TL;DR
- 场景:时序/日志类表写入高、查询慢,想吃到 MergeTree 的吞吐与范围查询红利。
- 结论:用本文 SOP 可 10 分钟跑通 PARTITION BY + ORDER BY + index_granularity 最小闭环,并掌握合并观测/手动触发/回滚。
- 产出:详细分析研究 ClickHouse MergeTree 结构原理分析
MergeTree
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎。MergeTree系列引擎是ClickHouse的核心存储引擎,专为高吞吐量数据写入和高效查询而设计,特别适合处理时间序列数据、日志分析等大数据场景。
MergeTree引擎系列的基本理念如下:当你有巨量数据要插入到表中时,采用批量写入数据片段的方式要比传统的实时单行插入高效得多。具体工作原理是:
-
数据写入阶段:
- 数据以数据块(part)的形式批量写入
- 每个数据块内部按主键排序存储
- 写入过程是追加式的,不会修改已有数据
-
后台合并过程:
- 系统会定期(通常10-15分钟)自动触发合并操作
- 将多个小数据块合并成更大的有序数据块
- 合并过程会优化存储结构并删除重复数据
- 合并操作是异步进行的,不影响写入性能
这种设计相比传统数据库需要在插入时不断重写数据的方式具有显著优势:
- 写入吞吐量高:批量写入可达到每秒数百万行的速度
- 查询效率高:有序存储的数据更利于范围查询
- 资源利用率好:合并操作可以安排在系统负载较低时进行
实际应用场景示例:
- 物联网设备数据采集(每秒数十万条传感器数据)
- 网络流量日志分析(TB级日志存储和查询)
- 电商用户行为分析(海量点击流数据存储)
MergeTree系列还包括多种变种引擎,如ReplacingMergeTree(自动去重)、SummingMergeTree(自动聚合)等,针对不同场景提供专门优化。
存储结构
创建新表
shell
CREATE TABLE mt_table(date Date, id UInt8, name String)
