推理模型:探索高级推理和问题解决模型
推理模型 (如 o3 和 o4-mini)是通过强化学习训练的大型语言模型,专门用于执行推理任务。推理模型会在回答前进行思考,在响应用户之前生成长长的内部思维链。这类模型在复杂问题解决、编码、科学推理和代理工作流的多步骤规划方面表现出色,也是Codex CLI(我们的轻量级编码代理)的最佳选择模型。
与我们的 GPT 系列一样,我们提供更小、更快的模型(o4-mini 和 o3-mini),这些模型每 token 的成本更低;而更大的模型(o3 和 o1)速度较慢且成本更高,但在复杂任务和广泛领域中通常能生成更好的响应。
为确保最新推理模型 o3 和 o4-mini 的安全部署,部分开发者可能需要完成组织验证才能访问这些模型。可在平台设置页面开始验证流程。
推理模型入门
推理模型可通过响应 API 使用,如下所示:
在响应 API 中使用推理模型
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const prompt = `
编写一个 bash 脚本,该脚本接收一个以 '[1,2],[3,4],[5,6]' 格式表示的矩阵字符串,并以相同格式打印其转置矩阵。
`;
const response = await openai.responses.create({
model: "o4-mini",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
prompt = """
编写一个 bash 脚本,该脚本接收一个以 '[1,2],[3,4],[5,6]' 格式表示的矩阵字符串,并以相同格式打印其转置矩阵。
"""
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "medium"},
input=[
{
"role": "user",
"content": prompt
}
]
)
print(response.output_text)
bash
curl https://api.aaaaapi.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o4-mini",
"reasoning": {"effort": "medium"},
"input": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以 \"[1,2],[3,4],[5,6]\" 格式表示的矩阵字符串,并以相同格式打印其转置矩阵。"
}
]
}'在上面的示例中,reasoning.effort 参数指导模型在生成对提示的响应之前生成多少推理 token。
此参数可指定为 low、medium 或 high,其中 low 更注重速度和经济的 token 使用,high 则更注重更完整的推理。默认值为 medium,这是速度和推理准确性之间的平衡。
推理工作原理
推理模型除了输入和输出 token 外,还引入了推理 token。模型使用这些推理 token 进行"思考",分解提示并考虑生成响应的多种方法。生成推理 token 后,模型会生成可见的完成 token 作为答案,并从其上下文中丢弃推理 token。
以下是用户和助手之间多步骤对话的示例:每一步的输入和输出 token 都会被保留,而推理 token 则会被丢弃。
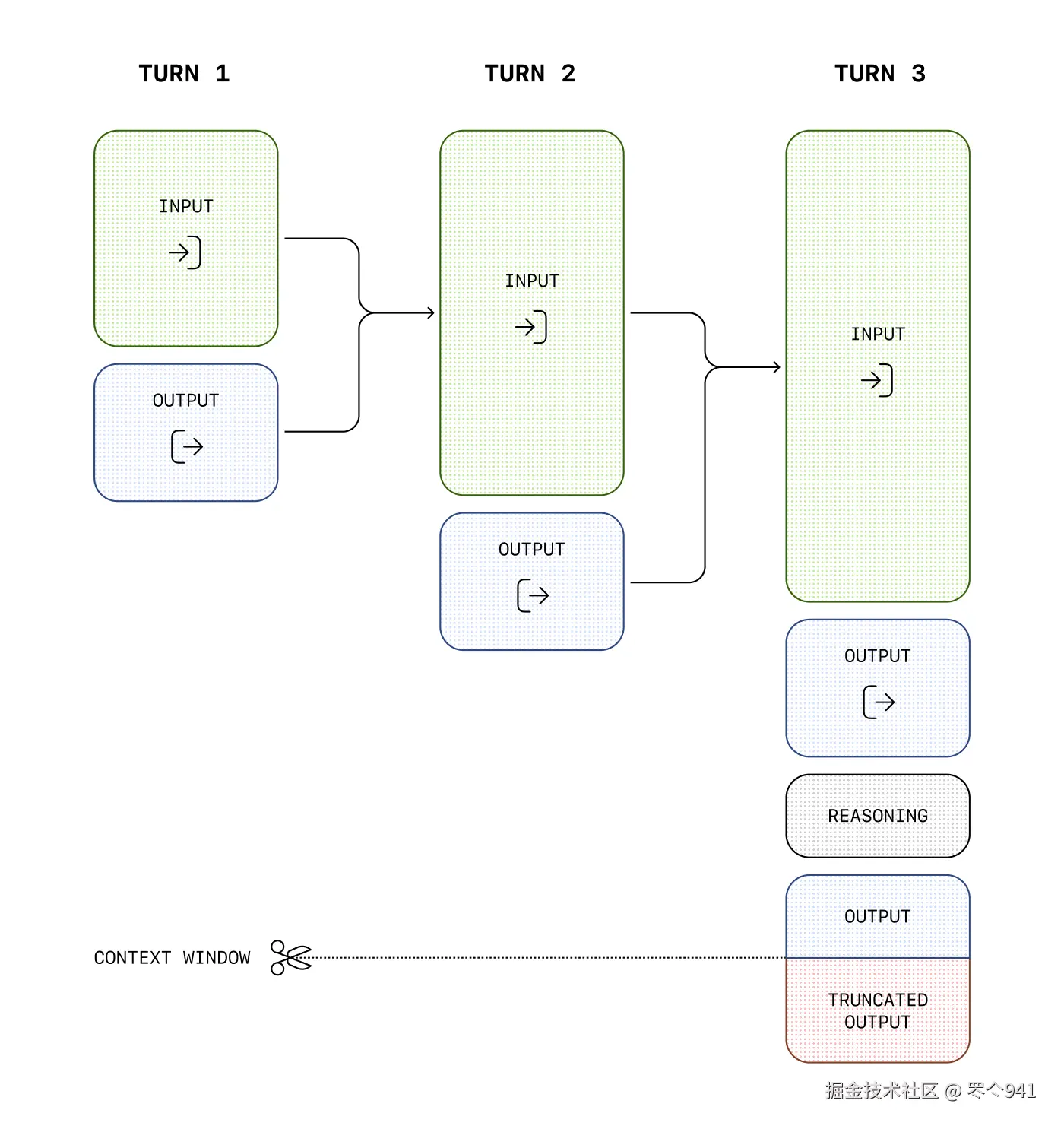
虽然推理 token 无法通过 API 看到,但它们仍然占用模型上下文窗口的空间,并按输出 token 计费。
管理上下文窗口
创建响应时,确保上下文窗口中有足够的空间容纳推理 token 非常重要。根据问题的复杂性,模型可能生成数百到数万个推理 token。使用的推理 token 的确切数量可在响应对象的使用情况对象中的 output_tokens_details 下查看:
json
{
"usage": {
"input_tokens": 75,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 1186,
"output_tokens_details": {
"reasoning_tokens": 1024
},
"total_tokens": 1261
}
}上下文窗口长度可在模型参考页面中找到,不同的模型快照会有所不同。
控制成本
如果在模型轮次中手动管理上下文,可以丢弃较旧的推理项,除非你正在响应函数调用,在这种情况下,你必须包含函数调用和最后一条用户消息之间的所有推理项。
