告别等待,秒级响应!这不只是教程,这是你驾驭PB级数据的超能力!我的ClickHouse视频课,凝练十年实战精华,从入门到精通,从单机到集群。点开它,让数据处理速度快到飞起,让你的职业生涯从此开挂!
全套视频教程联系博主 :试听视频位置
1 什么是稀疏索引?
首先,让我们忘掉传统数据库(如 MySQL)中的 B+Tree 索引。传统索引非常"稠密",它几乎为表中的每一行数据都建立一个索引条目,这使得它能快速定位到单行数据,但代价是索引本身会占用大量磁盘和内存空间,并且在写入新数据时需要复杂的维护(如页面分裂、旋转、合并)。
它是一种非常轻量级的索引,其核心思想是:不记录每一行数据的索引,只为每个数据块(Granule)的第一行数据建立索引条目。
这就好比一本书的目录:
-
稠密索引(MySQL) :像是书末尾的"索引表",列出了几乎所有重要名词和它出现的具体页码(例如:
ClickHouse: 5, 12, 23, 41...)。 -
稀疏索引(ClickHouse) :像是书开头的"章节目录",只告诉你每一章从哪一页开始(例如:
第一章: 第1页,第二章: 第25页,第三章: 第50页)。
当你需要找一个特定内容时,你先看目录(稀疏索引)找到它可能在的章节,然后你只需要阅读那一章(数据块),而不需要翻遍整本书。
2 核心概念: Granule 和 index_granularity
要理解稀疏索引,必须先理解 Granule (数据颗粒/数据块) 这个概念。
-
Granule:是 ClickHouse 中数据存储和索引的基本单位。一个表的数据在物理上被分割成许多个Granules。 -
index_granularity:这是一个表设置,定义了每个Granule大约包含多少行数据。默认值是 8192 。这意味着 ClickHouse 在写入数据时,会以大约 8192 行为一个单位,将它们打包成一个Granule。
稀疏索引 就是为每个 Granule 创建一个索引条目,该条目记录了此 Granule 中主键列的 起始值 和它在物理文件中的 偏移量。
3 图解稀疏索引的结构
假设我们有一张表,按 (EventDate, UserID) 作为主键排序,并且 index_granularity 设置为 4(为了方便演示,实际是8192)。
表数据如下:
|-----------|--------|----------|
| EventDate | UserID | Action |
