01|原声视频翻译背景介绍
大家好,我们是 BILIBILI Index 团队。
最近,我们上线了一个新能力:支持将部分中文视频翻译为外语的原声风格配音。也就是说,观众现在可以听到"这个人用另一种语言在说话",但他的声音、语气、节奏,甚至个性表达都和原片几乎一致,不再是那种传统配音里千篇一律的"代言人声线",而是像本人亲自讲外语一样自然。这背后,其实是一整套跨模态、多语言协同生成系统的能力升级。
这一系列技术探索的出发点,源于一个日益迫切的需求:随着视频内容全球化的深入,多语言传播已成为连接文化与社群的关键载体。观众不再满足于"听懂",而是追求"真实感"与"在场感"------希望听到原声的情绪起伏、看到口型与语音的自然匹配;创作者也愈发意识到,声音不仅是信息的载体,更是人格表达与情感共鸣的核心媒介。
要实现真正沉浸式的跨语言体验,必须突破当前本地化流程中的关键限制,其中最具代表性的是以下三类挑战:
- 声音人格的缺失: 传统配音虽解决语言障碍,却抹去了创作者独特的音色、语调与口音------这些正是"谁在说话"的核心标识。在人格化传播时代,声音是IP的重要组成部分。一旦被标准化配音取代,情感连接断裂,影响力随之衰减。
- 避免字幕的认知负担: 字幕将声音降维为文字,丢失语气、情绪与节奏,削弱内容表现力。同时,"听音+读字"的双模输入造成注意力割裂,尤其在高密度知识类或沉浸式内容中,严重影响理解效率与观看体验。
- 降低本地化的成本壁垒: 多语言制作依赖复杂的人工流程:配音、对轨、混音、校对......每增一语种,成本指数级上升。中小创作者难以承担,全球化沦为少数人的特权。
在本文中,我们将系统性地介绍该能力的技术架构与核心挑战,并分享我们在实践中如何逐步实现这些目标。
02|面向感知一致性的语音生成建模
传统TTS系统通常以语音自然度、可懂度和音色相似度为主要优化目标,缺乏对原始听觉场景的多维建模能力。而视频级语音翻译本质上是感知一致性重建 ,需协同建模三个关键维度:说话人身份特征 、声学空间属性 ,以及多声源时频结构,方能实现听觉体验的完整迁移。
-
说话人身份特征重建: 传统配音常因使用固定配音演员或通用声库,导致合成语音与原演员声线错位,这种"音色失真"让原本角色的语气、个性和表现力都被弱化。针对这一问题,我们自研的 BILIBILI IndexTTS2 重点在视频语音翻译场景保持高精度音色克隆,仅通过原语音中的少量信息,就在发声质感与语用风格上高度还原原始说话人特征。
-
声学空间属性保留: 人对声音的空间属性存在潜意识感知,包括混响特性、麦克风距离与环境噪声等,共同构成空间上的听觉线索。这种由混响、空间残响、麦克风距离、背景噪声等构成的声学环境信息,也是构建听感真实性的重要因素。BILIBILI IndexTTS2的另一个特色就是可以保留原始声场特征,这种声场一致性,能显著提升听觉连贯性,避免"脱场感"。
-
多声源时频结构融合: 原始音轨中的人声、背景音乐与环境音共同构建了动态的听觉节奏与情绪张力。为避免简单替换导致的感知断裂,我们在音频合成时,结合了人声、背景声、音乐等进行感知加权重建,尽可能的贴合原片的听感。
2.1 一体化解决跨语言音色一致、情绪迁移难以及语速控制的问题
在真实的视频翻译场景中,想要实现一套完整且自然的"原声风格"翻译体验,仅仅将内容翻译成目标语言远远不够。我们真正要解决的,是在语音生成层面,跨语言地保留说话人的"声音个性",并同时维持语气情绪的一致性和语速节奏的自然过渡。这背后隐藏着多个技术层面的挑战:
