 (msg_acks)
这张表用来记录详细的已读回执信息,主要是为了给发送者展示"谁读了我的消息":
sql
CREATE TABLE msg_acks (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
sender_uid BIGINT NOT NULL COMMENT '发送方用户ID',
msgid BIGINT NOT NULL COMMENT '消息ID',
recv_uid BIGINT NOT NULL COMMENT '接收方用户ID',
gid BIGINT NOT NULL COMMENT '群ID',
if_ack BOOLEAN NOT NULL DEFAULT FALSE COMMENT '是否已读',
ack_time TIMESTAMP NULL COMMENT '已读时间',
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY uk_msg_recv (msgid, recv_uid),
INDEX idx_sender_msg (sender_uid, msgid),
INDEX idx_group_msg (gid, msgid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;说实话,这张表的存在还是有争议的。因为即使优化了,每条消息还是需要N-1条回执记录。但产品经理坚持要"已读列表"功能,我们只能妥协,不过后面通过定期清理缓解了存储压力。
系统流程设计
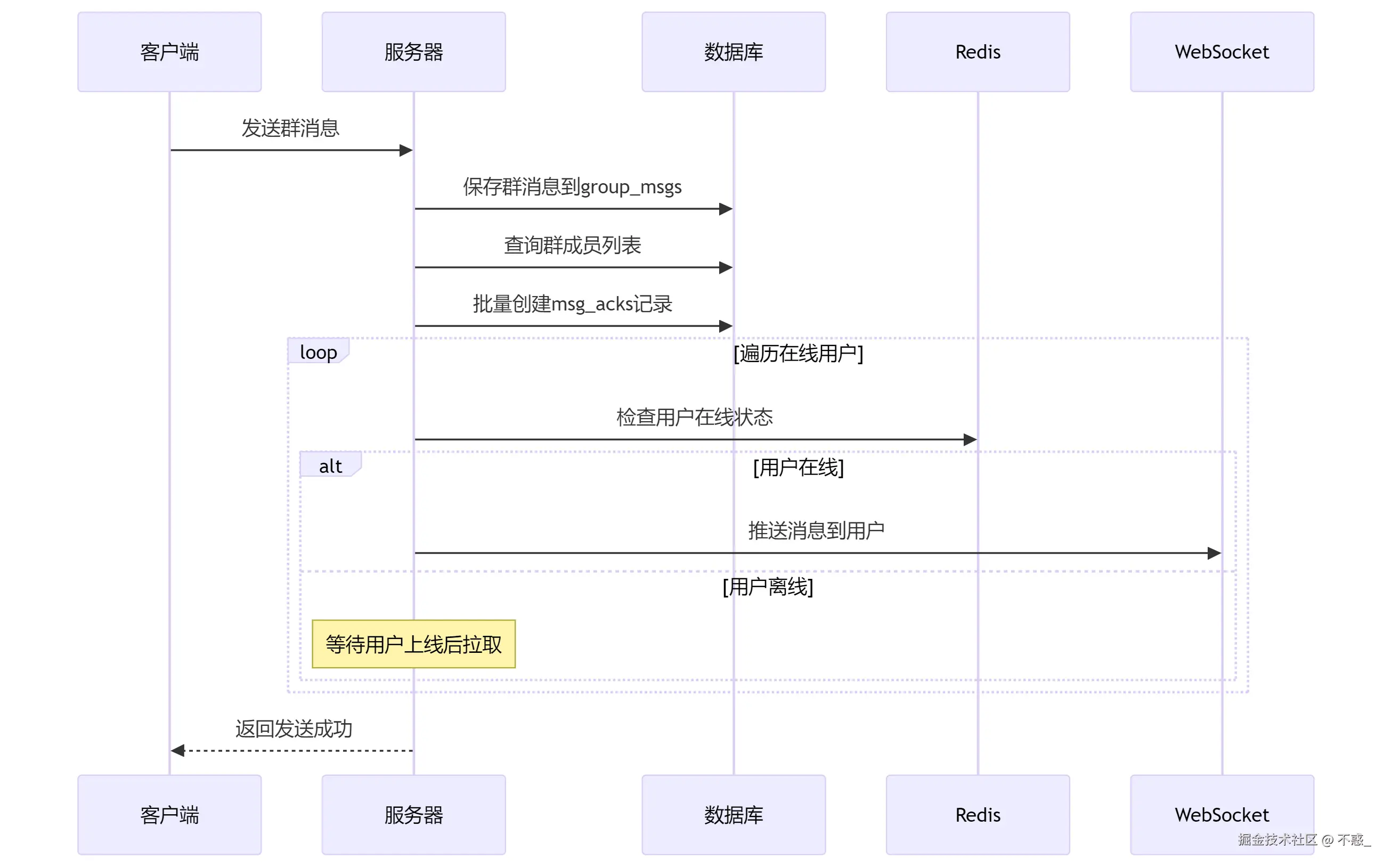
消息发送的完整流程,当用户发送一条群消息时,系统的处理流程是这样的:这个流程看起来挺简单的,但实际实现时遇到了不少坑。比如说,批量创建回执记录时如果群成员太多,就会导致单个事务过大。我们后来改成了异步批量插入,效果好了很多。
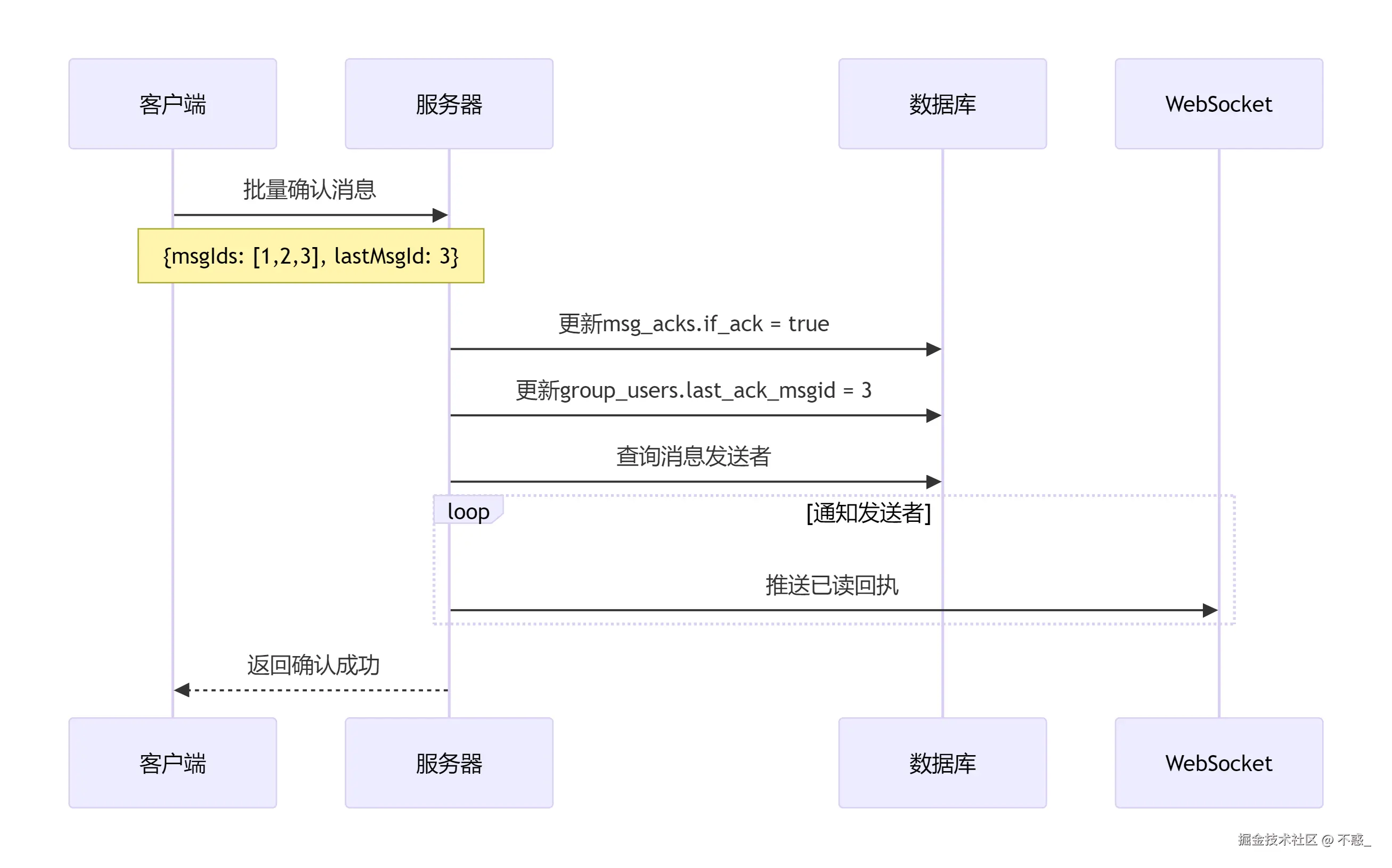
消息确认的批量处理,用户读消息后的确认流程是这样的:这里的关键是批量处理。客户端会攒够10条消息再一起提交,而不是每条消息都单独确认。这个优化对性能提升非常明显。
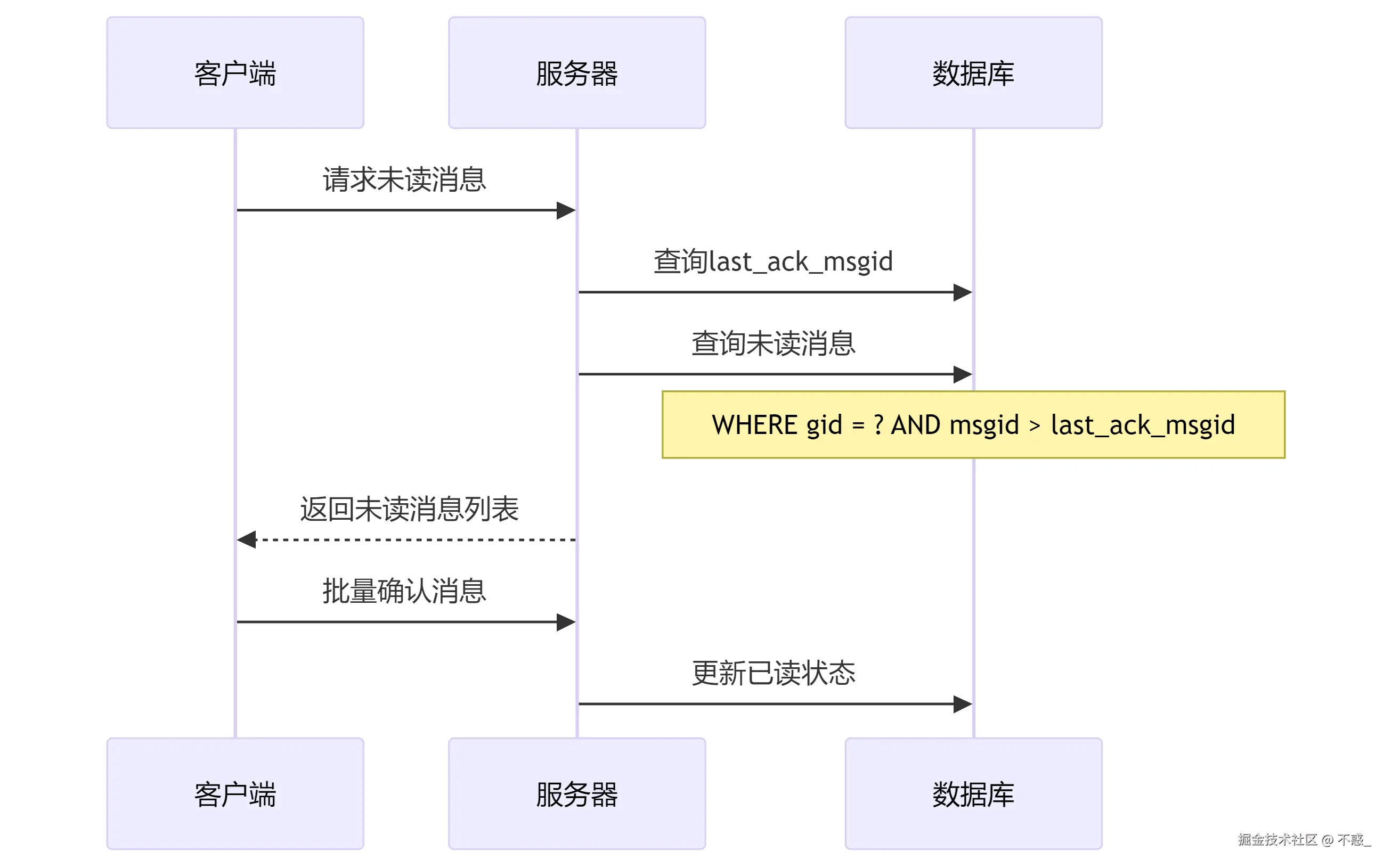
未读消息的拉取机制,用户上线后拉取未读消息的流程相对简单:这个查询的性能关键在于索引设计。我们在(gid, msgid)上建了复合索引,查询效率很高。
代码实现的一些细节
消息发送服务的核心逻辑,这块代码我们重构了好几次,最终的版本是这样的:这里有个坑需要注意:Lambda表达式中不能直接使用外部的可变变量。我们之前直接用request.getSenderUid()结果编译报错,后来改成final变量才解决。
java
@Service
@Transactional
public class GroupMessageService {
@Autowired
private GroupMessageRepository messageRepository;
@Autowired
private GroupUserRepository groupUserRepository;
@Autowired
