点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到: Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- 消费者的基本流程
- 消费者的参数、参数补充

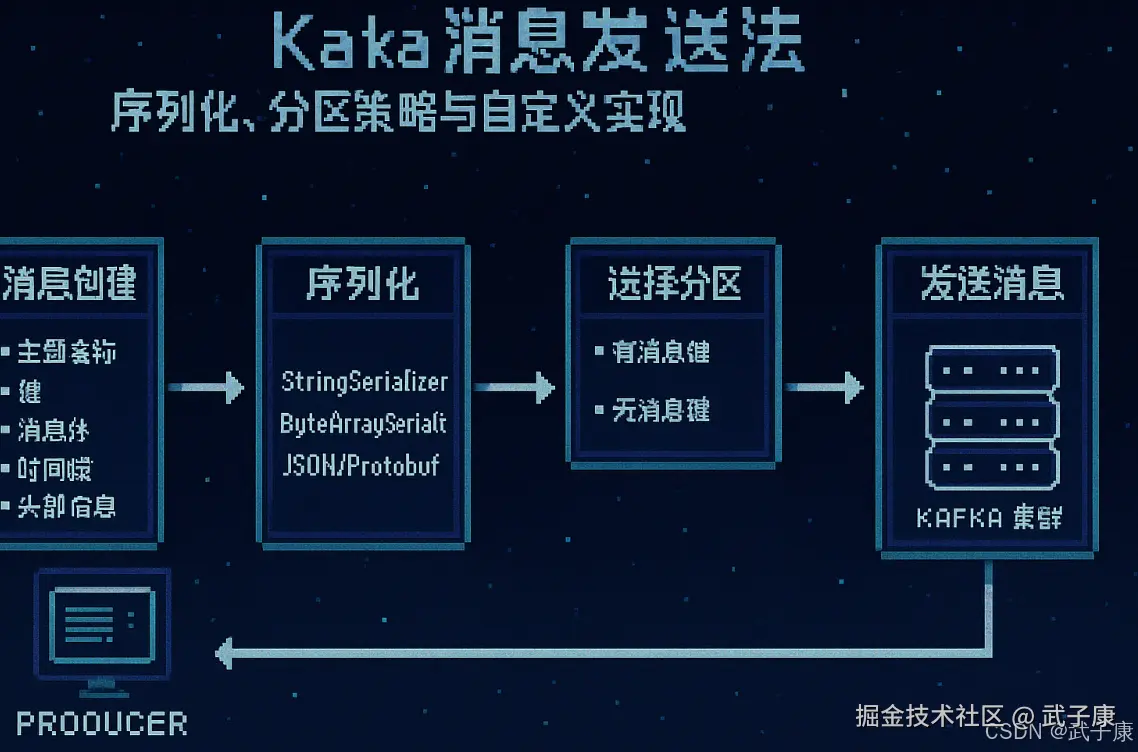
Kafka 消息发送(Message Production)
在 Kafka 中,消息发送是指生产者将数据写入 Kafka 主题的过程。生产者是负责创建和发送消息的客户端应用,它们将数据转换为 Kafka 可识别的格式并发送到指定的主题中。
消息发送的过程
-
消息创建:生产者(Producer)首先需要构造一条完整的Kafka消息。这条消息包含以下关键组成部分:
- 主题名称:指定消息要发往的Kafka主题(Topic),这是消息的分类标识
- 键(可选):消息键(Key)用于控制消息的分区路由策略。如果没有指定键,消息将采用轮询方式分配到各个分区
- 消息体:实际的业务数据内容,可以是JSON、XML、Protobuf等任意格式的负载数据
- 时间戳(可选):消息创建时间或事件发生时间
- 头部信息(可选):附加的键值对元数据
-
序列化:在发送前需要将消息转换为Kafka可处理的格式:
- 键和消息体都需要经过序列化器(Serializer)处理
- 常见的序列化方式包括:
- StringSerializer:字符串序列化
- ByteArraySerializer:字节数组序列化
- JSON/Protobuf/AVRO等格式序列化
- 序列化过程将数据转换为字节数组(byte\[\])格式,这是Kafka底层存储的基本单位
-
选择分区:消息路由的关键步骤:
- 如果有指定消息键:
- 默认使用哈希算法(如murmur2)计算键的哈希值
- 根据哈希值对分区数取模,确定目标分区
- 确保相同键的消息始终路由到同一分区,保证顺序性
- 如果没有消息键:
- 采用轮询(Round-Robin)方式均衡分配到各分区
- 支持自定义分区器(Partitioner)实现特殊路由逻辑
- 如果有指定消息键:
-
发送消息:消息传输的核心过程:
- 生产者将消息放入发送缓冲区
- 单独的Sender线程从缓冲区获取消息
- 通过TCP连接将消息批量发送到Kafka集群
