本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第4篇,解析跨国异构数仓迁移背后的企业级权限管理升级与数据安全技术增强的全过程。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
前言
随着东南亚数字经济的蓬勃发展,支付和电商巨头 GoTerra 作为区域领导者,其数据规模和复杂度持续增长。为了满足日益增长的业务需求和合规要求,GoTerra 决定将其大数据业务从 Google BigQuery 迁移到阿里云 MaxCompute 平台。这一迁移不仅是技术平台的转换,更是数据治理和安全体系的全面升级。
针对 BigQuery 与 MaxCompute 的产品差异点,MaxCompute元数据团队在现有访问控制原子能力基础上,开发了 GCP 兼容的权限体系和 Catalog 管理 API,帮助 GoTerra 实现了元数据、角色权限等配置的高效平滑迁移。
本文将重点介绍MaxCompute在跨域访问控制和数据安全领域为 GoTerra 量身定制的企业级特性,包括跨账号多层级访问控制、基于PolicyTag策略标签的数据动态脱敏等功能,这些特性不仅解决了 GoTerra 在迁移到 MaxCompute 时遇到的卡点,同时也为 MaxCompute 的用户提供了更完善的数据安全解决方案。
异构迁移下的权限安全挑战
由于 GoTerra 作为东南亚互联网集团,其自身业务覆盖多个领域且组织架构复杂,需要在统一平台的情况下,能够支持不同业务间不同的权限管理与配置需求。
复杂的业务需求:
- 复杂组织架构的权限架构:GoTerra 作为大型集团,内部有多个独立或半独立的业务线,每个业务线内部又可能有数据开发、数据科学、数据分析师、业务人员等不同角色和团队,他们对数据的访问需求各不相同(例如,开发需要读写,分析师只需要读取特定脱敏后的数据)。
- 严格的权限分离与最小权限原则:为了数据安全和合规,需要确保每个用户或团队只能访问其工作所必需的最小数据集,不能越权访问其他业务线或敏感数据。
- 多账号间灵活管理:GoTerra 在阿里云上使用了多个账号,需要在保证安全的前提下实现跨账号的数据共享和协作。
同时客户深度应用与依赖 Google BigQuery的权限管理模型,因此需要MaxCompute新企业级能力需要兼容BigQuery的权限管理特性。
BigQuery的权限管理特性:
- 与 IAM (Identity and Access Management) 高度集成:客户可以将 IAM 上定义的 BigQuery API 粒度的权限,绑定到具体的 BigQuery 资源(如 Dataset 或者 Table)上,从而实现更细粒度的授权,以及授权关系的水平可扩展。
- 资源层级授权 :权限可以在 Google Cloud 的资源层级结构(如
