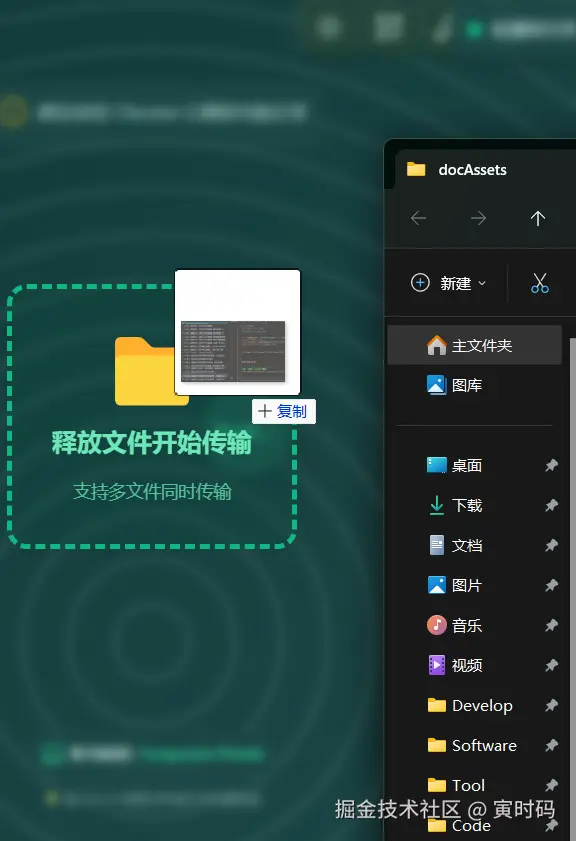
无需安装,纯浏览器实现跨平台文件、文本传输,支持断点续传、二维码、房间码加入、粘贴传输、拖拽传输、多文件传输
这是一个 MonoRepo 搭建的全栈项目,包含前端、后端、公共包
- 源码: github.com/beixiyo/web...
- 在线体验(国外服务器,网络不一定好,你可以通过 Docker 一键部署): web-share.beixiyo.dpdns.org/fileTransfe...


✨ 核心功能亮点
🚫 无需安装应用,纯浏览器运行
- 🖱️ 拖拽传输
- 📋 粘贴传输
- 🖼️ 图片文件预览
- 🔢 扫码连接
- 🔑 密钥连接
📖 阅读本文,你将学会
这篇文章将带你深入我开发的开源项目 Web-Share,但我们不只是走马观花。读完本文,你将收获的不仅仅是一个文件传输工具的实现过程,更是一套解决复杂 Web 应用问题的实战思路:
- WebRTC 实战:从连接建立到数据传输,掌握 WebRTC 的核心流程与关键 API。
- 二进制数据处理 :学习如何巧妙地将元数据与二进制数据打包,解决
RTCDataChannel的一大限制。 - 性能优化:理解并实现"背压"机制,防止数据发送过快导致连接崩溃。
- 前端架构解耦:通过发布订阅和 Promise,优雅地处理复杂异步流程和 UI 交互。
- 断点续传设计:从零设计一套可靠的断点续传机制,并保证数据的完整性。
- 房间码、二维码管理房间:通过房间码、二维码管理房间,实现多对多的文件传输。
- 流式下载解决大文件下载内存溢出 :使用 Service Worker 或 File System Access API 进行流式下载,避免传统的
Blob下载方式导致内存溢出。需要浏览器支持,手机端 Chrome 可用
准备好了吗?让我们一起,让浏览器再次伟大!
🔬 WebRTC 原理概述:浏览器之间的"鹊桥相会"
这个项目是基于 WebRTC 技术实现的。WebRTC (Web Real-Time Communication) 允许浏览器之间建立点对点(P2P)的直接连接,实现音视频或任意数据的实时传输。
但这里有一个"鸡生蛋,蛋生鸡"的问题:两个浏览器都不知道对方的网络地址(IP、端口),怎么建立连接呢?
