背景
做前端好多年了, 在掘金前端热榜上,刷到的好多文章,都是旧饭新炒。这种情况说明, 前端技术已从蓝海变成红海,需要寻找新的蓝海,才能比较easy的获取到大量的新知识。那么该选择哪门编程语言作为下一个目标呢,个人感觉Python比较有前途,因为当下比较火热的AI大模型领域,编程语言用的就是Python。目标选定好了之后,我们写一个查询年度基金排名的入门级应用,练练手。废话不多说了,现在我们进入正题。
第一步 安装Python及项目依赖包
1. 安装Python
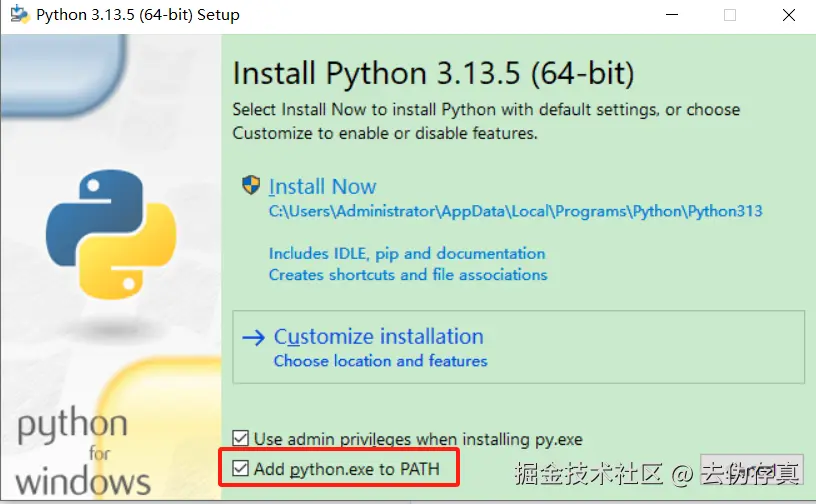
下载win最新版的Python,安装时记得勾选Add python.exe to PATH
2. 安装项目依赖的Python包
这里说两点:第一点,给pip配置永久镜像源,以提升下载速度,解决连接问题。第二点,要做环境隔离。Python项目安装依赖包时,建议设置环境隔离。
1.配置永久镜像源
常用国内镜像源有:
| 国内镜像源 | 地址 |
|---|---|
| 清华大学 | pypi.tuna.tsinghua.edu.cn/simple |
| 阿里云 | mirrors.aliyun.com/pypi/simple |
| 中国科技大学 | pypi.mirrors.ustc.edu.cn/simple |
| 华中理工大学 | pypi.hustunique.com/simple |
| 豆瓣 | pypi.douban.com/simple |
可以采用ping指令测试各个源的响应速度,例如
bash
ping pypi.tuna.tsinghua.edu.cn
ping mirrors.aliyun.com
// ...经过测试,发现阿里云比较快,所以将pip镜像源配置成阿里源。打开Windows: C:\Users\<你的用户名>\pip\pip.ini文件,如果没有,可以手动创建pip文件夹,并在此文件夹下创建一个pip.ini文件。填写如下内容:
bash
[global]
index-url = https://mirrors.aliyun.com/pypi/simple配置完之后,可以用下面的命令验证配置是否成功
bash
pip config list2.设置环境隔离
为什么需要环境隔离?不同项目可能依赖不同版本的库,比如: 项目A需要 pandas 版本1.3, 项目B需要 pandas 版本2.0; 如果你在系统全局安装包,没有隔离,会产生冲突,导致代码跑不起来。隔离后,每个项目的依赖包版本互不干扰,代码环境干净且可控。
如何做环境隔离呢,采用下面的命令:
bash
cd 项目目录
python -m venv venv # 创建虚拟环境
source venv/Scripts/activate # win激活虚拟环境
pip install 依赖包 # 安装依赖
pip freeze > requirements.txt # 记录依赖
# 下次打开项目
source venv/Scripts/activate
# 团队成员拉取新项目时
source venv/Scripts/activate
pip install -r requirements.txt第二步 编写查询基金年度排名功能
1. 编写主体功能
整理思路就是:
- 从所有基金中筛选出可以进行T+0交易的基金。
- 对符合条件的基金进行排名,打印出排名前三的基金
对于T+0的判断逻辑,这里要说明一下:A股市场中,ETF的属性字段没有直接是标注"T+0"还是"T+1"交易。要判断一个ETF是支持T+0交易,主要是基于以下几个关键规则:
- 跨境ETF:只要是投资境外市场(例如:港股、美股、日股、德股等)的ETF,并且在境内(沪深两市)上市,通常都可以进行T+0交易。这是因为这类ETF的底层资产在境外,与A股市场的交易时间存在时差,为了方便投资者交易,监管机构允许其当日买入后当日卖出。