ENGINE = MergeTree PARTITION BY toYYYYMM(date) ORDER BY id;
CREATE TABLE mt_table3 (
`date` Date,
`id` UInt8,
`name` String
) ENGINE = MergeTree PARTITION BY toYYYYMM(date) ORDER BY id;执行的结果如下图所示: 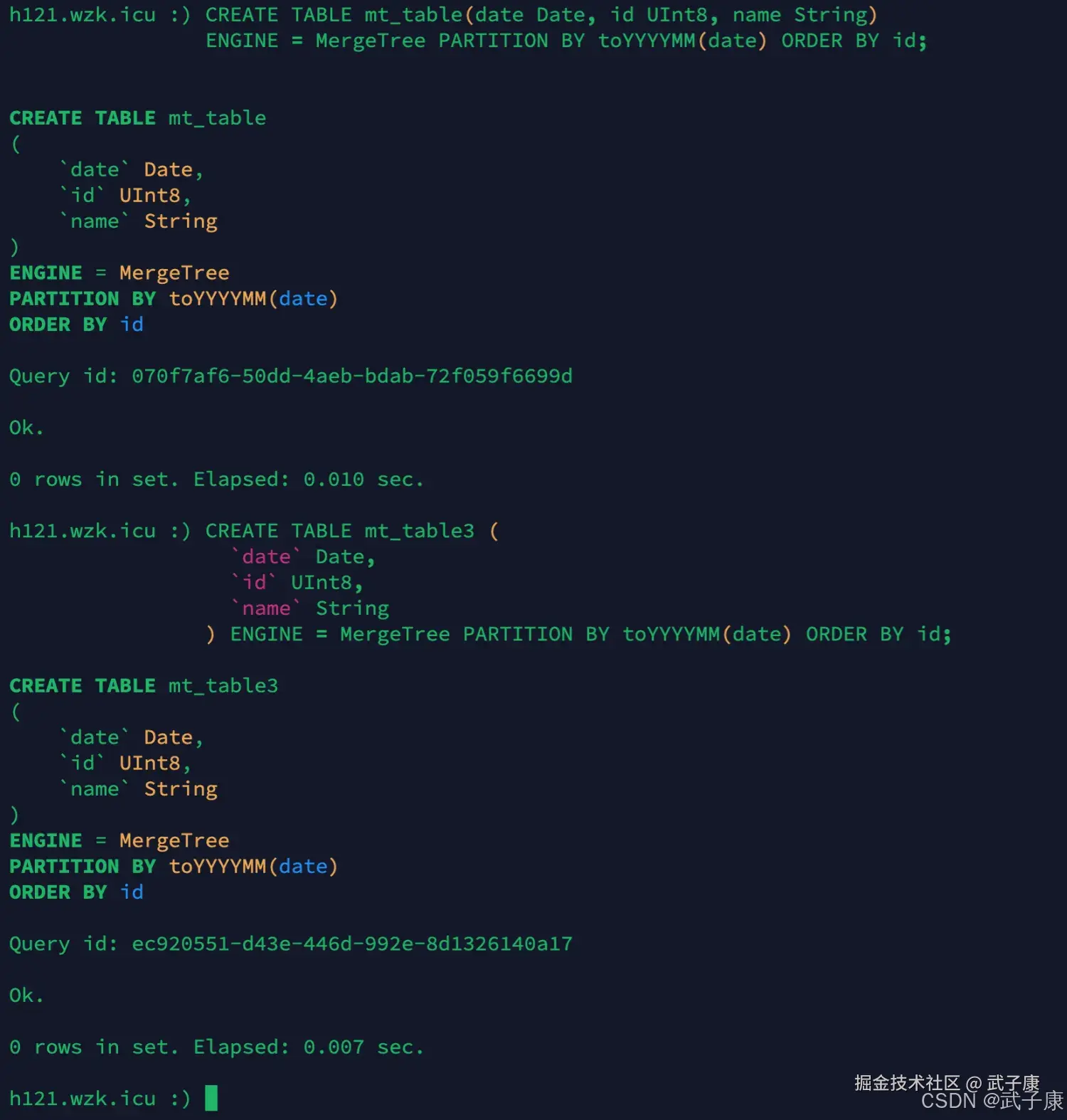
插入数据
shell
INSERT INTO mt_table VALUES ('2024-07-31', 1, 'wzk');
INSERT INTO mt_table VALUES ('2024-07-30', 2, 'icu');
INSERT INTO mt_table VALUES ('2024-07-29', 3, 'wzkicu');执行结果如下图所示: 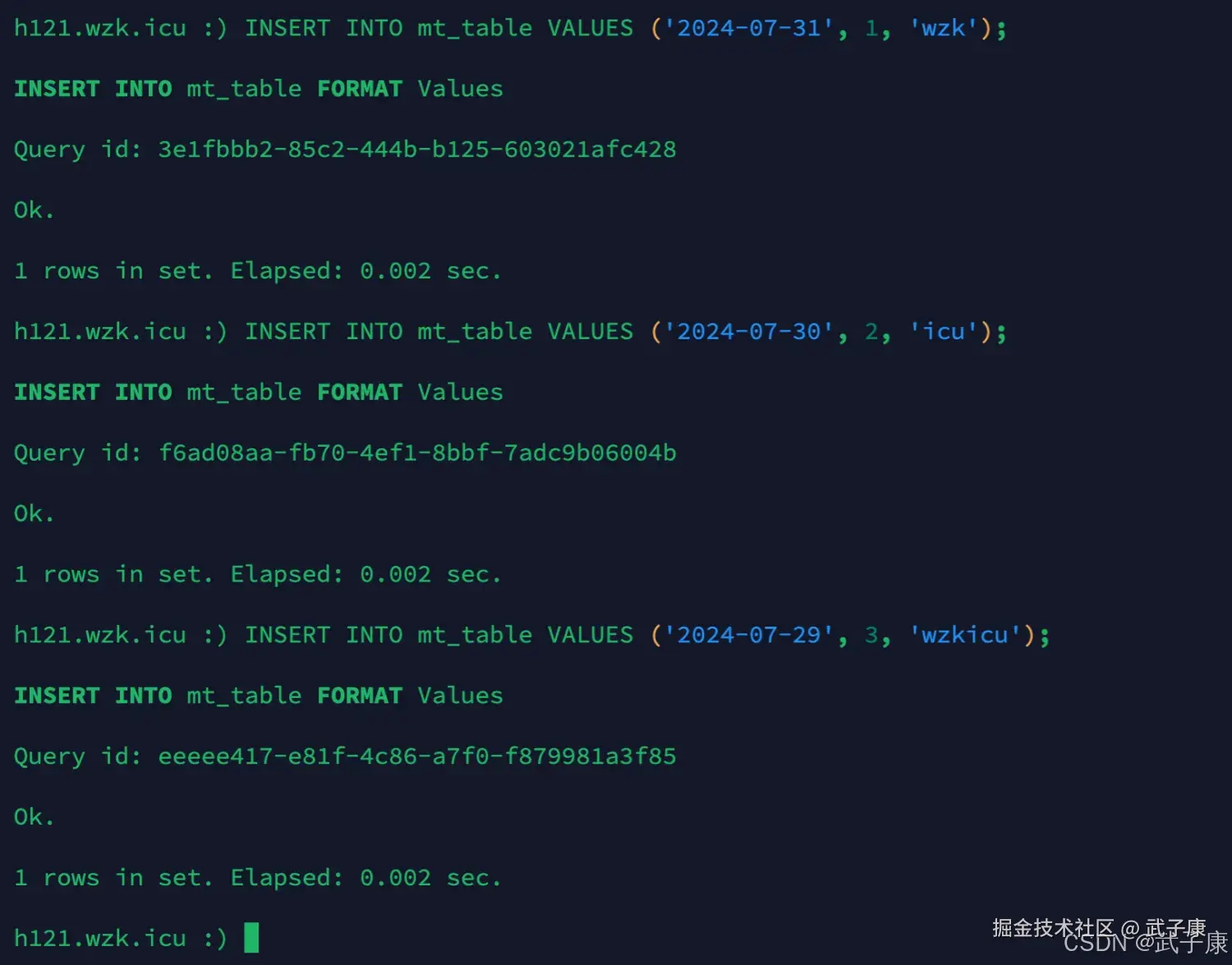
查看目录
shell
cd /var/lib/clickhouse/data/default/mt_table
ls执行结果如下图所示:  我们随便进入一个目录,可以看到:
我们随便进入一个目录,可以看到:
- bin 是按列保存数据的文件
- mrk 保存块偏移量
- primary.idx 保存主键索引
存储结构
shell
.
├── 202407_1_1_0
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ ├── minmax_date.idx
│ ├── partition.dat
│ └── primary.idx
├── 202407_2_2_0
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ ├── minmax_date.idx
│ ├── partition.dat
│ └── primary.idx
├── 202407_3_3_0