- 音色的一致性在跨语言场景中天然存在缺口。许多传统语音合成系统在迁移语言时,容易将说话人的音色"带偏"------比如中文中圆润的发音特征,迁移到英语后容易变尖、偏硬,导致"听起来像是另一个人在说话"。这种音色偏差破坏了原声重建的核心感知基础。
- 情绪迁移难以量化控制。说话人原本的语气、态度、语义强调,在不同语言中表达方式不同。例如中文中"质疑"可能通过语调变化呈现,而在英文中则依赖更多语法和节奏结构。一旦模型缺乏对原始情绪结构的建模能力,就会生成语气单一、缺乏感染力的声音输出,观感显著下降。
- 语速控制在翻译重建中格外复杂。不同语言的表达长度差异大,同一句话用英文讲可能比中文长 30%以上,而原视频的音轨时长是固定的。这就要求模型具备跨语言节奏预测和信息压缩能力,否则就容易出现"语速过快听不清"或"说完提前停顿"等违和现象。
这些问题在原声翻译中常常不是孤立发生,而是交织叠加,互相放大。例如音色偏移会削弱情绪的传达能力,情绪错误又会进一步放大语速与节奏的突兀感,最终导致整段配音听起来"假"、"不自然"。
因此,我们在系统设计上,必须从前端建模、音色编码、跨语言对齐,到语速调控与声音合成,全流程协同建模、统一优化,才能真正实现原声风格的跨语言还原。
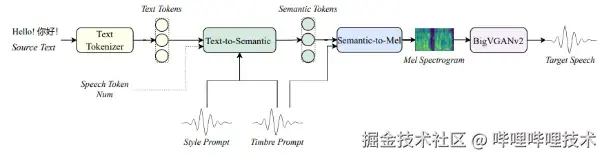
BILIBILI IndexTTS2模型架构
在 BILIBILI IndexTTS2 中,我们创新性地提出了一种通用于 AR 系统的"时间编码"机制,首次解决了传统 AR 模型难以精确控制语音时长的问题。这一设计让我们在保留 AR 架构在韵律自然性、风格迁移能力、多模态扩展性等方面优势的同时,也具备了合成定长语音的能力。
BILIBILI IndexTTS2 引入了音色与情感解耦建模机制,处理支持单音频参考以外,额外支持分别指定音色参考与情感参考,实现更加灵活、细腻的语音合成控制。同时,模型还具备基于文本描述的情感控制能力,可通过自然语言描述、使用场景描述、上下文线索等进行精准调节合成语音的情绪色彩。
这种架构使得 BILIBILI IndexTTS2 在跨语言合成中具备了高度的表现力,无论何种语言系统都能够将原语音中人物的个性与情绪自然地注入到目标语言的语言中,实现保音色、保情感、保风格的高质量视听重建。
2.2 解决观看时多角色混淆问题
在原声翻译的实际场景中,多说话人是极为常见的情况。若仅用单一说话人进行重建,会极大降低还原度,破坏视频原有的交流氛围和角色关系。然而,若要保留多说话人信息,最核心的前提就是对说话人进行精准切分。一旦说话人分割出错,不仅会影响语义理解,后续的翻译与音色合成也将受到连锁影响,使得最终结果出现严重失真。
在实际处理多说话人视频时,说话人分割面临一系列复杂挑战。传统的 diarization 方法往往假设说话人交替有清晰边界、语音持续时间较长、语音信噪比可接受,但这些假设在真实的视频场景中往往并不成立。此外,以下这些地方也都是很明显的技术挑战:
- 多说话人频繁交替且衔接紧密,有时几乎没有间隔,甚至存在明显的语音重叠,这使得边界识别变得极其困难;
- 视频中经常出现极短发言的说话人,例如仅有一两个字的"嗯""哦""对"等,虽然简短但具有语义功能,极易被模型忽略或错误归类;
- 部分角色在整段视频中只出现一两次,这些低频发言人由于缺乏充分的声纹特征支撑,在聚类阶段极易被合并至其他发言人;