这时候就需要一个"婚姻介绍所 "------我们称之为信令服务器 (Signaling Server)。
它的作用很简单:
- 浏览器
A告诉"介绍所":"我想认识B,这是我的联系方式。" - "介绍所"把
A的联系方式转交给B。 B同意后,也把自己的联系方式通过"介绍所"告诉A。- 双方交换联系方式后,"介绍所"功成身退。
A和B开始私下直接通信,传输文件。
这个过程保证了我们的文件数据,自始至终都只在用户的设备之间进行端到端加密传输,服务器完全碰不到,实现了极致的高效 与安全。
搭建服务器(简化版本)
1. 安装 express、ws 开发服务器
bash
pnpm add express ws2. 创建简单的服务器入口
ts
import express from 'express'
import { WSServer } from '@/WSServer'
const PORT = process.env.PORT || 3001
// 服务器
const app = express()
const server = app.listen(PORT, () => {
console.log(`信令服务器运行在端口 ${PORT}`)
})
// 创建 WebSocket 信令服务器
new WSServer(server)3. 创建信令服务器处理简单的事件
核心在于 onMessage 方法,它通过不同的事件类型,使用不同的方式处理每个事件,就像状态机一样 比如:
- Ping 心跳检测
- JoinRoom 加入房间
- LeaveRoom 离开房间
- Relay 转发消息
- Offer 发送 Offer
- Answer 发送 Answer
- Candidate 发送 Candidate
- Text 发送文本
- ...
ts
import { WebSocket, WebSocketServer } from 'ws'
export class WSServer {
// ...
constructor(
server: Server,
opts: WSServerOpts = {},
) {
this.ws = new WebSocketServer({ server })
// 连接成功处理
this.ws.on('connection', (socket, request) => {
const peer = new Peer(socket, request)
/** 将用户添加到对应房间 */
this.addPeerToRoom(peer)
this.onConnection(peer)
})
/** 定期清理过期记录 */
this.keepAliveClear()
}
private onConnection = (peer: Peer) => {
const { socket } = peer
socket.on('message', data => this.onMessage(peer, data))
/** 监听WebSocket关闭事件 */
socket.on('close', (code, reason) => {
console.log(`${peer.name.displayName} WebSocket连接关闭 (code: ${code}, reason: ${reason})`)
this.handlePeerDisconnect(peer)
})
/** 监听WebSocket错误事件 */
socket.on('error', (error) => {
console.log(`${peer.name.displayName} WebSocket连接错误:`, error)
this.handlePeerDisconnect(peer)
})
}
private onMessage = (sender: Peer, data: RawData) => {
let msg: SendData
try {
msg = JSON.parse(data.toString())
}
catch (e) {
console.warn('WS: Received JSON is malformed')
return
}
switch (msg.type) {
case Action.Close:
sender.socket.terminate()
break
case Action.Ping:
sender[HEART_BEAT] = Date.now()
/** 更新设备映射的最后活跃时间 */
this.updateDeviceLastSeen(sender)
this.send(sender, { type: Action.Ping, data: null })
break
// ...
}
}
}💡 探索之旅:编码中的挑战与解决方案
这部分是文章的核心。我将分享在开发过程中遇到的几个关键问题,以及我是如何思考并解决它们的。
💡 问题一:茫茫人海(局域网)中,如何让设备发现彼此?
当你和朋友连着同一个 Wi-Fi,打开这个应用,你们会神奇地出现在对方的设备列表里(仅限本地开发局域网环境)。
这背后是一个简单而巧妙的"房间"机制。
解决方案:IP 网段分组
当一个设备连接到信令服务器时,服务器会获取它的 IP 地址
typescript
class Peer {
// ...
private getRoomIdFromIP(ip: string): string {
// ... (本地回环地址处理)
/** 私有网络地址 - 按网段划分 */
if (Peer.ipIsPrivate(ip)) {
const parts = ip.split('.')
// 192.168.x.x 网络 - 按前三段划分
if (parts[0] === '192' && parts[1] === '168') {
return `lan_192_168_${parts[2]}`
}
// 10.x.x.x 网络 - 按前两段划分
if (parts[0] === '10') {
return `lan_10_${parts[1]}`
}
// ... (其他私有网段处理)
}
/** 公网IP - 每个IP一个房间 */
return `public_${ip.replace(/\./g, '_')}`
}
// ...