| 2023/10/1 | 101 | login |
| 2023/10/1 | 105 | view |
| 2023/10/2 | 102 | click |
| 2023/10/2 | 109 | purchase |
| 2023/10/3 | 101 | view |
| 2023/10/3 | 103 | logout |
| 2023/10/4 | 110 | view |
| 2023/10/4 | 112 | click |
ClickHouse 在存储时,会这样做:
-
数据文件 (
.bin):所有列的数据被连续存储。 -
主键索引文件 (
primary.idx):存储稀疏索引。
下面是这个过程图示:
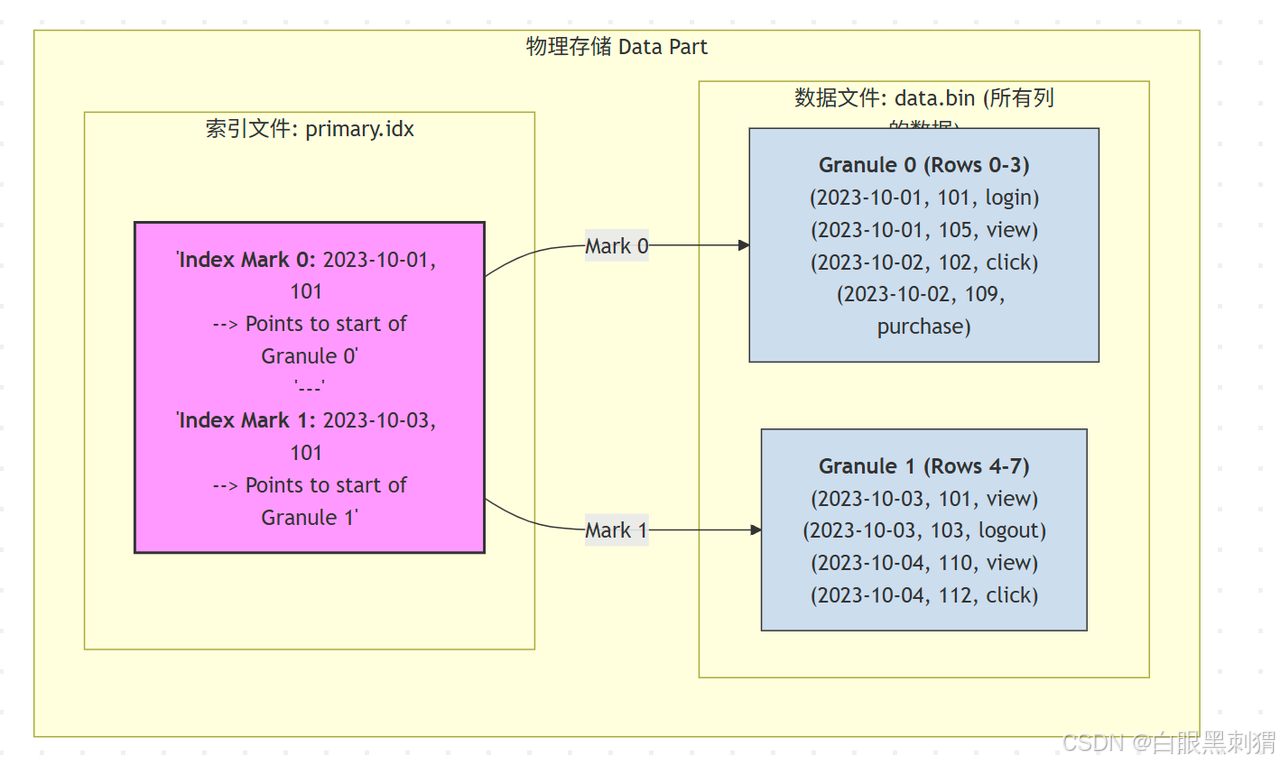
图解说明:
-
左侧
data.bin:是实际存储数据的压缩文件。数据被分成了两个Granule(因为我们的index_granularity假设为 4)。 -
右侧
primary.idx:这就是稀疏索引文件。-
Mark 0 : 记录了
Granule 0的主键起始值(2023-10-01, 101)。 -
Mark 1 : 记录了
Granule 1的主键起始值(2023-10-03, 101)。
-
-
箭头 :表示索引中的每个"标记"(Mark)指向对应
Granule在data.bin文件中的物理起始位置。
- 稀疏索引如何工作?(查询过程)
这是稀疏索引最神奇的地方。它通过排除法来大幅减少需要扫描的数据量。
查询示例: SELECT * FROM table WHERE EventDate = '2023-10-02'
查询处理流程如下:
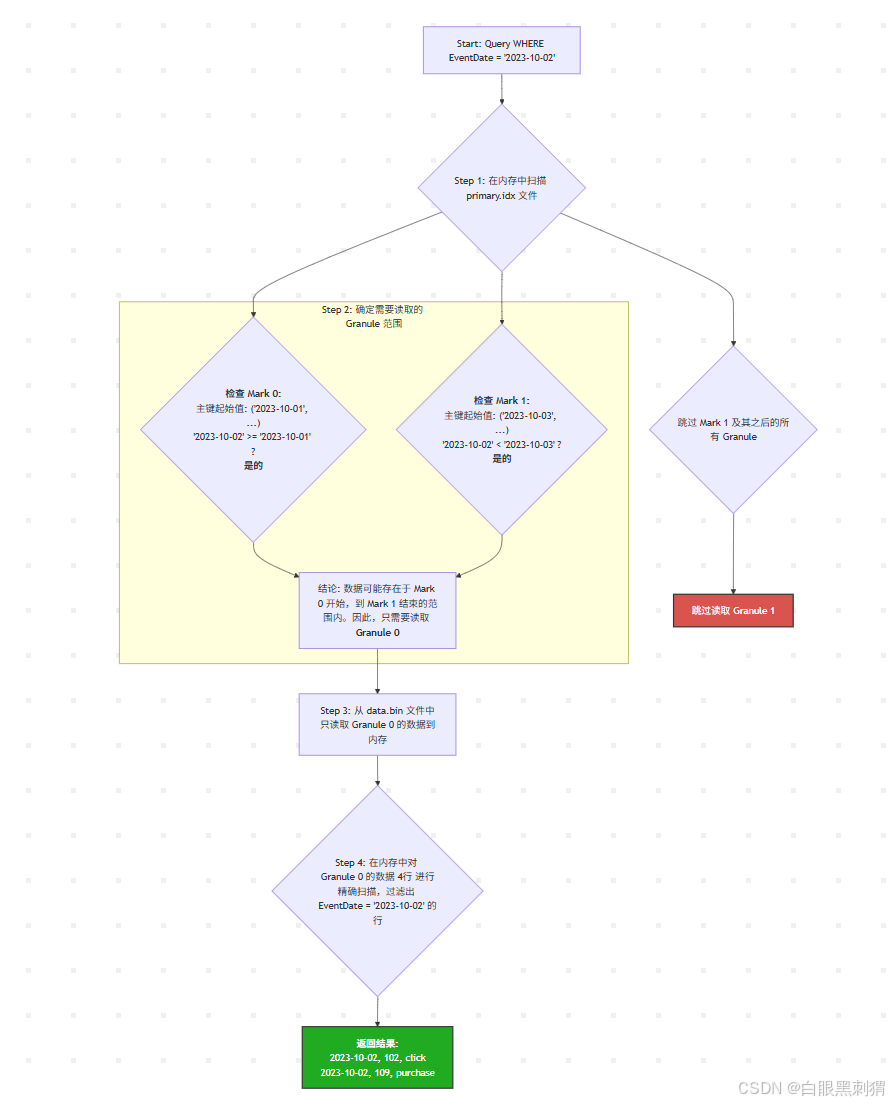
流程详解:
-
扫描索引 (Step 1) : ClickHouse 加载
primary.idx文件到内存(这个文件非常小),然后用查询条件EventDate = '2023-10-02'与索引中的每个标记进行比较。 -
确定范围 (Step 2):
-
'2023-10-02'大于等于 Mark 0 的起始日期'2023-10-01'。 -
'2023-10-02'小于 Mark 1 的起始日期'2023-10-03'。 -
ClickHouse 推断出,所有满足条件的数据 如果存在,必定在