- Broker接收到消息后:
- 验证消息有效性
- 将消息追加到对应分区的日志段(Log Segment)文件
- 根据配置的副本因子(Replication Factor)同步到其他副本Broker
- 更新分区的HW(High Watermark)和LEO(Log End Offset)
- 生产者根据配置的acks参数等待确认:
- acks=0:不等待确认(可能丢失消息)
- acks=1:等待leader确认
- acks=all:等待所有ISR副本确认
发送消息的配置参数
- acks:定义生产者需要等待多少个副本确认消息已经收到,才认为消息发送成功。常见的值包括 0(不等待)、1(等待 Leader 确认)、all(等待所有副本确认)。
- retries:当消息发送失败时,生产者重试的次数。
- batch.size:生产者在发送消息前积累的消息批次大小。批次越大,吞吐量越高,但也会增加延迟。
自定义序列化器(Custom Serializer)
在 Kafka 中,生产者发送的消息需要先经过序列化处理。Kafka 提供了默认的序列化器(如 StringSerializer、ByteArraySerializer 等),但在某些情况下,可能需要自定义序列化器以支持特定的数据格式或优化性能。
什么是序列化器
- 序列化器的作用:序列化器将生产者的消息对象(如字符串、Java 对象等)转换为字节数组,以便 Kafka 能够存储和传输数据。
- Kafka 的默认序列化器:Kafka 提供了多种默认序列化器来处理常见的数据类型,如字符串、整数和字节数组。
自定义序列化器的场景
- 复杂数据结构:当你的消息是复杂的对象结构(如嵌套的 JSON 对象、ProtoBuf 等),默认的序列化器可能无法满足需求。这时可以编写自定义序列化器,来处理这些复杂的结构。
- 性能优化:在一些高性能场景下,默认的序列化器可能无法满足低延迟、高吞吐量的需求。通过定制化的序列化器,可以优化序列化过程的效率。
自定义分区器(Custom Partitioner)
在 Kafka 中,分区器决定了消息被发送到哪个分区。Kafka 提供了默认的分区器(通常基于消息的键进行哈希计算),但在一些场景下,你可能希望自定义分区逻辑,以实现特定的消息分布策略。
分区器的作用