- 很多视频中说话人之间声纹差异较小,加上背景音乐、环境声干扰较强,进一步增加了区分难度,许多微妙的音色特征只有人类仔细听辨才能分辨,而传统算法常常力不从心。
这些挑战叠加在一起,使得说话人分割成为原声翻译流程中最容易"牵一发而动全身"的环节, 一旦分错,不仅语义理解会出错,后续翻译和音色合成也会随之受到误导,从而在最终结果中放大错误。
为此,我们提出了一套创新的说话人分割方法,专为原声翻译场景设计。
首先,我们将语音流按语义划分为多个小粒度语义片段,再以片段为单位进行说话人聚类,从根本上缓解边界模糊与重叠干扰问题;其次,在聚类层面引入了对低频说话人识别的增强策略,重新设计聚类算法的相似性约束,避免重要但稀有的发言被忽略或合并;此外,我们对基础的说话人特征模型进行了升级,采用端到端说话人训练机制,大幅提升了在噪声背景下的说话人区分能力,使模型能更准确地捕捉个体语音特征。使得在后续的声音重建过程中,通过自动匹配原视频的混响和空间声像,让多说话人语音自然地融入视频原有环境,增强空间感、临场感与真实感,最终呈现出更加一致、和谐的视听体验。
03|面向语音对齐的跨语言语义与文化适配建模
视频原声翻译面临的核心挑战,远不止"翻译准确"这么简单。相比传统文本翻译,原声翻译模型必须同时理解上下文、语义节奏和跨文化表达,才能实现真实可信的声音重构。
-
语音节奏与信息密度的动态平衡: 不同语言在信息密度与音节速率上存在显著差异,导致等长语音承载语义量不一致。为此,翻译模块需具备时长感知能力,以原始语音时长为软约束,在语义完整前提下动态调整生成文本长度:对高密度语言进行适度扩展,对低密度语言进行压缩,确保输出文本可被自然朗读并适配目标语音节奏,避免超长或过短。
-
上下文理解与风格一致性: 翻译需建模说话人身份 、对话结构 与领域语体,以维持前后一致的表达风格。系统基于多模态语义先验识别角色指代、语气模式与语体类型,并在序列生成中保持术语使用、句式结构与情感倾向的一致性,避免角色混淆或语体漂移。
-
专有名词与文化负载词的精准适配: 对于领域术语、网络用语与文化隐喻,需结合上下文与内容类别进行细粒度消歧与适配翻译。通过构建动态术语库与上下文感知映射机制,在保持字面准确的同时保留语用功能与情感张力,确保文化负载表达在目标语言中具备等效的语境可理解性与情绪共鸣。
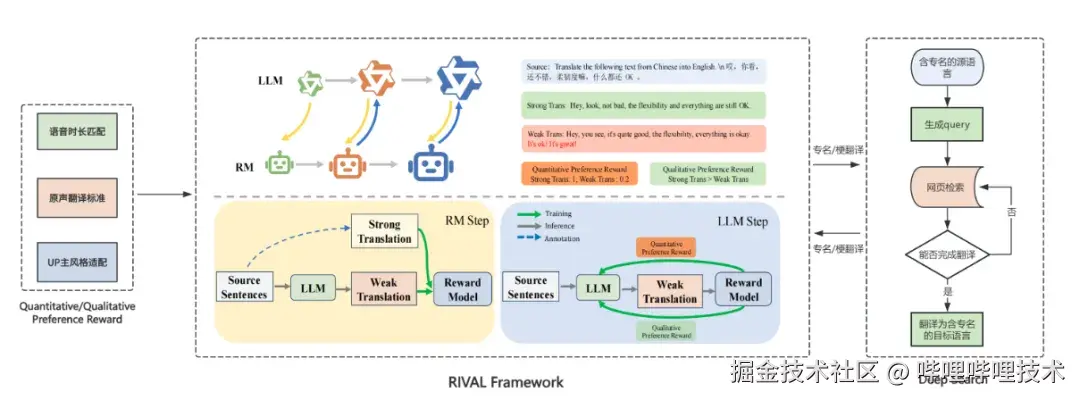
3.1 对抗式强化学习框架 RIVAL:显著提升翻译效果
在原声翻译的场景下,面临两大核心挑战:一是在精准控制语音节奏的同时,如何确保翻译的准确性、完整性与流畅性,以地道传神地传达视频内容;二是如何有效适配不同UP主风格,精准还原其个性特征,从而提升用户体验。
在应对这些挑战时,我们发现仅靠监督微调(SFT)存在泛化性局限,难以有效提升模型翻译能力;而常规强化学习(RL)则易受分布偏移影响,导致模型收敛困难。针对上述痛点,我们创新性地提出翻译领域的 RIVAL 对抗式强化学习训练框架。该框架将翻译优化过程建模为奖励模型(RM) 与大语言模型(LLM) 之间的动态博弈(min-max game),并通过双模型的迭代更新实现协同进化。
具体而言,RIVAL 框架将语音时长适配、原生翻译标准(准确性、完整性、流畅性等)以及 UP 主风格适配融入定性与定量结合的偏好奖励模型:
- 定性偏好奖励模型: 用于区分翻译结果的优劣,驱动大语言模型(LLM)通过缩小优劣模型间的差距来持续提升翻译能力。
