对于没有特征或者说需要寻找另类关系的数据集,我们通常会用聚合或KNN近邻的方法来分类,但这样的分类或许在结果上是好的,但是解释性并不好,有时候我们甚至能看到好的结果反直觉;而决策树回归做出的结果,由于其树的结构,我们能看到每一步的决策,也就能推测出树这么做的原因,还能进一步地调整树的深度,使得结果更好。
以下是一个例子:
# 加载必要的包
library(rpart) # 决策树
library(rpart.plot) # 可视化树
# 1. 生成模拟数据集(非线性关系)
set.seed(123)
n <- 200
x <- runif(n, 0, 10) # 特征x:0到10的随机数
y <- sin(x) + rnorm(n, 0, 0.3) # 目标y:sin(x)加噪声
data <- data.frame(x, y)
# 2. 划分训练集和测试集
train_idx <- sample(1:n, 0.7 * n)
train_data <- data[train_idx, ]
test_data <- data[-train_idx, ]
# 3. 训练决策树回归模型
tree_model <- rpart(y ~ x, data = train_data,
method = "anova", # 回归任务
control = rpart.control(maxdepth = 3)) # 限制树深度
# 4. 可视化树结构
rpart.plot(tree_model, main = "决策树回归")
# 5. 预测并计算误差
predictions <- predict(tree_model, test_data)
mse <- mean((predictions - test_data$y)^2)
cat("测试集均方误差(MSE):", round(mse, 3), "\n")
# 6. 绘制真实值与预测值对比
plot(test_data$x, test_data$y, col = "blue", pch = 19,
main = "真实值 vs 预测值", xlab = "x", ylab = "y")
points(test_data$x, predictions, col = "red", pch = 4)
legend("topright", legend = c("真实值", "预测值"), col = c("blue", "red"), pch = c(19, 4))输出:
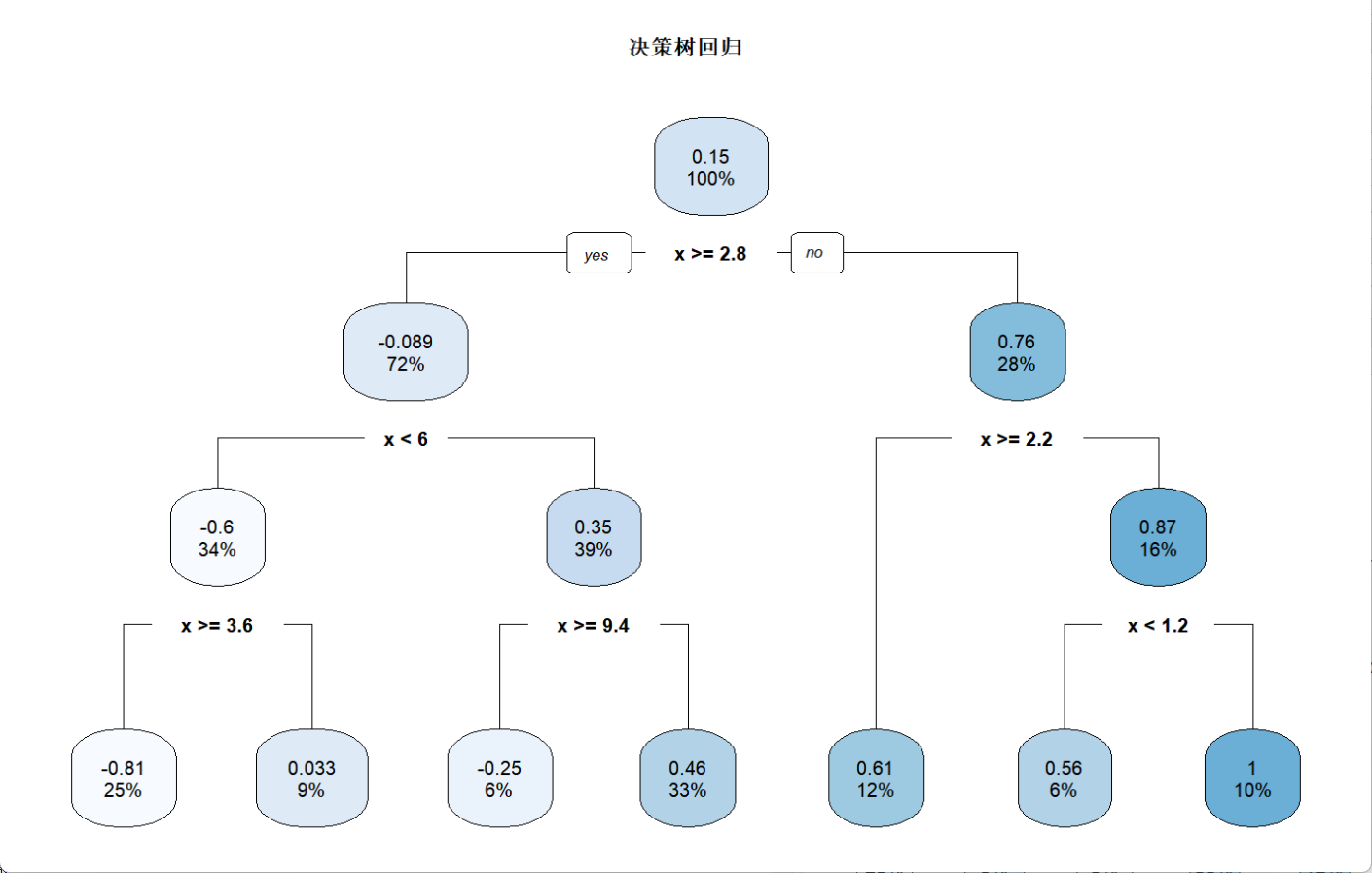
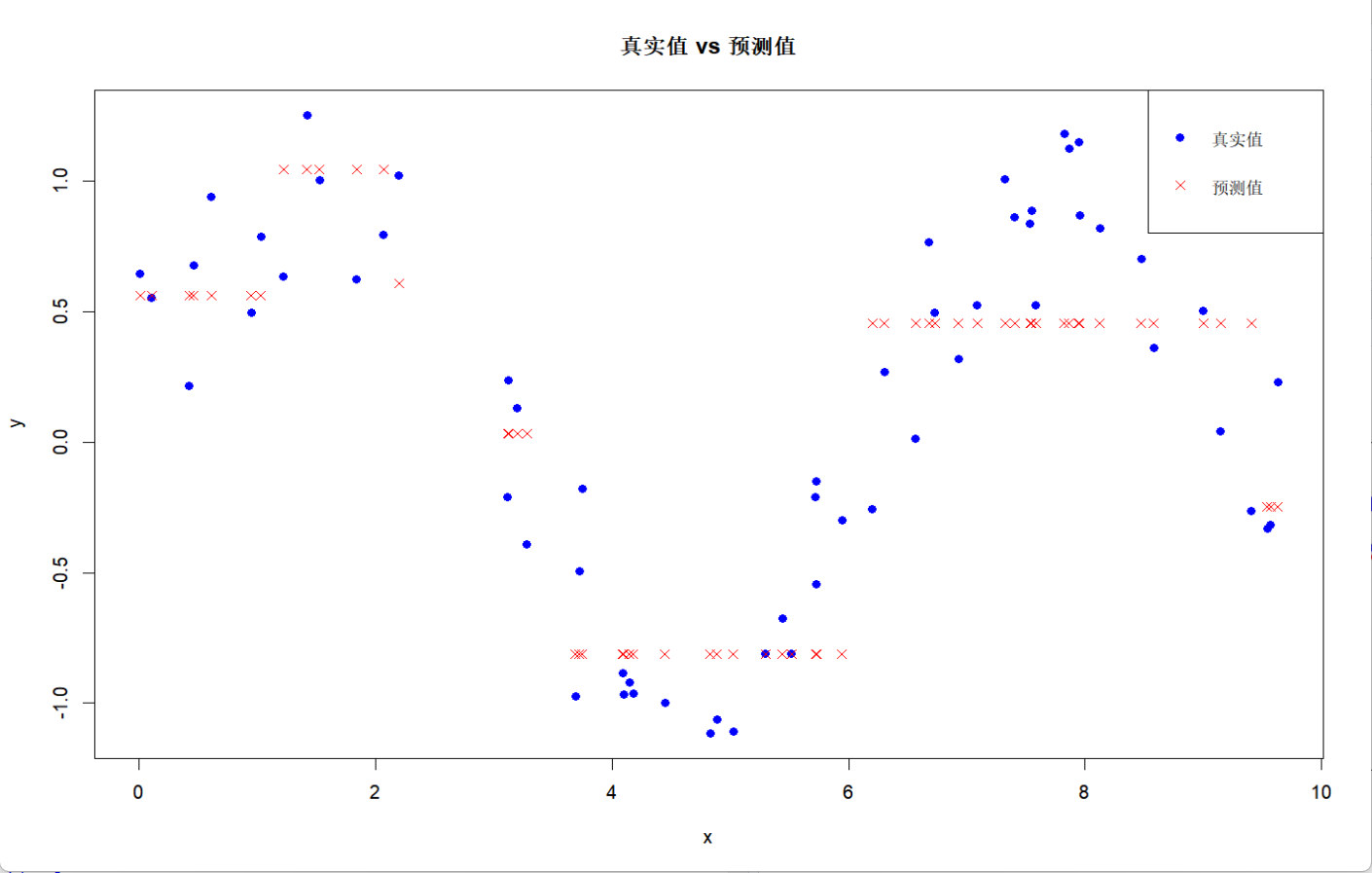
可以看到图中的决策树对于每一步的分支,都能看到分离之后两边的方差变化;而分布图则表明决策树对于波动较大的数据分布很难捕捉到趋势,很容易出现欠拟合的现象,但是由于其可以根据结果反推进一步调参,反而能加深其结果的解释性。