1: 背景
公司之前有一个非常老的系统,需要进行重构,包括代码的重构,还有数据库的迁移,目前难点就是在于数据库的数据迁移了,因为当前app一直有用户使用的,如果停机的话,会严重影响用户体验,停机方案是直接被否决的,本次使用的是不停机的数据库迁移。
2:迁移的方案
不停机的数据库迁移方案,主要包括以下步骤
1: 先利用myqsldump文件,把之前的数据全部迁移过来

2: 通过update_time字段,把迁移过程中的新增的数据迁移过来
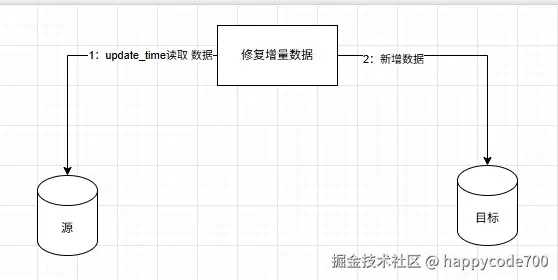
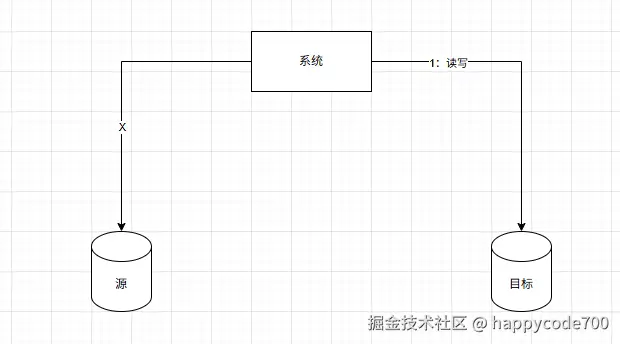
3: 开启双写, 先写源表数据,再写目标表数据
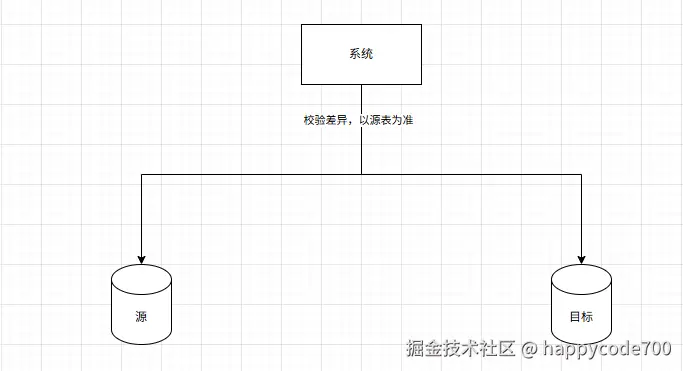
4:数据库的增量数据的对比和校验,以源表为准
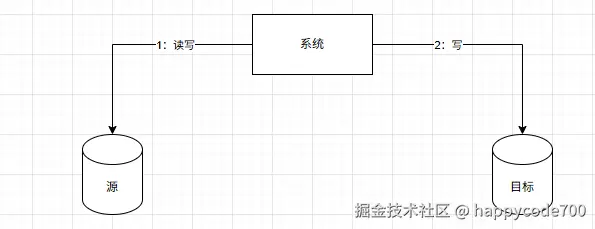
5: 稳定一段时间后,切换写数据顺序,先写目标表,再写源表
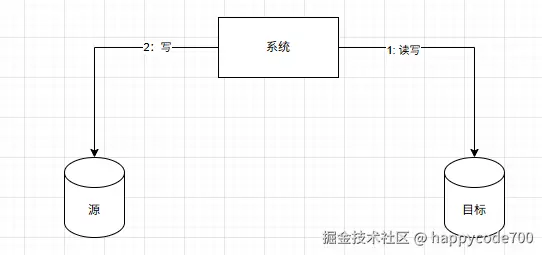
6:数据库的增量数据的对比和校验,以目标表为准
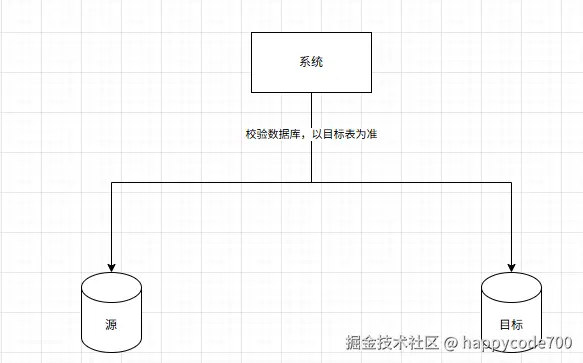 7: 稳定一段时间后,读写完全用目标表,源表下线,完成迁移
7: 稳定一段时间后,读写完全用目标表,源表下线,完成迁移
3: 迁移的问题
3.1: 怎么提高mysqldump的导入数据?
1:设置写binlog的参数为0,即每次提交数据不写binlog, 等系统自己刷新binlog
2: 设置写redlog的参数为0, 即每次提交数据不写redlog, 等系统自己刷新redlog
3.2: 双写怎么实现?
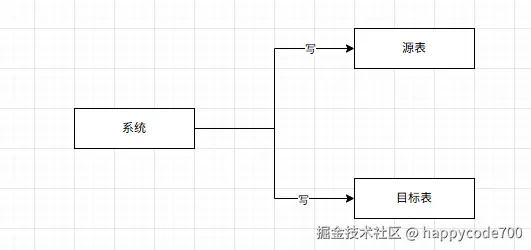
1: 第一种方案,在每一处调用update和insert的地方,加上双写逻辑,这样的实现方式最简单,但是怕改漏
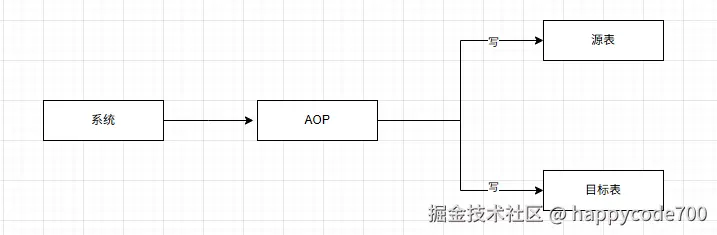
2: 第二种方案,Aop方案,在表的写逻辑处使用AOP,AOP内部的逻辑就是双写,改造的范围小,不怕漏
3.3: 如果源表写入成功,但是写目标表失败呢?
没有关系,后续有检验增量定时任务,会补全的,这种当初设计的时候,也是新增了日志告警,可以及时发现写入目标表失败的细节,后面人工注意观察
3.4: 目标表的主键怎么设计的?
目标表主键是同步源表的,先写源表,写入成功了,源表会返回主键,后续写目标表的直接用该主键就可以了,这样可以防止数据不一致的问题
3.5: 定时任务检验增量数据是怎么做的?
1:第一种方案是最简单的,我们表有update_time字段,通过update_time查询出某一段时间的数据,去对比源表和目标表关键性字段,如果不一致就更新。
2:第二种方案,也是我们采用的方案,通过消费源表的binlog,当源表binlog是写数据的时候,我们会通过binlog的信息查询源表和目标表数据,进行对比。
3.6: 对比数据是查询从库还是主库?
为了缓解主库的压力,其实我们查询的是从库,但是从库可能会有主库延迟的问题,所以当查询源表和目标数据不一致的时候,我们才再去查主库,其实不一致的情况不多,这样就能解决主库压力过大的问题。