AST简介
在平时的开发中,经常会遇到对JavaScript代码进行检查或改动的工具,例如ESLint会检查代码中的语法错误;Prettier会修改代码的格式;打包工具会将不同文件中的代码打包在一起等等。这些工具都对JavaScript代码本身进行了解析和修改。这些工具是如何实现对代码本身的解析呢?这就要用到一种叫做AST抽象语法树的技术。
抽象语法树(Abstract Syntax Tree, 缩写为AST),是将代码抽象成一种树状结构,树上的每个节点表示代码中的一种语法,包括标识符,字面量,表达式,语句,模块等等。将代码形成抽象语法树AST之后,还可以通过这棵树还原成代码。在AST的形成过程中会丢弃注释和空白符等无意义的内容。
将代码抽象成AST需要两个步骤:1.词法分析,是扫描代码并将其中的内容标识为token数组。2.语法分析,是将词法分析的token数组转化为树状的形式,也就形成了抽象语法树。下面我们分别看一下每个步骤。
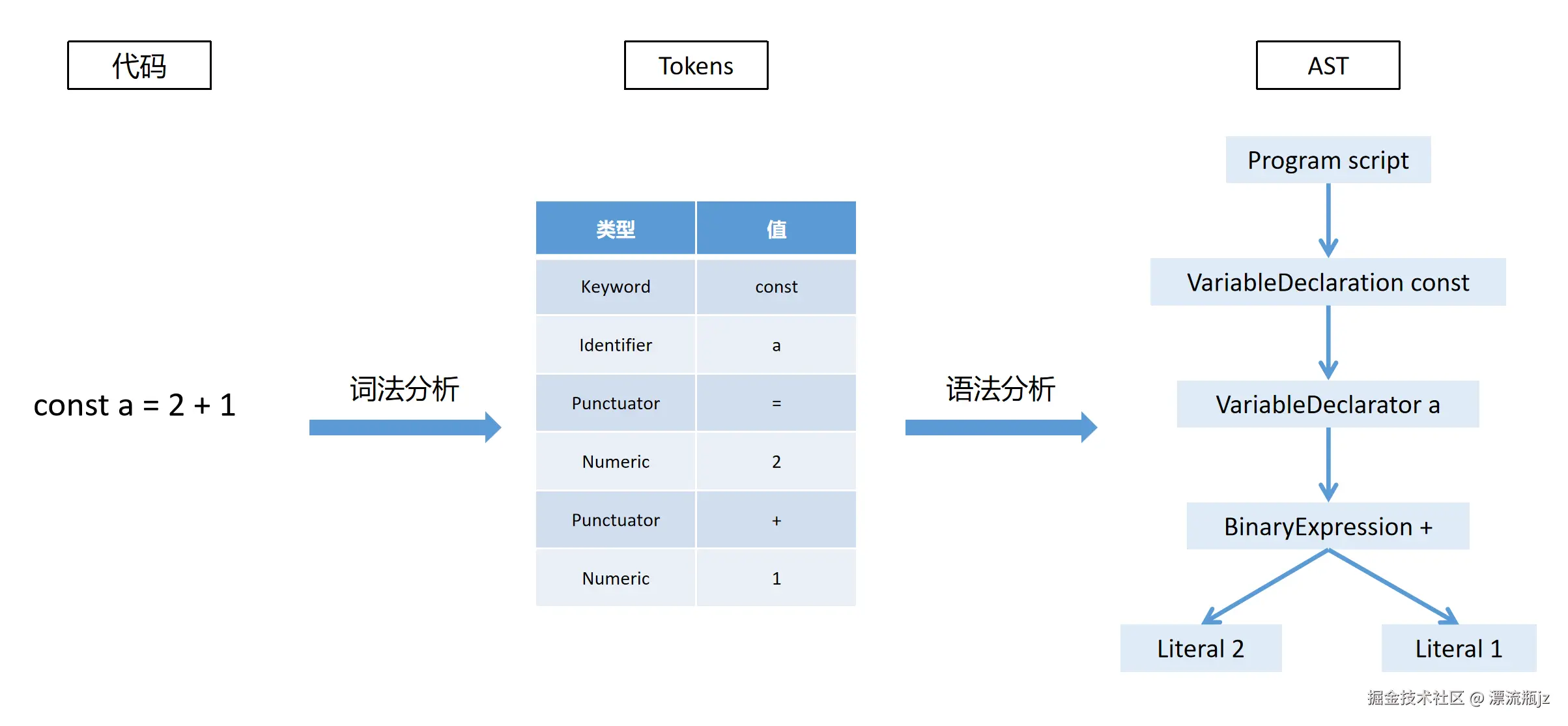
词法分析
词法分析是生成AST的第一个步骤,它将代码的内容转换为一个一个的标识token,忽略空白符号,识别标识符的类型,最终形成一个tokens数组。这里使用Esprima,一个ECMAScript解析器来生成tokens。本来想用babel,但是babel没有抛出独立生成tokens的方法。
js
const esprima = require("esprima");
const code = "const a = 2 + 1;";
const tokens = esprima.tokenize(code);
console.log(tokens);
/* 生成的tokens
[
{ type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '2' },
{ type: 'Punctuator', value: '+' },
{ type: 'Numeric', value: '1' },
{ type: 'Punctuator', value: ';' }
]
*/在Node.js中执行这段代码,命令行中就打印出了生成的tokens,放在上面的注释中了。可以看到,代码中除了空白之外,全都被生成token了,value为实际的内容,type为这个内容的类型,其中Keyword为JavaScript的关键字,Numeric为数字,Punctuator是符号,Identifier指的是标识符,例如变量名等。
我们再看一个代码中包含多行与函数的场景,与上面的代码相比,只有code不一样,因此其它代码就省略了:
js
// 准备解析的代码
const fun = function (a) {
const b = 2;
return a + b;
}
/* 生成的tokens
[
{ type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'fun' },
{ type: 'Punctuator', value: '=' },
{ type: 'Keyword', value: 'function' },
{ type: 'Punctuator', value: '(' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: ')' },
{ type: 'Punctuator', value: '{' },
{ type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'b' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '2' },
{ type: 'Punctuator', value: ';' },
{ type: 'Keyword', value: 'return' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: '+' },
{ type: 'Identifier', value: 'b' },
{ type: 'Punctuator', value: ';' },
{ type: 'Punctuator', value: '}' }
]