- 黄金ETF:在沪深交易所上市的黄金ETF,如华安黄金ETF(518880),也属于T+0交易品种。
- 货币基金ETF:在交易所上市的货币市场基金,如华宝添益(511990),也支持T+0交易。
- 商品期货ETF:跟踪国内商品期货指数的ETF,比如豆粕ETF、原油ETF等,也属于T+0交易。
通过关键词匹配的方式来筛选,是一个非常有效的、也是目前最主流的实现方式。
初始版本是:
python
import akshare as ak
import pandas as pd
from datetime import datetime
def get_qdii_etf_rank():
try:
df = ak.fund_etf_fund_daily_em()
# 过滤含有海外、全球、港股、美股、纳指等关键词
df = df[df["基金简称"].str.contains("全球|纳指|标普|恒生|港股|美股|道琼斯|国际|MSCI|海外", na=False)]
# 提取并转换"近1年"列
df["近1年"] = pd.to_numeric(df["近1年"].str.rstrip('%'), errors="coerce")
# 排序取前10
top10 = df.sort_values(by="近1年", ascending=False).head(10)
print(f"\n[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] 全球ETF近一年涨幅前10:\n")
print(top10[["基金代码", "基金简称", "基金类型", "近1年"]].to_string(index=False))
except Exception as e:
print(f"获取 ETF 数据失败:{e}")
if __name__ == "__main__":
get_qdii_etf_rank()这个Python脚本用到了两个外部依赖包,它们的功能如下:
| 模块导入名 | pip 安装包名 | 用途说明 |
|---|---|---|
akshare |
akshare |
提供财经数据接口库,可获取股票、基金、期货、宏观等金融数据 |
pandas |
pandas |
提供强大的数据处理、表格处理能力,例如 DataFrame。适用于读写 CSV、Excel、数据分析等。 |
执行安装命令进行安装,如果安装成功,但运行报错,大概率因为Python版本与依赖包依赖的包版本不兼容,需要把Python升级到最新版本。
js
# 安装依赖
pip install akshare pandas
# 验证安装是否成功
python -c "import akshare, pandas, requests; print('All packages are installed')"2. 更换数据源
查询A股所有的ETF时,老是报错: Connection aborted., ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接, 意思说客户端成功地向数据服务器(远程主机)发起了连接请求,但服务器那边因为某种原因,在数据还没传输完的时候就单方面切断了这个连接。发现是ak.fund_etf_fund_info_em()引起的,ak.fund_etf_fund_info_em() 这个函数是从东方财富(em)获取数据的。akshare 库非常灵活,它常常提供来自不同数据源(如东方财富、新浪财经、腾讯财经)的接口。当一个源不稳定时,可以尝试更换另一个。可以用 akshare 中另一个获取ETF实时行情列表的函数 ak.fund_etf_spot_em() 来代替它。虽然这个函数主要用于获取实时价格,但它同样返回了一个包含代码和名称的ETF列表,足以满足筛选的需求。
3. 手动计算排名
更换数据源之后,获取ETF列表没有问题了,可是查询排名的时候又报错
js
第三步:正在获取所有基金的业绩排名数据...