Organization -> Project -> Dataset -> Table)上进行定义和继承。这意味着可以很容易地为一个项目或数据集(Dataset)设置一组权限,这些权限会自动应用于其下的所有表。 - 预定义和自定义角色:提供了丰富的预定义角色,也支持用户创建自定义角色,精确控制具体可以执行的操作。
- 灵活的成员管理:可以将角色分配给个人用户、服务账号、Google Groups(组)等不同类型的"成员",便于基于团队或职能进行批量授权和管理。
- 易于管理的列级权限:支持集中管理的、可复用的、支持树状结构的策略标签 (Policy Tag),再将标签应用到列上并通过标签管理用户权限。
而MaxCompute的权限系统 对比 BigQuery 的产品特性差异,与客户权限需求的GAP:
- MaxCompute 的核心权限边界是"Project项目":*虽然项目内可以通过 ACL(Access Control List)或 policy 授权,但与BigQuery 那样在更高层级(如组织/资源目录)或更细粒度层级(如 Schema、表、列)进行统一、继承式管理的原生权限机制,有较大差异。
- 权限粒度较粗 :我们的权限控制主要集中在项目级别的访问(如
Read,Write)和对象级别的基本操作(如对特定表的Select,Describe),缺乏像 BigQuery IAM 那样可以精确到具体 API 操作粒度的控制。 - 缺乏高级继承机制:在原始模型下,如果要给一个团队(比如 GoTerra 的"数据分析团队")授予对多个项目或多个 Schema 下所有表的只读权限,需要对每个表或每个项目单独进行授权,管理起来非常繁琐且容易出错。它不支持像 BigQuery 那样的"在项目/数据集层级授予权限,自动应用于所有子资源"的继承特性。
- 跨项目、跨账号授权复杂:虽然我们有一定的跨项目资源共享能力(通过 package),也有一定的跨账号访问能力。但在 GoTerra 的多账号架构下,这些方式都不够安全或便捷,缺乏基于组织结构的边界控制能力。
- 列级权限使用复杂:列级脱敏策略是直接在项目内定义和管理的,与特定的项目关联,并直接绑定到特定的表列,缺乏集中式的标签管理概念和树状结构。每个策略更像是一个独立的规则定义,不方便策略的复用。
MaxCompute权限体系架构升级
为了解决 GoTerra 在迁移过程中的复杂需求,MaxCompute权限团队引入了一种全新的多层级访问控制系统。
全新资源层级结构
原有的权限系统主要基于项目级别,无法满足 GoTerra 复杂的组织架构和权限需求。为此,我们引入了命名空间(Namespace)等实体概念,作为比项目更大的数据平面边界。命名空间同时也会关联到资源目录(Resource Directory)上,以方便多账号管理。
新的层级结构如下图所示:
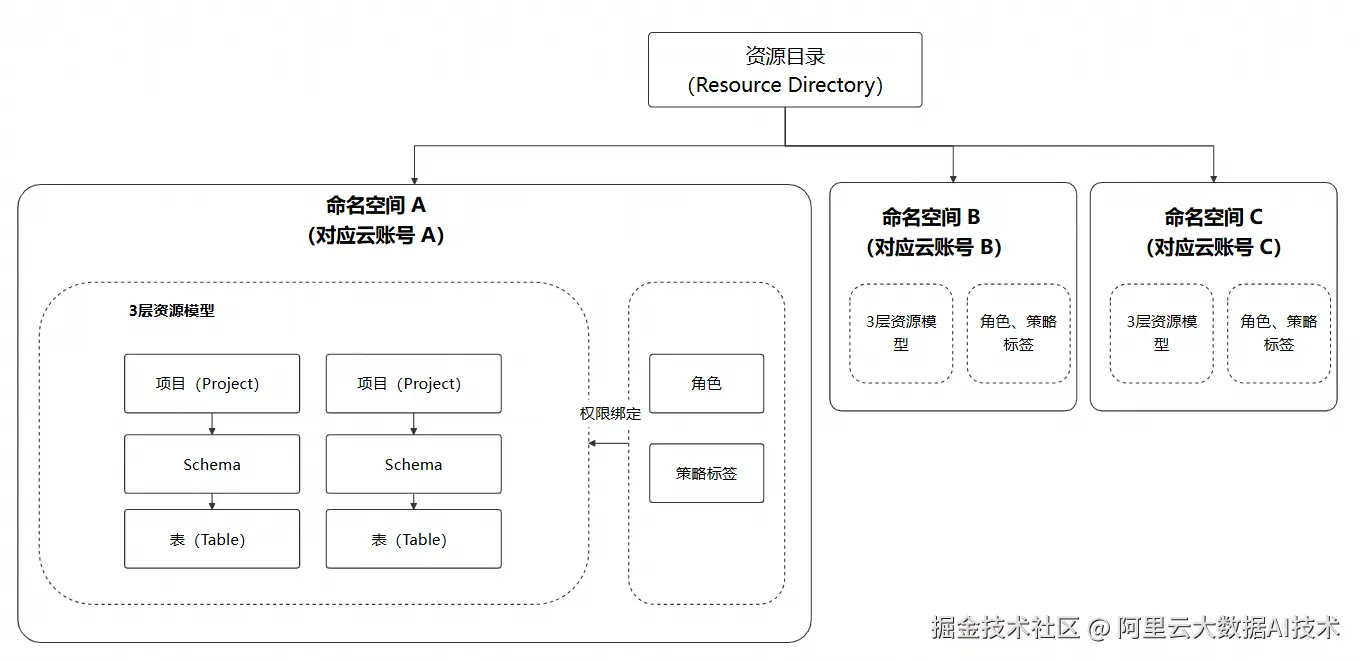
- 资源目录(ResourceDirectory):RD是阿里云提供的一个顶层组织和管理资源的容器。一个 RD 可以包含多个阿里云账号(主账号),这些账号可以是企业内部的不同部门、子公司或不同的业务单元。在 MaxCompute 中,RD是最大的边界,一个 RD 可以包含多个命名空间(如果这些命名空间所属的项目分别属于 RD 内的不同主账号)。