*/这个例子复杂很多,通过结果可以看到函数虽然作为一个整体,但是被拆分成了多个token。而且这个例子中虽然有多行,但生成的tokens是没有换行标志的。事实上对于Esprima,可以配置保留注释和以及展示每个token在源码中的位置(从而可以判断是否有换行)。更多配置可以看Esprima文档。
js
const esprima = require("esprima");
// 准备解析的代码
const code = `// 打印输出
console.log(value);`;
const tokens = esprima.tokenize(code, { loc: true, comment: true });
console.log(JSON.stringify(tokens));
/* 生成的tokens
[
{
type: "LineComment",
value: " 打印输出",
loc: { start: { line: 1, column: 0 }, end: { line: 1, column: 7 } },
},
{
type: "Identifier",
value: "console",
loc: { start: { line: 2, column: 0 }, end: { line: 2, column: 7 } },
},
{
type: "Punctuator",
value: ".",
loc: { start: { line: 2, column: 7 }, end: { line: 2, column: 8 } },
},
{
type: "Identifier",
value: "log",
loc: { start: { line: 2, column: 8 }, end: { line: 2, column: 11 } },
},
{
type: "Punctuator",
value: "(",
loc: { start: { line: 2, column: 11 }, end: { line: 2, column: 12 } },
},
{
type: "Identifier",
value: "value",
loc: { start: { line: 2, column: 12 }, end: { line: 2, column: 17 } },
},
{
type: "Punctuator",
value: ")",
loc: { start: { line: 2, column: 17 }, end: { line: 2, column: 18 } },
},
{
type: "Punctuator",
value: ";",
loc: { start: { line: 2, column: 18 }, end: { line: 2, column: 19 } },
},
];
*/可以看到结果中打印了每一个token的起始位置和最终位置,注释也保留了,使用LineComment类型。另外注意看console.log这个对象方法,在数组中被分解为了标识符+符号+标识符三个。另外这个被解析的代码我故意放了一个错误(value未定义就被使用值),但这里仅仅是识别token,代码是否可以被执行与生成tokens无关。
语法分析
词法分析结束之后,对生成tokens进一步分析,最后形成一个语法树,就是抽象语法树AST了。这里我们还是使用Esprima生成。(本想尝试利用词法分析结果来生成AST,但暂时没有找到相关的API,因此只能从代码直接生成AST了)。
js
const esprima = require("esprima");
// 准备生成的代码
const code = "const a = 2 + 1;";
const ast = esprima.parse(code);
console.log(JSON.stringify(ast));
/* 生成的AST
{
type: "Program",
body: [
{
type: "VariableDeclaration",
declarations: [
{
type: "VariableDeclarator",
id: { type: "Identifier", name: "a" },
init: {
type: "BinaryExpression",
operator: "+",
left: { type: "Literal", value: 2, raw: "2" },
right: { type: "Literal", value: 1, raw: "1" },
},
},
],
kind: "const",
},
],
sourceType: "script",