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ ├── minmax_date.idx
│ ├── partition.dat
│ └── primary.idx
├── detached
└── format_version.txt执行结果如下图所示: 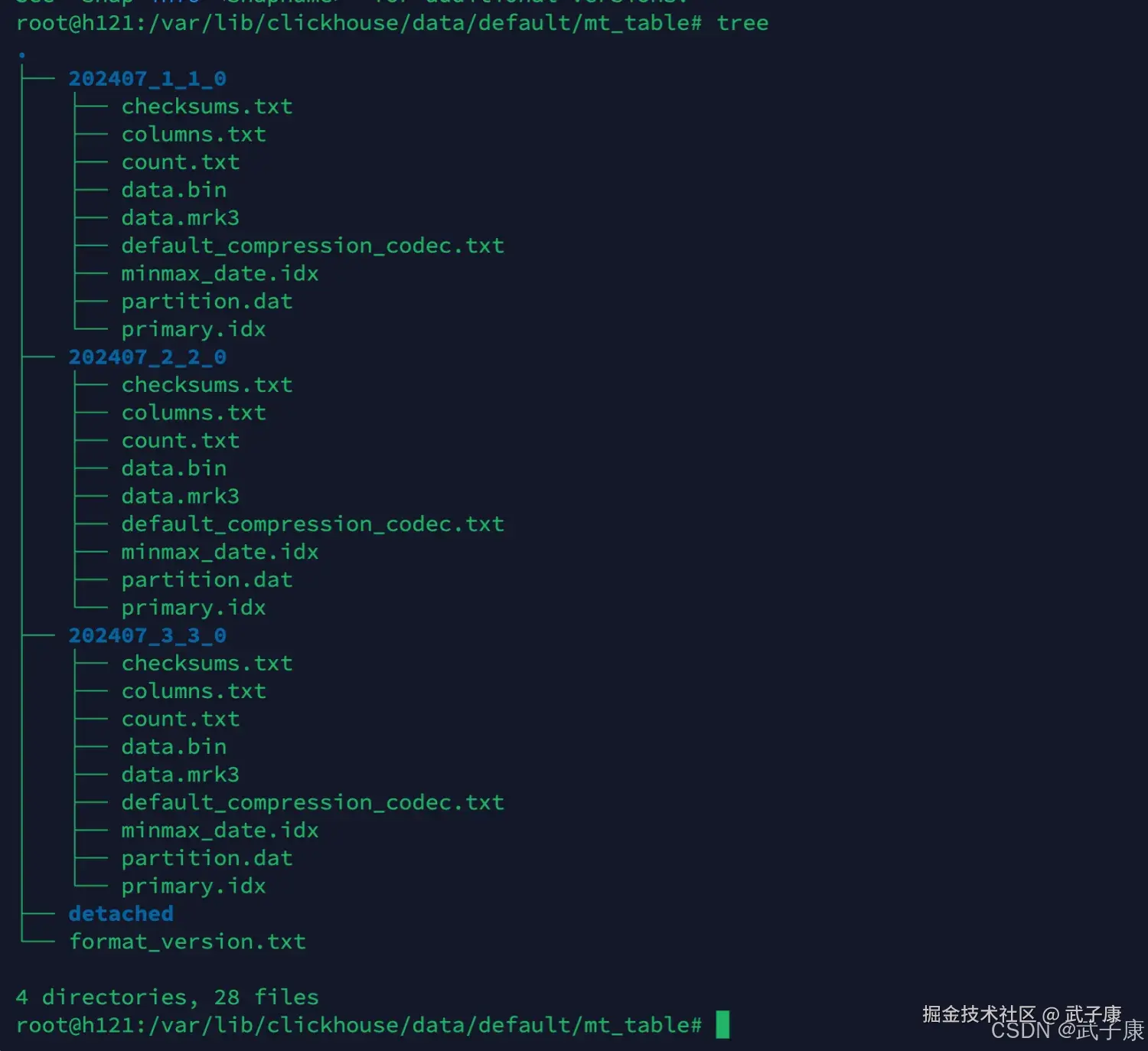
- checknums.txt 二进制校验文件,保存了余下文件的大小size和size的hash值,用于快速校验文件的完整和正确性
- columns.txt 明文的列信息
- date.bin 压缩格式(默认LZ4)的数据文件,保存了原始数据,以列名 bin 命名。
- date.mrk2 使用了自适应大小的索引间隔
- primary.idx 二进制一级索引文件,在建表的时候通过 order by 或者 primary key 声明稀疏索引。
数据分区
数据是以分区目录的形式组织的,每个分区独立分开存储。这种形式,在数据查询的时候,可以有效的跳过无用的数据文件。
分区规则
分区键的取值,生成分区ID,分区根据ID决定,根据分区键的数据类型不同,分区ID的生成目前有四种规则:
- 不指定分键
- 使用整型
- 使用日期类型 toYYYYMM(date)
- 使用其他类型 数据在写入的时候,会按照分区ID落入对应的分区。
分区目录生成
- BlockNum 是一个全局整型,从1开始,每当新创建一个分区目录,此数字就累加1。
- MinBlockNum:最小数据块编号
- MaxBlockNum:最大数据块编号
- 对于一个新的分区,MinBlockNum和MaxBlockNum的值是相同的
分区目录合并
MergeTree 的分区目录在数据写入过程中被创建,不同的批次写入数据属于同一分区,也会生成不同的目录,在之后某个时刻再合并(写入后10-15分钟),合并后的旧分区目录默认8分钟后删除。
同一个分区的多个目录合并以后得命名规则:
- MinBlockNum:取同一分区中MinBlockNum值最小的
