页面要求 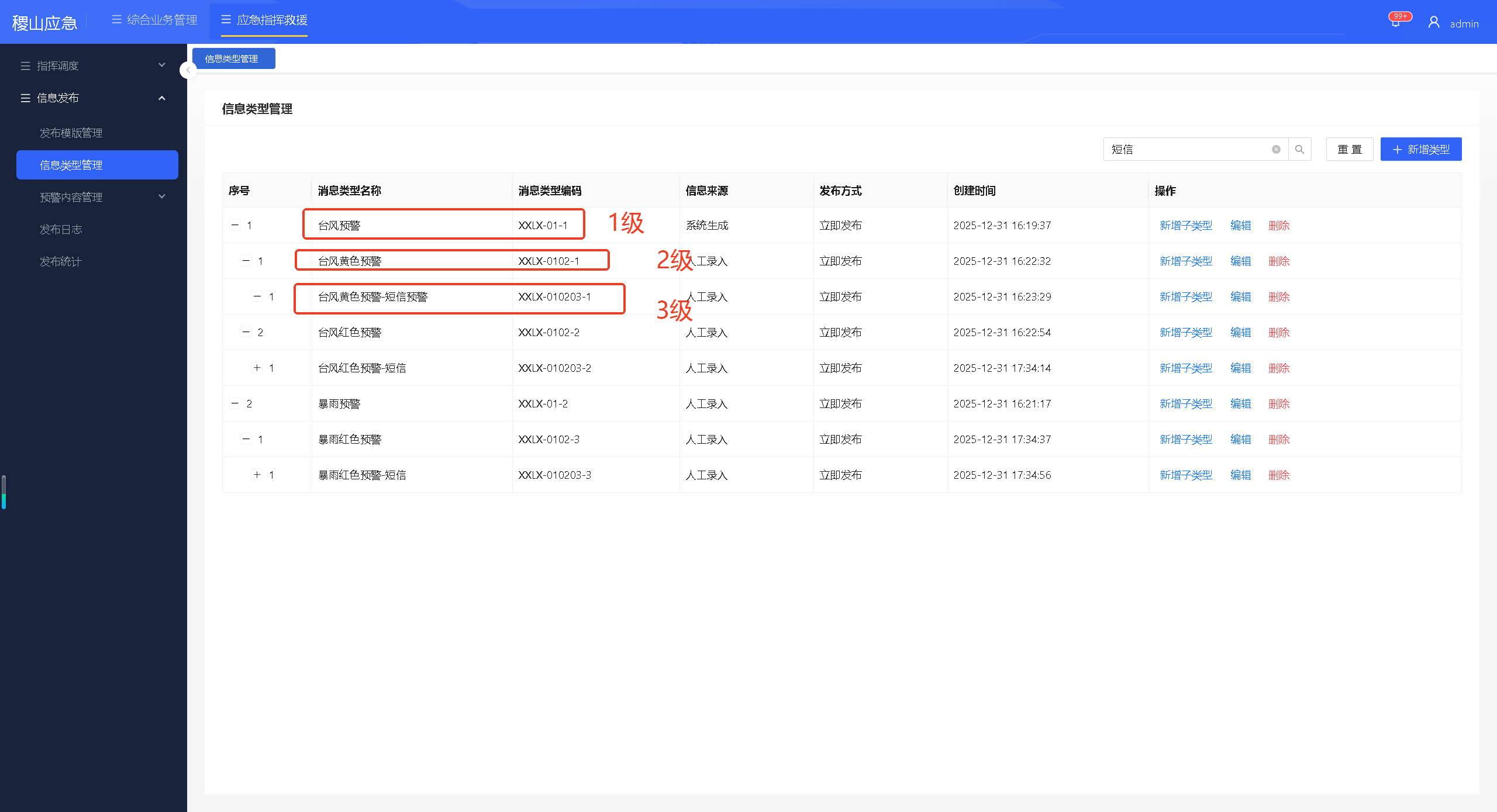 表结构
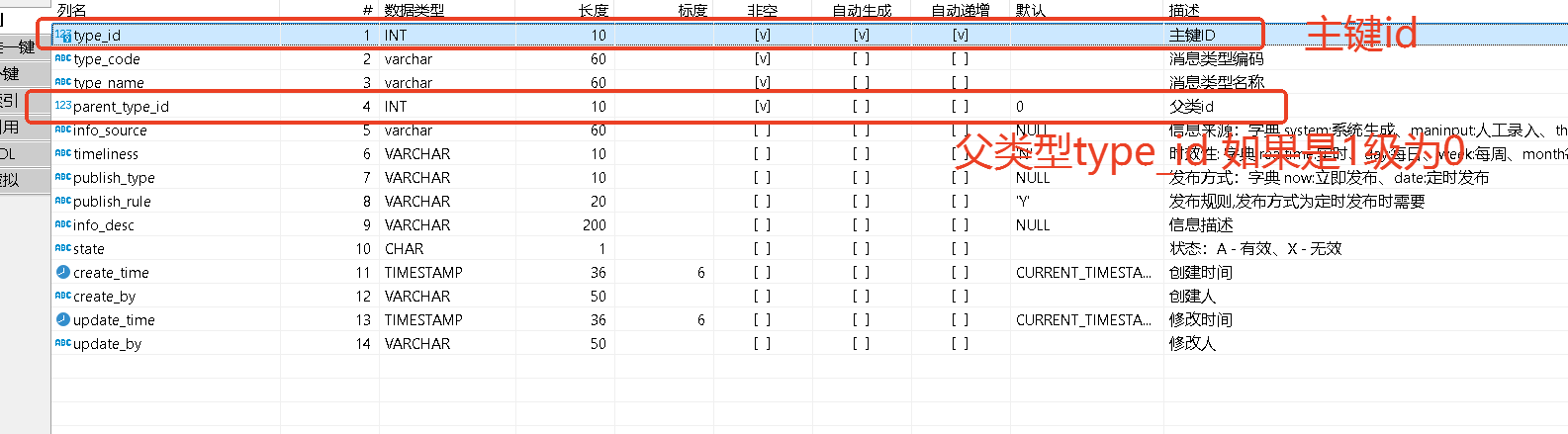
表结构
代码逻辑:
Groovy
typeName = Utils.val("typeName")
def sql = """
WITH RECURSIVE type_cte (
type_id, parent_type_id, type_code, type_name, info_source,
timeliness, publish_type, publish_rule, info_desc, state, create_time, create_by, update_time, update_by
) AS (
SELECT
type_id, parent_type_id, type_code, type_name, info_source,
timeliness, publish_type, publish_rule, info_desc, state, create_time, create_by, update_time, update_by
FROM js_em_publish_info_type
WHERE state = 'A'
AND parent_type_id = 0
UNION ALL
SELECT
t.type_id, t.parent_type_id, t.type_code, t.type_name, t.info_source,
t.timeliness, t.publish_type, t.publish_rule, t.info_desc, t.state, t.create_time, t.create_by, t.update_time, t.update_by
FROM js_em_publish_info_type t
INNER JOIN type_cte p ON t.parent_type_id = p.type_id
WHERE t.state = 'A'
)
SELECT t1.type_id, t1.parent_type_id, t1.type_code, t1.type_name,
t1.info_source, t2.dict_value as info_source_name,
t1.timeliness, t3.dict_value as timeliness_name,
t1.publish_type, t4.dict_value as publish_type_name,
t1.publish_rule, t1.info_desc, t1.state,
TO_CHAR(t1.create_time, 'YYYY-MM-DD HH24:MI:SS') AS create_time,
t1.create_by, t1.update_time, t1.update_by
FROM type_cte t1
LEFT JOIN js_sys_dict t2 ON t1.info_source = t2.dict_code and t2.class_code='psmp_info_source'