}
*/可以看到代码被解析成了一个JSON结构,这个JSON结构即描述了代码本身。我们从外向内试着分析一下这个结构:
- Program 表示一个程序
- VariableDeclaration 表示变量声明,kind表示了是const
- VariableDeclarator 表示变量声明的标识符,是名称为a的Identifier标识符
- BinaryExpression 二元运算符表达式,其中操作符是+号
- Literal 加号的左右都是字面量,值为数字1和2
因此,一段代码就被分析成了这样一颗AST树。这里我们再看一个例子:
js
// 准备解析的代码
const fun = function (a) {
const b = 2;
return a + b;
}
/* 生成的AST
{
type: "Program",
body: [
{
type: "VariableDeclaration",
declarations: [
{
type: "VariableDeclarator",
id: { type: "Identifier", name: "fun" },
init: {
type: "FunctionExpression",
id: null,
params: [{ type: "Identifier", name: "a" }],
body: {
type: "BlockStatement",
body: [
{
type: "VariableDeclaration",
declarations: [
{
type: "VariableDeclarator",
id: { type: "Identifier", name: "b" },
init: { type: "Literal", value: 2, raw: "2" },
},
],
kind: "const",
},
{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "+",
left: { type: "Identifier", name: "a" },
right: { type: "Identifier", name: "b" },
},
},
],
},
generator: false,
expression: false,
async: false,
},
},
],
kind: "const",
},
],
sourceType: "script",
}
*/这个例子增加了FunctionExpression,表示函数;BlockStatement表示块级语句;ReturnStatement表示return语句等。与前面词法分析将函数拆分成多个token不一样,这次函数是一个整体,且内部包含了params,BlockStatement和ReturnStatement等,确实是做到了对语法本身的分析。
与tokenize方法一样,语法分析的parse方法也有很多选项,例如解析注释,列出在代码中的位置等等,这里就不描述了。除了通过代码之外,还有AST explorer网站可以将代码在线转换为AST,并且可以在线标黄AST结点对应的代码。
抽象语法树规范ESTree
前面生成的AST树的结构中,我们看到了很多AST结点,这些节点有type表示结点类型,以及其他属性。Javascript有这么多语法规则,而且在不停的更新,如何知道这些语法规则的类型和属性定义呢?
ESTree就提供了Javascript语法到AST结点的属性定义的规则。ESTree并不是AST转换工具,它是一份文档,提供了ECMAScript标准中的语法到AST结点定义的规则。生成AST的工具,需要遵守这个规则,这样不同工具生成的抽象语法树就是通用的,我们也只需要写一套代码来解析即可。ESTree维护在GitHub,通过查看ESTree的目录结构和规则示例,可以看到不仅包含了每年的最新语法,甚至还包含了一些还在stage中的语法。
js
// 目录结构(部分)
├── experimental/
├── extensions/
├── stage3/
├── deprecated.md
├── es2015.md
├── es2016.md
├── es2017.md
├── es2018.md
├── es2019.md
├── es2020.md
├── es2021.md
├── es2022.md
├── es2025.md
├── es2026.md
├── es5.md
└── ...