- 命名空间(NameSpace):这是 MaxCompute 新引入的一个比项目更大的数据平面边界,它可以将多个项目组织在一起,方便进行统一的权限管理。用户可以通过 Catalog API 或者 DCL 授权语句,在命名空间这一层级创建自定义角色,以及策略标签。创建好的自定义角色和策略标签,可以应用于所属命名空间内的所有项目。 目前,命名空间和阿里云主账号是一对一的关系。
- 项目(Project):这是 MaxCompute 中最基础和核心的组织单元。用户在 MaxCompute 中进行的所有操作(如创建表、运行 SQL、提交作业等)都必须在一个具体的项目中进行。一个项目只属于一个命名空间,并且可以包含多个 Schema。
- 模式 (Schema):项目内部的一个逻辑分组,用于组织和管理表和其他资源对象(如表的快照、函数、资源等)。一个 Schema 只属于一个项目,并且可以包含多个表。
- 表 (Table):这是 MaxCompute 中存储结构化数据的基本单元。用户可以将策略标签应用于表的特定列,实现基于策略标签的数据动态脱敏和列级访问控制。
扩展角色和权限继承
全新权限体系最显著的特点是权限继承,权限可以在资源层级结构中从上层对象传递到下层对象。
- 继承规则:当用户被授予某个对象(如 Schema)的权限时,该权限通常会自动应用于该对象所包含的所有下层子对象(如该 Schema 下的所有 Table)。
- 灵活性: 虽然存在继承,但用户也可以在更细粒度的级别(如特定的 Table)上授予或撤销权限,实现更精确的控制。
- 命名空间级别角色: 支持用户通过 Catalog API 或 SQL(DCL 语句)创建自定义角色,此角色可以作用在同一个命名空间的所有项目。
下面,我们通过一个虚构的跨部门数据协作与分析的场景, 来说明新的权限系统是如何工作的。
场景描述:
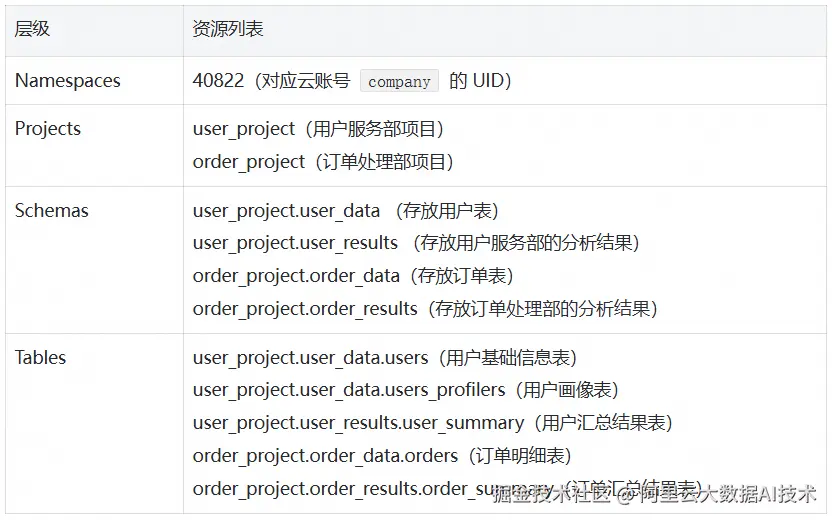
一家公司有两个核心业务部门:用户服务部 (User Service) 和 订单处理部 (Order Processing)。公司需要进行数据分析,以优化运营。
- 用户服务部负责用户信息管理,其数据存放在项目
user_project中的user_project.user_dataSchema 下。 - 订单处理部负责订单处理,其数据存放在 MaxCompute 项目
order_project中的order_project.order_dataSchema 下。订单处理部需要读取用户服务部的用户基础信息来完成订单处理。 - 数据分析部需要访问两个部门处理后的最终结果数据,以便进行报表和分析。
资源分层结构:
用户列表:

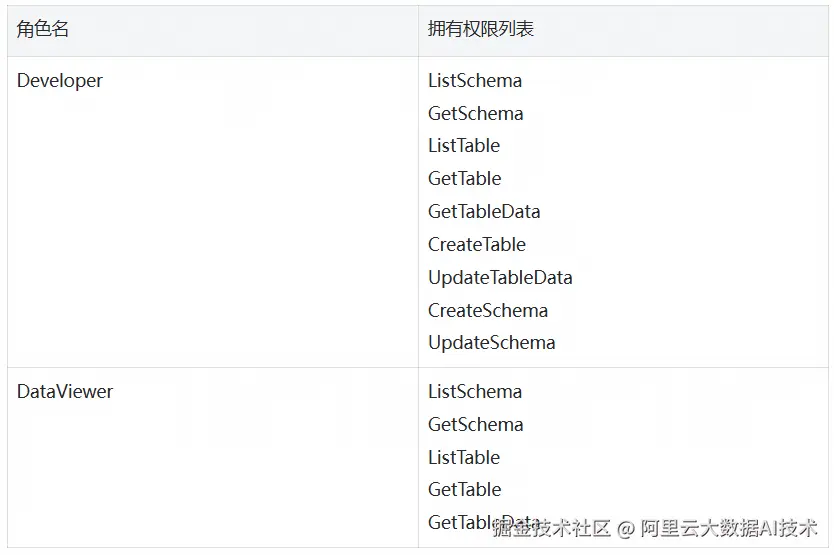
自定义角色(通过 Calalog API 创建):
