大模型微调数据集加载和分析
1. 项目简介
loaddataset.py 是一个用于加载和分析 JSONL 格式数据集的 Python 脚本。它支持读取训练集和验证集,并对这些数据集进行基本的统计分析,包括样本数量统计和文本长度统计。
2. 主要功能
- 读取 JSONL 文件 :通过
read_jsonl函数,脚本能够读取 JSONL 格式的文件,并将其解析为 Python 列表。 - 数据集大小统计:统计训练集和验证集的样本数量,并输出总样本数。
- 文本长度统计 :计算并输出训练集和验证集中源文本(
src)和目标文本(tgt)的平均长度、最大长度和最小长度。
3. 使用说明
3.1 准备工作
- 下载数据集 wget bj.bcebos.com/paddlenlp/d...
- 解压缩数据集 tar -xf AdvertiseGen.tar.gz
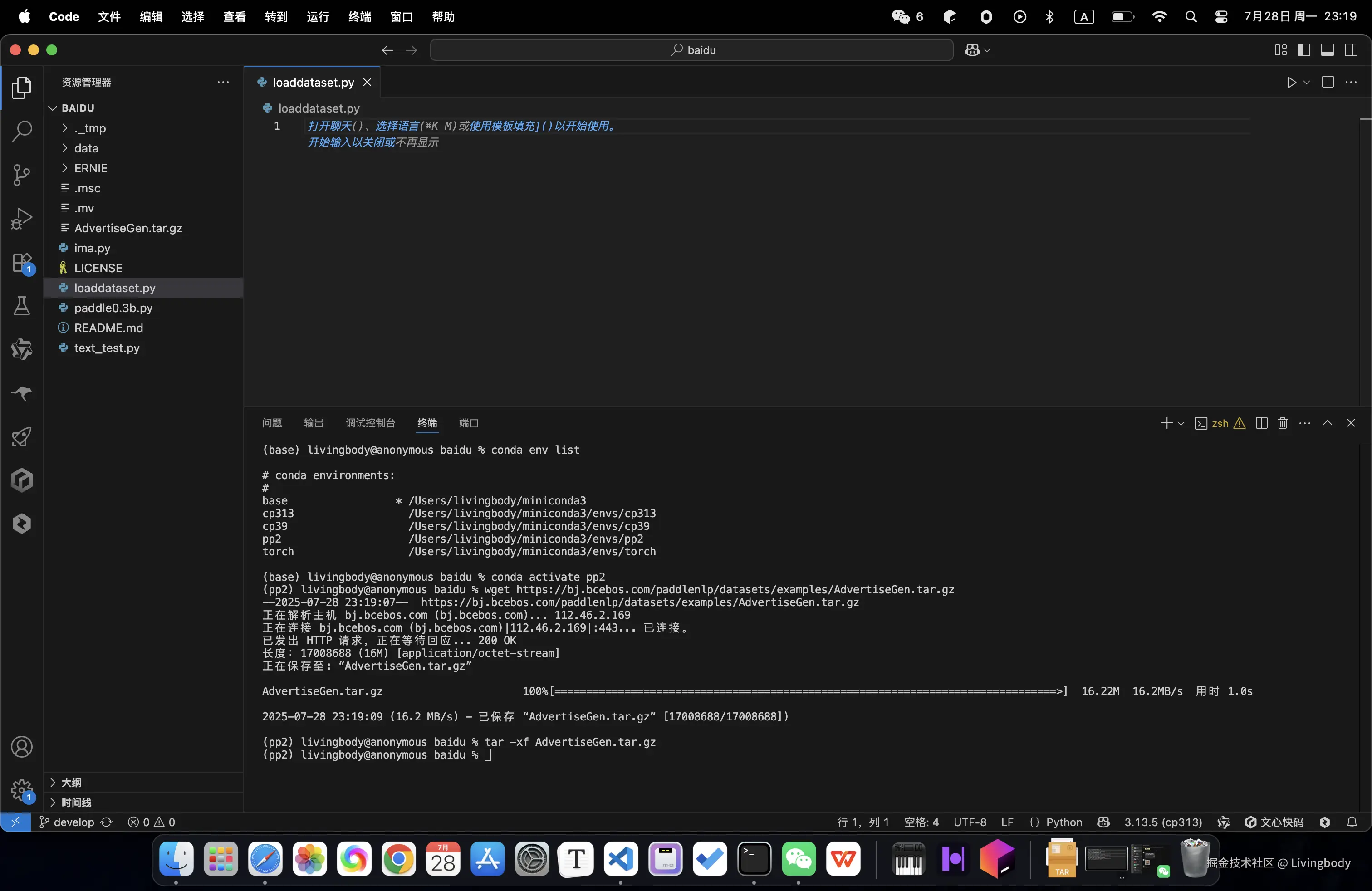 数据集中包含以下文件:
数据集中包含以下文件:
data/train.json:训练集数据文件,JSONL 格式。data/dev.json:验证集数据文件,JSONL 格式。
3.2 运行脚本
在终端或命令行中,找到 loaddataset.py 文件的目录,并运行以下命令:
python
import os
import json
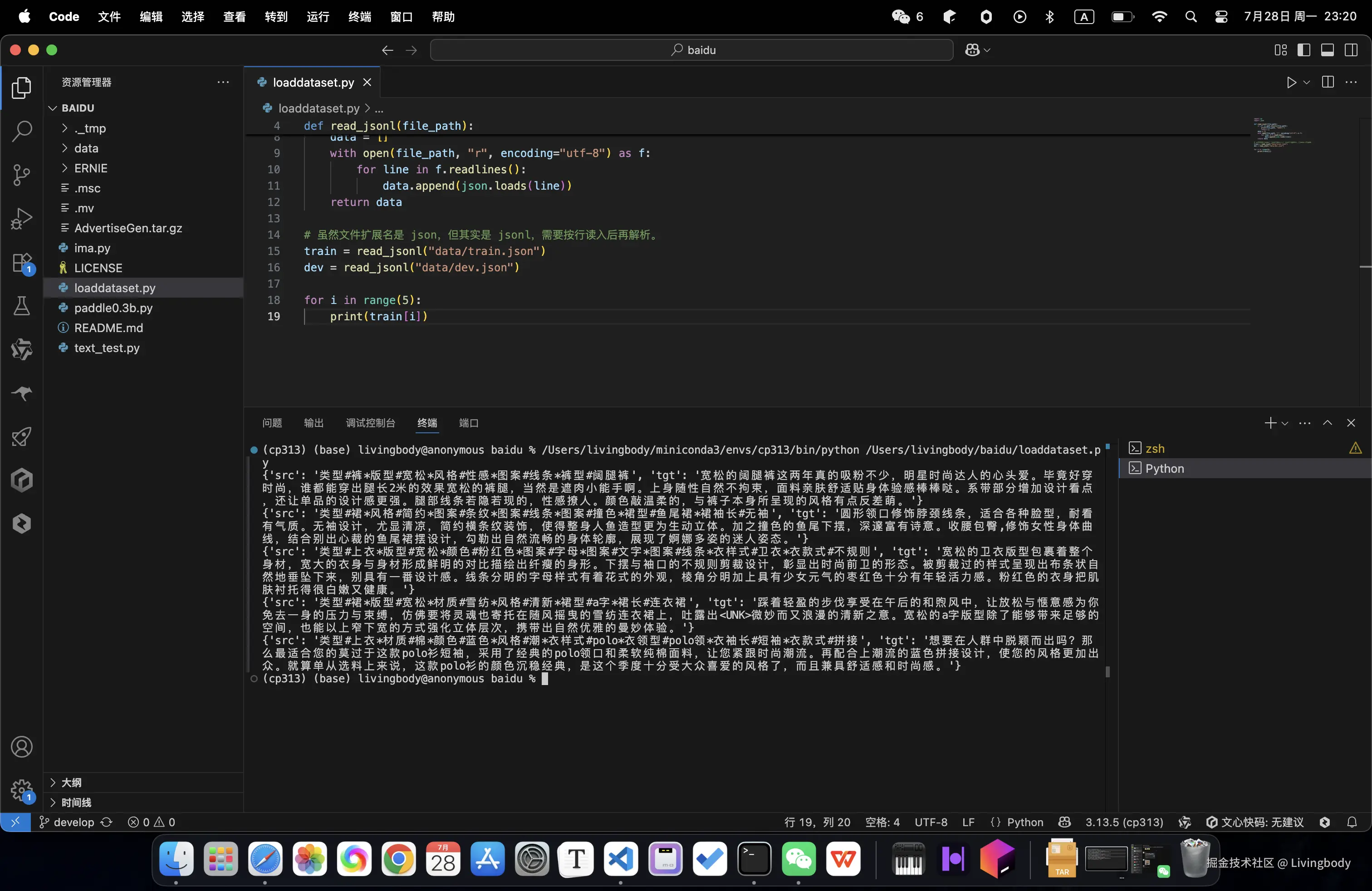
def read_jsonl(file_path):
if not os.path.exists(file_path):
print(file_path, "不存在")
return []
data = []
with open(file_path, "r", encoding="utf-8") as f:
for line in f.readlines():
data.append(json.loads(line))
return data
# 虽然文件扩展名是 json,但其实是 jsonl,需要按行读入后再解析。
train = read_jsonl("data/train.json")
dev = read_jsonl("data/dev.json")
for i in range(5):