❌ 第 1 次尝试获取基金排名数据失败: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
5秒后将进行重试...
❌ 第 2 次尝试获取基金排名数据失败: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
5秒后将进行重试...
❌ 第 3 次尝试获取基金排名数据失败: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))原因是调用东方财富出在调用ak.fund_open_fund_rank_em() 上。这个函数和最初失败的函数一样,都是从东方财富(em)获取数据,因此也同样遭到了网络拦截。既然直接获取"基金排名"这个大表格的路被堵死了,就换一种思路:不拿现成的排名表了,而是自己动手,一个一个地去查询符合条件的ETF过去一年的历史价格,然后手动计算出它们的涨跌幅。
这个方法虽然慢一点,但有两大优势:
- 查询单个ETF历史数据是小请求,不容易被防火墙拦截。
- 即使中途有几个ETF查询失败,程序也不会崩溃,可以跳过它们继续运行,最终能得到一个有效的结果。
将基础版修改为:
Python
import pandas as pd
import akshare as ak
import time
from datetime import datetime, timedelta
def find_top_t0_global_etfs_professional():
# --- 第一步:获取ETF列表 ---
print("第一步:正在获取所有A股ETF基金列表 (使用备用接口)...")
try:
etf_info_df = ak.fund_etf_spot_em()
etf_info_df.rename(columns={'名称': '基金简称'}, inplace=True)
print("✅ ETF列表获取成功!")
except Exception as e:
print(f"❌ 获取ETF列表失败: {e}")
return
# --- 第二步:筛选全球ETF (扩展关键词) ---
print("\n第二步:正在筛选潜在的T+0全球ETF...")
# 关键改动:在关键词列表中加入"香港"
keywords = ['纳指', '标普', '恒生', 'H股', '中概', '日经', '德国', '法国', '美国', '港股', '全球', '亚太', '越南', '印度', '香港']
pattern = '|'.join(keywords)
global_etfs_df = etf_info_df[etf_info_df['基金简称'].str.contains(pattern, na=False)].copy()
if global_etfs_df.empty:
print(" 未能找到符合条件的全球ETF。")
return
print(f" 已找到 {len(global_etfs_df)} 个潜在的T+0全球ETF。")
# --- 第三步:手动计算近一年涨跌幅 (增加专业过滤器) ---
print("\n第三步:正在逐个获取ETF历史数据并计算近一年涨跌幅...")
end_date = datetime.now()
start_date = end_date - timedelta(days=365)
end_date_str = end_date.strftime('%Y%m%d')
start_date_str = start_date.strftime('%Y%m%d')
results = []
total_etfs = len(global_etfs_df)
for index, row in global_etfs_df.iterrows():
etf_code = row['代码']
etf_name = row['基金简称']
print(f" 正在处理 ({index+1}/{total_etfs}): {etf_code} {etf_name}...")
try:
hist_df = ak.fund_etf_hist_em(symbol=etf_code, period="daily", start_date=start_date_str, end_date=end_date_str, adjust="qfq")
if not hist_df.empty and len(hist_df) :
start_price = hist_df.iloc[0]['收盘']
end_price = hist_df.iloc[-1]['收盘']
yearly_return = ((end_price / start_price) - 1) * 100
results.append({
'代码': etf_code,
'基金简称': etf_name,
'近1年涨跌幅': yearly_return
})
print(f" ✅ 计算成功: {yearly_return:.2f}%")
time.sleep(0.5)
except Exception as e:
print(f" ❌ 获取或计算失败,跳过。错误: {e}")
continue
if not results:
print("\n未能成功计算任何ETF的涨跌幅。")
return
# --- 第四步:排序和展示结果 ---
print("\n第四步:正在对结果进行排序...")