private MessageAckRepository messageAckRepository;
@Autowired
private WebSocketMessageService webSocketService;
public GroupMessage sendGroupMessage(MessageSendRequest request) {
// 1. 保存群消息
GroupMessage groupMessage = new GroupMessage();
groupMessage.setGid(request.getGroupId());
groupMessage.setSenderUid(request.getSenderUid());
groupMessage.setContent(request.getContent());
groupMessage.setMsgType(request.getMsgType());
groupMessage = messageRepository.save(groupMessage);
// 2. 查询群成员
List<GroupUser> groupMembers = groupUserRepository
.findByGidAndStatus(request.getGroupId(), 1);
// 3. 创建消息回执记录(排除发送者)
final Long senderUid = request.getSenderUid();
final Long msgId = groupMessage.getMsgId();
final Long groupId = request.getGroupId();
List<MessageAck> acks = groupMembers.stream()
.filter(member -> !member.getUid().equals(senderUid))
.map(member -> {
MessageAck ack = new MessageAck();
ack.setSenderUid(senderUid);
ack.setMsgId(msgId);
ack.setRecvUid(member.getUid());
ack.setGid(groupId);
ack.setIfAck(false);
return ack;
})
.collect(Collectors.toList());
messageAckRepository.saveAll(acks);
// 4. 推送消息给在线用户
webSocketService.pushGroupMessage(groupMessage, groupMembers);
return groupMessage;
}
}批量ACK的处理逻辑,消息确认的逻辑相对简单,但需要考虑事务的边界:这里的batchUpdateAckStatus是我们自己写的批量更新方法,比JPA默认的逐条更新效率高多了。
java
@Service
@Transactional
public class MessageAckService {
public void batchAckMessages(AckRequest request) {
