今天这篇文章,是专为那些刚刚接触 Python,又对量化交易心里痒痒的朋友们准备的。我们来聊聊一个听起来很"高大上"的东西:卡尔曼滤波器(Kalman Filter)。别急!你可能已经开始紧张了,觉得数学一定一堆公式压顶。放心,花姐不会把你扔到高数的深海里,而是拉着你,一步一步上岸。
"滤波"?不是做奶茶那个过滤器?
哈哈,不是😂。我们说的"卡尔曼滤波器"是一个能在一堆噪声里,精准捕捉趋势的小工具。你可以把它想象成一个聪明的老司机,面对糟糕的导航指令,依然能稳稳把车开到目的地。
你可能在想------为啥一个 1960 年代发明的算法,现在还能用在交易里?还挺火?
是这样的:
这个工具的厉害之处在于------它不看表面,而是看"本质"。
市场数据吵吵闹闹,K线忽上忽下。但卡尔曼滤波可以"滤掉"那些干扰,给你一个"更真实"的状态。聪明的你一定会发现,这不就是我们做交易最缺的"理性"吗?
别着急谈策略,先讲点通俗的
先来个真实点的例子吧。有一天我量体重,称了一下:52kg。然后又称了一下:51.5kg。接着再称,52.3kg......嗯?难道我在5分钟里胖瘦交替?不可能吧🙃
其实------这就是测量误差。称有误差,地板不平,我呼吸太重...等等。
那么问题来了:我真实的体重大概是多少?
我们可以拿这些误差数据,取平均值,或者更聪明地------像卡尔曼滤波一样,不断"更新"一个最可信的估计值。
这,就是卡尔曼滤波最朴素的逻辑。
那么到底怎么用?
你要是做交易,尤其是对冲交易(Pairs Trading),你会发现一个痛点:
比如你找了两个强相关的股票,A 和 B。A 涨了,B 却没涨,难道 B 落后了?可以买?这时候你需要判断:A 和 B 的关系还稳不稳?
卡尔曼滤波可以告诉你:稳不稳,怎么稳,应该怎么调整仓位。
再比如你想预测波动率,或者想知道一个模型是否"偏离"太远了------卡尔曼都可以帮你出主意。
它不像简单的滚动均值死板,它能动态地调整自己对市场的理解,有点像一个每天修正自己认知的交易员(是不是突然有点人格了?)。
打开 Python,干!
讲代码前我必须先吐槽一句:
花姐我本人对网上那种 copy 代码就跑,连变量名都看不懂的教学,体感很糟🙅♀️
我们要写,就写点有脑子的 东西。变量名就用最通俗的,比如 jiage, shijian, zhuangtai。看得懂才叫学会。
所以我们从最简单的卡尔曼滤波逻辑开始,用 Python 写个能"预测"趋势的小东西:
python
import numpy as np
import matplotlib.pyplot as plt
# 初始状态和误差
zhuangtai = np.array([[0], [0]]) # 初始位置和速度
P = np.eye(2) * 1000 # 初始误差协方差矩阵
# 状态转移矩阵(假设每秒移动一次)
F = np.array([[1, 1],
[0, 1]])
# 观测矩阵(我们只观察位置)
H = np.array([[1, 0]])
# 过程噪声和测量噪声
Q = np.eye(2) * 0.01
R = np.array([[1]])
# 模拟测量数据
np.random.seed(42)