final_df = pd.DataFrame(results)
top_3_etfs = final_df.sort_values(by='近1年涨跌幅', ascending=False).head(3)
print("\n==================== 查询结果 (专业版) ====================")
print("近一年涨跌幅前三的可T+0交易全球ETF为:")
print("---------------------------------------------------------")
if top_3_etfs.empty:
print("在上市的基金中,没有找到符合条件的ETF数据。")
else:
top_3_etfs.reset_index(drop=True, inplace=True)
for index, row in top_3_etfs.iterrows():
print(f"🏆 排名 {index + 1}:")
print(f" - 基金代码: {row['代码']}")
print(f" - 基金简称: {row['基金简称']}")
print(f" - 近一年涨跌幅: {row['近1年涨跌幅']:.2f}%")
print("---------------------------------------------------------")
print("\n⚠️ 免责声明: 数据仅供参考,不构成投资建议,市场有风险,投资需谨慎。")
if __name__ == '__main__':
find_top_t0_global_etfs_professional()执行python main.py, 得到的结果是:
js
近一年涨跌幅前三的可T+0交易全球ETF为:
---------------------------------------------------------
🏆 排名 1:
- 基金代码: 159570
- 基金简称: 港股通创新药ETF
- 近一年涨跌幅: 133.74%
---------------------------------------------------------
🏆 排名 2:
- 基金代码: 513090
- 基金简称: 香港证券ETF
- 近一年涨跌幅: 133.37%
---------------------------------------------------------
🏆 排名 3:
- 基金代码: 159567
- 基金简称: 港股创新药ETF
- 近一年涨跌幅: 128.97%
---------------------------------------------------------和同花顺查询的结果对比了一下, 同花顺显示的结果是
js
1. 513090 | 香港证券ETF | 134.88%
2. 159570 | 港股创新药ETF | 127.33%
3. 159567 | 港股创新药ETF | 122.98%4. 结果差异原因
结果有些差异,造成这些差异的原因有:
-
近一年"的计算基准日不同:
- 代码 :
start_date = datetime.now() - timedelta(days=365),这会精确地从今天向前推365天。 - 同花顺 :同花顺的数据更新可能是每日收盘后,或者在某些特定时间点。它所定义的"近一年"可能是从今天(交易日)的收盘价与一年前同期交易日的收盘价进行对比。例如,如果一年前的今天是一个非交易日,同花顺可能会使用上一个交易日的数据。这种细微的时间差异就会导致计算结果不同。
- 代码 :
-
复权方式的细微差异:
- 代码 :
ak.fund_etf_hist_em(..., adjust="qfq"),使用的是前复权。 - 同花顺 :同花顺也使用复权数据,但其具体复权算法(比如对分红、拆分等事件的处理细节)可能与
akshare接口所采用的底层数据源略有不同。尽管绝大多数情况下差异很小,但在某些特定ETF上,累积起来的微小差异就可能影响最终的百分比。
- 代码 :
总结来说,代码逻辑是完全正确的。出现差异是由于数据源、计算基准日和复权细节上的不同。这种差异在金融数据分析中很常见,只要逻辑严谨,代码计算结果就是可靠的。
最后
今天有点事,先写到这里,下一步打算把查询出来的消息,推送到企微或微信,代码片段先保存着,未完待续。
js
def send_wechat(msg):
# 你需要替换成自己的 SKey,注册 Server酱:https://sct.ftqq.com/
server_key = 'YOUR_SERVER_CHAN_KEY'
url = f'https://sctapi.ftqq.com/{server_key}.send'
data = {
'title': '全球ETF涨跌幅排名(近一年)',
'desp': msg
}
try:
requests.post(url, data=data, timeout=10)
except Exception as e:
print(f'发送微信失败:{e}')
send_wechat(f"```\n{msg}\n```")