// 1. 批量更新消息确认状态
messageAckRepository.batchUpdateAckStatus(
request.getMsgIds(),
request.getUserId(),
new Date()
);
// 2. 更新用户最后确认的消息ID
groupUserRepository.updateLastAckMsgId(
request.getGroupId(),
request.getUserId(),
request.getLastMsgId()
);
// 3. 推送已读回执给消息发送者
notifyReadReceipt(request);
}
private void notifyReadReceipt(AckRequest request) {
// 查询消息发送者并推送已读回执
List<Long> senderIds = messageRepository
.findSenderIdsByMsgIds(request.getMsgIds());
senderIds.forEach(senderId -> {
ReadReceiptNotification notification = new ReadReceiptNotification();
notification.setSenderId(senderId);
notification.setReaderId(request.getUserId());
notification.setMsgIds(request.getMsgIds());
notification.setReadTime(new Date());
webSocketService.pushReadReceipt(senderId, notification);
});
}
}WebSocket推送的优化,WebSocket推送这块我们也踩了不少坑:这里用了并行流来提升推送效率,但要注意线程安全问题。另外,在线状态的检查我们放在了Redis里,避免了频繁查询数据库。
java
@Component
public class WebSocketMessageService {
@Autowired
private SimpMessagingTemplate messagingTemplate;
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void pushGroupMessage(GroupMessage message, List<GroupUser> members) {
// 构建消息体
GroupMessageNotification notification = new GroupMessageNotification();
notification.setMsgId(message.getMsgId());
notification.setGroupId(message.getGid());
notification.setSenderUid(message.getSenderUid());
notification.setContent(message.getContent());
notification.setSendTime(message.getTime());