}这个方法会分析客户端的 IP 地址,将处于同一个局域网子网(例如 192.168.1.x)的所有设备,都分配到同一个 roomId。这样,当有新设备加入时,服务器只需将它的信息广播给这个"房间"里的所有其他设备,就实现了自动发现。
当然,为了应对复杂的网络环境,项目还支持通过"二维码"或"6位房间码"来创建和加入临时房间,其本质也是为一次性会话创建一个唯一的 roomId。
💡 问题二:WebRTC 连接建立的"三步走"
WebRTC 的连接过程充满了术语:SDP、Offer、Answer、ICE。听起来很复杂,但我们可以把它简化为"连接三步走"。
解决方案:Offer / Answer / ICE 模型
-
发起方(A)发送连接申请 (Offer) :本着有枣没枣搂一竿子的原则,用户
A点击B的头像,申请连接,浏览器会生成一份Offer。这份 Offer 是一个符合 SDP (Session Description Protocol) 规范的文本,详细描述了A的通信能力(支持的编解码器、加密算法等)。然后A通过信令服务器将Offer发给B。 -
接收方(B)的"回信" (Answer) :
B收到Offer后,如果接收方也压抑了,点击同意连接,就会生成一份对应的Answer,同样是 SDP 格式,表示"你的条件我接受,我们可以连接"。Answer也通过信令服务器回传给A。 -
寻找"最佳连接路线" (ICE Candidates) :在交换"信件"的同时,
A和B也在各自探索所有可能的网络路径,比如自己的内网IP、通过 STUN 服务器发现的公网IP等。这些路径被称为ICE Candidate。双方会不断地通过信令服务器交换这些"候选路线",并尝试互相"打洞"(NAT Traversal),就好像狡兔三窟,从多个洞穴中寻找最近的路径,直到找到一条能成功连接的最佳路径。
一旦路径建立,RTCDataChannel(数据通道)就会被打开,信令服务器的任务彻底结束,真正的文件传输开始了。
💡 问题三:元数据和二进制,如何"一石二鸟"?
这是一个非常经典的问题。RTCDataChannel 的 send() 方法一次只能发送一种类型的数据:要么是字符串,要么是二进制(ArrayBuffer 等)。
当我需要发送一个文件块(二进制)时,如何同时告诉接收方这个块的元数据,比如:它属于哪个文件?是第几个块?偏移量是多少?
一个直观但糟糕的方案是"交叉发送":先 send() 一个 JSON 字符串描述元数据,再 send() 文件块的二进制数据。这会导致发送次数翻倍,性能低下,且接收方需要维护复杂的状态机来配对元数据和数据,极易出错。
解决方案:像打包快递一样,将元数据和二进制"粘"在一起
我的思路是:在发送前,将元数据和二进制数据打包成一个单一的 ArrayBuffer 进行发送。 就像是把"货物"和"运单"一起放进一个快递包裹里。这个过程由 BinaryMetadataEncoder.ts 完成,它的工作流程如下:
- 准备"运单"(Metadata) :首先,我们将包含文件哈希、偏移量等信息的 JavaScript 对象,通过
JSON.stringify()转换成字符串,再用TextEncoder转换成二进制的字节流(Uint8Array)。这就是我们的"运单"。 - 计算尺寸,准备"包裹" :我们精确计算出最终"包裹"需要多大空间。总大小 =
"运单"长度所需空间+"运单"本身大小+"货物"本身大小。然后创建一个这么大的ArrayBuffer作为包裹。 - 贴上"包裹说明"(Metadata Length) :这是最关键的一步。我们在"包裹"的最前面,用固定的2个字节(
Uint16)写入"运单"的实际长度。这2个字节就像是贴在快递箱上的说明,告诉收货员:"运单"有多长,从哪里开始是真正的"货物"。 - 打包:依次将"运单"的二进制内容和"货物"(文件块)的二进制内容,填充到"包裹"中相应的位置。
- 发送 :将这个包含了所有信息的、结构完整的"包裹"(
ArrayBuffer) 一次性发送出去。
这样,我们发送的每一个数据包都自带了"说明书",其结构是: ["运单"长度 (2字节)] + ["运单"JSON字符串 (n字节)] + ["货物"文件块 (m字节)]
接收方收到数据后,解码过程就是打包的逆操作:
- 先读取前2个字节,得到"运单"的长度
n。 - 再读取后面
n个字节,就能得到完整的"运单"信息,并解析成元数据对象。 - 剩下的所有内容,就是纯粹的"货物"------文件块数据。
这个方案将两次发送合并为一次,既高效又可靠,极大地简化了数据处理逻辑。
详细源码在:github.com/beixiyo/jl-...
我已经把我常用的工具发布到 npm 了,www.npmjs.com/package/@jl...
ts
export class BinaryMetadataEncoder {
// ...
