想象一下你走进一家巨型商场,这里有3000家店铺、500部电梯、100个洗手间。如果每个顾客都要靠纸质地图找路,不出三天商场就会乱成一锅粥------这就是微服务架构没有服务发现的真实写照。别担心,今天要介绍的Nacos就是你的专属智能管家,它能让你的微服务像商场里的智能导航屏一样井然有序。
一、服务发现:代码界的"快递柜系统"
每个微服务启动时,都会把自己的"快递单"(IP+端口+元数据)存到Nacos这个超级快递柜。就像你在丰巢柜存包裹时会生成取件码,服务消费者只需报出"快递单号"(服务名),就能自动获取最新可用的服务地址。
- 注册中心:微服务的快递驿站
每个微服务启动时,都会把自己的"快递单"(IP+端口+元数据)存到Nacos这个超级快递柜。就像你在丰巢柜存包裹时会生成取件码,服务消费者只需报出"快递单号"(服务名),就能自动获取最新可用的服务地址。
服务A和服务B之间如果要相互调用,服务 A 怎么知道服务 B 中每台机器的地址呢?为了让服务 A 拿到服务 B 的机器清单,我们需要搭建一个中心化的服务注册中心,服务 B 只要将自己的信息添加到注册中心里,服务 A 就能够从注册中心获取到服务 B 的所有节点列表。
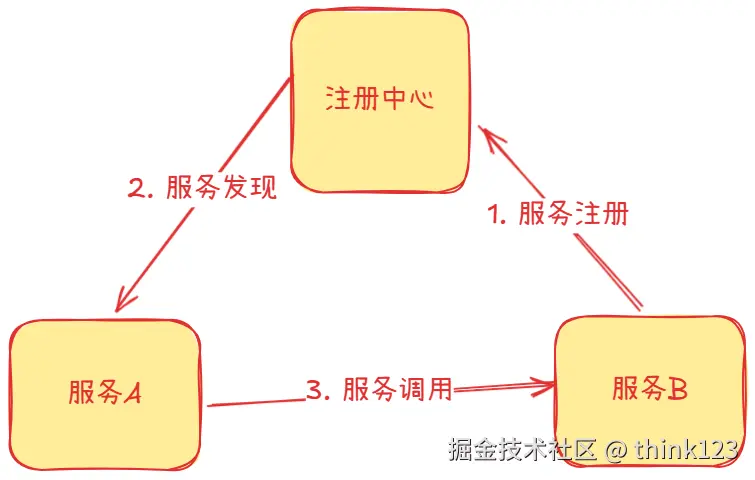
从上图可以看出首先,服务 B 集群向注册中心发起了注册,将自己的地址信息上报到注册中心,这个过程就是服务注册 。接下来,每隔一段时间,服务 A 就会从服务中心获取服务 B 集群的服务列表,或者由服务中心将服务列表的变动推送给服务 A, 这个过程叫做服务发现;最后,服务 A 根据本地负载均衡策略,从服务列表中选取某一个服务 B 的节点,发起服务调用。
在这个过程中,注册中心的角色是一个中心化的信息管理者,所有的微服务节点在启动后都会将自己的地址信息添加到注册中心,在服务注册的过程中,有两个关键信息是最为重要。
+. 服务名称: 通常默认是spring.aplication.name属性, 服务注册必须将服务名上报到注册中心,这样其他服务才能根据服务名称找到对应的服务节点
+. 地址信息: 服务节点的IP地址和端口
- 健康检查:24小时值班的物业管家
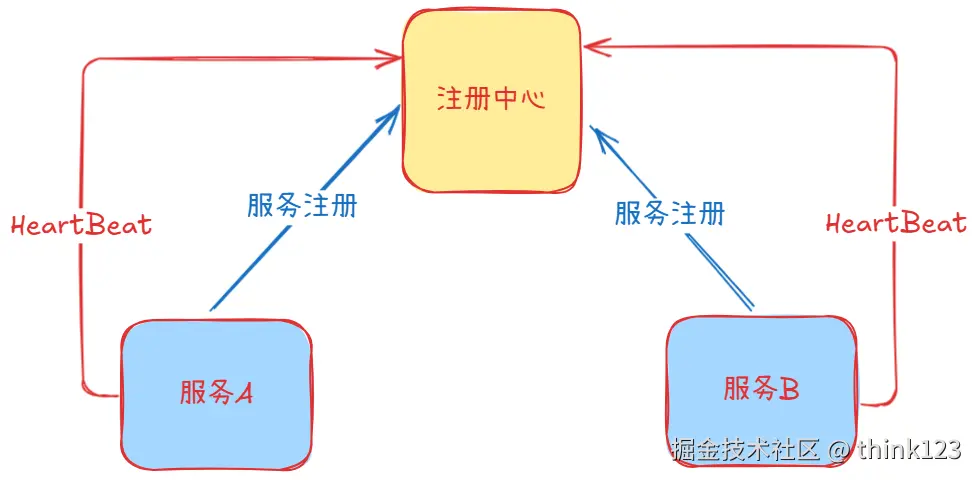
Nacos会定期给所有注册服务"打电话"(心跳检测或者服务探活),就像物业每天检查商铺是否正常营业。当某个服务连续3次不接电话(默认15秒一次),它就会被标记为"暂停营业",其他消费者就不会再往这里发送请求。