// 推送给在线用户
members.parallelStream()
.filter(member -> !member.getUid().equals(message.getSenderUid()))
.filter(this::isUserOnline)
.forEach(member -> {
String destination = "/user/queue/group/" + message.getGid();
messagingTemplate.convertAndSendToUser(
member.getUid().toString(),
destination,
notification
);
});
}
private boolean isUserOnline(GroupUser user) {
String key = "user:online:" + user.getUid();
return redisTemplate.hasKey(key);
}
public void pushReadReceipt(Long senderId, ReadReceiptNotification notification) {
if (isUserOnline(senderId)) {
messagingTemplate.convertAndSendToUser(
senderId.toString(),
"/user/queue/read-receipt",
notification
);
}
}
}性能优化的几个关键点
客户端批量ACK机制,这个优化效果最明显。客户端不再是收到消息就立即ACK,而是攒够一定数量再批量提交,这个机制将原来的N次请求压缩到了N/10次,效果立竿见影。
javascript
class MessageAckManager {
constructor(batchSize = 10) {
this.batchSize = batchSize;
this.pendingAcks = new Map(); // groupId -> msgIds[]
this.ackTimer = null;
}
addMessage(groupId, msgId) {
if (!this.pendingAcks.has(groupId)) {
this.pendingAcks.set(groupId, []);
}
this.pendingAcks.get(groupId).push(msgId);
// 达到批量大小或设置定时器
if (this.pendingAcks.get(groupId).length >= this.batchSize) {
this.flushAcks(groupId);
} else {
this.scheduleFlush();
}
}
flushAcks(groupId) {
const msgIds = this.pendingAcks.get(groupId);
if (msgIds && msgIds.length > 0) {
// 发送批量ACK请求
this.sendBatchAck(groupId, msgIds);
this.pendingAcks.set(groupId, []);
