一. 前言
丨1. 行业背景
在现代播放器架构中,音频后处理已不仅是锦上添花的功能,而是构建差异化听觉体验的关键组件。尤其在多样化的播放场景(手机外放、耳机、电视音响等)下,通过定制化的音效增强手段,有效提升听感表现已成为基础能力之一。
丨2. 本文概览
本系列文章将系统介绍我们在播放器音频后处理模块中的技术方案与工程实现,主要面向音视频方向的开发者。我们主要基于 FFmpeg的音频滤镜框架,结合自定义模块,构建了一套可扩展、高性能、易适配的音效处理链路。
第一期内容聚焦在两项核心基础音效:
-
重低音:通过构建低通滤波器与动态增益控制逻辑,增强低频段表现,适配小型设备下的听感优化
-
清晰人声:结合频段增强、人声掩码与背景音抑制技术,有效提升对白清晰度,在嘈杂或背景音复杂的场景下保持语音主干突出
我们将分享上述音效的整体处理流程、关键滤镜链搭建方式、滤波器设计细节,以及如何在保证延迟与功耗可控的前提下,通过 FFmpeg 的 af(audio filter)机制灵活插拔各类处理节点。
希望本系列文章能为你提供实用的技术参考,也欢迎有 FFmpeg 或音效处理相关实践经验的开发者交流碰撞,共同推动播放器音频后处理技术的深入发展。
二. 走进音频后处理
丨1. 技术定义和核心目标
对于视听消费场景,音频后处理指在音频信号完成解码(PCM/DSD数据生成)后,通过数字信号处理技术对原始音频进行音质增强、效果添加或缺陷修正的过程。核心目标包括:

丨2. 关键技术分类
音频后处理技术主要可分为以下四大类,每类技术的特点和应用如下:

三. 播放内核音频后处理框架

丨1. 整体架构
音频后处理模块在播放pipeline中的位置如上图所示,位于音频解码模块和音频帧队列之间。模块是否被链接于pipeline中是业务可选的,出于性能考虑,只有真正需要用到音频后处理功能的播放任务才会去链接音频后处理模块。
丨2. 音效支持
目前,播放内核已开放了包括:音量增强、清晰人声、重低音、立体环绕、降噪等多种音效,支持业务在播放前以及播放中打开、关闭或变更任意音效。根据业务的设置,音频后处理模块承担了音效滤镜的初始化、滤镜链组装、滤镜链变更等任务。该模块目前不仅提供了FFmpeg原生滤镜的支持,而且新增了内核自研的热门音效滤镜。
四. 落地音效一:重低音
丨1. 重低音
-
重低音效果通常指的是音响系统或音频设备中低频段的增强效果,特别是那些频率在20Hz到250Hz之间的声音。这种效果使得声音中的低频成分(如鼓声、贝斯声)更加突出和有力,从而带来一种震撼和沉浸式的听觉体验