- 动态路由:智能导航的最佳路线
想象你在商场APP里搜索"奶茶店",系统会自动推荐当前出餐最快、排队最短的店铺。Nacos通过权重配置和元数据标签,能实现同样的智能路由效果,让流量自动流向最健康的服务节点。
二、配置管理:程序员的"魔法行李箱"
- 配置中心:随用随取的百宝箱
传统配置文件像固定行李箱,改个配置要重新打包部署。而Nacos的配置中心就像魔法行李箱,所有配置以Key-Value形式云端存储。你的程序只需带个空箱子启动,运行时自动从Nacos获取最新装备。
- 多环境管理:一键切换旅行模式
开发环境、测试环境、生产环境就像不同的旅行目的地。通过Data ID后缀(如application-dev.yaml),Nacos让你像切换旅行模式一样轻松管理多套配置,再也不用担心沙滩裤出现在滑雪场。
- 动态更新:实时生效的变形咒
修改配置后传统方式需要重启服务,就像换衣服必须回家。而Nacos通过监听机制,能实现配置热更新------你的程序就像穿了自适应纳米战衣,修改的配置会立即生效,业务运行完全不受影响。
三、高可用架构:永不掉线的超级大脑
- 集群模式:分布式设计的完美体现
Nacos采用Raft协议实现集群选举,就像复联英雄们分工协作。3节点集群中即使1个节点宕机,剩余节点仍能正常提供服务,保证配置信息和服务列表永不丢失。
- 多级缓存:闪电响应的秘密武器
服务列表在内存、本地文件、注册中心存有三份副本,就像你在手机、电脑、云端同时备份重要文件。即使注册中心短暂不可用,本地缓存也能保证服务间正常通信。
- 混合模式:鱼与熊掌兼得的智慧
在CP(强一致性)和AP(高可用性)模式间自由切换,就像汽车的运动/经济模式。金融交易类服务用CP保证数据绝对准确,电商促销时切到AP模式保障系统可用性。
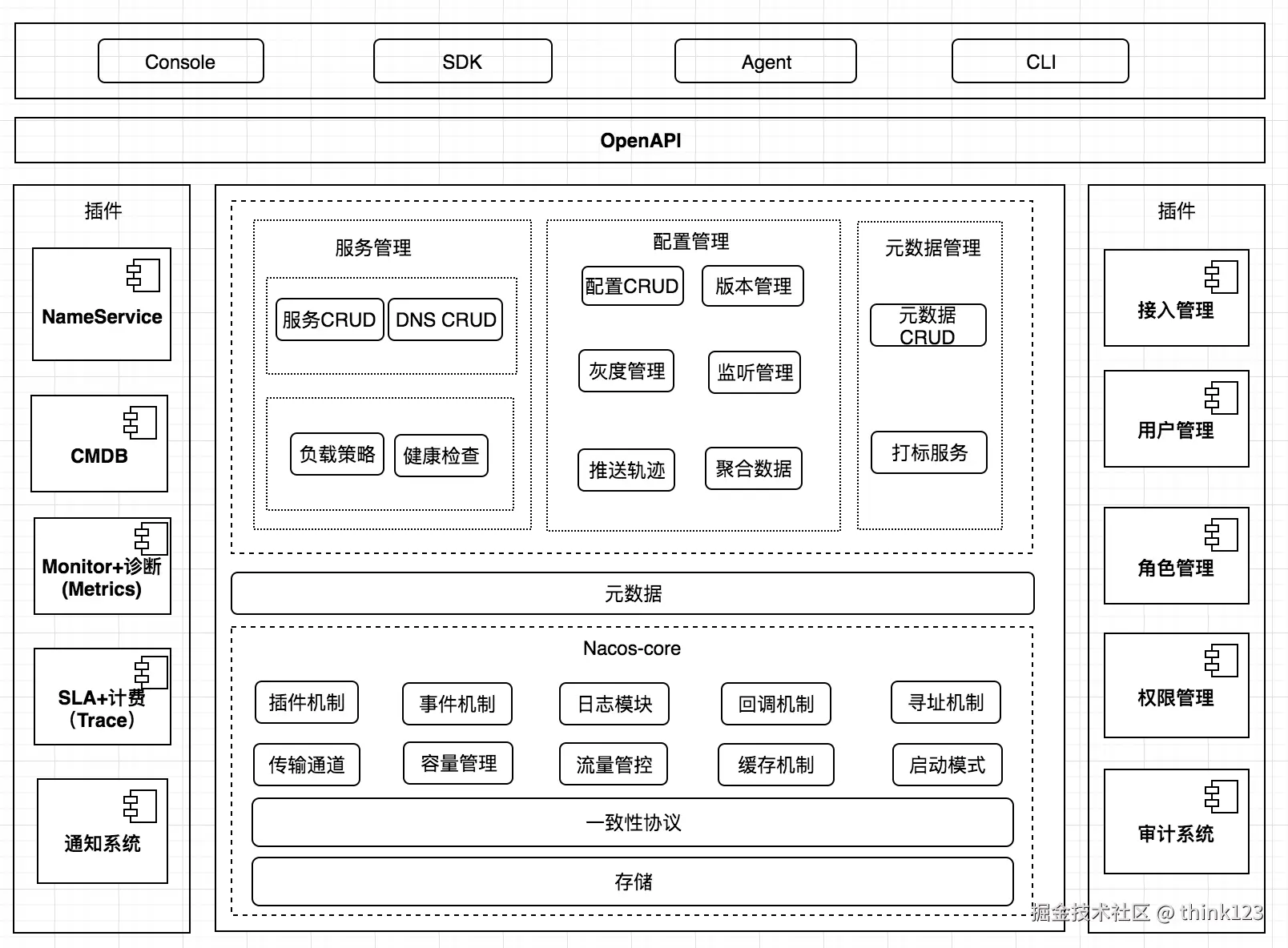
Nacos架构
整体架构分为用户层、业务层、内核层和插件,用户层主要解决用户使用的易用性问题,业务层主要解决服务发现和配置管理的功能问题,内核层解决分布式系统一致性、存储、高可用等核心问题,插件解决扩展性问题。
Nacos数据模型
注册中心的核心数据是服务的名字和它对应的网络地址,当服务注册了多个实例时,需要对不健康的实例进行过滤或者针对实例的一些特征进行流量的分配,那么就需要在实例上存储一些例如健康状态、权重等属性。随着服务规模的扩大,渐渐的又需要在整个服务级别设定一些权限规则、以及对所有实例都生效的一些开关,于是在服务级别又会设立一些属性。