}
}
}数据库查询的优化,SQL优化是老生常谈,但确实很重要,关键是避免了子查询,直接用JOIN的方式关联。另外LIMIT 100是为了避免一次性返回太多数据。
sql
-- 优化后的未读消息查询
SELECT m.msgid, m.content, m.sender_uid, m.time
FROM group_msgs m
INNER JOIN group_users gu ON m.gid = gu.gid
WHERE gu.uid = ?
AND gu.gid = ?
AND m.msgid > gu.last_ack_msgid
AND m.status = 1
ORDER BY m.msgid ASC
LIMIT 100;
-- 优化后的已读回执统计查询
SELECT
COUNT(CASE WHEN if_ack = true THEN 1 END) as read_count,
COUNT(*) as total_count
FROM msg_acks
WHERE msgid = ? AND sender_uid = ?;Redis在线状态管理,用Redis管理在线状态比查数据库快多了,过期时间来自动清理离线用户,避免了手动维护的麻烦。
java
@Component
public class UserOnlineManager {
private static final String ONLINE_KEY_PREFIX = "user:online:";
private static final int ONLINE_TIMEOUT = 300; // 5分钟
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void setUserOnline(Long userId) {
String key = ONLINE_KEY_PREFIX + userId;
redisTemplate.opsForValue().set(key, "1", ONLINE_TIMEOUT, TimeUnit.SECONDS);
}
public boolean isUserOnline(Long userId) {
String key = ONLINE_KEY_PREFIX + userId;
return redisTemplate.hasKey(key);
}
public Set<Long> getOnlineUsers(List<Long> userIds) {
List<String> keys = userIds.stream()
.map(id -> ONLINE_KEY_PREFIX + id)
.collect(Collectors.toList());
List<String> results = redisTemplate.opsForValue().multiGet(keys);
return IntStream.range(0, userIds.size())
.filter(i -> results.get(i) != null)
.mapToObj(userIds::get)
.collect(Collectors.toSet());
}
}数据清理和运维