Granule 0中 。因此,它完全不需要考虑Granule 1以及后续所有的数据块。这就是所谓的 "剪枝"(Pruning)。
-
-
读取数据 (Step 3) : ClickHouse 根据 Mark 0 指向的偏移量,从
data.bin文件中只读取Granule 0的数据(在本例中是4行,实际中是8192行)。 -
内存过滤 (Step 4) : 将解压后的
Granule 0数据加载到内存中,然后进行逐行精确匹配,最终找到符合条件的2行数据。
通过这个过程,我们避免了全表扫描,也避免了读取 Granule 1,查询效率大大提升。
4 优点和最佳实践
优点:
-
极小的索引开销:由于每 8192 行才有一个索引条目,索引文件非常小,可以轻松缓存在内存中。
-
写入性能高 :写入新数据时,只需在文件末尾追加新的
Granule和索引标记,几乎没有额外的索引维护成本。 -
对范围查询极其友好 :对于
WHERE time > '...' AND time < '...'这样的范围查询,稀疏索引可以快速定位到包含这些时间的Granule范围,效率极高。
最佳实践(非常重要!):
-
主键选择和数据排序是关键!
-
稀疏索引的有效性 完全依赖于数据是按主键物理有序存储的。
-
应该将查询中最常用的 低基数 、范围查询 的列放在主键的最前面。例如,对于日志分析,
ORDER BY (EventDate, EventType, ...)是一个非常好的主键选择。 -
如果你的数据没有按主键排序,稀疏索引将 完全失效,查询会退化为全表扫描。
-
-
合理设置
index_granularity-
默认值 8192 通常是最佳选择,在大部分场景下无需修改。
-
较小的值(如 4096):索引更精确,可能需要读取的数据块更少,但索引文件会变大。
-
较大的值 (如 16384):索引文件更小,但每个
Granule更大,可能导致查询时读取更多不必要的数据到内存中。
-
总结
ClickHouse 的稀疏索引是其高性能分析能力的基础。它通过牺牲单点查询的极致性能(与B+Tree相比),换来了极高的写入吞吐量、极低的索引维护成本和对范围扫描的卓越性能。
理解了 Granule、index_granularity 和基于数据排序的"剪枝"工作原理,你就掌握了 ClickHouse 查询优化的核心精髓。记住,用好 ClickHouse 的第一步,就是设计好你的主键( ORDER BY 子句)。