在 Python 中,多线程与多进程是实现并发编程的两种核心方式,但它们的底层原理和适用场景却有显著差异。本文将从原理出发,结合实例详细解析两者的特性、区别及最佳实践。
一、核心概念与底层差异
1. 多线程(Threading)
- 本质:基于操作系统原生线程实现,属于轻量级并发
- 内存空间:所有线程共享同一进程的内存空间(全局变量、文件句柄等)
- 核心限制:受 GIL(全局解释器锁)约束,同一时间只能有一个线程执行 Python 字节码
- 创建开销:较小,线程切换成本低
2. 多进程(Multiprocessing)
- 本质:通过创建独立进程实现并发,每个进程有独立的 Python 解释器
- 内存空间:进程间内存隔离,不共享全局变量
- 核心优势:不受 GIL 限制,可利用多核 CPU 实现真正的并行计算
- 创建开销:较大,进程切换成本高(约为线程的 10-100 倍)
二、深入理解 GIL:Python 多线程的 "隐形枷锁"
全局解释器锁(GIL)是 CPython 解释器特有的机制,也是理解 Python 多线程行为的关键。这个看似简单的互斥锁,深刻影响了 Python 并发编程的特性。
1. GIL 的本质与设计初衷
GIL 是一个全局互斥锁 ,存在于 CPython 解释器中,其核心作用是:确保同一时间只有一个线程能执行 Python 字节码。
设计 GIL 的初衷并非限制并发,而是为了简化解释器的内存管理:
- CPython 使用引用计数管理内存(每个对象记录被引用的次数,为 0 时自动回收)
- 若多个线程同时修改引用计数,可能导致计数错乱(如内存泄漏或提前释放)
- GIL 通过强制单线程执行字节码,避免了复杂的多线程内存竞争问题
2. GIL 的工作流程(附实例解析)
GIL 的运行机制可概括为 "获取 - 执行 - 释放" 的循环,具体流程如下:
- 线程启动时尝试获取 GIL
- 获取成功后执行 Python 字节码
- 满足释放条件时主动释放 GIL,让其他线程竞争
释放 GIL 的条件:
-
CPU 密集型任务:执行一定数量的字节码指令(默认约 100 条)后释放
-
I/O 密集型任务:遇到 I/O 操作(如网络请求、文件读写)时立即释放
实例:GIL 如何影响线程执行
import threading import time
def cpu_bound_task(): """CPU密集型任务:纯计算""" start = time.time() count = 0 for _ in range(10**7): count += 1 print(f"任务耗时: {time.time() - start:.2f}秒")
单线程执行
cpu_bound_task() # 输出: 任务耗时: 0.82秒
ini
# 多线程执行(两个相同任务)
t1 = threading.Thread(target=cpu_bound_task)
t2 = threading.Thread(target=cpu_bound_task)
t1.start()
t2.start()
t1.join()
t2.join() # 总耗时约1.65秒(接近单线程的2倍)现象解析 :
多线程执行 CPU 密集型任务时,总耗时接近单线程的 2 倍。因为 GIL 限制了同一时间只有一个线程执行计算,两个线程实际是 "串行执行",还额外增加了线程切换开销。
3. GIL 与线程安全的关系
GIL 保证了单个字节码指令的原子性,但多数 Python 操作需要多条字节码完成,因此仍可能出现线程安全问题。
例如,count += 1对应的字节码:
bash
LOAD_GLOBAL 0 (count) # 加载变量到栈
LOAD_CONST 1 (1) # 加载常数1
INPLACE_ADD # 执行加法
STORE_GLOBAL 0 (count) # 保存结果若线程 A 执行到INPLACE_ADD后释放 GIL,线程 B 修改了count,则线程 A 保存的结果会覆盖线程 B 的修改,导致数据错误。
解决方案 :使用threading.Lock手动保护临界区:
csharp
count = 0
lock = threading.Lock()
def safe_increment():
global count
for _ in range(10**6):