// 规则实例
interface Function <: Node {
id: Identifier | null;
params: [ Pattern ];
body: FunctionBody;
}
A function declaration or expression.ESTree最早是由Mozilla工程师在开发Javascript引擎SpiderMonkey时定义的,后来被大家接受并形成了事实的标准,现在由Babel,ESlint和Acorn维护。ESTree并不是一个强制规则,因此也有部分AST转换工具没有使用这个标准。下面的工具介绍中会提到这一点。
AST工具列表
首先列举一下目前社区中流行的AST生成工具,以及它们是否支持ESTree和输出Tokens。
| 工具名称 | 支持ESTree | 支持输出Tokens | 简介 |
|---|---|---|---|
| Esprima | 是 | 是 | 很早的AST工具,支持最新语法的进度较慢 |
| Acorn | 是 | 是 | 流行的AST工具,支持插件 |
| Espree | 是 | 是 | ESLint(JS语法检查工具)的AST工具,最初基于Esprima开发,后来基于Acorn |
| @babel/parser | 是 | 否 | Babel(JS编译器)的AST工具,fork于Acorn |
| UglifyJS | 否 | 否 | UglifyJS(JS压缩工具)中提供的AST工具,独立格式不支持ESTree |
其中Esprima是非常早的AST工具,也很好用,但由于ES6开始,ECMAScript标准中语法的数量增多速度变快,导致Esprima无法即使更新,因此出现了更多AST生成工具。其中Acorn是流行的工具之一,具有插件机制,现在很多JavaScript工具都采用了Acorn或者在它的基础上继续开发。下面我们简单列举下这些工具的代码使用方式示例:
js
/*
code 被解析的代码
tokens 词法分析结果
ast 生成的抽象语法树
*/
const code = "const a = 2 + 1;";
// --- Esprima ---
const esprima = require("esprima");
const tokens = esprima.tokenize(code);
const ast = esprima.parse(code);
// --- Acorn ---
const acorn = require("acorn");
// it是个js遍历器
const it = acorn.tokenizer(code);
const tokens = [...it];
const ast = acorn.parse(code, { ecmaVersion: "latest" });
// --- Espree ---
const espree = require("espree");
const tokens = espree.tokenize(code);
const ast = espree.parse(code, { ecmaVersion: "latest" });
// --- @babel/parser ---
const babelParser = require("@babel/parser");
const ast = babelParser.parse(code);
// --- UglifyJS ---
const UglifyJS = require("uglify-js");
const ast = UglifyJS.minify(code, {
parse: {}, compress: false, mangle: false,
output: { ast: true, code: false }
});通过代码示例可以看到,虽然API细节个别有区别,但使用方式是基本一致的。还有一些社区工具虽然有解析AST的能力,但却没有抛出API,比如Terser;还有一些工具是直接集成了上面的工具作为解析AST的方法,例如recast。这些工具我们就不在表格中列出了。
AST的应用Demo
AST在Javascript的工具中应用非常广泛:代码编译构建,混淆压缩,语法高亮,错误检查,格式修改,ES版本兼容等等,应用实在是太多了。可以说在前端工程化领域中绝大部分工具都需要AST的能力。但其中大部分工具都不仅只是生成语法树,它们还会对AST进行修改,最后再生成代码。我们再用一个流程图来表示:
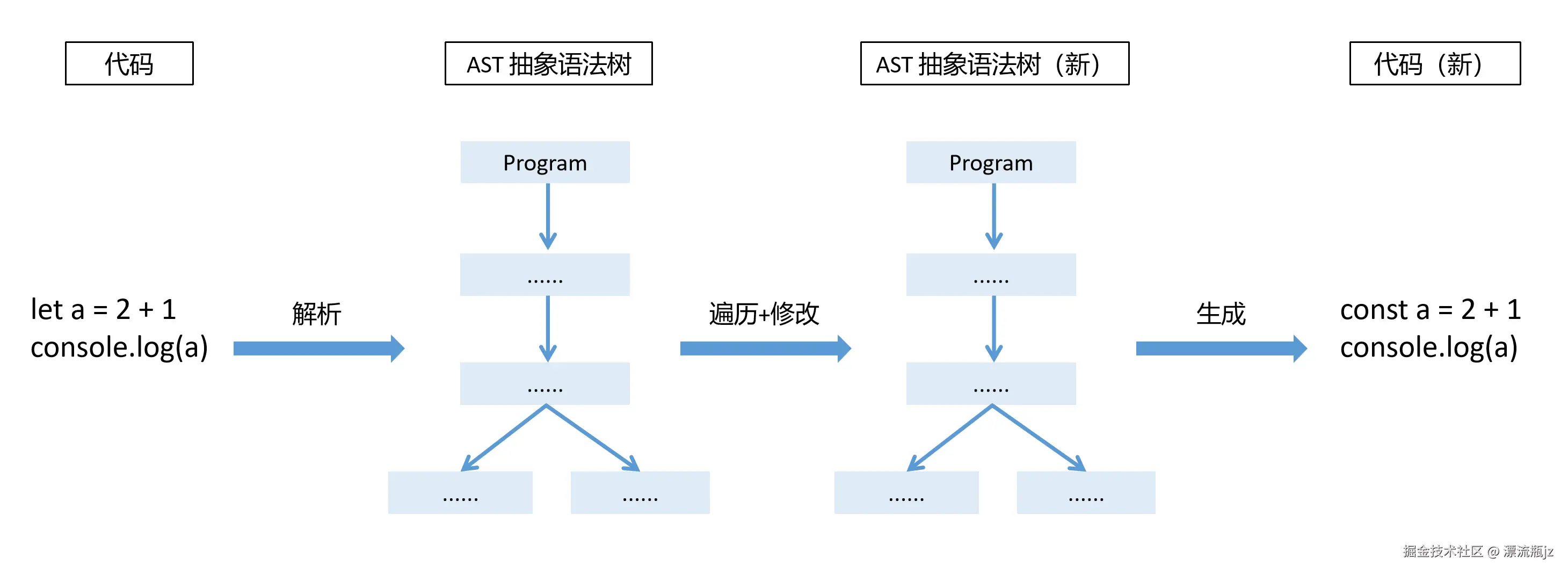
从图中可以看到,大部分工具利用AST的方式是,先把代码生成AST,然后再对AST进行遍历和修改,生成一颗新的AST。最后将AST生成代码作为输出结果。这里我们尝试一个最简单的例子,其中遍历AST使用的是Estraverse,从AST生成代码使用的是Escodegen。
js
const esprima = require("esprima");
const estraverse = require("estraverse");