- MaxBlockNum:取同一分区中MaxBlockNum最大的
- Level:取同一分区最大的Level值+1
一级索引
稀疏索引
文件:primary.idx MergeTree的主键使用PrimaryKey定义,主键定义之后,MergeTree会根据index_granularity间隔(默认8192)为数据生成一级索引并保存至primary.idx中,这种方式就是稀疏索引。 简化形式:通过 ORDER BY 指代 主键
primary.idx 文件的一级索引采用稀疏索引。
- 稠密索引:每一行索引标记对应一行具体的数据记录
- 稀疏索引:每一行索引标记对应一段数据记录(默认索引粒度是8192)
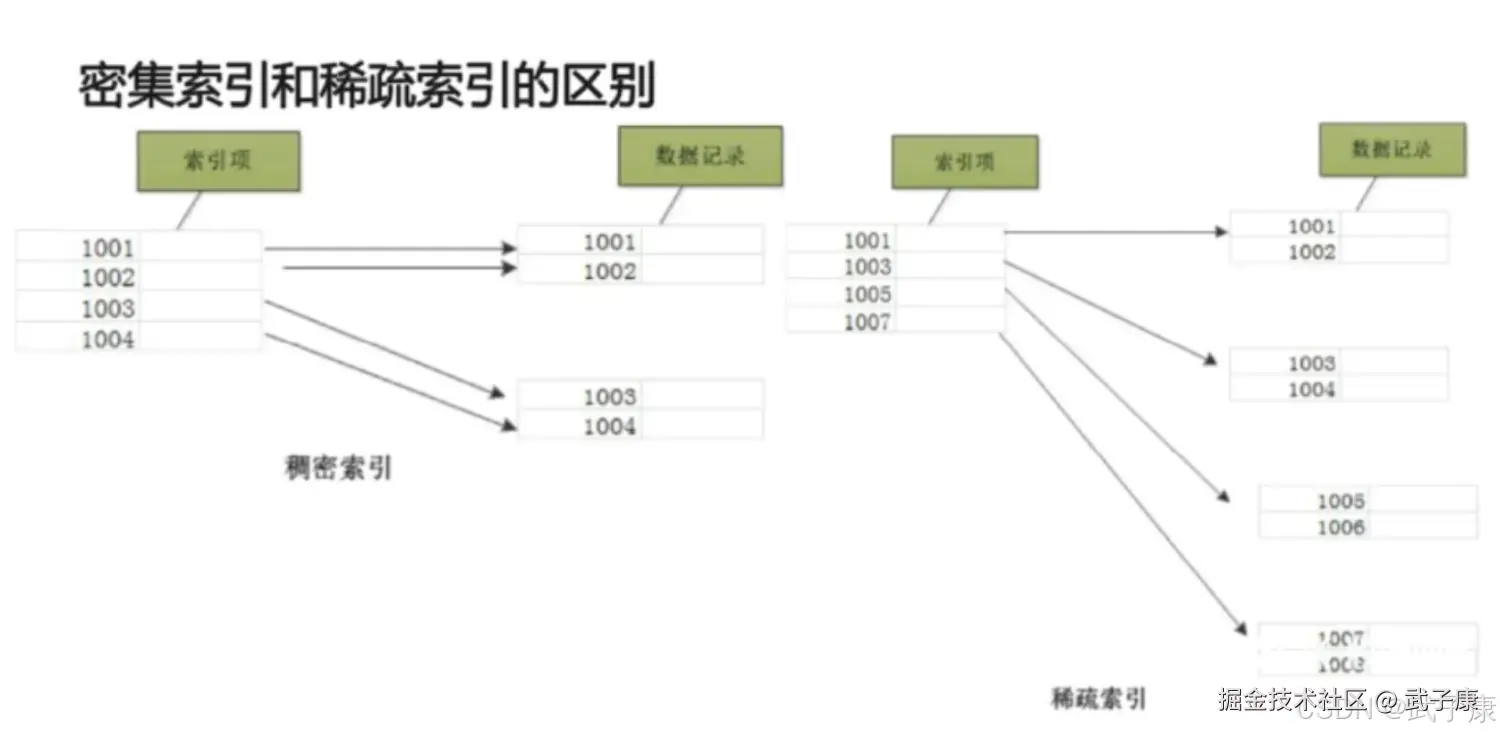 稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度快。
稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度快。
生成规则
primary.idx文件,由于稀疏索引,所以MergeTree要间隔index_granularity行数据才会生成一个索引记录,其他索引值会根据声明的主键字段获取。
查询过程
索引是如何工作的?对primary.idx文件的查询过程
- MarkRange: 一小段数据区间,按照 index_granularity的间隔粒度,将一段完整的数据划分成多个小的数据段,小的数据段就是MarkRange
- MarkRange与索引编号对应
小案例:
- 200行数据
- index_granularity大小为5
- 主键ID为int,取值从0开始
共200行数据/5 = 40个MarkRange  假设索引查询 where Id = 3
假设索引查询 where Id = 3
- 第一步:形成区间格式 3,3
- 第二步:进行交集 3,3 ∩ 0, 199 以MarkRange的步长大于8分块,进行剪枝:

- 第三步:合并, MarkRange(start0, end20)