print(train[i])
# 数据集大小统计
print(f"训练集样本数: {len(train)}")
print(f"验证集样本数: {len(dev)}")
print(f"总样本数: {len(train) + len(dev)}")
# 文本长度统计(按字符计算)
def analyze_data(data, name):
src_lens = [len(d['src']) for d in data]
tgt_lens = [len(d['tgt']) for d in data]
print(f"\n{name}数据集统计:")
print(f"• src平均长度: {sum(src_lens)/len(src_lens):.1f} 字符")
print(f"• tgt平均长度: {sum(tgt_lens)/len(tgt_lens):.1f} 字符")
print(f"• src最大长度: {max(src_lens)} 字符")
print(f"• tgt最大长度: {max(tgt_lens)} 字符")
print(f"• src最小长度: {min(src_lens)} 字符")
print(f"• tgt最小长度: {min(tgt_lens)} 字符")
# 执行统计分析
analyze_data(train, "训练集")
analyze_data(dev, "验证集")3.3 输出结果
脚本将输出以下内容:
- 训练集和验证集的前 5 个样本(以 JSON 格式)。
- 训练集和验证集的样本数量。
- 训练集和验证集的总样本数。
- 训练集和验证集中源文本和目标文本的平均长度、最大长度和最小长度。
4. 注意事项
- 确保 JSONL 文件中的每一行都是一个有效的 JSON 对象。
- 如果 JSONL 文件不存在,脚本将输出文件不存在的提示,并返回空列表。
5. 代码结构
plaintext
loaddataset.py
├── read_jsonl(file_path): 读取并解析 JSONL 文件。
├── analyze_data(data, name): 对数据集进行文本长度统计。
├── main: 加载数据集并执行统计分析。6. 依赖库
os:用于文件路径操作。json:用于解析 JSON 数据。