权限配置与继承演示
初始状态: 所有用户(除了管理员)对所有项目、Schema、表均无权限。
权限配置由管理员进行操作。
步骤 1:配置用户服务部研发权限。
- 目标:
alice对user_project下的所有数据拥有完全权限(开发、维护、读取)。 - 操作:将
Developer角色授予alice在user_project级别。 - DCL:
GRANT `namespaces/40822/roles/Developer` ON PROJECT user_project TO RAM$company:alice - 效果(权限继承):
alice获得了user_project的所有权限。- 根据继承规则,
alice自动获得了user_project.user_data和user_project.user_results两个 schema 的ListSchema,GetSchema权限。 - 同时,
alice也自动获得了这两个 schema 下的所有表(users,user_profiles,user_summary)的ListTable,GetTable,GetTableData,UpdateTableData,CreateTable等权限。 - 总结:通过在项目级别授权,
alice继承了对该项目内所有 Schema 和表的完整开发权限。
步骤 2:配置订单处理部研发权限。
- 目标:
bob对order_project下的所有数据拥有完全权限(开发、维护、读取)。 - 操作 1:将
Developer角色授予bob在order_project级别。 - DCL:
GRANT `namespaces/40822/roles/Developer` ON PROJECT order_project TO RAM$company:bob - 效果:
bob对order_project及其所有 Schema 和表拥有完全权限(同alice的情况)。 - 操作 2:将
DataViewer角色授予bob在user_project.users_data.users表上。 - DCL:
GRANT `namespaces/40822/roles/DataViewer` ON TABLE user_project.users_data.users TO RAM$company:bob - 效果:
bob获得了对users表的读取权限。注意,这里没有给bobuser_project或user_dataSchema 的写权限,仅限读取这张特定的表。 - 继承说明:这个权限是直接授予表的,不涉及向上或向下的继承。它精确地满足了
bob读取特定依赖数据的需求,而不会继承到users表所在 Schema 的其他表或整个项目。
步骤 3:配置数据分析师权限
- 目标:
carol能读取两个部门的结果数据(user_summary,order_summary)。 - 操作 1:将
DataViewer角色授予carol在user_project.user_resultsSchema 上。 - DCL:
GRANT `namespaces/40822/roles/DataViewer` ON SCHEMA user_project.user_results TO RAM$company:carol - 效果(权限继承):
carol获得了对user_project.user_resultsSchema 的GetSchema,ListTable权限。- 通过继承,
carol自动获得了该 Schema 下所有表(如user_summary)的GetTable,GetTableData权限。 - 操作 2:将
DataViewer角色授予carol在oder_project.order_resultsSchema 上。 - DCL:
GRANT `namespaces/40822/roles/DataViewer` ON SCHEMA order_project.order_results TO RAM$company:carol - 效果:和
user_results类似,carol获得了oder_project.order_resultsSchema 下所有的读权限。 - 总结:通过在两个结果 Schema 级别授权,
carol利用权限继承机制,获得了访问这两个 Schema 下所有结果表的只读权限,而无需对每张表单独授权。
基于PolicyTag策略标签的动态数据脱敏
为满足 GoTerra 对敏感数据访问的严格控制和合规要求,我们引入了基于策略标签 (Policy Tag) 的集中式动态数据脱敏功能。该功能借鉴了 Google BigQuery 的先进理念,并结合阿里云生态进行了优化,提供了灵活、可复用且支持层级结构的列级访问控制和数据脱敏能力。
核心概念
- 动态脱敏:无需用户修改现有查询SQL,数据被访问时系统会根据访问者身份对敏感数据列进行脱敏处理,确保数据在查询、下载、关联分析、UDF计算时已经处于脱敏状态,有效避免个人信息等数据的泄露风险。
- 策略标签 (Policy Tag):这是附加到表列上的元数据标签,用于标识该列的数据敏感性(如 PII、财务数据、机密信息等)。
- 分类法 (Taxonomy):策略标签可以组织成树状结构的分类法。一个分类法可以包含多个策略标签,策略标签之间可以有父子层级关系。这种层级结构支持权限的继承和精细化管理。
- 数据策略 (Data Policy):与策略标签关联的规则,定义了对该标签标记的列数据的访问行为。主要类型包括:
- 列级安全策略 (COLUMN_LEVEL_SECURITY_POLICY):定义哪些用户或角色可以访问(读取)被该标签标记的列数据。
- 数据脱敏策略 (DATA_MASKING_POLICY):定义当用户无权访问原始数据时,应如何展示脱敏后的数据(例如,显示为
NULL、默认值、或经过哈希处理的值)。 - 预定义角色:
MaskedReader:被授予此角色的用户,可以读取被策略标签标记的列的脱敏后数据。FineGrainedReader:被授予此角色的用户,可以读取被策略标签标记的列的原始、未脱敏数据。