- 定量偏好奖励模型: 通过融入语音时长、翻译统计指标等定量偏好信号,有效增强训练过程的稳定性及模型的泛化能力。
总结来看,RIVAL框架通过创新的对抗式强化学习机制,成功地将语音节奏控制、翻译质量保障(准确/完整/流畅)与个性化风格适配这三大核心挑战统一建模,利用定性与定量奖励信号的协同驱动,显著提升了翻译模型的性能上限与泛化能力,为高质量、高适配性的原声视频翻译开辟了新路径。
3.2 攻克专有名词与文化适配难题
专有名词翻译历来是翻译领域的难点。尽管大模型具备强大的知识储备与推理能力,但在处理专有名词时仍面临诸多挑战:领域知识整合效率低、低资源场景下模型偏见易放大、实时性需求与模型冻结状态相矛盾等,尤其在二次元、游戏等专有名词与"梗点"密集的领域。
为有效解决专有名词翻译的核心痛点,我们提出 Deep Search 深度挖掘技术方案。该方案针对难以翻译的专有名词案例,通过生成查询(query)→ 实时网页检索 → 总结翻译的流程,动态获取精准译文。同时,结合领域知识的实时嵌入,显著提升专有名词翻译的准确性。
04|面向音画对齐的视频信息重建
在完成音频层面的感知一致性重建后,系统需进一步解决视听模态间的时间对齐与空间一致性问题 。视频翻译中的语音替换打破了原始音画耦合关系,若不进行联合建模,将引入显著的跨模态失配。为此,我们形式化两个关键子任务:字幕区域的语义-视觉解耦重建 与音频驱动的唇形时序生成,实现从语音到画面的端到端视觉对齐。
-
字幕区域的多模态定位与修复: 翻译后的音频内容与原始字幕在语言、节奏与时间轴上均不再匹配,保留原字幕不仅会造成语言上的混淆,还会破坏视觉上的沉浸感。因此,我们开发了多模态内容理解大模型与传统OCR模型的协同架构,对字幕区域进行精确定位和擦除,最大限度还原真实场景。
-
基于音频驱动的高保真唇形同步: 此外,翻译后的语音在时长、节奏、音节构成上必然与原语音存在显著差异,这导致重建后的音频与原视频画面中的人物口型动作无法对齐,产生了明显的"唇语不同步" 现象,这种不协调感会极大地分散观众的注意力,破坏真实感。因此,我们基于生成模型开发了唇形同步技术,使用diffusion基座动态生成与音频精确匹配的口型画面,同时,引入参考网络机制保证人物ID的还原,确保生成的口型适配人物原貌,在视觉上高度保真。
4.1 消除原始字幕
翻译后的音频在时间轴上与原视频字幕完全脱节,保留原字幕会造成严重的语言混淆和视觉割裂感,我们需要做到精准地消除原字幕。核心需要解决两大问题:一是精准识别与区分,需要将画面中所有字幕区域无遗漏、无错判地定位出来,这在字幕与背景文字、水印、图标等干扰信息混合时尤其困难;二是尽可能确保帧间的一致性,避免由于相邻帧的不一致而出现的字幕闪现,严重影响观看体验。
针对这些难点,我们设计了一套多模态感知与跨帧协同的技术方案。首先,在单帧字幕感知方面,构建了异构模型协同架构,深度融合多模态大模型在语义理解与内容分类上的高阶认知能力与传统OCR模型在空间定位上的像素级精度优势。 并针对出海内容场景特性,进一步实施了基于领域知识的Prompt优化,实现了字幕与非字幕文字区域的精准区分。其次,为提高帧间一致性,对擦除区域进行了三个维度的跨帧平滑:分别是OCR的位置结果与大模型字幕识别的跨帧匹配、大模型字幕识别不匹配OCR位置时的跨帧位置推断,以及短暂区间未检测到字幕区域时的补全。

4.2 口型对齐