/**
* @param metadata 元数据对象(可JSON序列化)
* @param buffer 二进制数据(ArrayBuffer或TypedArray)
* @param metaLengthType 元数据长度存储类型(默认Uint16)
* @returns 合并后的ArrayBuffer
*/
public static encode(
metadata: any,
buffer: ArrayBuffer | ArrayBufferView,
metaLengthType: MetaLengthType = 'Uint16',
): ArrayBuffer {
// 1. 序列化元数据
const metaStr = JSON.stringify(metadata)
const metaBuffer = new TextEncoder().encode(metaStr)
/** 元数据长度 */
const metaLength = metaBuffer.length
// 2. 验证元数据长度是否超出范围
const maxMetaLength = BinaryMetadataEncoder.getMaxMetaLength(metaLengthType)
if (metaLength > maxMetaLength) {
throw new Error(`Metadata too large (${metaLength} > ${maxMetaLength}). Consider increasing metaLengthType.`)
}
// 3. 获取二进制数据(处理ArrayBufferView)
const dataBuffer = buffer instanceof ArrayBuffer
? buffer
: buffer.buffer
// 4. 创建总Buffer
/** 类型长度 */
const lengthBytes = BinaryMetadataEncoder.Config.MetaLengthType[metaLengthType]
/**
* 总长度
* 类型长度 + 元数据长度 + 二进制数据长度
*/
const totalBuffer = new Uint8Array(lengthBytes + metaLength + dataBuffer.byteLength)
const view = new DataView(totalBuffer.buffer)
// 5. 写入元数据长度
switch (metaLengthType) {
case 'Uint8':
view.setUint8(0, metaLength)
break
case 'Uint16':
view.setUint16(0, metaLength, false) // false表示大端序
break
case 'Uint32':
view.setUint32(0, metaLength, false)
break
default:
throw new Error(`Unsupported metaLengthType: ${metaLengthType}`)
}
// 6. 写入元数据和二进制数据
totalBuffer.set(metaBuffer, lengthBytes)
totalBuffer.set(new Uint8Array(dataBuffer), lengthBytes + metaLength)
return totalBuffer.buffer
}
/**
* 解码混合数据
* @param combinedBuffer 编码后的ArrayBuffer
* @param metaLengthType 元数据长度存储类型(需与编码时一致)
* @returns 解构出的元数据和二进制数据
*/
public static decode<T extends Record<string, any>>(
combinedBuffer: ArrayBuffer,
metaLengthType: MetaLengthType = 'Uint16',
): { metadata: T, buffer: ArrayBuffer } {
// ... 反向处理
}
}💡 问题四:如何防止"快车"拖垮"慢车"?
想象一个场景:发送方是一台性能强劲的电脑,网络飞快;接收方是一台老旧的手机,处理速度慢。如果发送方不加节制地疯狂发送数据块,会发生什么?
数据并不会立刻通过网络发送出去,而是会先进入浏览器内部的一个"待发送缓冲区"。如果这个缓冲区被塞满(因为发送速度远大于网络传输和接收方处理速度),新的数据块就会无处安放,最终可能导致浏览器崩溃或连接中断。这就是所谓的"背压"(Back-pressure)问题。
这个问题困扰了我很久,因为我写 Demo 时都是发送小数据,每次都没问题,一写大项目就各种异常
更重要的是,我翻遍了网站关于 WebRTC 的文章(包括 AI Deep Research),没有找到任何关于 RTCDataChannel 的背压传输说明
最终只能看 MDN 文档慢慢找了
解决方案:基于 bufferedAmount 的智能流量控制
为了解决这个问题,我利用了 RTCDataChannel 提供的一个属性:bufferedAmount。
- 它是什么?
bufferedAmount告诉我们当前有多少数据字节堆积在"待发送缓冲区"里,还没来得及通过网络发出去。 - 为什么要检查? 它可以实时反映网络的拥堵情况和接收方的处理能力。如果这个数值持续增高,说明我们发送得太快了。