工作流程
- 定义分类法和策略标签:在命名空间创建分类法,并在其中定义策略标签及其层级关系。
- 配置数据策略:为每个策略标签创建数据策略,指定其列级安全规则和数据脱敏规则。
- 分配角色:将
MaskedReader或FineGrainedReader角色授予给加入到 MaxCompute 中的 RAM 用户或角色,并绑定到特定的策略标签上。 - 应用策略标签:将定义好的策略标签应用到表的相应列上。
- 查询与生效:用户查询表时,系统根据其被授予的角色和查询的列所关联的策略标签,动态决定返回原始数据、脱敏数据或拒绝访问。
集中式管理与跨项目复用
策略标签、分类法和数据策略均定义在命名空间层级。由于一个命名空间通常对应一个云账号,这意味着可以在账号级别集中创建和管理一套统一的策略标签体系。这套体系可以被应用于该命名空间下所有项目内的表,极大地简化了多项目环境下的数据安全管理,确保了策略的一致性。
下面,我们通过一个虚构的样例,来演示如何通过策略标签的层级结构和角色分配,实现非常精细的访问控制。
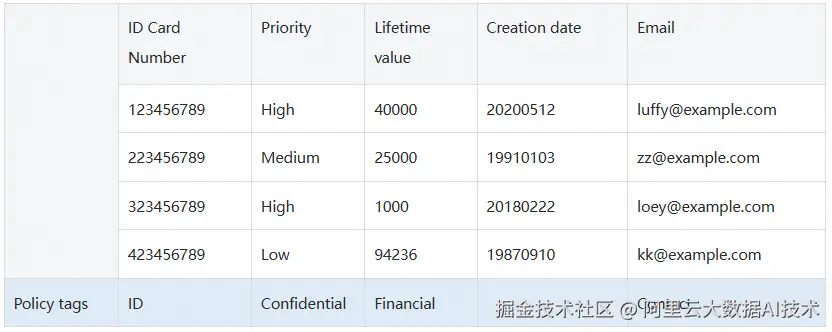
假设有一个用户画像表proj1.schema1.user_profiles:
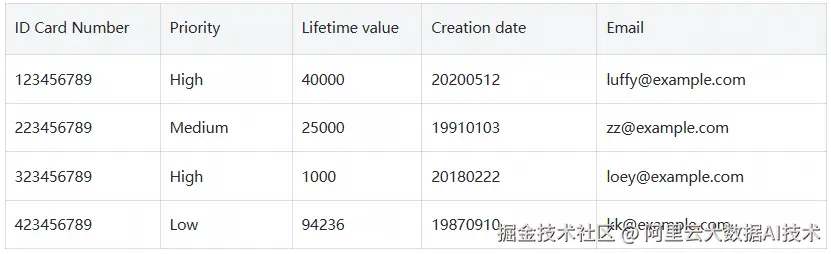
- 策略标签设置:
- 创建一个名为
sensitive_data的分类法。 - 在
sensitive_data下创建PII标签。 - 创建
ID和Contact标签,作为PII的子标签。 - 创建
Confidential标签。 - 创建
Financial标签,作为Confidential的子标签。 - 标签应用:
idCardNumber列应用ID标签。priority列应用Confidential标签。lifetimeValue列应用Financial标签。email列应用Contact标签。- 数据策略与角色分配:
- 为
PII标签配置数据脱敏策略(如ALWAYS_NULL),并为用户user1,user2,user3,user4分配MaskedReader角色。 - 在
ID标签上,为用户user2分配FineGrainedReader角色。 - 在
Confidential标签上,为用户user3分配FineGrainedReader角色。 - 为
Financial标签配置数据脱敏策略(如SHA256哈希),并为用户user4分配MaskedReader角色。
经过上述配置后,策略标签的树状结构,以及每个标签的角色分配如下图所示:
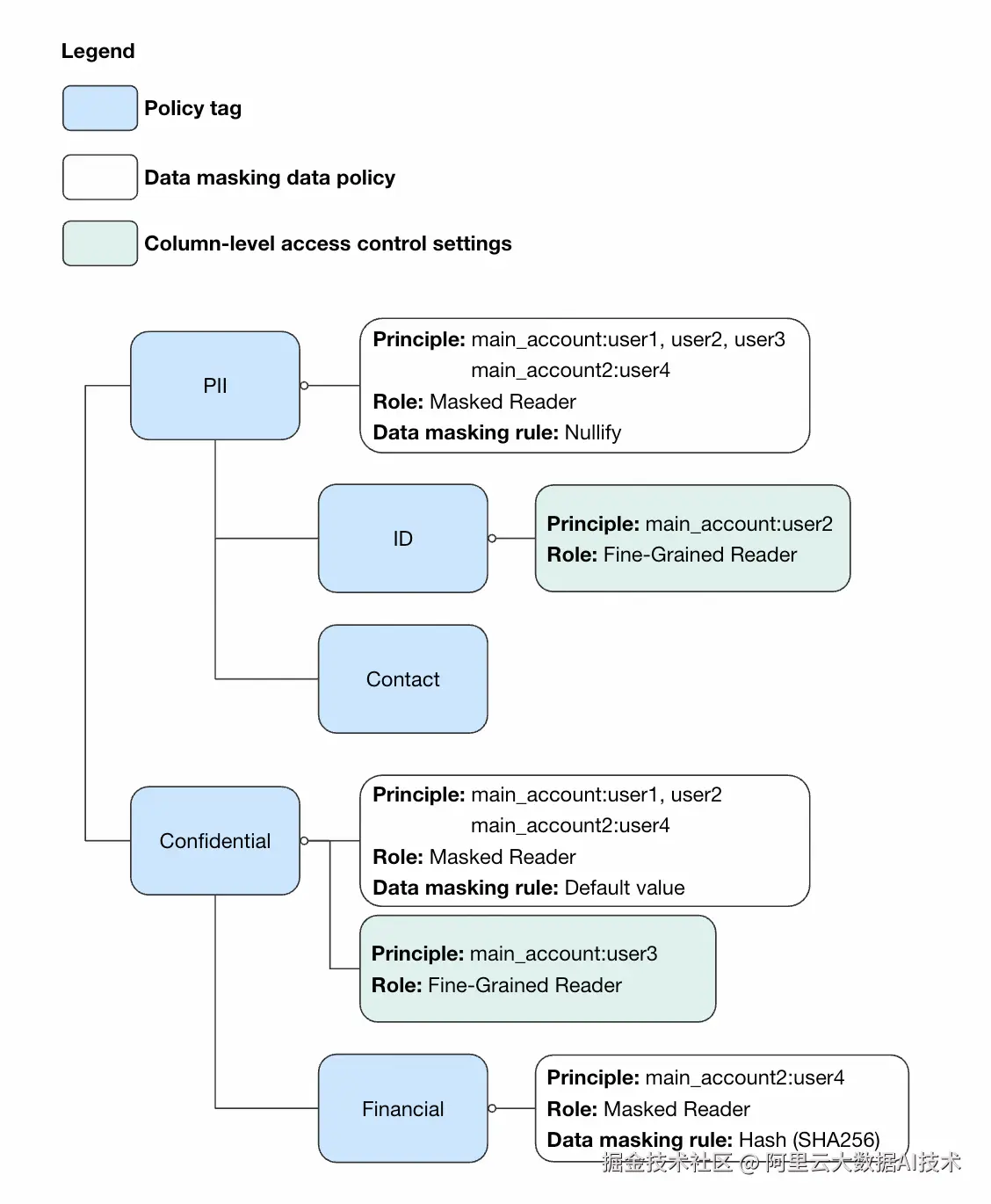
接下来,我们将创建好的策略标签绑定到表的不同列上,如下表所示。
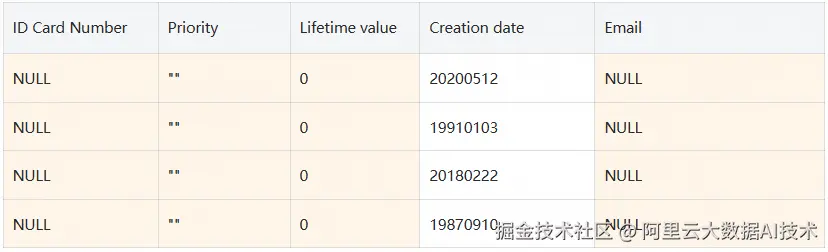
根据与列关联的标签,运行SELECT * FROM proj1.schema1.user_profiles; 会对不同的用户产生以下结果:
user1: 该用户已被授予PII 和Confidential 策略标签的MaskedReader 角色。返回以下结果:
user2: 该用户已被授予ID 策略标签的FineGrainedReader角色。返回以下结果:
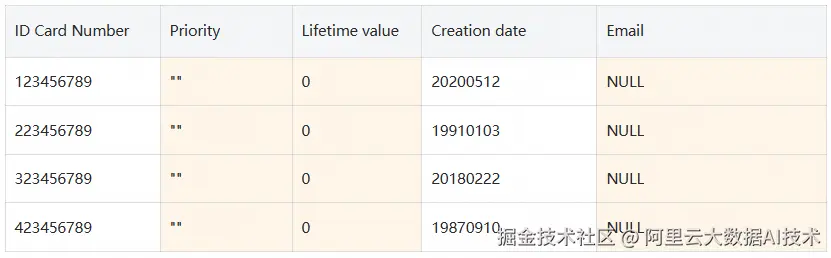
user3: 该用户已被授予Confidential 策略标签的FineGrainedReader 角色。返回以下结果:
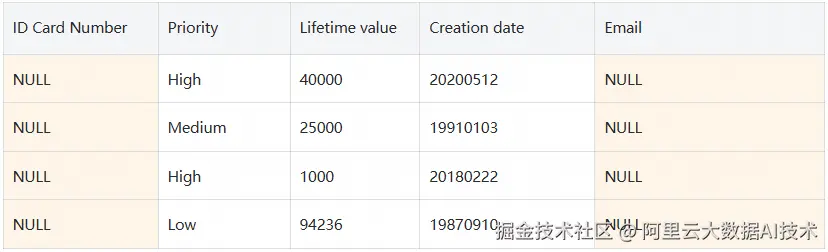
user4: 该用户已被授予Financial 策略标签的MaskedReader 角色。返回以下结果:
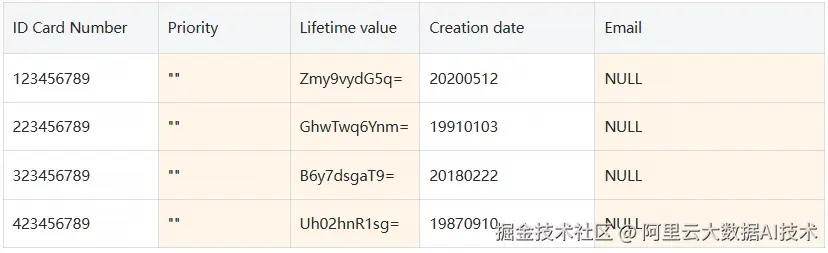
所有其他用户: 任何不属于上述列出组的用户都会收到访问被拒绝的错误,因为他们尚未被授予FineGrainedReader 或MaskedReader 角色。要查询proj1.schema1.user_profiles 表,他们必须在 SELECT 语句中指定他们有权访问的列。
跨账号用户管理及访问控制
在企业级环境中,基于业务需求、部门职能、资产管理及合规要求的差异,通常会设立多个云账号以实现资源的有效管理和隔离,例如:数据管理方拥有专门的账号和项目空间用于集中存储与写入数据;各业务部门则通过独立的账号和项目空间执行特定任务的数据处理工作;安全部门同样配置有专用项目空间来进行安全审计等活动。
为了确保对敏感信息的严格访问控制,在实际操作过程中,数据管理者需直接负责权限分配,即由数据提供方向具体的数据使用方授予访问权限。这样一来,虽然业务使用者利用自身项目中的计算能力来处理数据,但其访问外部(即数据提供方)项目中的数据时,必须遵循预先设定好的授权规则。这种方法不仅加强了数据安全性,还促进了跨团队间的协作效率。
在多账号环境下,我们基于资源目录(RD)实现了跨主账号的身份授权边界,并提供了细粒度的权限管理能力。这使得企业的数据管理员能够在 MaxCompute 内统一管理同一 RD 下的用户,将这些云账号中的RAM 用户和角色添加为 MaxCompute 的成员,并进行详细的权限配置,无需额外设置委托授权。这样不仅确保了数据权限完全由数据所有者掌控,还减少了对主账号身份依赖所带来的安全风险。
同时,为了防范未经授权的外部人员获取敏感信息,我们允许用户通过 RD 控制策略来限制哪些用户可以被添加至特定 MC 项目之中,同时简化了多账号场景下的安全管理流程。
以下为 RD 控制策略,限制只允许同一个 RD 之下的 RAM 用户和角色被添加到 MaxCompute:
json
{
"Version": "1",
"Statement": [
{
"Effect": "Deny",
"Action": [
"odps:AllowCrossAccountAddUser"
],
"Resource": "*",
"Condition": {
"Bool": {
