开源模型数量: DeepSeek开源主模型+多个蒸馏版本共6款,文心4.5全面开源从 0.3B 到 424B共10款模型。
开源协议: DeepSeek是开源MIT协议,而百度文心4.5开源在Apache 2.0协议。MIT 更加宽松,Apache 2.0 更规范。MIT是开发者的最爱,Apache是企业法务的刚需。因为Apache 2.0明确授予用户对代码中涉及的专利具有使用权。
部署友好度: 部署这方面DeepSeek更偏向于社区开发者,百度文心更偏向于工业级的部署。当然DeepSeek虽然偏向于社区驱动,但事实上很多企业级也是部署deepseek,也就是我们常看到的满血版DeepSeek。
如果说这次文心的开源对国内大模型,在技术方面会带来非常大的影响,肯定还是不现实的,毕竟DeepSeek的能力摆在那的。或许更多的影响是在企业级、开源理念方面的影响。
虽然文心官方给出来的数据还是比较好的,但使用后还是能测试出很多问题。比如:
- 3+4等于几的问题?
- 4.19与4.2哪个更大?

大模型普遍走向开源的三大驱动因素
社区驱动、加速创新
开源可以激发全球研发者协同迭代,快速修复与优化模型。是吸引用户提高知名度较快的手段之一。只要用户起来了,生态起来了就会有投资者投入资金。
在中国并不缺乏开源的土壤的,开源排行榜top10里就是3个中国项目在里面,中国不缺乏开源精神的种子,所以在开源AI浪潮中中国出线也并不奇怪。