- 什么时候检查? 在发送每一个文件块之前,我都会检查这个值。
- 如何应对? 当我发现
bufferedAmount超过了一个我设定的安全阈值时,我会暂停发送。不要用轮询,而是监听一个更智能的事件:bufferedamountlow。这个事件在浏览器成功发送掉一部分缓冲区数据,使其降低到阈值以下时自动触发。我用一个Promise来"等待"这个事件,一旦触发,Promise完成,发送循环才会继续。
ts
class RTCConnect {
/**
* 通道缓冲区是否过高
*/
get channelAmountIsHigh(): boolean {
if (!this.channelIsReady(this.channel))
return false
return this.channel.bufferedAmount > this.channel.bufferedAmountLowThreshold
}
/**
* 等待通道空闲
* 当通道缓冲区过高时,等待直到缓冲区降低到阈值以下
*
* @returns Promise<void> 当通道空闲时 resolve
*
* @example
* ```typescript
* if (rtcConnect.channelAmountIsHigh) {
* await rtcConnect.waitUntilChannelIdle()
* }
* rtcConnect.send(largeData)
* ```
*/
waitUntilChannelIdle(): Promise<void> {
return new Promise<void>((resolve) => {
if (!this.channelIsReady(this.channel)) {
resolve()
return
}
this.channel.onbufferedamountlow = () => {
resolve()
}
})
}
}这套机制就像一个智能的水龙头,能感知下水道的排水速度。当下水道快堵塞时,会自动关小水流,等通畅后再开大,从而动态地将发送速度匹配到接收方的处理能力,极大地保证了文件传输的稳定性和可靠性。
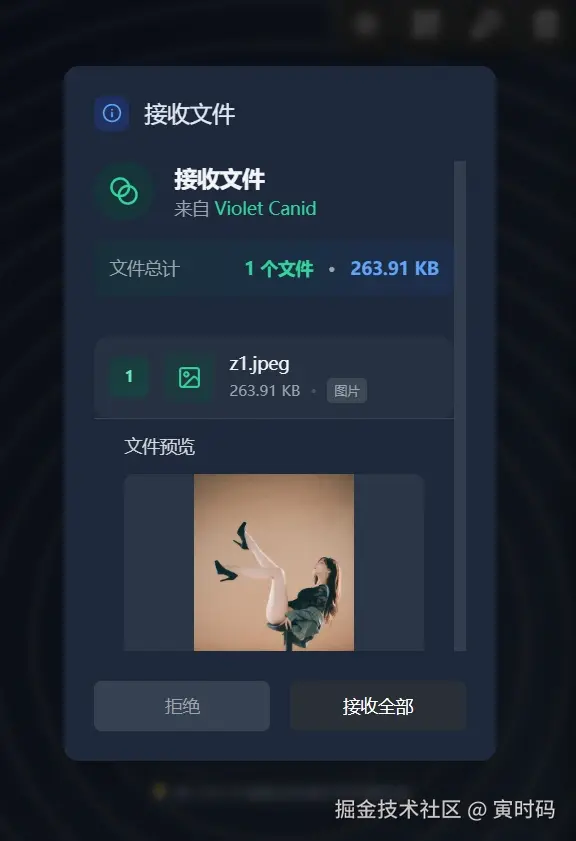
💡 问题五:文件预览是如何实现的?它和异步UI交互有何关联?
在发送文件前,接收方会弹出一个确认框,上面不仅有文件名、大小,甚至还有图片的预览图。用户点击"接受"或"拒绝"后,发送方才会继续或中止。
文件预览的"取巧"实现
你可能会想,预览图是不是通过 WebRTC 发送的?最初我也是这么想的,但很快发现一个问题:RTCDataChannel 对单次发送的数据大小有限制。一张经过压缩的 Base64 缩略图也可能有几十KB,很容易超出限制,导致数据发送失败。
因此,更稳妥的方案是:通过信令服务器来传递这份初始元数据。
在 FileSendManager 中,当用户选择文件后,我会先为图片生成一个低质量的 Base64 缩略图,然后将它连同文件名、大小等元数据一起,通过更可靠的 WebSocket 信令服务器发送给接收方。当接收方用户点击"接受"后,我们才开始通过高速的 WebRTC DataChannel 传输真正的、巨大的文件块。
这正是"好钢用在刀刃上":用信令服务器保证关键控制信息的可靠送达,用 WebRTC 保证海量数据的传输效率。
compressImg 压缩图片函数核心是利用 canvas 的能力实现的,同样来自我的工具库
ts
const metaPromises = files.map((file) => {
return new Promise<FileMeta>(async (resolve) => {
const res: FileMeta = getMeta(file)
/**
* 为首张可被浏览器解码的图片生成预览
* 1. 仅尝试常见浏览器支持的格式,排除 HEIC/HEIF 等
* 2. 若生成失败,记录 warning 并继续,不再 reject,避免整个 Promise.all 失败
*/
if (res.type.startsWith('image/') && !hasImg) {
hasImg = true
try {
const url = URL.createObjectURL(file)
const img = await getImg(url)
if (img) {
const base64 = await compressImg(img, 'base64', 0.1, 'image/webp')
res.base64 = base64
}
else {
console.warn('无法加载图片,跳过预览: ', file.name)
}
URL.revokeObjectURL(url)
}
catch (error) {
console.warn('生成预览图失败,将继续发送文件而不附带预览:', error)
}
}
/** 无论预览是否成功,都正常 resolve,确保元数据发送流程不中断 */
resolve(res)
})
})
const data = await Promise.all(metaPromises)
this.fileMetaCache = data
/** 通过 WebSocket 中转,因为 WebRTC 接收文件大小有限 */
this.config.relay({
data,
toId,
fromId: this.config.getPeerId(),
type: Action.FileMetas,
})💡 问题六:如何优雅的实现异步UI交互?