- 控制消息的分区:分区器的主要作用是根据消息的键或其他属性来确定消息应该发送到哪个分区。默认情况下,Kafka 使用键的哈希值来确定分区。
- 分区的意义:通过合理分配分区,可以实现消息的负载均衡、提高系统的并行处理能力,并确保相同键的消息总是被发送到同一个分区。
自定义分区器的场景
- 定制化的消息分布:在某些场景下,可能需要根据业务逻辑将消息定向到特定的分区。例如,按照用户 ID 分区、按照消息类型分区等。
- 特殊的分区需求:某些情况下,你可能希望确保某些分区具有更高的优先级或更大的存储能力,这时可以使用自定义分区器来实现这些需求。
序列化器
由于Kafka中的数据都是字节数组,在将消息发送到Kafka之前需要将数据序列化成为字节数组。 序列化器作用就是用于序列化要发送的消息的。
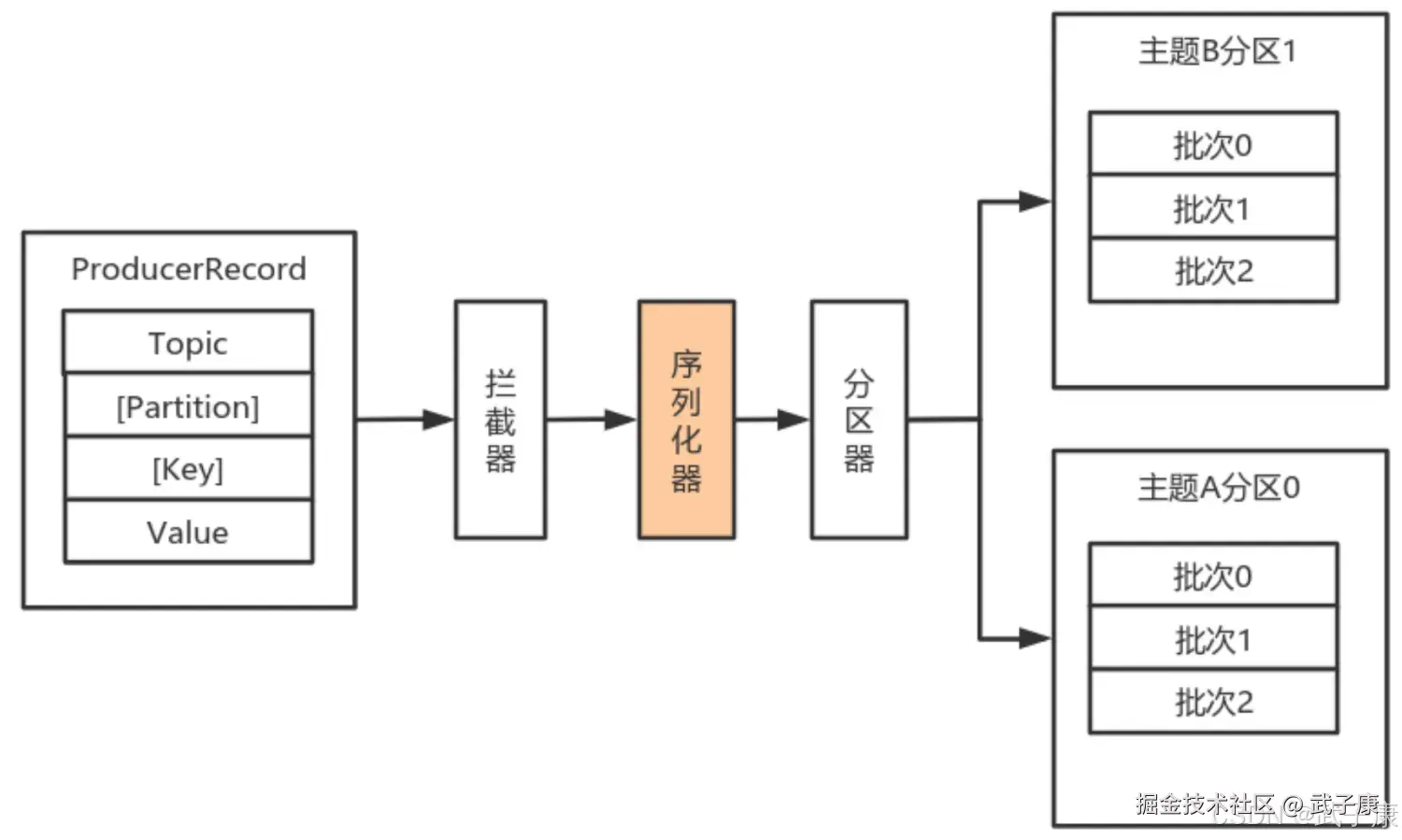 Kafka通过 org.apache.kafka.common.serialization.Serializer 接口用于定义序列化器,将泛型指定类型的数据转换为字节数据。
Kafka通过 org.apache.kafka.common.serialization.Serializer 接口用于定义序列化器,将泛型指定类型的数据转换为字节数据。
java
public interface Serializer<T> extends Closeable {
/**
* Configure this class.
* @param configs configs in key/value pairs
* @param isKey whether is for key or value
*/
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
/**
* Convert {@code data} into a byte array.
*
* @param topic topic associated with data
* @param data typed data
* @return serialized bytes
*/
byte[] serialize(String topic, T data);
/**
* Convert {@code data} into a byte array.
