传统 RAG 架构主要分为 文档解析、文本召回、大模型生成这三个阶段,在实际落地中会面临一系列挑战:
1. 文档解析阶段
- 数据异构:文档来源多样(PDF、网页、表格、图片等),解析结构化难度大。
- 结构混乱:标题、段落层次混乱,缺乏明确语义边界。
- 切分困难:固定大小切分易导致语义破损,语义分块成本高。
2. 文本召回阶段
- 语义不匹配:用户 Query 通常简短,与文档表述存在风格差异。
- 召回覆盖不足:Top-k 召回可能漏掉关键信息块,尤其是分散的知识点。
3. 生成阶段
- 召回噪音:大量与问题弱相关的 chunk 被召回,影响生成质量。
- 上下文不连贯:片段之间缺乏连接,导致大模型难以理解逻辑关系。
下面介绍一些优化策略,提高以上三个阶段的准确性
切片策略优化
动态切片
针对文档解析阶段的问题,我们可以采用以下动态切片技术:
1. Context Enriched Retrieval(丰富上下文)
在检索的时候,返回给模型更多的上下文,也就是当前 chunk 的前后窗口。比如:我们检索到了 chunk2,那么应该返回临近的 chunk1 以及 chunk3,丰富上下文。
实现原理:
- 当检索到相似度为 0.9 的 chunk2 时
- 自动获取 chunk1+chunk2+chunk3 的组合
- 将合并后的内容提供给大模型进行回答
这种方法能够有效解决信息割裂的问题,确保模型获得足够的上下文信息。
2. Semantic Chunking(语义分块)
通常文档会被分成多个小的 chunk,当我们检索内容时,获取其中相关性得分较高的TopN的内容。因为文档被切分的很小,因此很容易漏掉一些相关联的内容,导致语义不完整。
核心思想:
- 判断相邻chunk的语义相似度
- 当相似度接近(如>0.95)时,将相邻chunk合并
- 通过动态分块确保语义完整性
优势:
- 解决信息不足问题
- 保持语义完整性
- 减少因切分导致的信息丢失
3. RSE(相关段落搜索增强)
针对一般文档,相关信息大概率是分布在连续的文本段落中,而不是离散的 chunk。基于这个假设,RSE的完整流程如下:
- 固定切分存储:将所有数据进行固定切分,存入向量数据库
- 初步筛选:过滤出相似度较高的片段
- 上下文扩展:根据筛选出的片段进行上下文连续片段的查找(主要是往下查找)
- 相似度聚合:将片段相似度相加求总和,进行阈值筛选
- 结果返回:最终将筛选出的数据进行返回
辅助信息检索
1. Contextual Chunk Headers(添加标题辅助检索)
通过为所有的文档片段统一添加标题,来提高检索得分。在实际查询场景中,用户的输入一般为短文本,而我们的chunk块一般是长文本。(短文本与短文本的向量相似度更高)
实现方式:
- 为每个chunk生成简洁、准确的标题
- 将标题和内容结合进行向量化
- 检索时同时匹配标题和内容
2. Document Augmentation(文档增强)
为每个 chunk 提前生成好问答对,将潜在的问题作为额外的检索入口。
核心理念:
- 文本内容 → 生成相关问题
- 问题作为额外检索入口,提高匹配准确度
- 用户查询时,既可以匹配原文,也可以匹配生成的问题
实现方式:
- 对每个chunk,使用大模型生成3-5个相关问题
- 将问题和原文一起进行向量化存储
- 检索时同时搜索原文和问题库
- 提高问题匹配的准确性
3. Contextual Compression(上下文压缩)
检索回来的内容可能包含很多无关的内容块,需要压缩提炼后给到大模型。
实现流程:
- 获取更多的相关chunk(扩大检索范围)
- 使用大模型对内容进行压缩
- 过滤只和query相关的内容
- 将精炼后的内容提供给生成模型
整体信息提取
1. GraphRAG(知识图谱增强检索)
知识图谱通过提供结构化的、关系丰富的信息,帮助系统更好地理解和处理查询,从而增强生成内容的相关性和准确性。
优势:
- 构建实体间的关系网络
- 支持复杂的关系推理
- 提供全局性的信息视角
- 能够回答跨文档的关联性问题
- 增强全局理解能力,适用于政策类、法规类等结构化文档。
挑战:
- 构建成本较高
- 实体和关系提取需要专业技术
- 维护和更新复杂
- 对领域专业知识要求高
Query 优化
Query优化主要解决两个核心问题:
- 检索数据过少:用户查询过于简单或模糊
- 向量空间不匹配:问题向量空间和内容向量空间存在差异
1. Query Transformation(查询改写)
问题改写,提高检索匹配能力。
核心思路: 将用户的原始查询转换为多个更具体、更容易匹配的查询变体。
例子:
-
"AI依赖大数据有哪些问题?"