-
重低音效果通常应用在音乐、电影和游戏中,用以增强音效的冲击力。例如,在观看动作电影时,重低音效果能够使爆炸或撞击声更加震撼,而在听音乐时,它能让鼓点和贝斯的节奏感更强烈。一般来说,这种效果是通过音响设备中的低音炮或音频处理器来实现的,它们能够放大并优化低频声音,使得音效更加浑厚、深沉和有力量
-
音频的频率范围大致可以划分为:
-
次低音 (Sub-bass): 20 Hz - 60 Hz
包括极低频率的声音,如低音炮的低频段,能够带来深沉的震撼感
- 低音 (Bass): 60 Hz - 250 Hz
涵盖常规低音部分,如贝斯和低音鼓,带来厚重感和力量感
- 低中音 (Low midrange): 250 Hz - 500 Hz
涉及一些低频乐器和男声的下半部分,增加声音的温暖感
- 中音 (Midrange): 500 Hz - 2 kHz
包含大部分人声和主要乐器的频段,是声音的核心部分
- 高中音 (Upper midrange): 2 kHz - 4 kHz
涵盖高频乐器、人声的高音部分,决定了声音的清晰度和穿透力
- 高音 (Treble): 4 kHz - 6 kHz
提供声音的亮度和细节,涉及高频乐器和背景环境声
- 极高音 (Brilliance or Presence): 6 kHz - 20 kHz
涉及非常高频的声音,如高频细节、空气感和一些环境声的尾音,影响声音的开放感和透明度
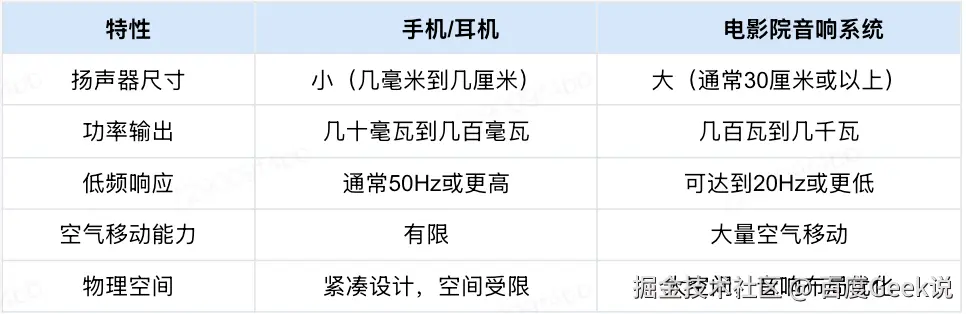
1.1 设备物理限制

手机或者耳机在体积功率等物理限制下,在中低压表现较弱。相比之下,电影院音响系统具备大尺寸扬声器和高功率输出,能够产生20Hz或更低的低频效果,并且其环境设计有助于低音的增强。
-
扬声器尺寸小:手机和耳机的扬声器尺寸通常较小,限制了低频声波的产生
-
功率输出低:这些设备的放大器功率有限,无法驱动强劲的低频振动
1.2 人耳听觉非线性特性
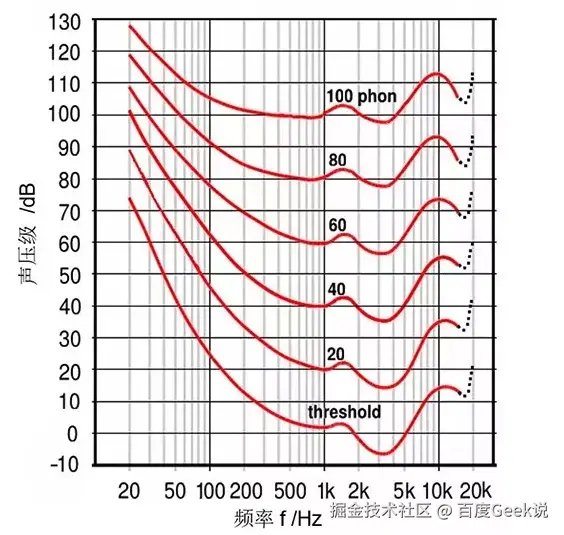
在不同响度下人耳的等响曲线
-
可以看到,不同响度下的"等响曲线"的走势都不是完全一致的。响度越小,曲线中各个频率之间的区别就越大,而响度越大,曲线就越趋于平缓,各个频率之间的区别就越小
-
人耳对于中频的敏感度要高于低频,而这种敏感度之间的差距会随着响度的增加而减小