with lock: # 确保count += 1的原子性
count += 14. 突破 GIL 限制的可行方案
虽然 GIL 是 CPython 的固有特性,但可通过以下方式规避其限制:
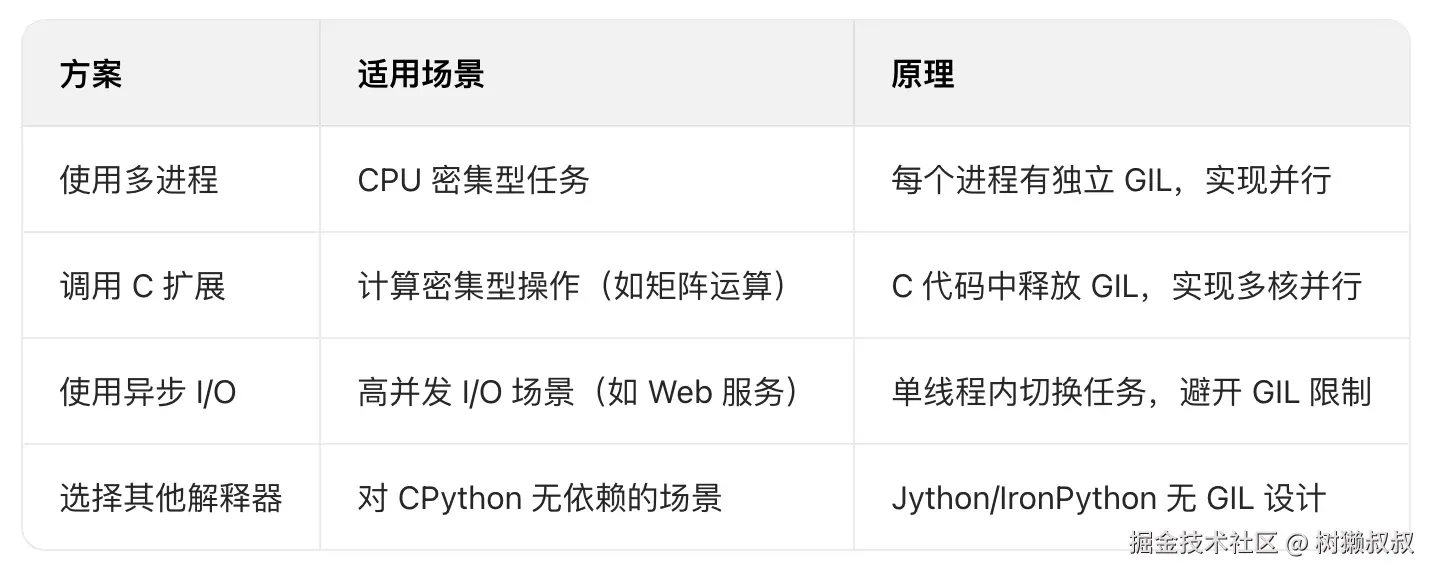
三、多线程实践:适合 I/O 密集型任务
多线程的优势体现在 I/O 密集型场景(如网络请求、文件读写、数据库操作),因为 I/O 操作时线程会释放 GIL,让其他线程得以执行。
示例 1:多线程爬取网页
python
import threading
import requests
import time
# 待爬取的URL列表
urls = [
"https://www.baidu.com",
"https://www.github.com",
"https://www.python.org",
"https://www.zhihu.com"
]
def fetch_url(url):
"""爬取单个URL内容"""
try:
response = requests.get(url, timeout=10)
print(f"URL: {url}, 状态码: {response.status_code}, 内容长度: {len(response.text)}")
except Exception as e:
print(f"URL: {url}, 错误: {str(e)}")
def single_thread():
"""单线程爬取"""
start = time.time()
for url in urls:
fetch_url(url)
print(f"单线程耗时: {time.time() - start:.2f}秒")
def multi_thread():
"""多线程爬取"""
start = time.time()
threads = []
# 创建线程
for url in urls:
t = threading.Thread(target=fetch_url, args=(url,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f"多线程耗时: {time.time() - start:.2f}秒")
if __name__ == "__main__":
single_thread()
multi_thread()运行结果(示例) :
makefile
URL: https://www.baidu.com, 状态码: 200, 内容长度: 2443
URL: https://www.github.com, 状态码: 200, 内容长度: 151107
URL: https://www.python.org, 状态码: 200, 内容长度: 50062
URL: https://www.zhihu.com, 状态码: 200, 内容长度: 19218
单线程耗时: 2.87秒
URL: https://www.baidu.com, 状态码: 200, 内容长度: 2443
URL: https://www.python.org, 状态码: 200, 内容长度: 50062
URL: https://www.github.com, 状态码: 200, 内容长度: 151107
URL: https://www.zhihu.com, 状态码: 200, 内容长度: 19218
多线程耗时: 0.93秒结论:多线程在 I/O 密集型任务中效率提升显著,总耗时接近单个任务的最长耗时(而非累加)。
四、多进程实践:适合 CPU 密集型任务
多进程通过内存隔离避开 GIL 限制,适合 CPU 密集型任务(如数学计算、数据处理),能充分利用多核 CPU。
示例 2:多进程计算质数
python
import multiprocessing
import time
import math
def is_prime(n):
"""判断一个数是否为质数"""
if n <= 1:
return False
if n == 2:
return True
if n % 2 == 0:
return False
for i in range(3, int(math.sqrt(n)) + 1, 2):
if n % i == 0:
return False
return True