- 拆解为:"数据质量问题"、"训练效率问题"、"隐私安全"等;
-
通过 LLM 生成 Query 的多视角变体,提升召回命中率。
2. HyDE(假设文档嵌入)
模型生成假想文档,辅助检索。
基本原理: HyDE方法认为原始问题一般都比较短,而生成的假设文档可能会更好地与索引文档对齐。
实施步骤:
- 用户提出问题
- 让大模型生成一个假设的、理想的答案文档
- 用这个假设文档去检索真实的文档库
- 基于检索到的真实文档生成最终答案
优势:
- 连接查询和文档之间的语义差异
- 提高检索的召回率
- 特别适用于复杂的技术问题
检索策略优化
检索策略优化主要解决两个问题:
- 检索得分计算不准确
- 检索流程需要优化,实现多策略机制
提高检索准确性
1. Reranker(重排序)
尽可能多的查询到相关内容,然后让rerank模型根据相似性重新对结果排序。
工作流程:
- 第一阶段:使用向量检索,召回更多候选文档(如Top 50)
- 第二阶段:使用更精确的rerank模型对候选文档重新排序
- 第三阶段:选择Top N(如Top 5)最相关的文档用于生成
优势:
- 提高检索精度
- 平衡召回率和精确率
- 可以使用更复杂的排序模型
2. Feedback Loop(反馈循环)
系统可以从用户反馈中学习,持续改进检索质量。
假设同样的Query查询, 文档A被多个用户采纳,新用户查询类似问题时:
- 文档A:原始相似度0.8 → 调整后0.96(0.8 × 1.2提升系数)
- 文档B:保持0.6(无相关反馈)
- 文档C:保持0.5(无相关反馈)
形成正向反馈循环,不断优化检索质量。
3. Hierarchical Indices(分层索引)
基于"用户查询多为短文本"的假设,采用分层检索策略。
核心原理:
- 越小的块:信息越单一,向量相对准确,短文本检索越准确
实现方案:
-
文档预处理:将文档分层分块,为大块生成摘要
-
向量化存储:将摘要和详细chunk分别向量化存入数据库
-
两阶段检索:
- 第一阶段:根据用户Query检索相关Summary
- 第二阶段:在筛选出的Summary下的chunk中再做精确检索
-
结果生成:拼接最相关的chunk和用户query,交给大模型生成答案
4. Hybrid Search (混合检索)
关键词召回+语义召回,结合两种检索方式的优势。
实现策略:
- 关键词检索:使用BM25、TF-IDF等传统方法
- 语义检索:使用向量相似度计算
- 融合算法:将两种检索结果按权重融合
检索流程优化
1. Self RAG
基于检索的文档chunk,大模型可以过滤和问题相关的chunk,减少噪音数据,用相关性高的chunk来回答问题。
核心机制:
- 检索阶段:获取多个潜在相关的文档片段
- 自我评估:模型评估每个片段与查询的相关性
- 过滤筛选:只保留高相关性的片段
- 生成回答:基于筛选后的高质量片段生成答案
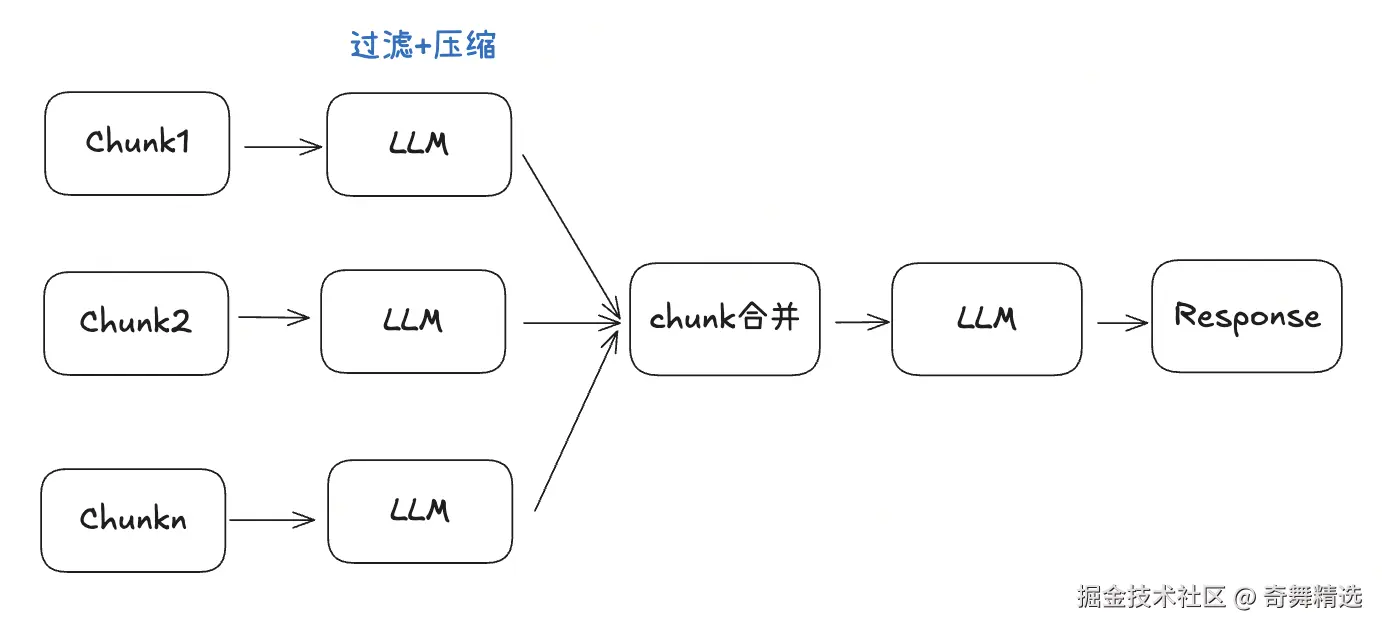
image.png
2. Adaptive RAG
不同类型的查询需要不同的检索策略,根据不同的场景细化检索的方式。
自适应机制:
- 问题分类:事实查询、分析查询、比较查询等
- 策略选择:根据问题类型选择相应的检索和生成策略
- 动态调整:根据上下文和用户反馈动态调整策略
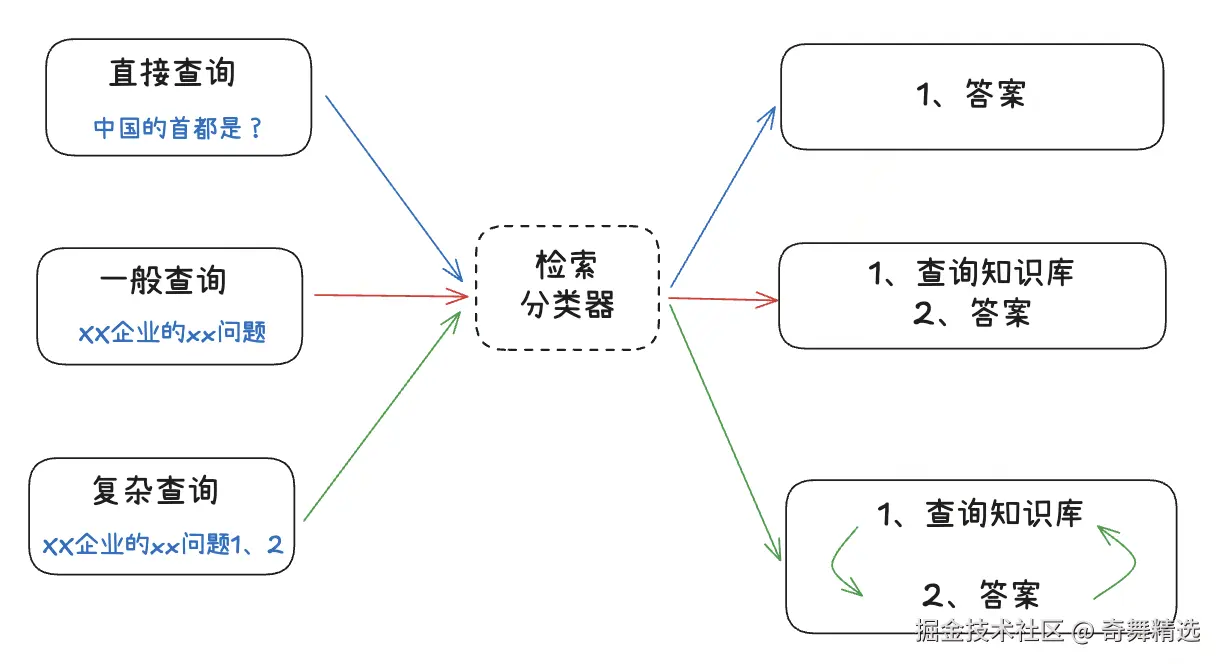
image.png
3. CRAG
针对用户的提问,检索的结果与问题不一定完全匹配,需要额外操作来丰富上下文。
三种情况分类处理:
1:检索结果正确 , 进入Knowledge Refinement 流程:
- 将文档分解为小片段(strip₁, strip₂, etc.)