丨2. 移动设备重低音方案选型
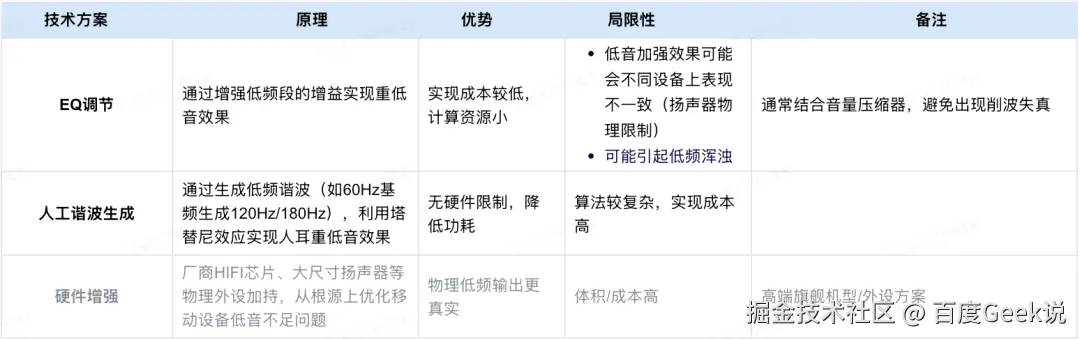
2.1 基于均衡器的低频调整
- 原理与实现:
频段划分:通过提升均衡器(Equalizer, EQ)低频段(比如20Hz-200Hz)的增益值直接增强低频信号幅度,例如,将 50Hz-80Hz 频段提升 +3dB~+6dB 可显著增强低音冲击力
- 技术特点:
线性处理,仅改变幅度,不产生谐波
需结合音频压缩器,避免出现削波失真、爆音等case
文件1(原始)
文件2(低音加强)
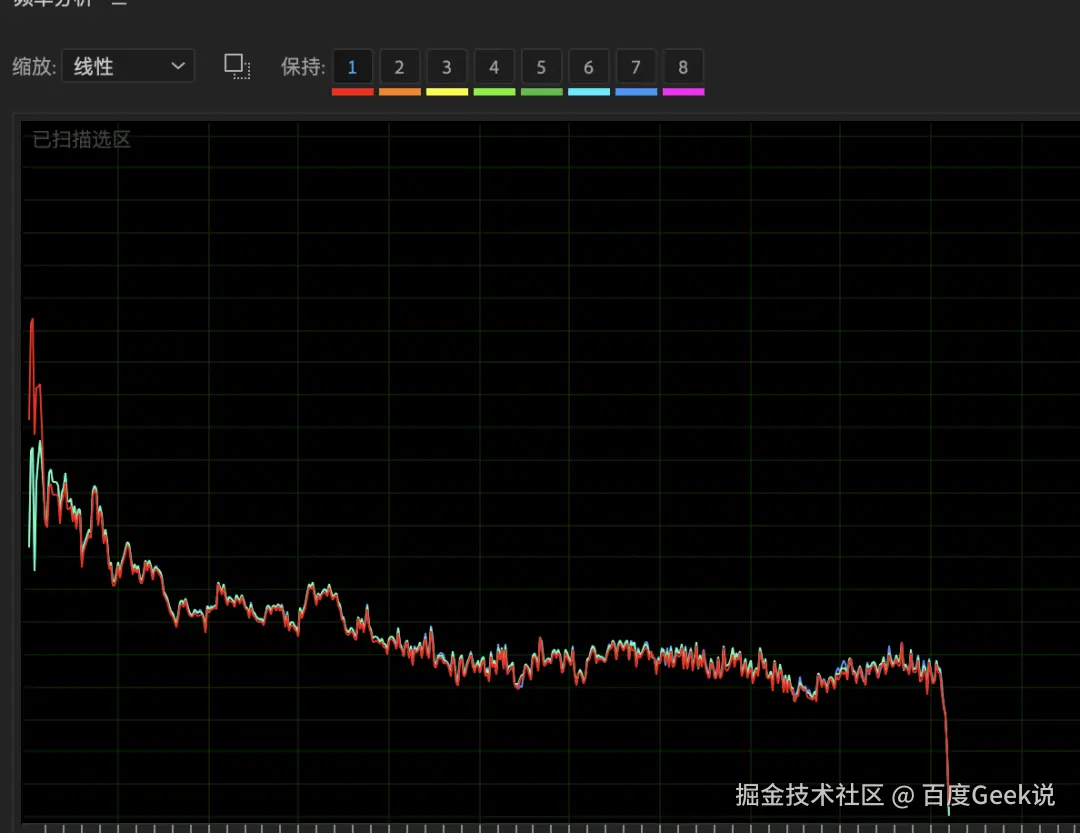
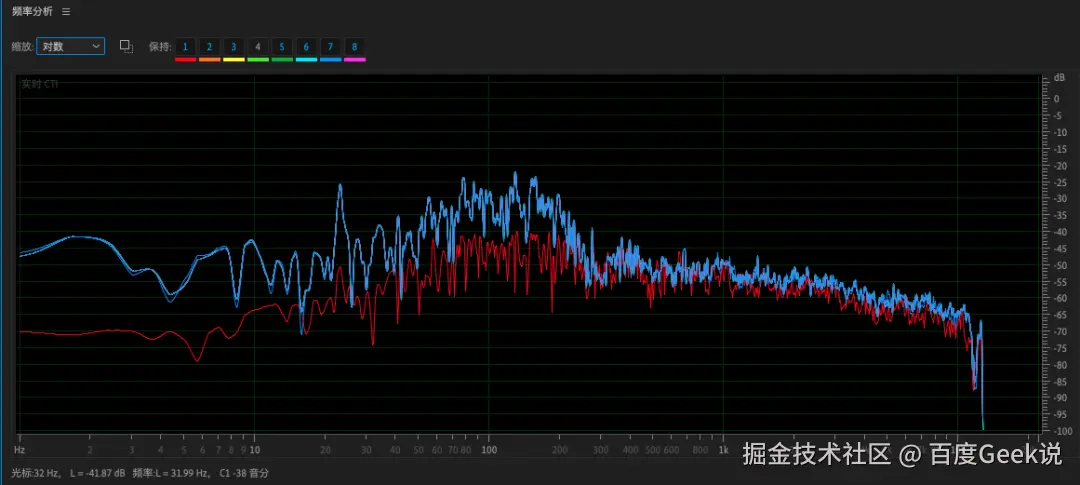
2.2 谐波生成与心理声学效应
核心原理:
-
一般认为音调应该是由以最低频率为基波决定的,谐波成分则决定音色
-
通过非线性信号处理生成低频信号的谐波成分(如60Hz基频生成120Hz、180Hz谐波),利用人耳的塔替尼效应(Tartini Effect)
-
当多个高频谐波存在时,大脑会"脑补"出缺失的基频(如120Hz+180Hz谐波组合可让人感知到虚拟的60Hz)
音频文件示例:
下面是两首曲听起来只是音色不同,但音调是一致的
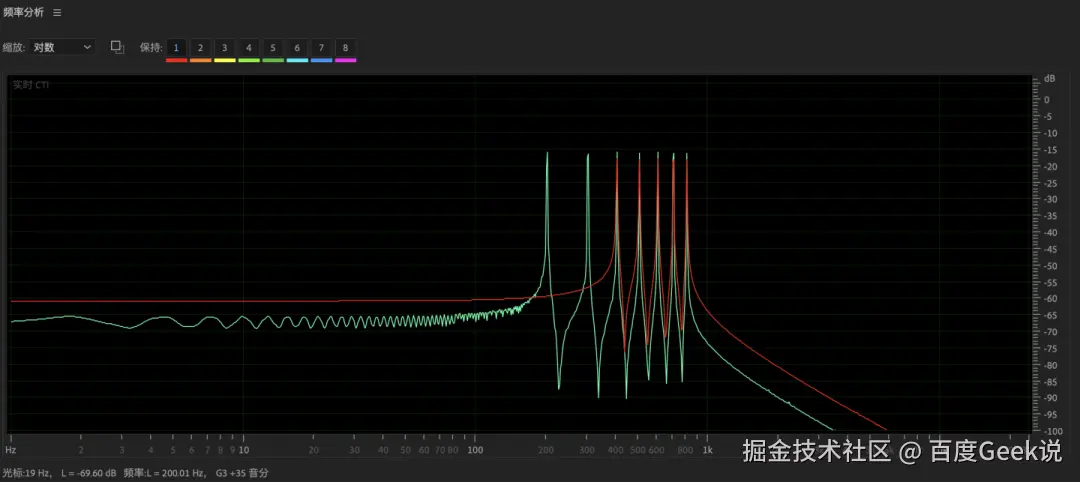
2.3 方案对比
丨3. 移动播放器重低音效果实现
3.1 现有技术局限
-
EQ直接提升
-
在低频段直接增加增益,易引发共振,引发"嗡嗡声"或"轰鸣感"
-
移动设备喇叭尺寸和功率限制,低频段增益效果一般
-
动态控制缺失:缺乏压缩和限制机制,易造成信号削波
3.2 技术目标
开发一款基于FFmpeg的高性能低音增强滤镜,实现以下功能:
-
分频处理:精准分离低频与高频信号,避免处理干扰
-
谐波增强:通过可控谐波生成方案,提升低频感知
-
动态均衡:结合前置/后置EQ与压缩器,优化频响与动态范围
-
参数可调:支持分频点、激励强度、混合比等灵活配置
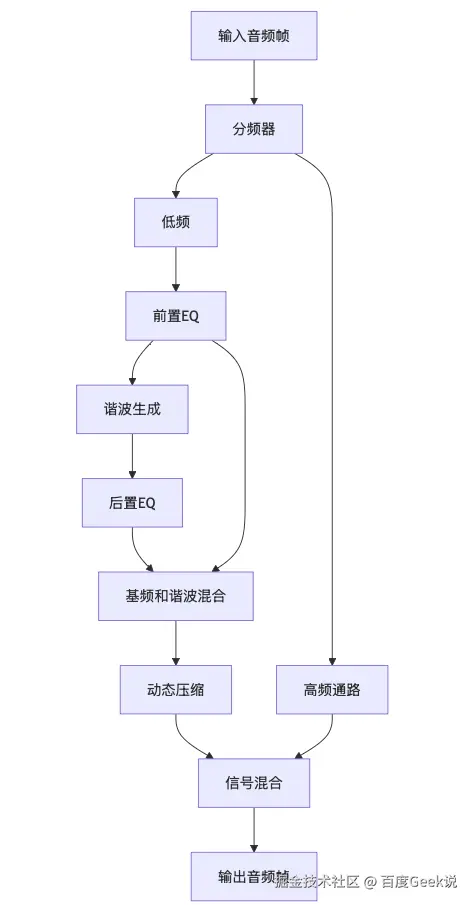
3.3 系统架构
3.4 核心模块详解
3.4.1 分频器模块
功能:将输入信号分割为低频和高频
技术实现:
-
滤波器类型:4阶Linkwitz-Riley分频器,由2个双二阶滤波器级联
-
相位对齐:低通与高通采用相同极点,保证分频点处相位连续
-
关键代码:
arduino
// 分频器系数计算(design_crossover函数)
const double w0 = 2.0 * M_PI * s->cutoff / s->sample_rate;
const double alpha = sin(w0) / (2.0 * sqrt(2.0)); // Butterworth Q值
// 低通与高通系数通过频谱反转生成3.4.2 前置EQ模块
功能:对分频后的低频信号进行预增强
技术实现:
-
滤波器类型:低架滤波器(Low Shelf),截止频率为cutoff * 0.8
-
增益公式:半功率增益计算(pre_gain/40),避免过度提升
-
代码片段:
ini
const double A = pow(10.0, s->pre_gain / 40.0);
const double omega = 2 * M_PI * s->cutoff * 0.8 / s->sample_rate;
// 低架滤波器系数计算(包含sqrt(A)项)3.4.3 谐波生成器
功能:通过非线性失真生成奇次谐波,增强低频感知
算法设计:
-
三阶多项式软化:shaped = x - (x^3)/6,生成3次、5次谐波
-
抗混叠处理:shaped *= 1/(1 + |x|*2),抑制高频噪声
-
直流偏移消除:return shaped - input*0.15
arduino
double generate_harmonics(double input, double drive) {
double x = input * drive;
// ...(非线性处理)
}3.4.4 后置EQ模块
功能:补偿谐波生成后的频响失衡
技术实现:
-
滤波器类型:高架滤波器(High Shelf),截止频率为cutoff * 1.2
-
增益公式:全功率增益计算(post_gain/20),直接调整整体电平
-
代码片段:
ini
const double A = pow(10.0, s->post_gain / 20.0);
const double omega = 2 * M_PI * s->cutoff * 1.2 / s->sample_rate;
// 高架滤波器系数计算(简化公式)3.4.5 动态压缩器
功能:防止增强后的低频信号过载
算法设计:
-
RMS检测:跟踪信号包络,计算动态增益
-