const escodegen = require("escodegen");
const code = `
let fun = function (letter) {
let b = 2;
console.log(" let letter");
return b + letter;
};
`;
// 生成AST
const ast = esprima.parse(code);
// 遍历
estraverse.traverse(ast, {
enter: (node) => {
if (node.type === "VariableDeclaration" && node.kind === 'let') {
// 修改AST
node.kind = "const";
}
},
});
// 生成新代码
const newCode = escodegen.generate(ast);
console.log(newCode);
/* 生成结果
const fun = function (letter) {
const b = 2;
console.log(' let letter');
return b + letter;
};
*/上面代码的作用是,将输入代码中的let变量声明修改为const。这仅仅是个最简单的Demo,没有考虑变量存在修改不能使用const的场景。有些人可能对于AST的作用有疑惑,认为对代码为用字符串替换或者正则的方式也能实现。但当代码内容复杂时,例如变量名和字符串常量中都可能包含let,这时使用常规的正则方式难度是比较高的。
CST具体语法树
前面我们介绍的都是AST抽象语法树,它是忽略注释,分号等无意义内容之后的组成的一颗树。那么有没有一种语法树可以保留这些内容呢?有的,它就是具体语法树CST(Concrete Syntax Tree)。具体语法树是代码的完整表示,在代码高亮,代码格式化等方面非常有用。这里我们使用Tree-sitter工具,尝试对代码生成具体语法树。
js
const Parser = require('tree-sitter');
const JavaScript = require('tree-sitter-javascript');
const parser = new Parser();
parser.setLanguage(JavaScript);
const sourceCode = 'let x = 2;';
const tree = parser.parse(sourceCode);
console.log(tree.rootNode.toString());
console.log(tree.rootNode.children[0].toString());
console.log(tree.rootNode.children[0].children);
console.log(tree.rootNode.children[0].children[1].toString());
console.log(tree.rootNode.children[0].children[1]);
/* 输出
(program (lexical_declaration (variable_declarator name: (identifier) value: (number))))
(lexical_declaration (variable_declarator name: (identifier) value: (number)))
[
SyntaxNode {
type: let,
startPosition: {row: 0, column: 0},
endPosition: {row: 0, column: 3},
childCount: 0,
},
VariableDeclaratorNode {
type: variable_declarator,
startPosition: {row: 0, column: 4},
endPosition: {row: 0, column: 9},
childCount: 3,
},
SyntaxNode {
type: ;,
startPosition: {row: 0, column: 9},
endPosition: {row: 0, column: 10},
childCount: 0,
}
]
(variable_declarator name: (identifier) value: (number))
VariableDeclaratorNode {
type: variable_declarator,
startPosition: {row: 0, column: 4},
endPosition: {row: 0, column: 9},
childCount: 3,
}