- 使用大模型过滤无关信息
- 重新组合为精炼知识k_in
- 直接用于生成答案
2:检索结果错误 , 进入Knowledge Searching 流程:
- 触发网络搜索,获取外部信息
- 收集多个候选答案k₁, k₂, k_n
- 选择最佳的外部知识k_ex
- 基于外部知识生成答案
3:检索结果模糊:
- 同时执行知识精炼和知识搜索
- 将内部精炼知识和外部搜索知识进行整合
- 生成更全面、准确的答案
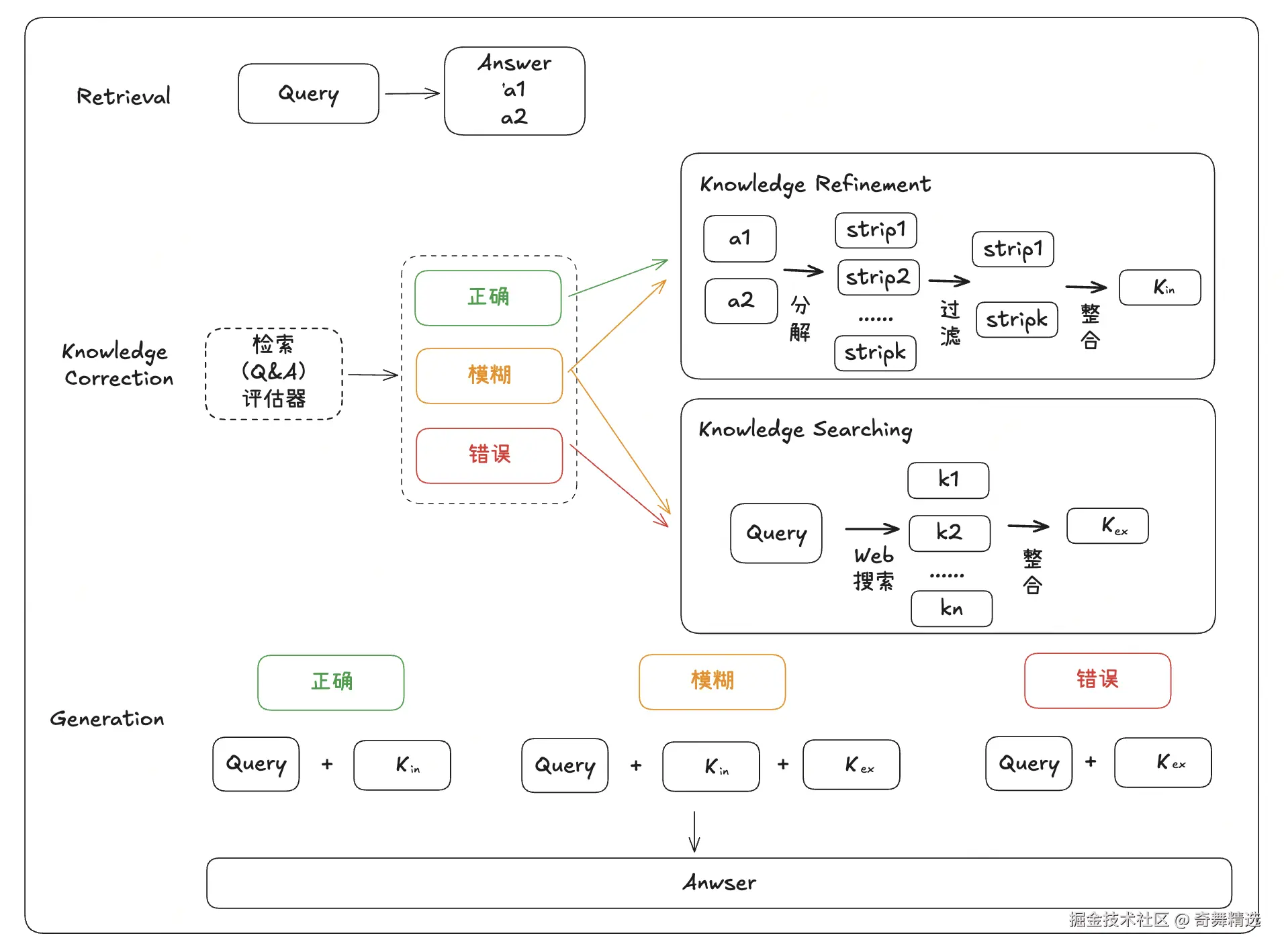
image.png
总结
RAG系统的优化是一个系统性工程,需要从多个维度进行改进, 建议根据业务需求、数据特点,选择合适的优化策略组合,提升RAG系统在实际应用中的表现,为用户提供更准确、更相关、更有价值的信息检索和生成服务。