在ClickHouse中,MergeTree引擎表的索引列在建表使用ORDER BY语法来指定。 而在官方中,用了下面一副图来说明。  这张图示出了以 CounterID、Date两列为索引列的情况,即先以CounterID为主要关键字排序,再以Date为次要关键字排序,最后用两列的组合作为索引键。Marks与MarkNumbers就是索引标记,且Marks之间的间隔就由建表时的索引粒度参数index_granularity来制定,默认是8192。
这张图示出了以 CounterID、Date两列为索引列的情况,即先以CounterID为主要关键字排序,再以Date为次要关键字排序,最后用两列的组合作为索引键。Marks与MarkNumbers就是索引标记,且Marks之间的间隔就由建表时的索引粒度参数index_granularity来制定,默认是8192。
在 ClickHouse 之父Alexey Milovidov分享的PPT中,有更加详细的图示: 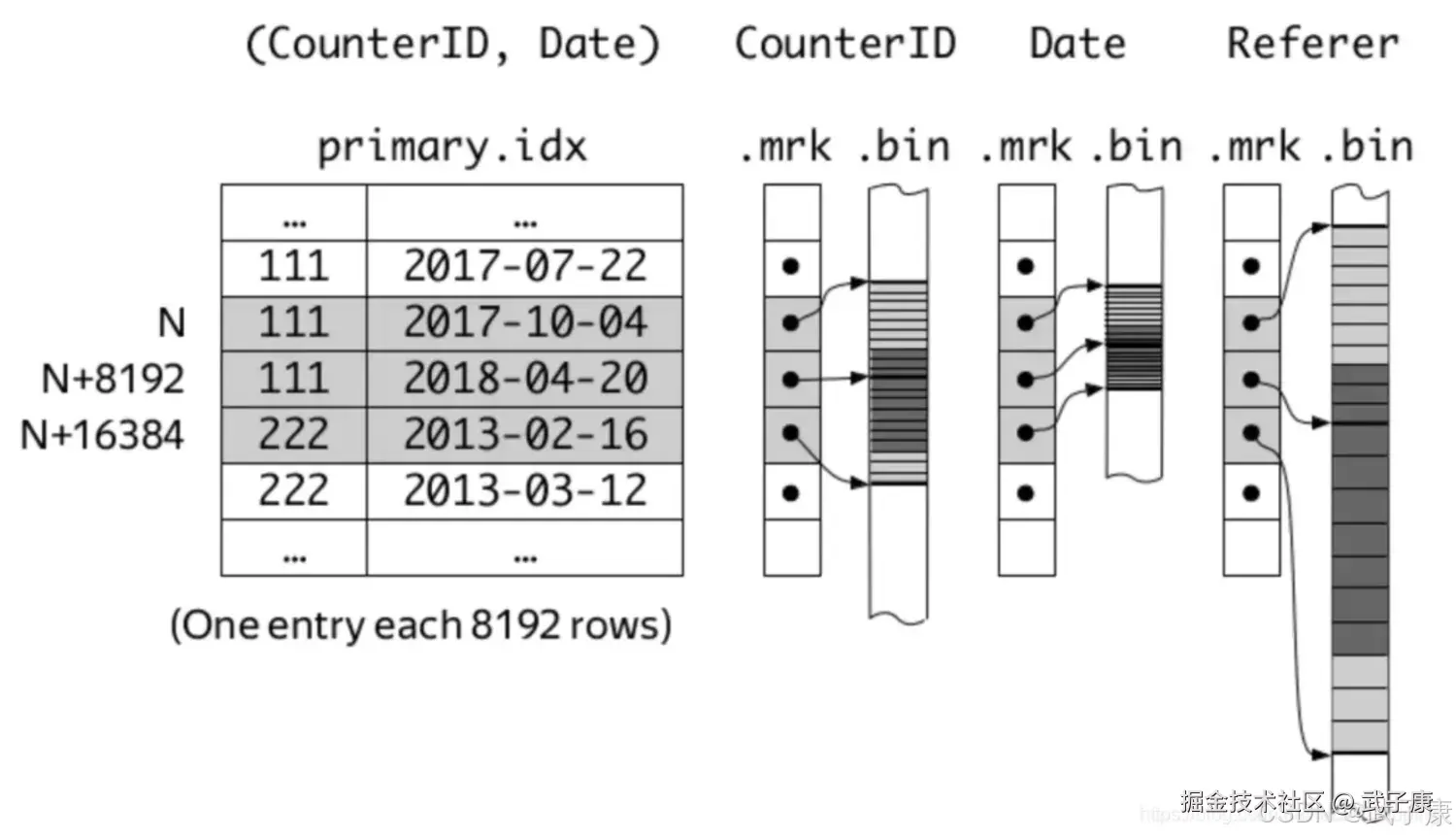
这样,每一列都通过ORDER BY列进行了索引,查询时,先查找到数据所在的parts,再通过mrk2文件确定bin文件中数据的范围即可。 不过,ClickHouse的稀疏索引与Kafka的稀疏索引不同,可以由用户自由组合多列,因此也要格外注意不要加入太多索引列,防止索引数据过于稀疏,增大存储和查找成本。另外,基数太小(即区分度太低)的列不适合做索引列,因为很有可能横跨多个mark值仍然相同,没有索引的意义了。
跳数索引
- index_granularity 定义了数据的粒度
- granularity定义了聚合信息汇总的粒度
- granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据
可用类型
- minmax存储指定表达式的极值(如果表达式是tuple,则存储tuple中每个元素的极值),这些信息用于跳过数据块,类似主键
- set(max_rows)存储指定表达式的唯一值(不超过max_rows个,max_rows=0则表示无限制)。这些信息可以用于检查 WHERE 表达式是否满足某个数据块