这里还有一个挑战:底层的 WebRTC 传输逻辑,如何"暂停"下来,等待用户的 UI 操作(点击"接受"或"拒绝")?
我的解决方案是,利用 Promise 来创建一个"遥控器",完美地解耦了数据逻辑与UI展现。
-
逻辑层需要"许可" :当接收方的
RTCPeer(逻辑层)收到文件元数据后,它知道需要用户确认。 但它不关心UI长什么样,它只做一件事:**创建一个"遥控器"(Promise.withResolvers),并把这个遥控器(包含resolve和reject按钮)递交给上层(UI层)。Promise.withResolvers是一个新的 Api,他能立刻获取resolve和reject函数,很方便 然后,它就在原地await这个Promise,相当于暂停等待遥控器的指令。 在相当多的地方,我都用到了这种方式,他非常方便tsconst { promise, resolve } = Promise.withResolvers() me.value.sendOffer(selectedPeer.value.peerId, resolve) promise.then(() => console.log('Offer sent to room owner after scan join')) /** * 等待 RTC 通道连接 */ async function connectRTCChannel(peer: UserInfo) { if (!selectedPeer.value || !me.value) return const { promise, resolve } = Promise.withResolvers() await me.value.sendOffer(peer.peerId, resolve) await promise }你也不用担心兼容性,这个 Api 很简单,完全可以自己实现一个
tsexport function PromisePolyfill() { // @ts-ignore if (Promise.withResolvers) { return } Promise.withResolvers = function <T>() { let resolve: (value: T | PromiseLike<T>) => void, reject: (reason?: any) => void const promise = new Promise<T>((_res, _rej) => { resolve = _res reject = _rej }) return { resolve: resolve!, reject: reject!, promise, } } } -
UI层接收"遥控器"并展示:(UI层)拿到了这个"遥控器",它的任务是弹出一个漂亮的确认框给用户看,然后静静地保管好这个遥控器。
-
用户按下"按钮" :当用户在界面上点击"接受"按钮时,UI层的代码就会按下遥控器上的
resolve按钮。如果用户点击"拒绝",就按下reject按钮。 -
逻辑层响应"指令" :逻辑层
await的那个Promise终于收到了信号,从暂停状态中恢复过来。根据是resolve还是reject,它就知道是该继续准备接收文件,还是通知对方传输已取消。
这个模式,就像给异步流程安装了一个可由UI控制的"暂停/播放开关",使得底层的网络逻辑可以完全独立于上层的UI实现,极大地提升了代码的可读性和可维护性。
💡 问题七:如何实现可靠的断点续传并保证数据完整性?
网络抖动、手滑关闭页面,是大文件传输的噩梦。断点续传是必备功能。
解决方案:哈希识别 + IndexedDB 缓存 + 偏移量协商与校验
-
哈希识别 :传输开始前,使用"文件名 + 文件大小"为任务生成一个唯一的
fileHash,作为"身份证"。 -
本地缓存 :接收方每收到一个带有元数据 的数据块,就会将其存入浏览器的
IndexedDB中。ResumeManager.ts负责管理这些缓存,它像一个高效的仓库管理员。 -
偏移量协商 :当连接恢复,准备再次接收同一文件时(通过
fileHash识别),接收方先查IndexedDB,计算出已下载的最大连续偏移量。然后通过ResumeInfo消息告诉发送方:"请从第10485761个字节开始发。" 发送方收到后,就会从指定位置继续传输。
数据完整性如何保证?
这是断点续传的灵魂。如果缓存的数据是错乱的、有"空洞"的,那么最后拼接出的文件就是损坏的。
我在 ResumeManager.ts 中做了关键处理:
- 利用生成器,一点一点的流式输出数据,避免一次性加载大量数据,导致浏览器卡顿
- 简单说一下生成器,他就是数组的核心方法,当一个对象实现了生成器,就能用
for of迭代它 - 每次调用
next方法,都会返回一个{ value, done }对象,value是当前迭代的值,done是是否迭代完成 - 生成器是可以暂停的,所以无需一次加载所有数据,性能非常好。你可以像数组一样直接使用它即可
- 简单说一下生成器,他就是数组的核心方法,当一个对象实现了生成器,就能用
- 利用偏移量校验,确保数据块的连续性
- 利用 IndexedDB 缓存,来存储大量的二进制数据
- 利用
fileHash识别,确保数据块的唯一性 - 利用
ResumeInfo消息,确保数据块的连续性
连续性校验 在从缓存中恢复数据时,我并不仅仅是读出所有数据块。我会对所有缓存块的偏移量进行连续性校验 。如果发现偏移量不连续(例如,0, 16384, 49152,中间丢失了 32768),我会认为从断点处开始的缓存是不可靠的,果断丢弃所有不连续的数据,并只从最后一个连续的位置请求数据。
这种"宁缺毋滥"的设计,确保了最终文件的完整性和正确性。
ts
class ResumeManager {
// ...