要管理推理模型的成本,可以使用 max_output_tokens 参数限制模型生成的总 token 数(包括推理和最终输出 token)。
为推理分配空间
如果生成的 token 达到上下文窗口限制或你设置的 max_output_tokens 值,你将收到一个 status 为 incomplete 且 incomplete_details 中 reason 设置为 max_output_tokens 的响应。这可能在生成任何可见输出 token 之前发生,这意味着你可能会为输入和推理 token 支付费用,但不会收到可见响应。
为防止这种情况,请确保上下文窗口中有足够的空间,或将 max_output_tokens 值调整为更高的数字。OpenAI 建议在开始试用这些模型时,至少为推理和输出预留 25,000 个 token。当你熟悉提示所需的推理 token 数量后,可以相应地调整此缓冲区。
处理不完整响应
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const prompt = `
编写一个 bash 脚本,该脚本接收一个以 '[1,2],[3,4],[5,6]' 格式表示的矩阵字符串,并以相同格式打印其转置矩阵。
`;
const response = await openai.responses.create({
model: "o4-mini",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
max_output_tokens: 300,
});
if (
response.status === "incomplete" &&
response.incomplete_details.reason === "max_output_tokens"
) {
console.log("token 耗尽");
if (response.output_text?.length > 0) {
console.log("部分输出:", response.output_text);
} else {
console.log("推理过程中 token 耗尽");
}
}
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
prompt = """
编写一个 bash 脚本,该脚本接收一个以 '[1,2],[3,4],[5,6]' 格式表示的矩阵字符串,并以相同格式打印其转置矩阵。
"""
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "medium"},
input=[
{
"role": "user",
"content": prompt
}
],
max_output_tokens=300,
)
if response.status == "incomplete" and response.incomplete_details.reason == "max_output_tokens":
print("token 耗尽")
if response.output_text:
print("部分输出:", response.output_text)
else:
print("推理过程中 token 耗尽")在上下文中保留推理项
在响应 API 中使用推理模型进行函数调用时,我们强烈建议你传回与最后一个函数调用一起返回的任何推理项(除了函数的输出)。如果模型连续调用多个函数,你应该传回自最后一条 user 消息以来的所有推理项、函数调用项和函数调用输出项。这使模型能够继续其推理过程,以最节省 token 的方式产生更好的结果。
最简单的方法是将先前响应中的所有推理项传入下一个响应。我们的系统会智能地忽略与你的函数无关的任何推理项,只保留上下文中相关的推理项。你可以使用 previous_response_id 参数,或将过去响应中的所有输出项手动传入新响应的输入中,来传递先前响应中的推理项。
对于你可能在将上下文窗口的部分内容传递到下一个响应之前截断和优化的高级用例,只需确保将最后一条用户消息和函数调用输出之间的所有项原封不动地传递到下一个响应中。这将确保模型拥有所需的所有上下文。
查看本指南以了解有关手动上下文管理的更多信息。
加密的推理项