- ngrambf_v1 存储包含数据块中所有N元短语的布隆过滤器。只可用于字符串上,用于优化equals、like和in表达式的性能。
- tokenbf_v1 跟 ngrambf_v1 类似,不同于ngrams 存储字符串指定长度的所有片段,它只存储被非字母数据字符分割的片段。
最小可运行示例
shell
# 1) 启动一个本地 ClickHouse(Docker)
docker run -d --name ch -p 8123:8123 -p 9000:9000 clickhouse/clickhouse-server:latest
# 2) 建表(按月分区,按 id 排序)
cat > mt_schema.sql <<'SQL'
CREATE DATABASE IF NOT EXISTS demo;
DROP TABLE IF EXISTS demo.mt;
CREATE TABLE demo.mt (
date Date,
id UInt32,
name String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(date)
ORDER BY (id)
SETTINGS index_granularity = 8192;
SQL
docker exec -i ch clickhouse-client --multiquery < mt_schema.sql
# 3) 插入样例数据(3 批次)
cat > mt_insert.sh <<'SH'
#!/usr/bin/env bash
for d in 2024-07-29 2024-07-30 2024-07-31; do
docker exec -i ch clickhouse-client -q \
"INSERT INTO demo.mt SELECT '$d', number, concat('name_', toString(number)) FROM numbers(100000)"
done
SH
bash mt_insert.sh