LEFT JOIN js_sys_dict t3 ON t1.timeliness = t3.dict_code and t3.class_code='psmp_info_timeliness'
LEFT JOIN js_sys_dict t4 ON t1.publish_type = t4.dict_code and t4.class_code='psmp_info_publish_date_type'
where 1=1
-- ?{typeName, and t1.type_name like concat('%', #{typeName}, '%')}
ORDER BY t1.type_id ASC
"""
log.info("日志输出2: {}", sql)
allTypeList = db.find(sql)
// 优化:在树构建后,仅保留与模糊查询匹配的节点及其祖先、所有子孙,树会自动裁剪非匹配支。
def typeNameParam = typeName ?: null
// 遍历树形数据,匹配需要模糊查询的类型名称,返回过滤后的树型数据
def filterTypeTreeByName(typeList, typeName) {
if (!typeName) return typeList
def result = []
typeList.each { node ->
if ((node.typeName ?: '').contains(typeName)) {
// 节点匹配,保留整棵子树
result << node
} else if (node.children && node.children.size() > 0) {
def filteredChildren = filterTypeTreeByName(node.children, typeName)
if (!filteredChildren.isEmpty()) {
node.children = filteredChildren
result << node
}
}
}
return result
}
// 把无等级树结构的数据,格式化成前端可以直接用的树结构数据
def buildTypeTree(typeList) {
def roots = typeList.findAll { it.parentTypeId == 0 }
roots.each { t ->
t.children = getChildTypes(t.typeId, typeList)
}
return roots
}
def getChildTypes(parentId, typeList) {
def children = typeList.findAll { it.parentTypeId == parentId }
children.each { c ->
c.children = getChildTypes(c.typeId, typeList)
}
return children
}
// 处理数据为前端需要的树数据结构
resultTree = buildTypeTree(allTypeList)
// 如果按类型名称模糊查询的入参不为空,去过滤
if (typeNameParam) {
resultTree = filterTypeTreeByName(resultTree, typeNameParam)
}
return resultTree