async* getCachedChunksStream(fileHash: string): AsyncGenerator<ChunkInfo, void, unknown> {
// ... 获取所有缓存块的 key,并按偏移量排序
let sortedOffsets = chunkKeys
.map(key => ({ key, offset: Number.parseInt(key.split('_').pop() || '0', 10) }))
.sort((a, b) => a.offset - b.offset)
// ======================
// * 校验数据偏移连续性
// ======================
let offsetIndex = 0
for (const { offset } of sortedOffsets) {
if (offset !== offsetIndex++ * CHUNK_SIZE) {
/** 数据块不连续! */
Log.error(`数据块不连续...放弃部分数据`)
/** 只保留连续的部分 */
sortedOffsets = sortedOffsets.slice(0, offsetIndex - 1)
/** 删除无效的缓存 */
this.deleteResumeCache(fileHash)
break
}
}
// ...
/** 之后只 yield 连续部分的数据块 */
}
// ...
}使用生成器一点点读取
ts
class FileDownloadManager {
/**
* 恢复缓存的数据到下载缓冲区(优化版本 - 流式处理)
*/
private async restoreCachedData(): Promise<number> {
if (!this.currentFileHash) {
return -1
}
/** 使用流式处理,避免一次性加载所有数据到内存 */
const chunkStream = this.resumeManager.getCachedChunksStream(this.currentFileHash)
let chunkCount = 0
let lastOffset = 0
/** 流式处理每个数据块 */
for await (const chunk of chunkStream) {
lastOffset = chunk.offset
await this.writeFileBuffer(chunk.data)
chunkCount++
/** 每处理100个数据块输出一次进度 */
if (chunkCount % 100 === 0) {
console.warn(`恢复缓存数据进度: ${this.currentFileHash}, 已处理: ${chunkCount} 个数据块`)
}
}
if (chunkCount > 0) {
Log.info(`恢复数据偏移量: ${lastOffset}`)
Log.success(`缓存数据恢复完成: ${this.currentFileHash}, 总计: ${chunkCount} 个数据块`)
return lastOffset
}
return -1
}
}💡 问题八:扫码加入房间如何实现
原理其实非常简单
- 后端生成一个随机码,发给前端
- 前端拼接
${URL}?roomId=${roomId}通过 qrcode 库转为二维码 - 用户扫码后,前端解析二维码,识别为 URL,自动打开浏览器
- URL 附带的 roomId、peerId 可以被前端解析,前端再把数据通过 WebSocket 发给后端,后端根据 roomId、peerId 找到对应的房间,将用户添加到房间
ts
import QRCode from 'qrcode'
/**
* 前端处理URL查询参数
*/
function handleQuery(route: RouteLocationNormalized) {
const { roomId, peerId } = route.query as { roomId: string, peerId: string }
if (!roomId || !peerId) {
return
}
server.joinDirectRoom(roomId, peerId)
}
/**
* 处理服务器创建二维码
*/
async function handleQRCodeRommCreate(
data: RoomInfo,
info: UserInfo | undefined,
setLoading: (state: boolean) => void,
) {
if (data.roomId) {
if (info) {
info.roomId = data.roomId
server.saveUserInfoToSession(info)
}
const { peerId } = data.peerInfo
qrData = `${ServerConnection.getUrl().href}/fileTransfer/?roomId=${encodeURIComponent(data.roomId)}&peerId=${encodeURIComponent(peerId)}`
console.log('创建房间成功:', qrData)
try {
qrCodeValue.value = await QRCode.toDataURL(qrData, { errorCorrectionLevel: 'H', width: 300 })
return true // 表示应该显示二维码模态框
}
catch (err) {
console.error('生成二维码失败:', err)
Message.error('生成二维码失败,请稍后再试')
}
}
setLoading(false)
}💡 问题九:如何实现大文件下载
我看了很多类似项目,它们无一例外,都是把所有数据加载到内存里,这样浏览器很容易内存溢出
你们有注意过吗?比如你在网上点击一个 URL,他会一点点下载,无论多大,都不会内存溢出。而我正是要实现这种方式
传统下载方式
ts
const blobs = [...无数个 Blob]
/**
* 合并成一个 Blob,转成 URL,然后下载
* 此时如果数据过大,浏览器会崩溃,因为内存溢出
*/
const url = URL.createObjectURL(new Blob(blobs))
const a = document.createElement('a')
a.href = url
a.download = 'file.zip'
a.click()
URL.revokeObjectURL(url)流式下载方式
- 使用 Service Worker,但是需要 Https 环境,且兼容性不佳,尤其是移动端
- 使用 File System Access API,但是需要用户手动授权,且兼容性不佳,尤其是移动端
为了解决兼容性,我实现了一个优雅降级的下载器(如果不支持上面两种方式,会自动使用 Blob 下载),同样在我的工具库有提供
使用方式如下,我写了一个简单的 demo,你可以参考 github.com/beixiyo/jl-...