# 4) 核验:看到 3 个 part、范围查询命中
docker exec -i ch clickhouse-client -q "
SELECT partition, name, rows, marks
FROM system.parts
WHERE database='demo' AND table='mt' AND active
ORDER BY name;"
docker exec -i ch clickhouse-client -q "
SELECT count() FROM demo.mt WHERE id BETWEEN 1000 AND 2000;"错误速查
回滚剧本(示例)
sql
-- 1) 先冻结快照(强烈推荐)
ALTER TABLE demo.mt FREEZE WITH NAME 'pre_optimize';
-- 2) 如果合并后效果不佳:DETACH 分区,再从快照恢复
ALTER TABLE demo.mt DETACH PARTITION 202407; -- 仅从元数据移除
-- 手工将 /shadow/{UUID}/data/demo/mt/202407_* 拷回,然后
ALTER TABLE demo.mt ATTACH PARTITION 202407;FAQ
- PRIMARY KEY 与 ORDER BY:在 MergeTree 中常等价;声明 ORDER BY 即定义稀疏主索引。
- 索引列怎么选:优先选择高选择性、常用于过滤/排序的列;多列组合别过多,避免索引过稀疏。
- index_granularity 要不要改:大多数场景保留默认 8192;极端窄扫描/超高并发再评估。
- Compact vs Wide part:小 part 多见 Compact,合并/阈值达标转 Wide;两者共存是正常的。
- OPTIMIZE ... FINAL 能替代后台合并吗:不能,FINAL 是强制合并操作,成本高,用于特定窗口或维护。
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解