*/Tree-sitter本身是用C语言编写的,但提供了JavaScript语言的npm包供使用。同时它也支持解析多种语言,不同的语言引入不同的解析器即可。Tree-sitter并不使用ESTree作为解析格式,而是使用S表达式,如我们输出的第一行tree.rootNode.toString()。S表达式(S-Expression)类似于前缀表达式,在Lisp语言中使用较多。这里举一个简单的例子:
- 原表达式: 1 * (2 + 3)
- S表达式: (* 1 (+ 2 3))
从例子中可以简单理解为,在中间的操作符需要提到最前面。然后我们再来看输出的第一行,其中每个节点的含义如下:
- program 程序根节点
- lexical_declaration 声明语句
- variable_declarator 声明器
- name(identifier) 变量名
- value:(number) 数字值
然后将它们组合起来:
- (program (lexical_declaration (variable_declarator name: (identifier) value: (number))))
- (程序根节点 (声明语句 (声明器 变量名 数字值)))
详细含义和解析方法可以查看Tree-sitter文档。不过细心看虽然用了S表达式的形式,但这依然是一颗AST而不是CST,因为树中并没有分号等无意义符号。我们仔细看输出的子节点中,发现了分号的存在,这一类无意义结点被称作匿名节点,在S表达式中并不会展示,但是遍历子节点时,是可以遍历到的。另外Tree-sitter也能解析存在错误的语法:
js
const sourceCode = 'let x = 2qwe;';
/*
(program (lexical_declaration (variable_declarator name: (identifier) (ERROR (number)) value: (identifier))))
*/在代码有错误的情况下,依然生成了S表达式,且表达式中可以看到ERROR结点。这种能力对语法错误提示等功能有帮助。
总结
这篇文章仅仅是对语法树(AST CST)做了一个简单的介绍,并没有对原理和细节做深入的了解。事实上,解析与生成代码是计算机学科中一个专门的领域,也是一门大学的课程,叫做编译原理。像是龙书《编译原理》中就有讲到词法分析,语法分析,语法树生成等等,其中的复杂程度远远超过了一篇博客的内容。
对于语法树的生成工具来说,AST和CST的界限也并不是完全区分的(一般默认是AST模式),很多工具就可以在语法树中保留注释等无意义内容,有些也可以解析包含错误的代码。具体用AST还是CST还是自定义的树,要看使用场景。
前端除了JavaScript之外,还有JSX代码,TS代码,CSS代码等等,都有工具可以做到解析语法树。
有一个前端非常常用的编译器,叫做babel,包含了很多编译相关的工具。关于babel相关的内容,会在后面单独文章介绍。同时也将会尝试关于AST更复杂一点的应用。
参考
- AST 抽象语法树知识点
mp.weixin.qq.com/s/KaIaCjRGC... - CST vs AST 以及 biome 和 Oxc 各自的选择理由
juejin.cn/post/750416... - Babel文档
babeljs.io/ - 前端工程化基石 -- AST(抽象语法树)以及AST的广泛应用
juejin.cn/post/715515... - Esprima 文档
esprima.org/ - 快来享受AST转换的乐趣
zhuanlan.zhihu.com/p/617125984 - ESTree Github
github.com/estree/estr... - AST explorer JavaScript代码在线转换为AST语法树 astexplorer.net/
- 【转译器原理 parser 篇】实现 js 新语法并编译到 css
juejin.cn/post/695950... - JS AST 原理揭秘
zhaomenghuan.js.org/blog/js-ast... - Acorn Github
github.com/acornjs/aco... - Espree Github
github.com/eslint/js/t... - UglifyJS Github
github.com/mishoo/Ugli... - UglifyJS --- why not switching to SpiderMonkey AST
lisperator.net/blog/uglify... - Terser Github
github.com/terser/ters... - Estraverse Github
github.com/estools/est... - Escodegen Github
github.com/estools/esc... - Tree-sitter 文档
tree-sitter.github.io/tree-sitter... - Node Tree-sitter 文档
tree-sitter.github.io/node-tree-s... - 利用 Tree-sitter 进行语法树分析
juejin.cn/post/740727...