Hive SQL溯源秘籍:基于YARN Timeline的SQL执行全链路追踪》
在大数据生态中,精准追踪Hive SQL的执行足迹 是运维与优化的核心挑战。本文提出一套基于 YARN Timeline Service 的端到端解决方案,通过打通 Hive→Tez→YARN 全链路监控体系,实现:
1️⃣ 一键关联 :从YARN Application ID直接溯源原始SQL文本
2️⃣ 跨层穿透 :通过HIVE_QUERY_ID和TEZ_DAG_ID实现Hive逻辑计划与Tez物理执行的联动分析
3️⃣ 安全治理 :适配Kerberos/Simple认证场景,解决ACL权限管控痛点
4️⃣ 配置护航:提供Hive/Tez/YARN三联调优指南,根治日志丢失顽疾
无论您是排查慢查询、审计数据血缘,还是优化Tez DAG性能,本方案将SQL执行的"黑盒"转化为可视化追溯流,让每一条Hive SQL都有迹可循!💡

部署对接
hive配置
hive-site.xml
shell
hive_timeline_logging_enabled = true
hive.exec.pre.hooks = org.apache.hadoop.hive.ql.hooks.ATSHook
hive.exec.post.hooks = org.apache.hadoop.hive.ql.hooks.ATSHook,org.apache.atlas.hive.hook.HiveHook
hive.exec.failure.hooks = org.apache.hadoop.hive.ql.hooks.ATSHookyarn配置
yarn-site.xml
shell
yarn.acl.enable = false(不推荐)
或者新增dr.who
yarn.admin.acl = xxx,dr,who(dr,who是为了tez-ui准备的)
yarn.timeline-service.http-authentication.type = simpletez配置
tez-site.xml
csharp
tez.am.view-acls: *
yarn.timeline-service.enabled: true
tez.tez-ui.history-url.base http://your-host/tez-ui/
tez.am.tez-ui.history-url.template __HISTORY_URL_BASE__?viewPath=/#/tez-app/__APPLICATION_ID__
tez.history.logging.service.class org.apache.tez.dag.history.logging.ats.ATSV15HistoryLoggingService接口
shell
#hive
x.x.x.x:8188/ws/v1/timeline/HIVE_QUERY_ID/
#tez
x.x.x.x:8188/ws/v1/timeline/TEZ_DAG_ID/yarn.acl.enable = true时加user.name= yarn.admin.acl的值即可(一个) 如/ws/v1/timeline/HIVE_QUERY_ID?user.name=yarn

问题
shell
FAILED: RuntimeException Error loading hooks(hive.exec.post.hooks): java.lang.ClassNotFoundException: org.apache.atlas.hive.hook.HiveHook
at java.net.URLClassLoader.findClass(URLClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.hive.ql.hooks.HookUtils.readHooksFromConf(HookUtils.java:55)
at org.apache.hadoop.hive.ql.HookRunner.loadHooksFromConf(HookRunner.java:90)
at org.apache.hadoop.hive.ql.HookRunner.initialize(HookRunner.java:79)