*
* @param topic topic associated with data
* @param headers headers associated with the record
* @param data typed data
* @return serialized bytes
*/
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
/**
* Close this serializer.
* <p>
* This method must be idempotent as it may be called multiple times.
*/
@Override
default void close() {
// intentionally left blank
}
}其中Kafka也内置了一些实现好的序列化器:
- ByteArraySerializer
- StringSerializer
- DoubleSerializer
- 等等... 具体可以自行查看
自定义序列化器
自定义实体类
实现一个简单的类:
java
public class User {
private String username;
private String password;
private Integer age;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}实现序列化
注意对象中的内容转换为字节数组的过程,要计算好开启的空间!!!
java
public class UserSerilazer implements Serializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
Serializer.super.configure(configs, isKey);
}
@Override
public byte[] serialize(String topic, User data) {
if (null == data) {
return null;
}
int userId = data.getUserId();
String username = data.getUsername();
String password = data.getPassword();
int age = data.getAge();
int usernameLen = 0;
byte[] usernameBytes;
if (null != username) {
usernameBytes = username.getBytes(StandardCharsets.UTF_8);
usernameLen = usernameBytes.length;
} else {
usernameBytes = new byte[0];
}
int passwordLen = 0;
byte[] passwordBytes;
if (null != password) {
passwordBytes = password.getBytes(StandardCharsets.UTF_8);
passwordLen = passwordBytes.length;
} else {
passwordBytes = new byte[0];
}
ByteBuffer byteBuffer = ByteBuffer.allocate(4 + 4 + usernameLen + 4 + passwordLen + 4);
byteBuffer.putInt(userId);
byteBuffer.putInt(usernameLen);
byteBuffer.put(usernameBytes);
byteBuffer.putInt(passwordLen);
byteBuffer.put(passwordBytes);