def count_primes_range(start, end):
"""计算指定范围内的质数数量"""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def single_process():
"""单进程计算"""
start = time.time()
total = count_primes_range(1, 1000000)
print(f"质数总数: {total}")
print(f"单进程耗时: {time.time() - start:.2f}秒")
def multi_process():
"""多进程计算(按CPU核心数拆分任务)"""
start = time.time()
cpu_count = multiprocessing.cpu_count()
chunk_size = 1000000 // cpu_count
# 创建进程池
with multiprocessing.Pool(processes=cpu_count) as pool:
# 拆分任务
tasks = []
for i in range(cpu_count):
start_num = i * chunk_size
end_num = (i + 1) * chunk_size if i < cpu_count - 1 else 1000000
tasks.append(pool.apply_async(count_primes_range, args=(start_num, end_num)))
# 收集结果
total = 0
for task in tasks:
total += task.get()
print(f"质数总数: {total}")
print(f"多进程耗时: {time.time() - start:.2f}秒")
if __name__ == "__main__":
single_process()
multi_process()运行结果(示例,8 核 CPU) :
makefile
质数总数: 78498
单进程耗时: 12.45秒
质数总数: 78498
多进程耗时: 1.87秒结论:多进程在 CPU 密集型任务中效率提升显著,耗时约为单进程的 1/CPU 核心数(接近线性加速)。
五、线程安全与进程通信
1. 线程安全问题
多线程共享内存,可能导致数据竞争,需使用同步机制(如Lock)保护临界区:
csharp
import threading
count = 0
lock = threading.Lock() # 创建锁
def increment():
global count
for _ in range(1000000):
with lock: # 自动获取和释放锁
count += 1
# 创建两个线程
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start()
t2.start()
t1.join()
t2.join()
print(f"最终结果: {count}") # 正确输出2000000(无锁则可能小于该值)2. 进程间通信方式
多进程内存隔离,需通过特定机制通信:
Queue:安全的消息队列(推荐)Pipe:双向管道Manager:共享复杂数据结构
python
from multiprocessing import Process, Queue
def producer(q):
"""生产者:向队列放入数据"""
for i in range(5):
q.put(f"数据{i}")
print(f"生产: 数据{i}")
def consumer(q):
"""消费者:从队列获取数据"""
while True:
data = q.get()
if data is None: # 结束标志
break
print(f"消费: {data}")
if __name__ == "__main__":
q = Queue()
p1 = Process(target=producer, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
p1.join()
q.put(None) # 发送结束信号
p2.join()六、选择策略:多线程还是多进程?