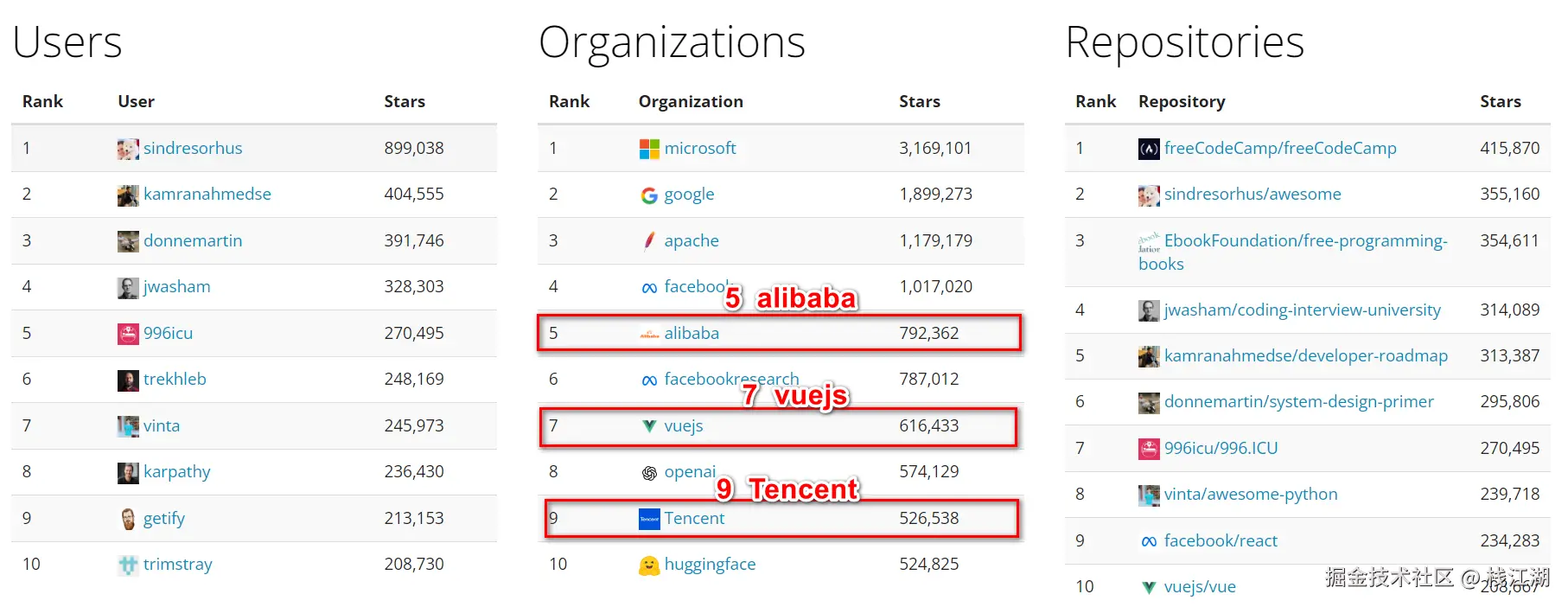
打开User这个维度的排行榜,可以看到中国人(含华人)占比24% ,在全球占比非常的高。
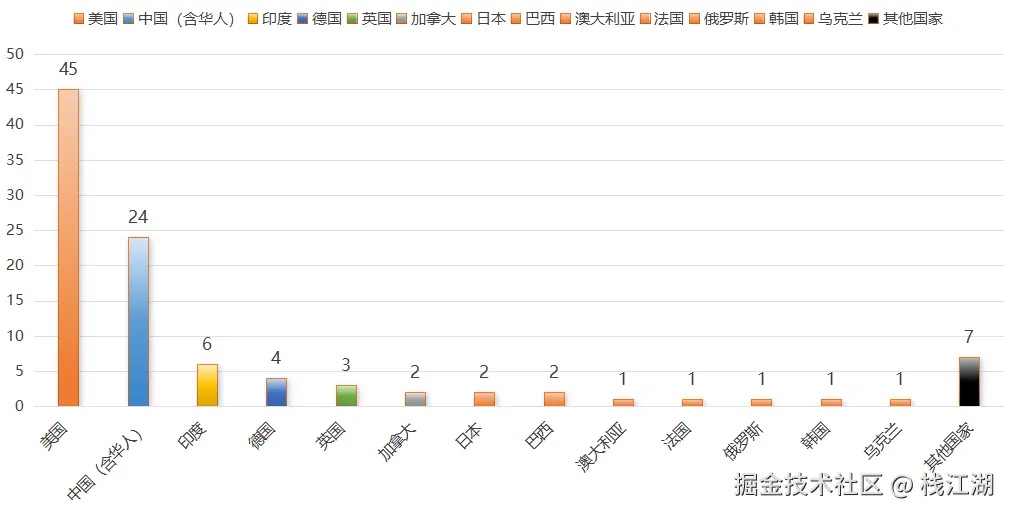
中国的开源开发者还非常的活跃,另外国人对开源的关注性一直都很高。
数据透明与安全可控
对于AI平台来说最核心的就是算力、算法、数据。
目前互联网能获取的数据基本上都差不多了,现在就是通过用户使用AI来获取用户的数据,说直白点说是要给AI投喂数据。但站在用户这个角度来说,我的数据投喂给了AI那我的秘密、隐私都泄露了。
对于个人用户、企业用户都是一样的,需要使用AI,但又担心隐私的泄露。特别是企业的业务数据,很多都是公司赢利的关键不能被泄露。所以企业更迫切需要搭建属于自己的AI大模型。如果AI是个闭源的,黑盒程序信息泄露的担心会更加强烈。而如果它开源了,那就完全没有这个担心了。
生态扩张,吸引资本
目前互联网很多企业本身是不赚钱的,比如openai一直说自己每年亏很多钱,但还是非常积极的开着公司,不会倒闭。因为他们本身就不是靠卖API来赚钱的,靠的是吸引资本的投资,让他们的身价上升、股票升值。
再如Hugging Face虽然以开源工具起家,但融资估值已达45亿美元。
而模型一旦开源就会被大量的开发者部署、微调,这样就会快速形成粘性很强的生态,不少开发者不但是用户,还是测试者、开发者。