at org.apache.hadoop.hive.ql.HookRunner.runBeforeParseHook(HookRunner.java:105)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:612)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1826)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1773)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1768)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.compileAndRespond(ReExecDriver.java:126)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:214)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:239)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:188)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:402)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)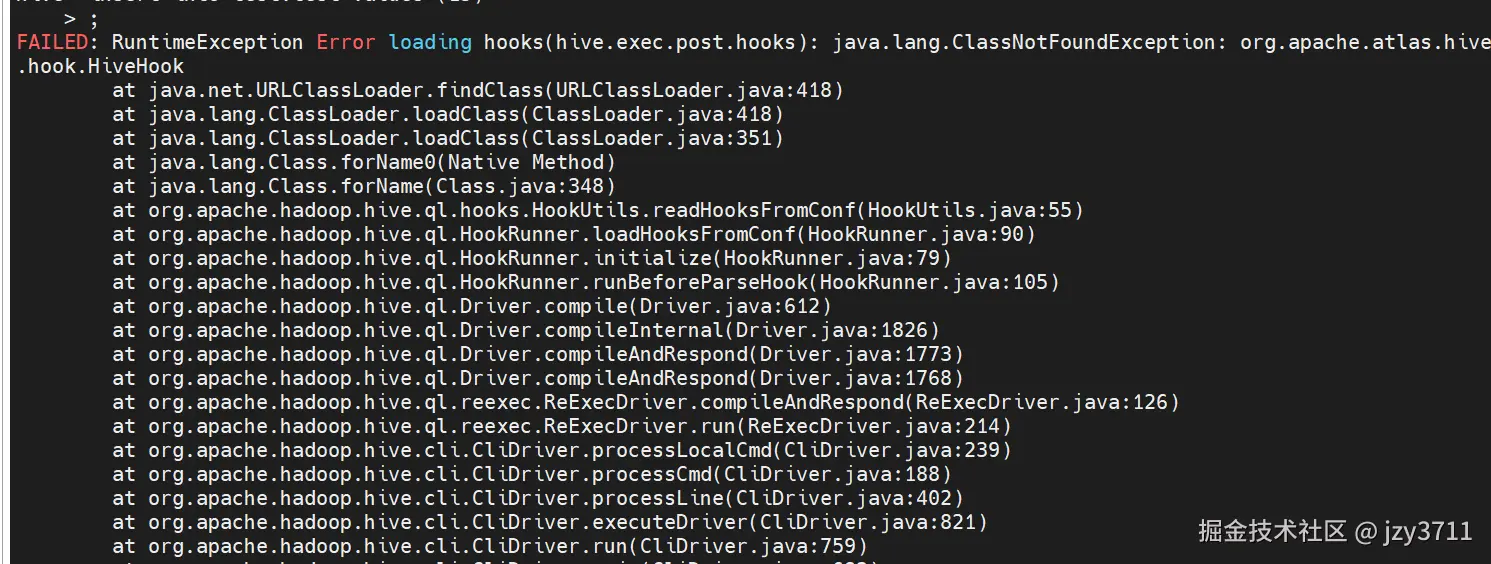 修改
修改hive-site.xml
shell
hive.exec.post.hooks = org.apache.hadoop.hive.ql.hooks.HiveProtoLoggingHook,org.apache.hadoop.hive.ql.hooks.ATSHook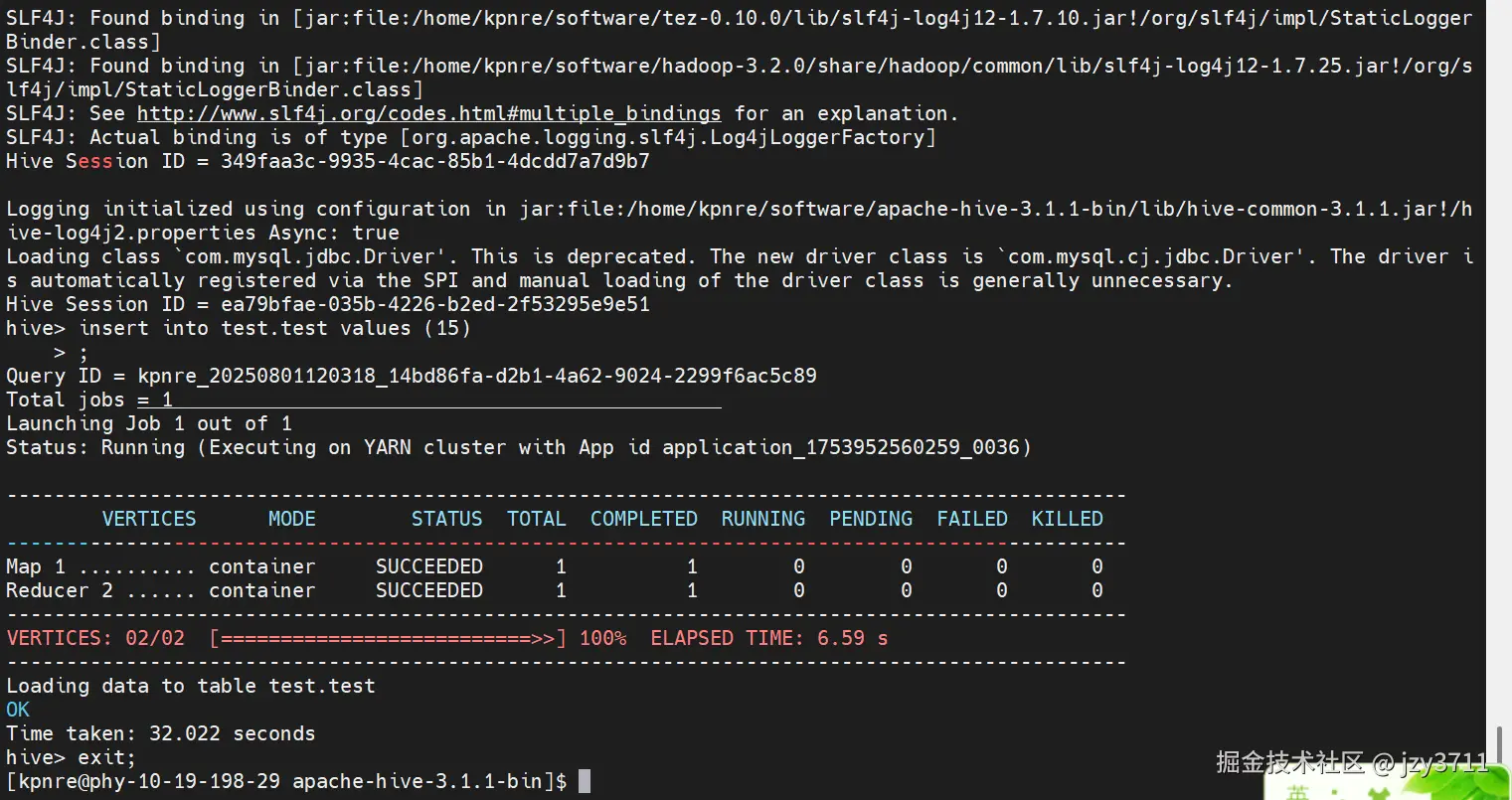

具体方案
核心流程
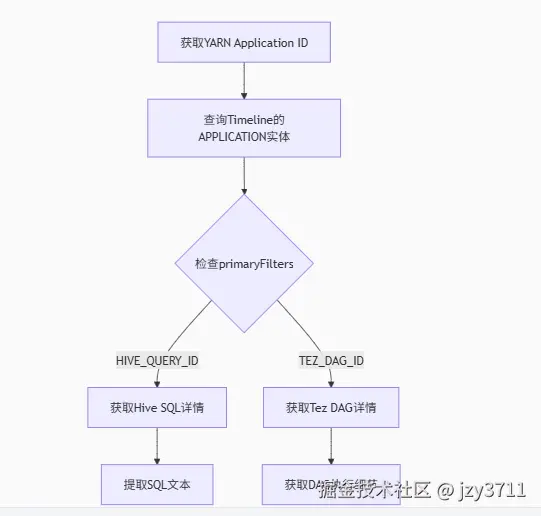
详细步骤
-
获取YARN应用ID
-
从ResourceManager Web UI或命令行获取:
bash
perlyarn application -list -appStates FINISHED | grep 'Hive on Tez'
-
-
查询Timeline Service获取关联ID
bash
bash# 请求示例(替换APPLICATION_ID和TIMELINE_SERVER) curl "http://timeline-server:8188/ws/v1/timeline/APPLICATION/application_123456789_12345"-
关键响应字段:
json
json{ "primaryFilters": { "HIVE_QUERY_ID": ["hive_query_20230801123456_abcd1234"], "TEZ_DAG_ID": ["tez_dag_123456789_12345_1"] } }
-
-
获取Hive SQL详情
bash
arduinocurl "http://timeline-server:8188/ws/v1/timeline/HIVE_QUERY_ID/hive_query_20230801123456_abcd1234"-
关键响应字段:
json
json{ "info": { "queryString": "SELECT * FROM sales WHERE dt='2023-08-01'", "user": "hive_user", "executionMode": "tez" } }
-
-
获取Tez DAG详情(可选)
bash
arduinocurl "http://timeline-server:8188/ws/v1/timeline/TEZ_DAG_ID/tez_dag_123456789_12345_1"- 响应包含DAG执行细节和任务统计
认证处理(当yarn.acl.enable=true时)