byteBuffer.putInt(age);
return byteBuffer.array();
}
@Override
public byte[] serialize(String topic, Headers headers, User data) {
return Serializer.super.serialize(topic, headers, data);
}
@Override
public void close() {
Serializer.super.close();
}
}分区器
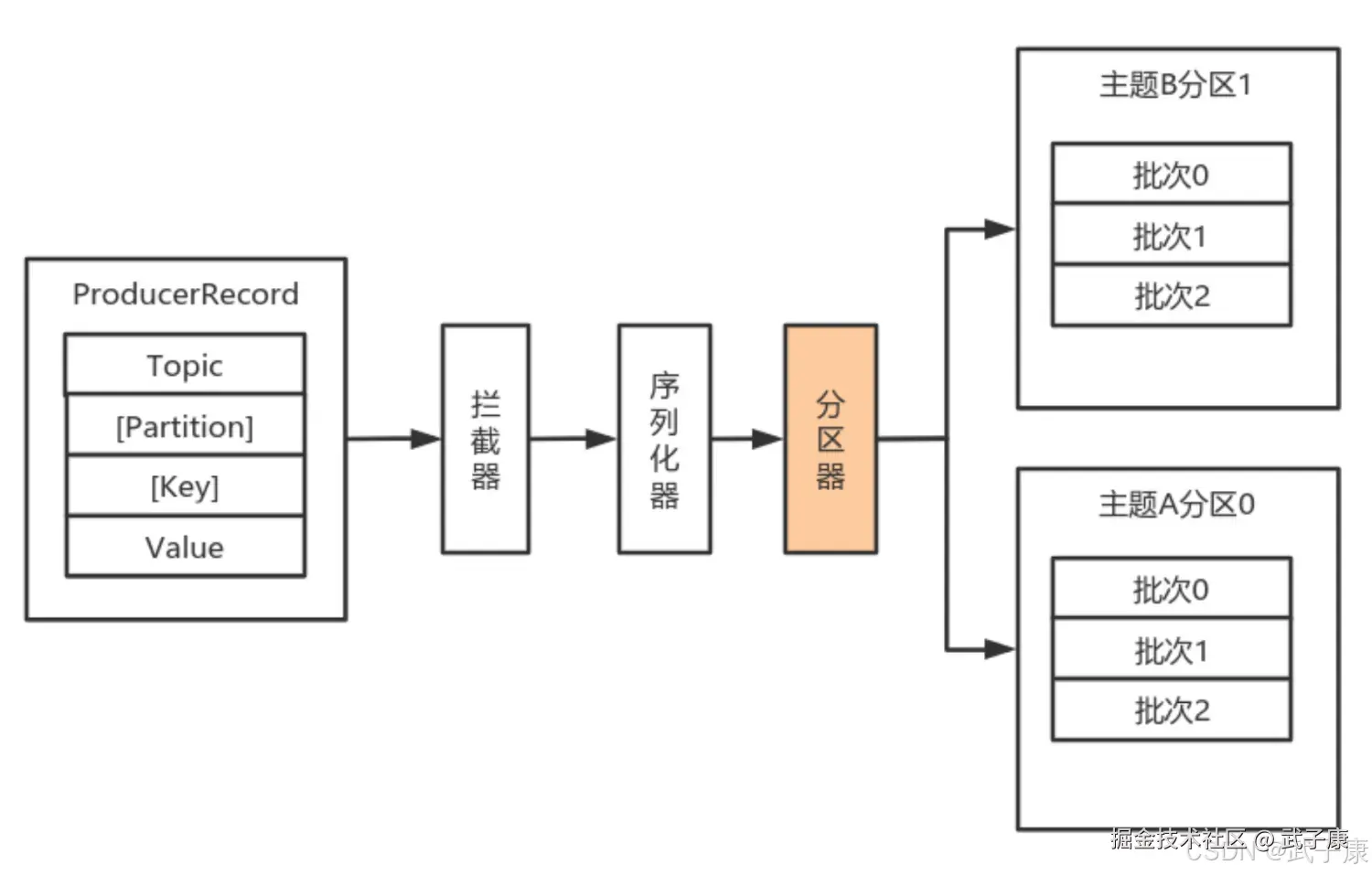
默认情况下的分区计算:
- 如果Record提供了分区号,则使用Record提供的分区号
- 如果Record没有提供分区号,则使用Key序列化后值的Hash值对分区数取模
- 如果Record没有提供分区号,也没有提供Key,则使用轮询的方式分配分区号
我们在这里可以看到对应的内容:
shell
org.apache.kafka.clients.producer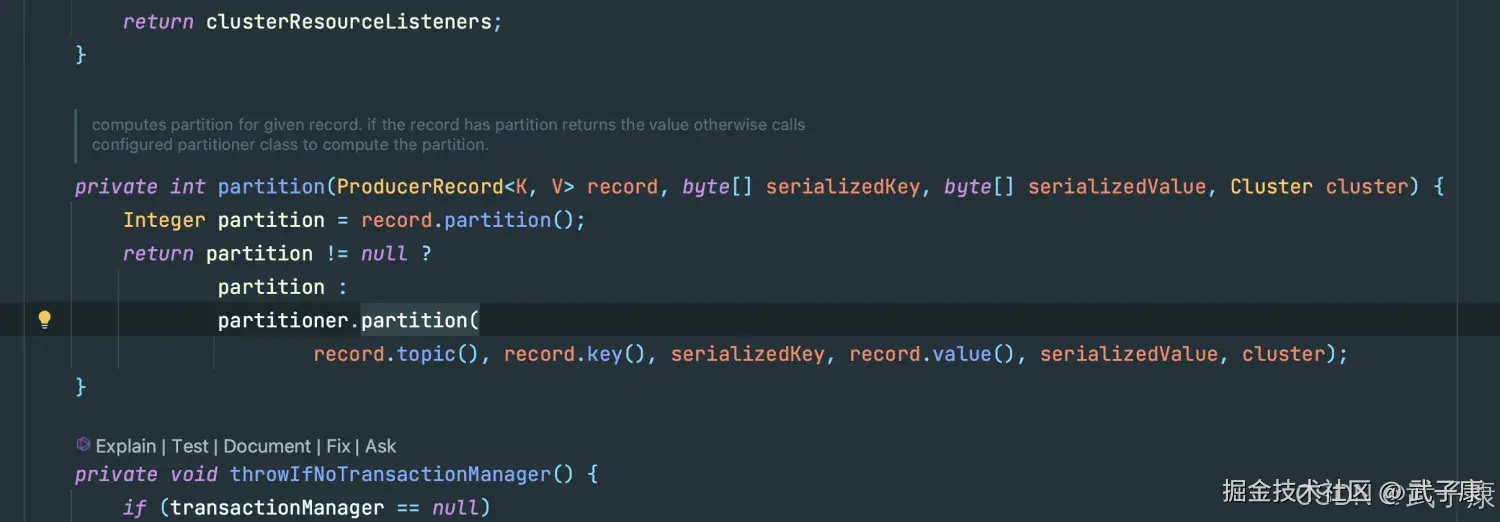 可以看到,如果 Partition 是 null的话,会有函数来进行分区,跟进去,可以看到如下方法:
可以看到,如果 Partition 是 null的话,会有函数来进行分区,跟进去,可以看到如下方法: 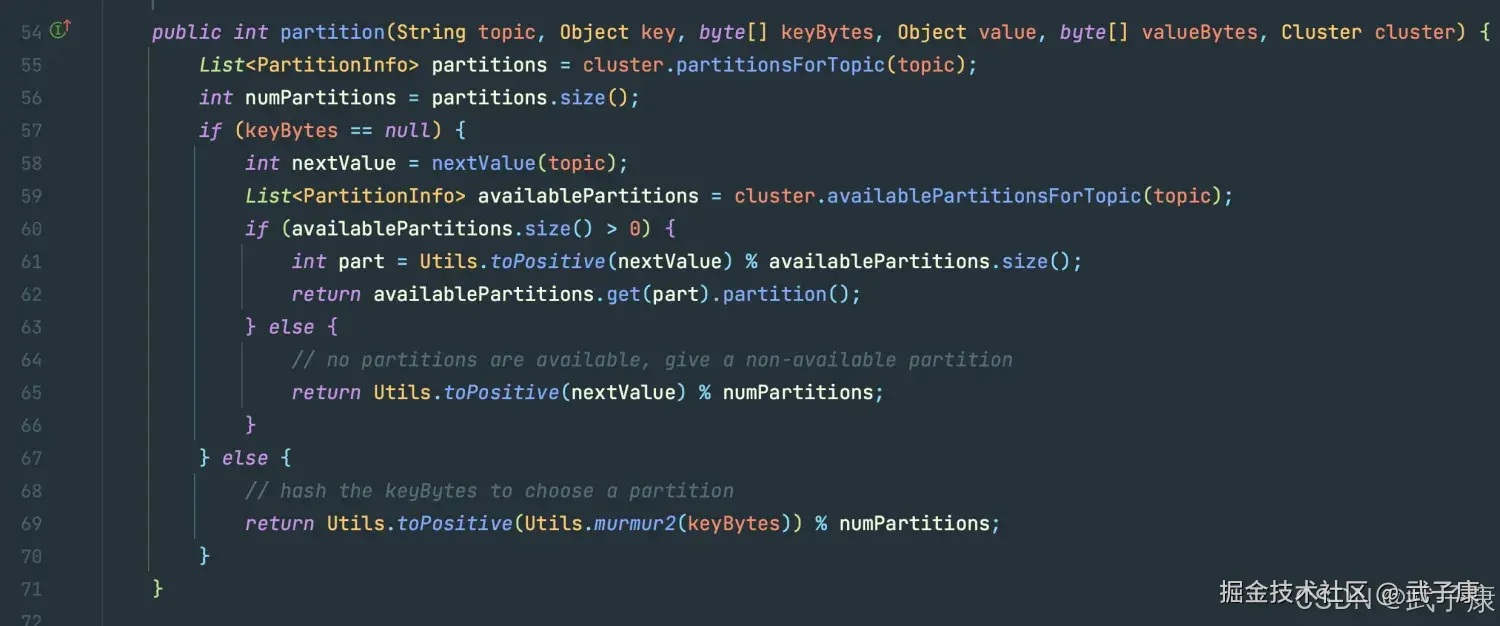
自定义分区器
如果要自定义分区器, 需要:
- 首先开发Partitioner接口中的实现类
- 在KafkaProducer中进行设置:configs.put("partitioner.class", "xxx.xxx.xxx.class")
java
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}