在原声翻译链路中,口型驱动的技术则是基于生成模型开发的。整体流程为输入下半张脸mask的视频、参考视频以及音频,基于音频生成相对应的更换口型的视频。在B站自研的技术方案中,视频编解码器采用3D VAE来提供更强的时序特征,可以减少嘴唇、牙齿的抖动;增加了参考网络用来加强ID的生成能力,可以生成高保真的唇形同步片段。此外,基于diffusion的基座能力,整体生成效果对于大角度、遮挡的鲁棒性更好,可扩展性也更强。
翻译后的音频与视频中人物原有的口型动作会出现不同步的现象,这种视听割裂感会极大分散观众注意力,破坏真实感和沉浸感。高度同步的口型驱动技术面临几个核心难点:一是身份的保持,在改变口型的同时,必须严格保持说话人的身份特征(ID),确保生成的下半脸看起来仍然是原人物;二是动态鲁棒性,需要处理各类复杂内容情况(e.g. 头部大角度转动、遮挡、频繁切镜)下的稳定口型生成。
因此,我们采用Diffusion模型作为生成基座,开发了高保真、强鲁棒的口型驱动技术。在人脸编码部分,使用 3D VAE更好地捕捉视频的时序特征进行建模,显著减少了嘴唇变色、牙齿抖动的难点。同时,引入参考网络 (Reference Network) 机制,学习提取并注入原始人物面部的身份特征信息,确保生成画面严格匹配原人物特征,视觉上自然真实。此外,diffusion的基座能力在处理头部转动、遮挡等复杂场景时表现稳定,可扩展性也更强。
05|结语
如今,内容的跨语言传播正日益与个体表达深度融合。从观众自发的字幕协作,到创作者对多语言表达的主动探索,人们不再满足于单纯的语言转换,而是更加关注声音背后的真实语调、情感特质与文化语境。一种强调语言多样性与表达原真性的创作趋势正在显现------声音本身,正成为意义的一部分。
然而,在迈向全球传播的过程中,我们也必须正视现实挑战:传统配音在解决语言障碍的同时,也在无形中抹去了声音个性与文化基因;字幕虽是信息桥梁,却常常成为认知干扰源,削弱沉浸体验与艺术表达;而高昂的本地化成本,则成为中小创作者难以跨越的门槛,限制了内容出海的可能性。面对这些问题,技术正在成为关键的破局者。未来的原声翻译系统,不仅要实现语言层面的精准转换,更要做到声音个性的保留、情绪张力的还原、文化语境的适配。
为了更好地覆盖多样化内容生态,我们在面向UGC场景时,关注创作者和消费者的需求,未来将支持更多语言,助力全球多语言交流。同时,针对PGC场景,我们设计了更加严谨和可控的工作流程与技术方案,保障高质量、多语言、跨模态的视听语言迁移体验,实现内容的专业呈现与高效制作。我们也计划将BILIBILI IndexTTS2模型开源,期待推动整个行业技术进步,欢迎大家持续关注与使用!
我们正站在一个内容无界、声音有温度的新起点。当技术不再只是工具,而是成为表达的一部分,我们才真正迎来一个既听得懂语言、也听得见灵魂的全球内容生态。也欢迎更多 AI 研究者、内容创作者、产品开发者与我们一起打磨这项技术。
体验地址: m.bilibili.com/topic-detai...
本文参考:
2506.21619 IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech(*arxiv.org/abs/2506.21...
2506.05070 RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation(*arxiv.org/abs/2506.05...
-End-
作者丨Index团队