在URL后添加user.name参数:
bash
curl "http://timeline-server:8188/ws/v1/timeline/HIVE_QUERY_ID/hive_query_...?user.name=yarn"配置验证清单
-
Hive配置验证:
bashhive -e "set hive.exec.pre.hooks; set hive_timeline_logging_enabled;"确保输出包含
org.apache.hadoop.hive.ql.hooks.ATSHook和true -
YARN Timeline状态检查:
bashcurl -I http://timeline-server:8188/ws/v1/timeline/ # 应返回200 OK -
Tez日志验证 :
检查AM日志是否包含:
textINFO: Using HistoryLoggingService: org.apache.tez.dag.history.logging.ats.ATSV15HistoryLoggingService
常见问题解决
-
404 Not Found:
- 检查实体类型大小写(必须全大写):
HIVE_QUERY_ID - 验证数据保留时间:
yarn.timeline-service.entity-group-fs-store.retain-seconds
- 检查实体类型大小写(必须全大写):
-
403 Forbidden:
xml<!-- yarn-site.xml 添加 --> <property> <name>yarn.timeline-service.http-auth.type</name> <value>kerberos</value> <!-- 或simple --> </property> <property> <name>yarn.timeline-service.http-auth.simple.anonymous.allowed</name> <value>true</value> </property> -
SQL信息缺失 :
确保Hive Hook配置正确:
xml<property> <name>hive.exec.post.hooks</name> <value>org.apache.hadoop.hive.ql.hooks.ATSHook</value> </property>
自动化脚本示例
python
import requests
def get_hive_sql(app_id, timeline_server="http://timeline:8188", user="yarn"):
# 获取主实体
app_url = f"{timeline_server}/ws/v1/timeline/APPLICATION/{app_id}?user.name={user}"
app_data = requests.get(app_url).json()
# 提取Hive查询ID
if "primaryFilters" not in app_data or "HIVE_QUERY_ID" not in app_data["primaryFilters"]:
return None
query_id = app_data["primaryFilters"]["HIVE_QUERY_ID"][0]
# 获取SQL详情
query_url = f"{timeline_server}/ws/v1/timeline/HIVE_QUERY_ID/{query_id}?user.name={user}"
query_data = requests.get(query_url).json()
return query_data.get("info", {}).get("queryString")
# 使用示例
print(get_hive_sql("application_162123456789_12345"))注意:生产环境建议添加:
- Kerberos认证处理
- SSL/TLS加密(设置
yarn.timeline-service.http-policy=HTTPS_ONLY)- 请求超时和重试机制
- 结果缓存(Timeline数据不变)