"odps:InSameRD": [
"false"
]
}
}
}
]
}从权限体系升级看企业价值
对于像 GoTerra 这样的大型企业而言,其大数据业务具有高度复杂性,这不仅体现在技术层面的数据处理与分析上,还反映在其支撑这一业务运作的组织架构之中。鉴于此,企业在权限管理体系方面面临着既要确保管理便捷性又要实现精细化控制的双重挑战。因此,构建一个既能够支持高效运维又具备强大灵活性和可扩展性的权限管理系统成为了此类企业不可或缺的核心能力之一。
以此为契机,我们实现了如下特性:
引入全新的层级结构,提供了完整、分层的管理和控制体系:
- RD 解决了跨账号的安全边界问题。
- 命名空间提供了更高层次的统一管理和策略定义点。
- 项目是核心的资源和安全边界。
- Schema 增加了逻辑分组和中间层授权的能力。
- 表是最终的数据载体,支持最细粒度的权限控制和列级安全(通过策略标签)。
支持权限在层级化资源上的自动继承:
- 简化管理:通过在较高层级授予权限,可以利用继承自动将权限应用到下层所有对象,大大减少了重复的授权操作。
- 精确控制:当需要更精细的权限时,可以在特定层级(如 Table)直接授予权限,且该权限不会自动继承到其他对象,满足了特定的跨部门数据依赖需求。
- 职责分离:不同的用户根据其职责获得了恰到好处的权限,既保证了工作效率,又保障了数据安全。
引入基于策略标签的动态数据脱敏功能:
- 强化数据安全与合规:集中定义敏感数据标签并关联脱敏策略,有效防止敏感信息泄露,满足企业合规要求。
- 灵活精细的访问控制:策略标签支持层级结构和继承,允许在标签层级统一定义访问规则(原始数据或脱敏数据),并可应用于具体列,实现了真正的列级精细化控制。
- 提升数据协作效率:不同角色可根据权限看到不同级别的数据视图,既保证安全又促进了安全的数据共享。
- 降低管理复杂度:策略标签和数据策略在命名空间级别集中管理、跨项目复用,简化了大规模环境下的敏感数据治理,确保策略一致性。
强化跨域访问控制与安全合规:
- 通过基于资源目录(RD)的身份边界控制和精细化的层级权限体系,有效防止了跨账号的非授权访问,满足了企业在多账号环境下严格的合规与数据安全要求,简化了安全管理流程。
结语和展望
MaxCompute全新权限安全系统与数据安全升级能力已在2025年 3 月发布到海外Region,支撑 GoTerra 线上业务。
同时我们还将在以下方向进一步探索:
- 权限系统的智能化:引入 AI 技术,自动推荐权限配置,降低权限管理复杂度。
- 脱敏策略的自动化:基于数据内容自动识别敏感信息,动态应用脱敏策略。
通过与 GoTerra 的深度合作,MaxCompute 正在成为企业级大数据平台的标杆,为全球用户提供安全、可靠、高效的数据处理服务。此次 GoTerra 搬站项目不仅是一次技术迁移,更是 MaxCompute 产品能力的一次全面提升。我们相信,这些为企业级数据安全和访问控制打造的新特性,在确保数据安全和合规的前提下,将帮助更多企业实现数据价值的最大化。