对数域压缩:阈值(COMP_THRESHOLD)设为-4dB,压缩比由drive参数动态调整
-
平滑过度:一阶IIR滤波器平滑增益变化,避免"抽吸效应"
代码逻辑:
scss
double compressor_process(...) {
// Attack/Release系数计算
const double coeff = (input^2 > envelope) ? attack_coeff : release_coeff;
// 增益平滑
s->ch_state[ch].gain = 0.2 * old_gain + 0.8 * target_gain;
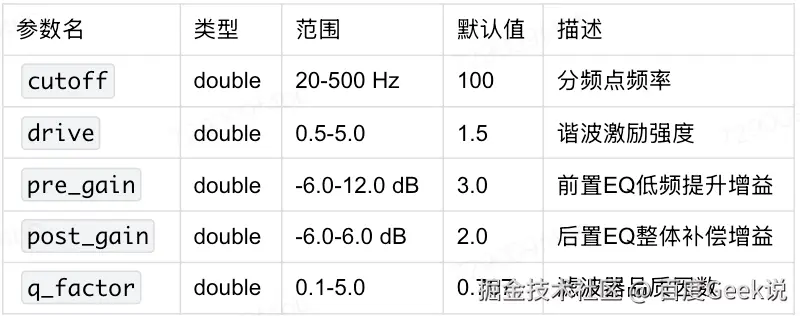
}3.4.6 配置参数表
五. 落地音效二:清晰人声
清晰人声结合频段增强、人声掩码与背景音抑制技术,能有效提升对白清晰度,在嘈杂或背景音复杂的场景下保持语音主干突出。为了更好地了解清晰人声的实现,本节将从音效的整体处理流程、滤波器设计细节、关键滤镜链搭建方式以及实现效果进行详细的介绍。
丨1. 技术原理
为了增强音频中人声的清晰度,对音频的处理主要分为四步:
-
识别并隔离主要说话者的声音,并进行语音放大
-
识别并减少各种类型的背景噪音
-
通过调整频率平衡来提高语音清晰度
-
应用精细的压缩和均衡来提高整体音频质量
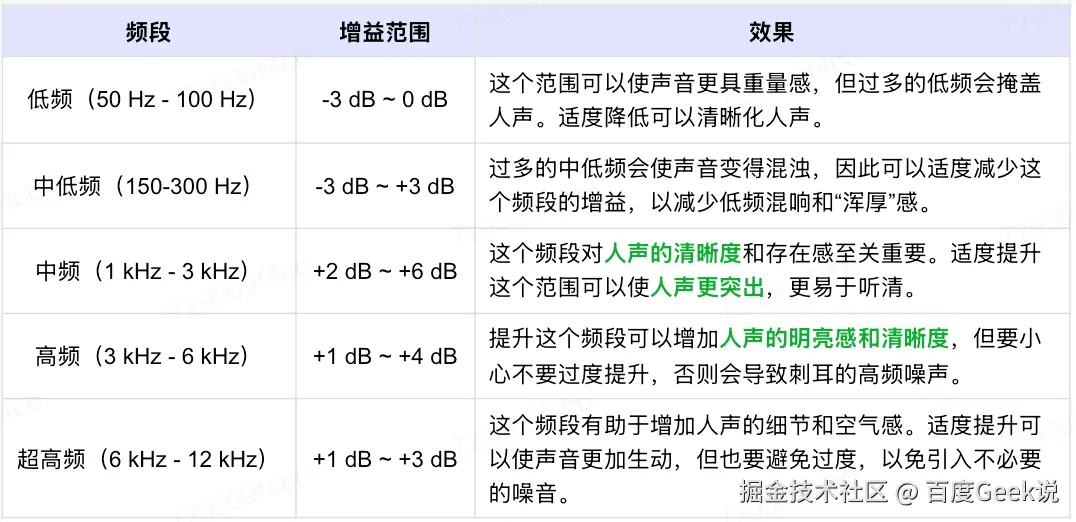
要调整音质以使人声更加清晰,通常需要在EQ中进行一些特定的频率调整。以下是一些常见的频率和增益设置及其效果,这些设置有助于提高人声(通常在300Hz~3kHz)的清晰度:
丨2. Dialoguenhance
FFmpeg中有一个可以用来增强立体声对话的音频滤镜,称为dialoguenhance。接下来,将对dialoguenhance滤镜进行一下整体的介绍,随后便详细地介绍一下该滤镜的设计细节,以及播放内核关键滤镜链的搭建方式。
2.1 滤镜介绍
Dialoguenhance滤镜接受立体声输入并生成环绕声(3.0声道)的输出。新生成的前置中置声道会强化原本在两个立体声声道中都存在的语音对话,同时前置左声道和右声道的输出则与原立体声输入相同。
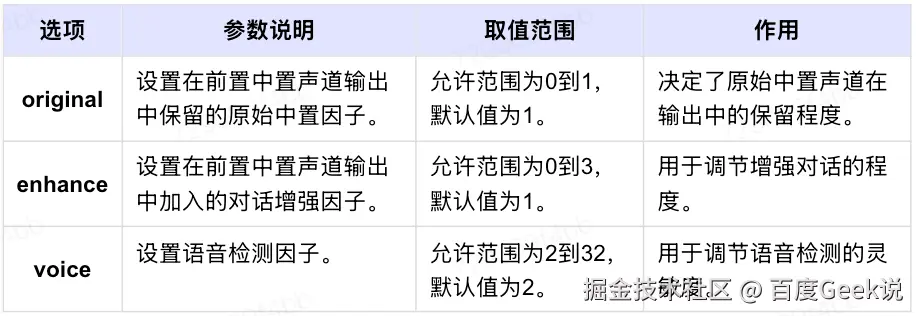
该滤镜提供了3个选项,分别是original、enhance、voice。下列表格中展现了这三个参数的说明、取值范围以及其作用。
2.2 实现原理