Nacos 在经过内部多年生产经验后提炼出的数据模型,则是一种服务-集群-实例的三层模型
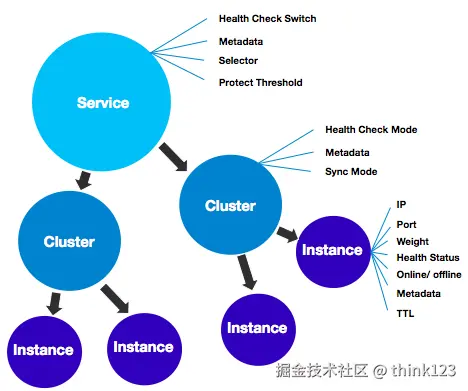
- Service是Nacos数据模型的最顶层概念,代表一个微服务。
- Cluster是Service下的一个逻辑分组,通常用于区分不同的环境或区域。
- Instance是Cluster下的具体服务实例,代表一个真实运行的服务节点。
实际使用案例
- Service: OrderService
- Clusters:
- BeijingCluster
- ShanghaiCluster
- Instances:
- BeijingCluster:
- 192.168.1.100:8080
- 192.168.1.101:8080
- ShanghaiCluster:
- 192.168.2.100:8080
- 192.168.2.101:8080
- BeijingCluster:
这样的结构允许我们
- 对整个OrderService进行统一管理
- 北京和上海的集群可以有不同的配置和策略
- 每个实例可以独立监控和管理
数据隔离模型
作为一个共享服务型的组件,需要能够在多个用户或者业务方使用的情况下,保证数据的隔离和安全,这在稍微大一点的业务场景中非常常见。另一方面服务注册中心往往会支持云上部署,此时就要求服务注册中心的数据模型能够适配云上的通用模型。
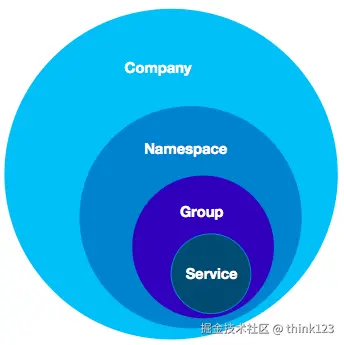
- Namespace:即命名空间,它是最顶层的数据结构,我们可以用它来区分开发环境、生产环境等不同环境。默认情况下,所有服务都部署到一个叫做"public"的公共命名空间
- Group:在命名空间之下有一个分组结构,默认情况下所有微服务都属于"DEFAULT_GROUP"这个分组,不同分组间的微服务是相互隔离的
- Service/DataID:在 Group 分组之下,就是具体的微服务了,比如订单服务、商品服务等等
通过 Namespace + Group + Service/DataID,我们就可以精准定位到一个具体的微服务。比如,我想调用生产环境下 A 分组的订单服务,那么对应的服务寻址的 Key 就是类似Production.A.orderService 的组合。