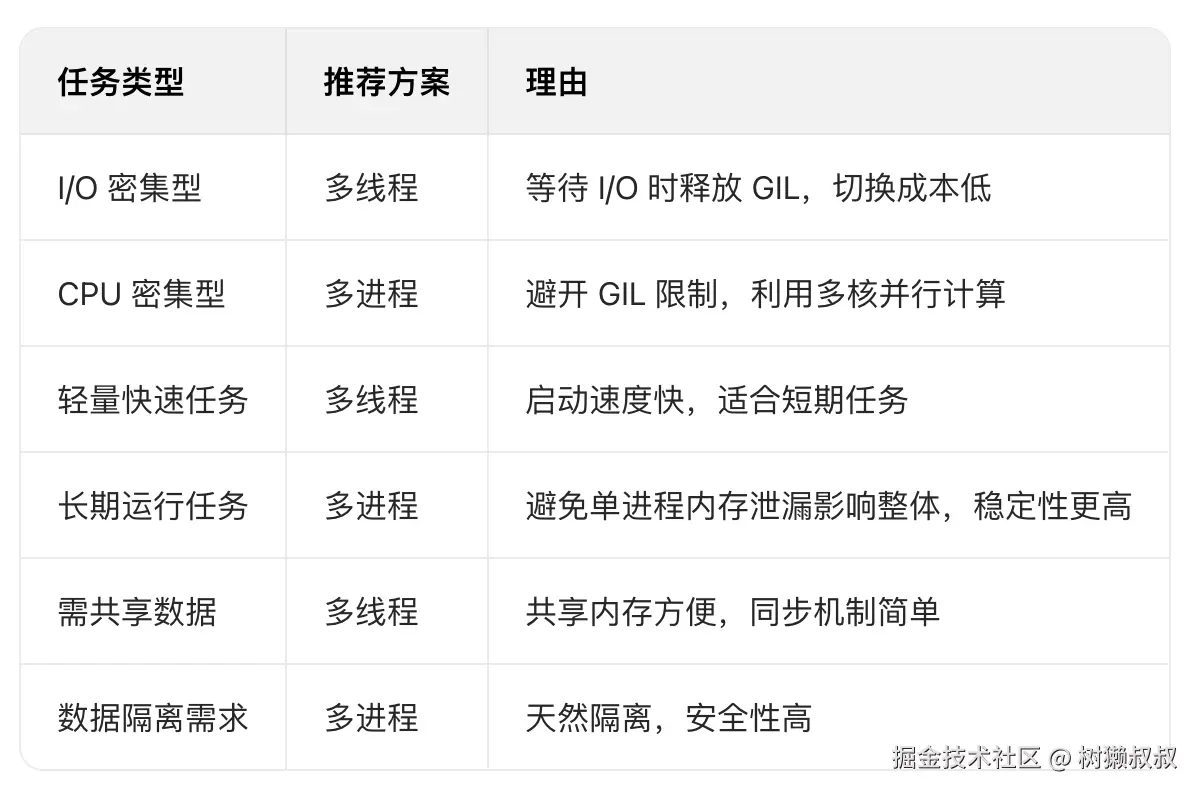
七、扩展:其他并发方案
- 异步 I/O(asyncio) :单线程内实现并发,适合高并发 I/O 场景(如 WebSocket 服务),效率优于多线程
- 线程池与进程池 :通过
concurrent.futures模块简化管理,避免频繁创建销毁的开销 - 混合方案:多进程 + 多线程组合(如每个进程内创建线程),兼顾并行与并发优势
总结
Python 的多线程与多进程并非对立关系,而是互补的并发工具:
-
多线程擅长处理 I/O 等待,通过并发提升效率
-
多进程擅长处理 CPU 计算,通过并行挖掘多核潜力
理解 GIL 的影响、内存模型的差异及适用场景,才能在实际开发中做出最优选择,构建高效稳定的并发程序。