filter_frame函数是FFmpeg大多数滤镜的核心处理函数,主要包含以下步骤:
-
第一步,接收原音频帧输入,并进行参数初始化。
-
第二步,对输入进行加窗处理,从而减少频谱泄露。
-
第三步,执行傅里叶变换,将音频输入信号从时域转化成频域。
-
第四步,对音频信号进行算法处理,这个是各个滤镜的核心部分。
-
第五步,执行傅里叶逆变换,将处理后的音频信号从频域转化为时域。
-
第六步,处理立体声信号,将其转换为处理后的信号,处理后的音频被组合并输出。协调整个滤镜过程,管理缓冲区并执行必要的变换和增强。
-
第七步,根据输入的参数和属性配置滤镜。
-
第八步,激活滤镜。
以dialoguenhance为例,以下展现了filter_frame函数的源代码。
ini
static int filter_frame(AVFilterLink *inlink, AVFrame *in)
{
AVFilterContext *ctx = inlink->dst;
AVFilterLink *outlink = ctx->outputs[0];
AudioDialogueEnhanceContext *s = ctx->priv;
AVFrame *out;
int ret;
out = ff_get_audio_buffer(outlink, s->overlap);
if (!out) {
ret = AVERROR(ENOMEM);
goto fail;
}
s->in = in;
s->de_stereo(ctx, out);
av_frame_copy_props(out, in);
out->nb_samples = in->nb_samples;
ret = ff_filter_frame(outlink, out);
fail:
av_frame_free(&in);
s->in = NULL;
return ret < 0 ? ret : 0;
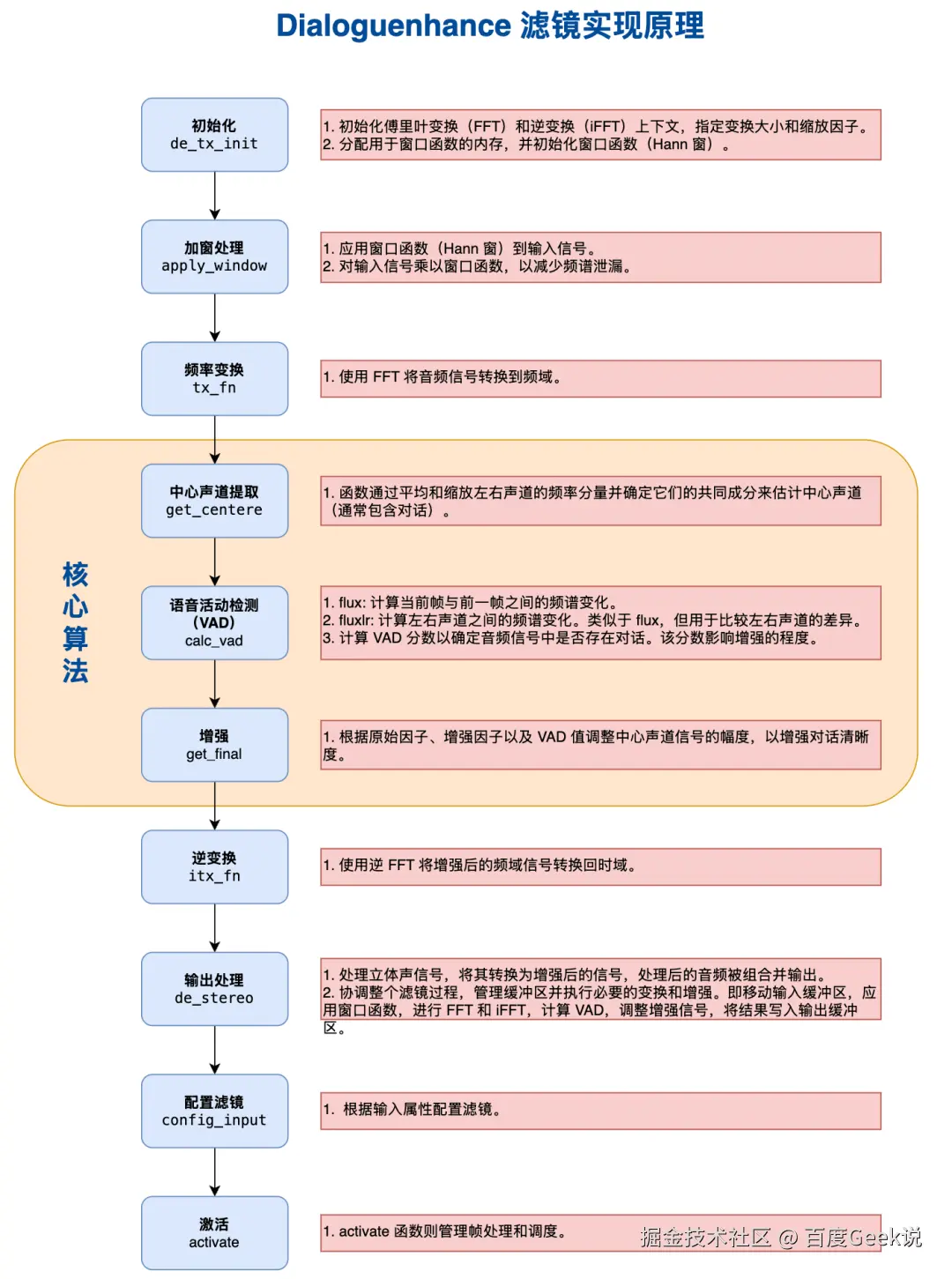
}Dialoguenhance滤镜是通过处理立体声音频信号并提取通常包含在中心声道中的对话内容来增强音频对话的,其核心算法处理包括对音频数据进行中心声道处理、语音活动检测、语音增强等步骤。下图展现了dialoguenhance滤镜的工作原理及其对应的代码模块功能:
丨3. 工程实现
对于播放内核而言,为接入dialoguenhance滤镜,主要包含以下两个重要的工程实现:
- 第一个是dialoguenhance滤镜的初始化以及获取滤镜的上下文。在播放内核的工程实现中,确定好了dialoguenhance各个选项的具体参数。
scss
#include "dialoguenhance_filter.h"
PLAYER_CORE_NAMESPACE_BEGIN
AVFilterContext* DialoguenhanceFilter::getAVFilterContext() {
return _avFilterContext;
}
int DialoguenhanceFilter::initFilter(AVFilterGraph* graph, AudioBaseInfo* audioBaseInfo, const JsonUtils::Value* param) {
AUDIOSCOPEDEBUG();
_avFilter = (AVFilter*)avfilter_get_by_name("dialoguenhance");
if (!_avFilter) {
LOGD("dialoguenhance filter not found");
return -1;
}
_avFilterContext = avfilter_graph_alloc_filter(graph, _avFilter, "dialoguenhance");
if (!_avFilterContext) {
LOGD("dialoguenhance filter context alloc failed");
return -1;
}
// 参数设置
av_opt_set_double(_avFilterContext, "original", 0, AV_OPT_SEARCH_CHILDREN);
av_opt_set_double(_avFilterContext, "enhance", 2, AV_OPT_SEARCH_CHILDREN);
av_opt_set_double(_avFilterContext, "voice", 16, AV_OPT_SEARCH_CHILDREN);
int result = avfilter_init_str(_avFilterContext, nullptr);
if (result < 0) {
LOGD("dialoguenhance filter init failed");