你需要在下载的 node_modules 中找到 @jl-org/tool 包,复制 streamDownload.js 到你的项目中根目录中,他是我打包的 Service Worker 文件
ts
const swDownloader = await createStreamDownloader(fileName, {
swPath: '/streamDownload.js',
})
for (let i = 0; i < 10; i++) {
const data = new Blob(['anything'])
const buffer = await data.arrayBuffer()
await swDownloader.append(new Uint8Array(buffer))
}
console.log('Service Worker Stream Download Complete')
await swDownloader.complete()🚀 开发与部署
本地开发
得益于 pnpm 和 Monorepo 架构,本地开发非常简单。
bash
# 克隆项目
git clone https://github.com/beixiyo/web-share.git
cd web-share
# 安装依赖
pnpm i
# 一键启动所有服务 (client, server, common)
# 首次运行需要执行两次,构建 common 包
pnpm run devpnpm run dev 命令会并行启动客户端、信令服务器和公共模块的监视模式,任何代码改动都会实时生效。
Docker 部署
项目已提供 Dockerfile 和 docker-compose.yml,一键部署到你的服务器。
关键步骤:
- 修改
docker-compose.yml文件。 - 找到
VITE_SERVER_URL环境变量,将其值修改为你的服务器公网IP或域名 对应的 WebSocket 地址(例如wss://your.domain.com)。这是为了让公网上的客户端能正确找到你的信令服务器。 - 执行
docker compose up -d。
部署后,在两个不同设备上(同一局域网)访问客户端地址,即可开始测试。
🔍 代码流程标记说明
为了便于开发者理解复杂的断点续传流程,我们在关键代码位置添加了 @数字. 描述 格式的流程标记
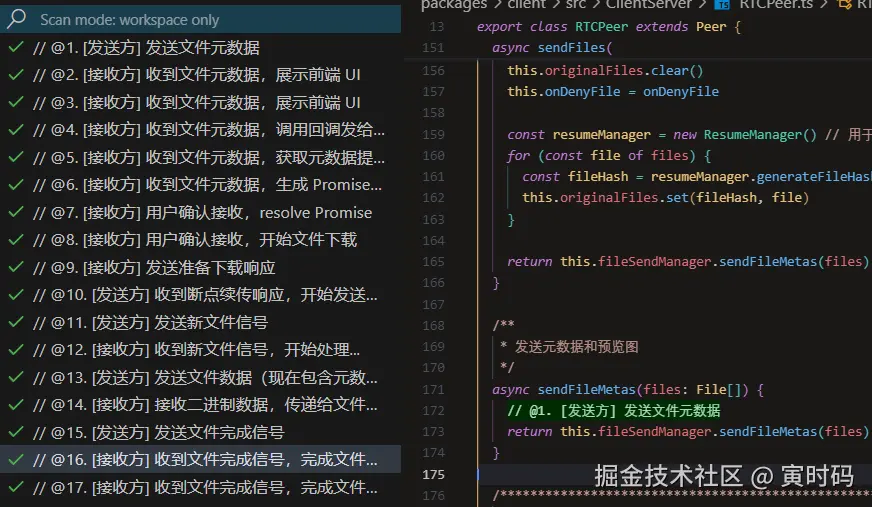
如何查看流程标记:
-
使用我定制的 VSCode Todo Tree Enhanced 插件(推荐):
- 项目已配置
.vscode/settings.json,自动识别@数字.格式标记 - 在 VSCode 侧边栏查看 "TODO TREE Enhanced" 面板
- 点击标记可直接跳转到对应代码位置
- 项目已配置
-
手动搜索:
- 在项目中搜索
@01.@02.等标记 - 按数字顺序查看完整流程
- 在项目中搜索
💡 提示:使用 VSCode Todo Tree 插件可以快速浏览所有流程标记,点击即可跳转到对应代码位置。