在无状态模式下使用响应 API 时(要么将 store 设置为 false,要么组织已注册零数据保留),你仍然必须使用上述技术在对话轮次中保留推理项。但是,为了使推理项能够与后续 API 请求一起发送,你的每个 API 请求必须在 API 请求的 include 参数中包含 reasoning.encrypted_content,如下所示:
bash
curl https://api.aaaaapi.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o4-mini",
"reasoning": {"effort": "medium"},
"input": "今天天气怎么样?",
"tools": [ ... 此处为函数配置 ... ],
"include": [ "reasoning.encrypted_content" ]
}'现在,output 数组中的任何推理项都将具有 encrypted_content 属性,其中将包含可与未来对话轮次一起传递的加密推理 token。
推理摘要
虽然我们不公开模型发出的原始推理 token,但你可以使用 summary 参数查看模型推理的摘要。查看我们的模型文档以检查哪些推理模型支持摘要。
不同的模型支持不同的推理摘要设置。例如,我们的计算机使用模型支持 concise 摘要器,而 o4-mini 支持 detailed 摘要器。要访问模型可用的最详细摘要器,请将此参数的值设置为 auto。auto 目前对于大多数推理模型相当于 detailed,但未来可能会有更精细的设置。
推理摘要输出是输出项的 reasoning 中的 summary 数组的一部分。除非你明确选择包含推理摘要,否则不会包含此输出。
下面的示例展示了如何发出包含推理摘要的 API 请求。
在 API 响应中包含推理摘要
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const response = await openai.responses.create({
model: "o4-mini",
input: "法国的首都是什么?",
reasoning: {
effort: "low",
summary: "auto",
},
});
console.log(response.output);
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
response = client.responses.create(
model="o4-mini",
input="法国的首都是什么?",
reasoning={
"effort": "low",
"summary": "auto"
}
)
print(response.output)
bash
curl https://api.aaaaapi.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o4-mini",
"input": "法国的首都是什么?",
"reasoning": {
"effort": "low",
"summary": "auto"
}
}'此 API 请求将返回一个输出数组,其中既包含助手消息,也包含模型生成该响应时的推理摘要。
json
[
{
"id": "rs_6876cf02e0bc8192b74af0fb64b715ff06fa2fcced15a5ac",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**回答一个简单问题**\n\n我看到一个 straightforward 的问题:法国的首都是巴黎。这是一个众所周知的事实,我想保持简洁明了。巴黎以其历史、艺术和文化而闻名,所以或许可以稍微提一下这种魅力。但主要还是旨在提供清晰直接的答案,确保用户得到他们想要的信息,没有任何多余的内容。"
}
]
},
{
"id": "msg_6876cf054f58819284ecc1058131305506fa2fcced15a5ac",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"logprobs": [],
"text": "法国的首都是巴黎。"
}
],
"role": "assistant"
}
]在将摘要器与我们最新的推理模型一起使用之前,你可能需要完成组织验证以确保安全部署。可在平台设置页面开始验证流程。
提示建议
提示推理模型时需要考虑一些差异。推理模型在仅有高级指导的任务上表现更好,而 GPT 模型通常受益于非常精确的指令。
- 推理模型就像一位资深同事------你可以给他们一个目标,然后相信他们能解决细节问题。