return -1;
}
return 0;
}
PLAYER_CORE_NAMESPACE_END- 第二个是将dialoguenhance滤镜接入播放内核音频后处理模块的滤镜链中。
ini
void AudioFrameProcessorElement2::init_filter_list(const std::string& filterType,const JsonUtils::Value* param){
std::shared_ptr<IAudioFilter> filterPtr = nullptr;
if (filterType == kAudioSrc){
filterPtr = std::make_shared<SrcFilter>(kAudioSrc);
}
else if (filterType == kAudioSink){
filterPtr = std::make_shared<SinkFilter>(kAudioSink);
}
else if (filterType == kAudioVolume){
filterPtr = std::make_shared<VolumeFilter>(kAudioVolume);
}
else if (filterType == kAudioRaiseVoice){
filterPtr = std::make_shared<DialoguenhanceFilter>(kAudioRaiseVoice);
}
if(filterPtr->initFilter(_filter_graph,_audio_base_info,param) == 0){
_filter_list.push_back(filterPtr);
}
}丨4. 实现效果
处理前:
处理后:
大家可以对比感受上面处理前/后效果。
- 第一组效果
处理前:背景音乐和人声音量差不多。
处理后:人声相对于背景音乐更加突出,对话内容更加清晰。
- 第二组效果
处理前:音乐和人声较平,音量差别不大。
处理后:人声相对于处理前更加清晰和突出,明显增强。音乐沉浸感也比处理前效果更好。
六. 小结
本文围绕播放器音频后处理中的重低音与清晰人声两种典型音效处理,简要介绍了其实现逻辑、关键参数控制策略,以及在播放链路中的集成方式。这两种处理在实际应用中具备较强的通用性,适用于大多数通用内容场景。
后续文章将继续分享更多音频后处理技术实践,敬请关注。