定时清理历史数据,这个功能是运维同学强烈要求的,不然数据库迟早会爆,选择凌晨2点是因为这个时间段用户最少,对业务影响最小。保留30天的数据基本能满足大部分业务需求。
java
@Component
public class DataCleanupTask {
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2点执行
public void cleanupHistoryData() {
Date cutoffDate = DateUtils.addDays(new Date(), -30); // 保留30天
// 清理历史消息回执
int deletedAcks = messageAckRepository.deleteByCreateTimeBefore(cutoffDate);
log.info("清理历史回执记录: {} 条", deletedAcks);
// 清理已删除的消息
int deletedMsgs = messageRepository.deleteByStatusAndTimeBefore(0, cutoffDate);
log.info("清理已删除消息: {} 条", deletedMsgs);
}
}监控指标的设计,监控这块我们主要关注几个核心指标,这些指标接入了我们的监控平台,一旦出现异常立即告警。
java
@Component
public class SystemMetrics {
private final MeterRegistry meterRegistry;
private final Counter messageCounter;
private final Timer ackProcessTime;
public SystemMetrics(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
this.messageCounter = Counter.builder("group.message.sent")
.description("群消息发送计数")
.register(meterRegistry);
this.ackProcessTime = Timer.builder("group.ack.process.time")
.description("消息确认处理时间")
.register(meterRegistry);
}
public void recordMessageSent(Long groupId, Integer memberCount) {
messageCounter.increment(
Tags.of(
"group.id", groupId.toString(),
"member.count.range", getMemberCountRange(memberCount)
)
);
}
public void recordAckProcessTime(Duration duration) {
ackProcessTime.record(duration);
}
}实际效果怎么样?
经过几个月的线上运行,效果确实不错:
性能测试数据
我们用JMeter做了压力测试,结果如下:
| 测试场景 | 群成员数 | 并发用户 | 消息发送TPS | 平均响应时间 | 99%响应时间 |
|---|---|---|---|---|---|
| 小群聊 | 50人 | 100 | 1200 | 45ms | 120ms |
| 中群聊 | 200人 | 200 | 800 | 78ms | 200ms |
| 大群聊 | 500人 | 300 | 500 | 156ms | 400ms |
这个结果基本满足了我们的业务需求。虽然大群的性能还有提升空间,但对比之前动不动就超时的情况,已经好了太多。
存储空间的对比
虽然我们的方案在存储上没有明显优势(回执表还是需要N-1条记录),但通过定期清理,实际的存储压力降低了很多:
| 方案类型 | 100人群 | 500人群 | 1000人群 | 备注 |
|---|---|---|---|---|
| 传统方案 | 100条记录 | 500条记录 | 1000条记录 | 永久存储 |
| 我们的方案 | 1条记录 + 99条回执 | 1条记录 + 499条回执 | 1条记录 + 999条回执 | 30天清理 |
加上批量处理的优化,整体性能提升还是很明显的。
后续的扩展方向
分库分表的考虑
如果业务继续增长,我们考虑这样分库分表:
sql
-- 按群ID分片
CREATE TABLE group_msgs_0001 LIKE group_msgs;
CREATE TABLE group_msgs_0002 LIKE group_msgs;
-- ... 更多分片
-- 按时间分片
CREATE TABLE group_msgs_202401 LIKE group_msgs;
CREATE TABLE group_msgs_202402 LIKE group_msgs;
-- ... 按月分表不过目前的业务量还用不到,先把单机性能榨干再说。
微服务化的思路
如果要做微服务拆分,我们的想法是这样的,含三个核心服务:消息服务、回执服务和推送服务,它们通过网关服务进行连接与协作。
消息服务:负责消息存储、群成员管理和消息查询。
回执服务:处理回执记录、批量确认和统计分析。
推送服务:管理在线状态、消息推送和连接管理。
网关服务:作为各个服务之间的路由和负载均衡中心,负责流量管理和限流熔断。
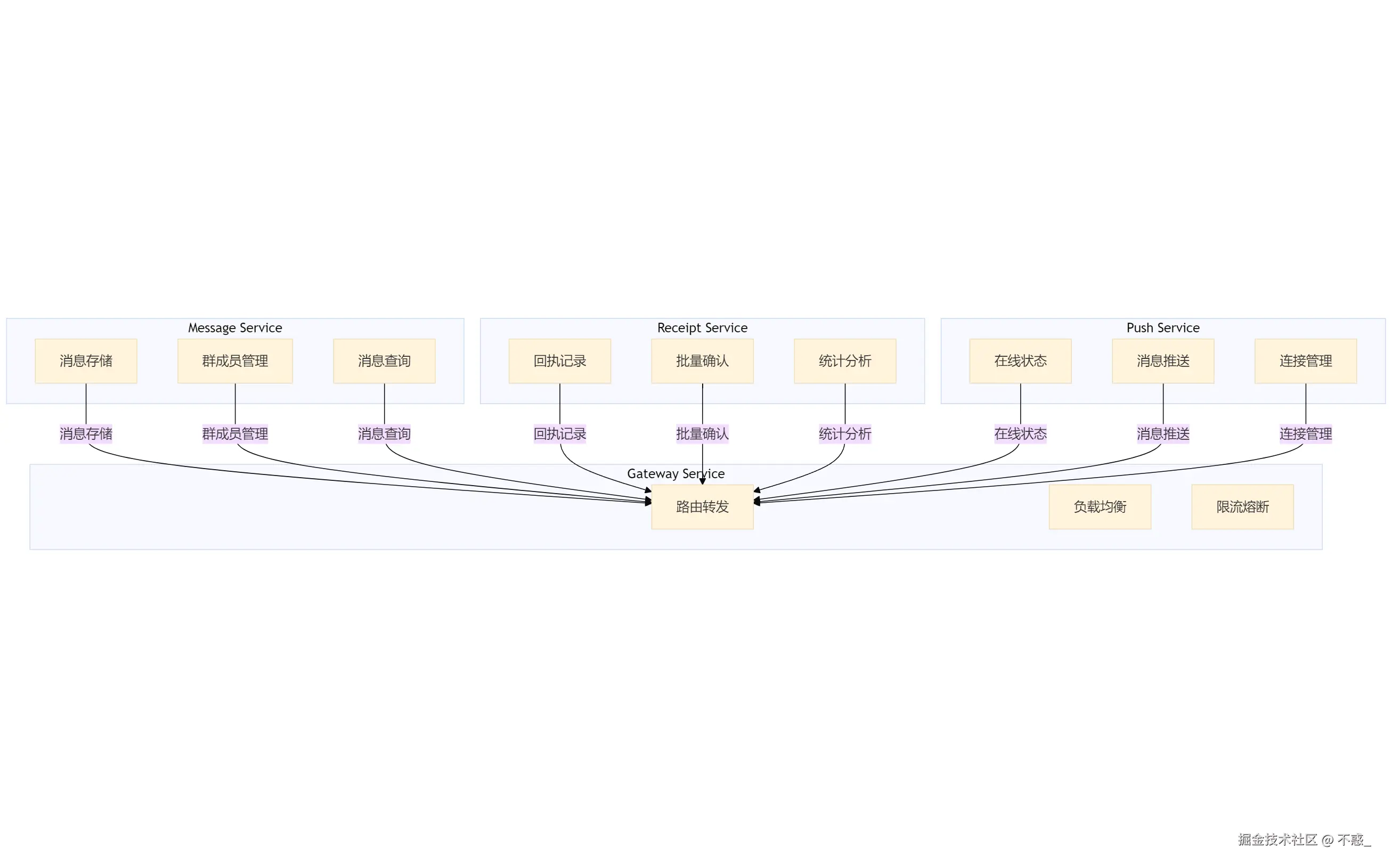
不过目前单体架构还能hold住,暂时没必要过度设计。
踩过的坑和经验总结
技术层面的坑
- Lambda表达式的变量引用问题:不能直接使用外部可变变量,需要声明为final
- WebSocket连接管理:需要处理断线重连,避免消息丢失
- 事务边界控制:批量操作时要注意事务大小,避免锁表时间过长
- Redis连接池配置:默认配置在高并发下容易出问题,需要调优
业务层面的思考
- 产品需求的平衡:完美的已读状态展示 vs 系统性能,需要找到平衡点
- 用户体验:批量ACK虽然提升了性能,但可能影响已读状态的实时性
- 运维成本:定期数据清理、监控告警等都需要考虑进去
这套方案在我们的业务场景下运行得还不错,基本解决了大群聊的性能问题。当然,任何技术方案都不是银弹,具体还是要根据自己的业务特点来调整。
如果你也在做类似的系统,希望这些经验能给你一些参考。有什么问题的话,欢迎一起交流讨论。