- GPT 模型就像一位初级同事------他们在有明确的特定输出指令时表现最佳。
有关使用推理模型的最佳实践的更多信息,请参考本指南。
提示示例
编码(重构)
OpenAI o 系列模型能够实现复杂算法并生成代码。此提示要求 o1 根据某些特定标准重构 React 组件。
重构代码
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const prompt = `
说明:
- 给定下面的 React 组件,修改它,使非虚构类书籍显示为红色文本。
- 仅在回复中返回代码
- 不包含任何额外格式,如 markdown 代码块
- 格式方面,使用四个空格的制表符,不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
prompt = """
说明:
- 给定下面的 React 组件,修改它,使非虚构类书籍显示为红色文本。
- 仅在回复中返回代码
- 不包含任何额外格式,如 markdown 代码块
- 格式方面,使用四个空格的制表符,不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)编码(规划)
OpenAI o 系列模型也擅长制定多步骤计划。此示例提示要求 o1 创建完整解决方案的文件系统结构,以及实现所需用例的 Python 代码。
规划并创建 Python 项目
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const prompt = `
我想构建一个 Python 应用程序,该应用程序接收用户的问题,并在映射到答案的数据库中查找。如果有近似匹配,它会检索匹配的答案。如果没有,它会要求用户提供答案,并将问题/答案对存储在数据库中。制定你需要的目录结构计划,然后完整返回每个文件。只在开头和结尾提供你的推理,不要在整个代码中提供。
`.trim();
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
prompt = """
我想构建一个 Python 应用程序,该应用程序接收用户的问题,并在映射到答案的数据库中查找。如果有近似匹配,它会检索匹配的答案。如果没有,它会要求用户提供答案,并将问题/答案对存储在数据库中。制定你需要的目录结构计划,然后完整返回每个文件。只在开头和结尾提供你的推理,不要在整个代码中提供。
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)STEM 研究
OpenAI o 系列模型在 STEM 研究中表现出色。要求支持基础研究任务的提示应该会显示出很好的结果。
提出与基础科学研究相关的问题
javascript
import OpenAI from "openai";
const openai = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const prompt = `
我们应该考虑研究哪三种化合物来推进新型抗生素的研究?为什么我们应该考虑它们?
`;
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
prompt = """
我们应该考虑研究哪三种化合物来推进新型抗生素的研究?为什么我们应该考虑它们?
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt
}
]
)
print(response.output_text)用例示例
在食谱中可以找到一些将推理模型用于实际用例的示例。
[
使用推理进行数据验证
评估合成医疗数据集的差异。
](cookbook.openai.com/examples/o1...%255B "https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation)%5B")
使用推理生成常规流程
使用帮助中心文章生成代理可以执行的操作。
](cookbook.openai.com/examples/o1...)
对于需要处理复杂推理任务的开发者而言,稳定的 API 连接是高效工作的基础。我们提供的 API 中转服务通过 https://api.aaaaapi.com 优化了请求路径,尤其适合对响应速度和稳定性要求较高的推理模型应用场景。如果在集成过程中遇到任何连接问题,可访问官网获取技术支持,确保推理任务顺利进行。