shijian = 50
true_pos = np.linspace(0, 49, shijian)
ceshi_pos = true_pos + np.random.normal(0, 1, shijian)
yuce = []
for i in range(shijian):
# 预测
zhuangtai = F @ zhuangtai
P = F @ P @ F.T + Q
# 更新
z = np.array([[ceshi_pos[i]]])
y = z - H @ zhuangtai
S = H @ P @ H.T + R
K = P @ H.T @ np.linalg.inv(S)
zhuangtai = zhuangtai + K @ y
P = (np.eye(2) - K @ H) @ P
yuce.append(zhuangtai[0, 0])
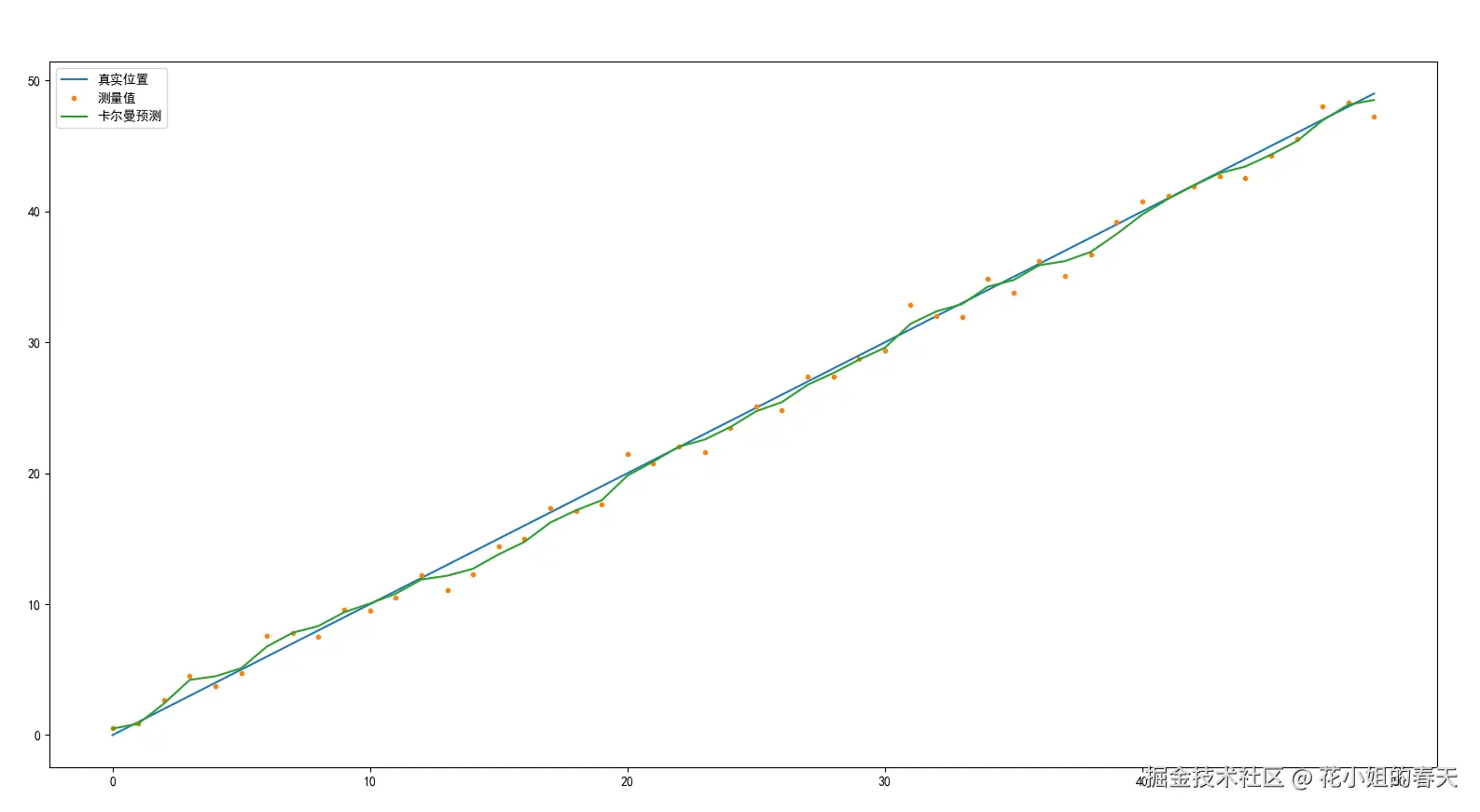
# 画图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正负号也正常显示
plt.plot(true_pos, label='真实位置')
plt.plot(ceshi_pos, '.', label='测量值')
plt.plot(yuce, label='卡尔曼预测')
plt.legend()
plt.show()聪明的你一定看出来了,这段代码其实就是模拟了一个东西在匀速移动,我们测量它的位置,每次都带点误差。然后用卡尔曼滤波器,重新估计它真正的位置。
@符号答疑
你看到示例代码里的@是不是特别懵 其实
@ 是 Python 3.5+ 里用于"矩阵乘法"的运算符
你可以理解成:
python
A @ B ⟶ 等价于 np.matmul(A, B)举个例子你就懂了
python
import numpy as np
A = np.array([[1, 2],
[3, 4]])
B = np.array([[5],
[6]])
C = A @ B # 等同于 np.matmul(A, B)
print(C)结果是:
txt
[[17]
[39]]运算过程为:
txt
[[1, 2], [[5], [[1*5 + 2*6], [[17],
[3, 4]] @ [6]] = [3*5 + 4*6]] = [39]]不理解也没关系,以后看到类似的代码可以在脑子里自动换成
"这是在做矩阵运算,别当它是普通乘法。"
拓展一下思维......
刚才我们预测的是"位置",你想过没有,这不就等于在预测价格?
如果我现在把"位置"换成股票的价格走势,"速度"换成涨跌速率------是不是就是一个简易的趋势预测模型?
对!你可以用它来判断趋势的延续性。
那你还可以干嘛?做市、动态仓位控制、预测收益率波动......甚至------写个自适应因子模型,自动修正参数。
花姐小Tips
卡尔曼滤波厉害的点,不是"预测得有多准",而是------它能承认自己错了,然后修正它自己。
这和我们做交易一模一样啊。犯错不可怕,可怕的是不认错、不修正。
卡尔曼滤波器的概念就讲到这里了,下一篇文章我们讲讲它在股市中的具体应用