逻辑回归的输入是线性回归的输出
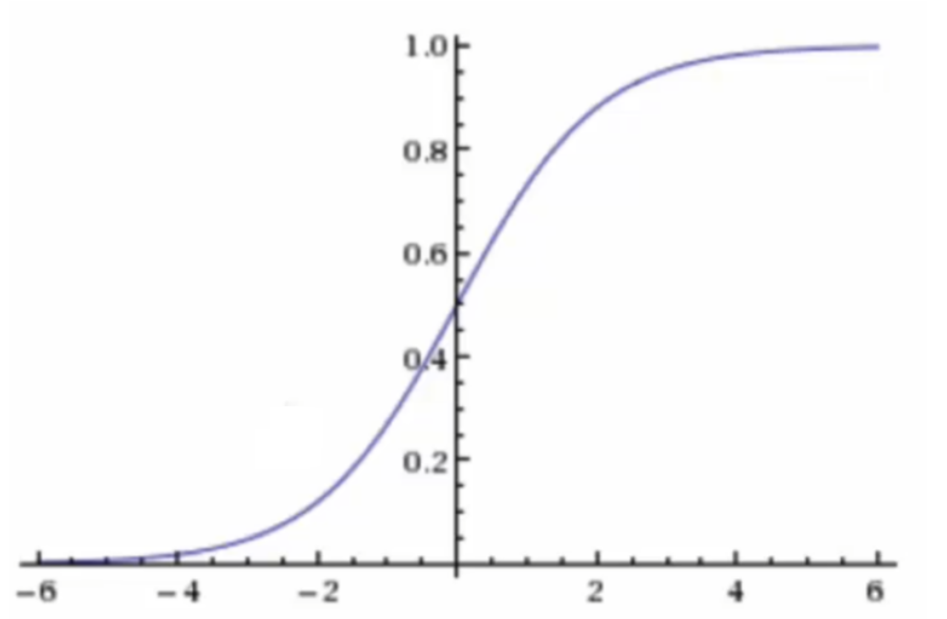
线性回归的输出是连续值(如 h(w)=w1x1+w2x2+...+b),而 sigmoid 函数可以将这个连续输出映射到 0, 1 区间,使其具备概率含义。

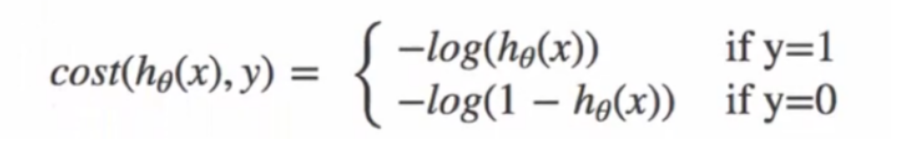
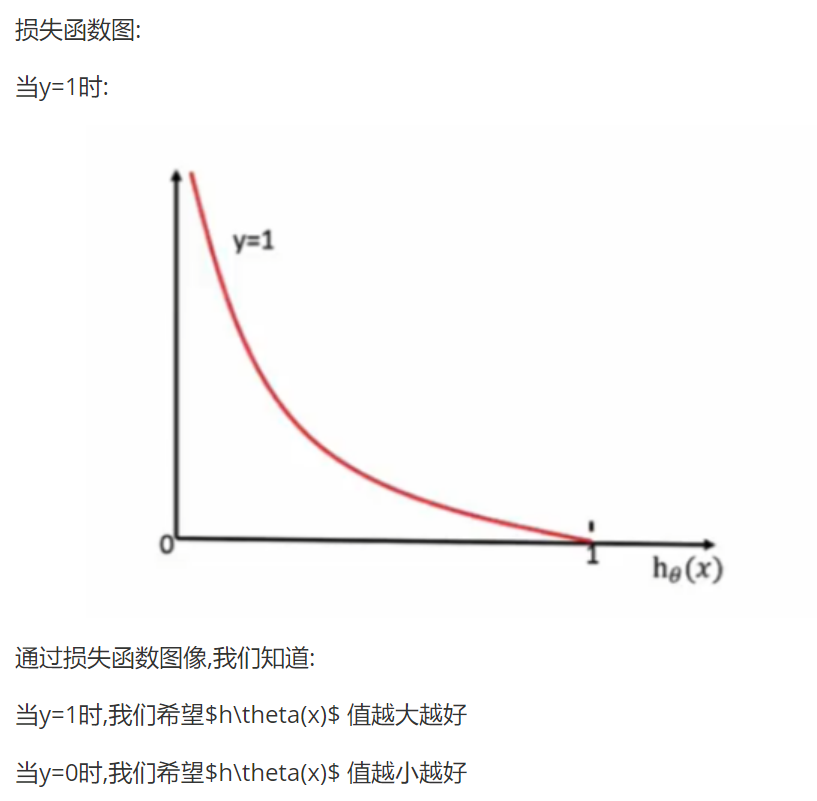

代码
python
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y)
plt.show()激活函数sigmoid
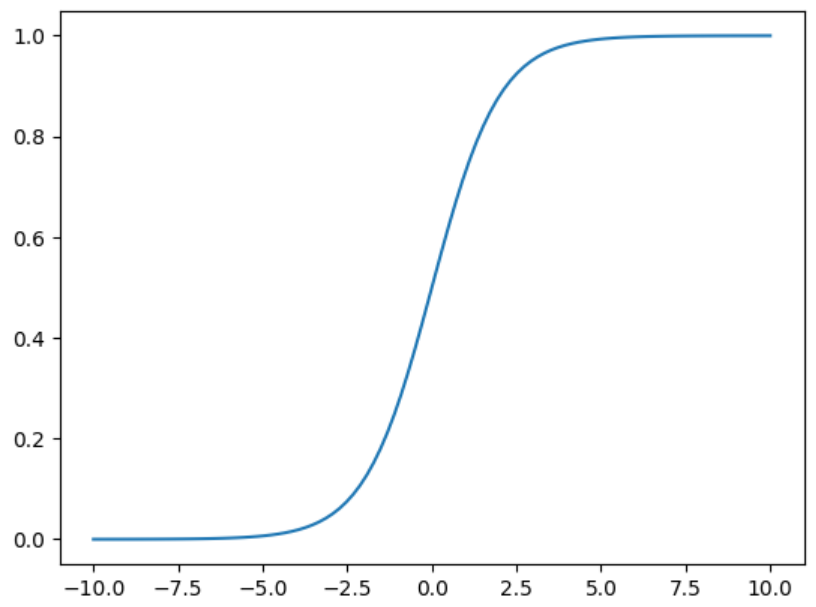
python
from sklearn.linear_model import LogisticRegression
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data = pd.read_csv("./src/titanic/titanic.csv")
print(data.columns)
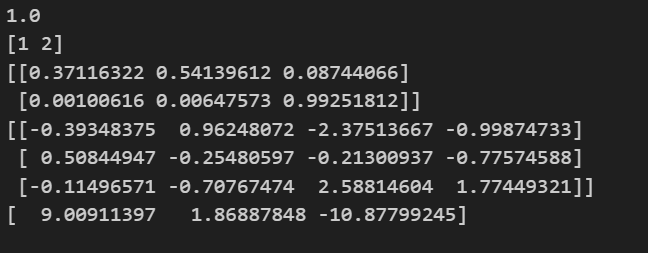
y = data["survived"].values
x = data[["pclass", "age", "sex"]]
# x[["age"]].fillna(x[["age"]].mean(), inplace=True)
# print(y.shape,type(y))
# print(x.head())
x["age"].fillna(x["age"].mean(), inplace=True)#对空值进行处理
x= x.to_dict(orient="records")
# print(x[:5])
dicter = DictVectorizer(sparse=False)
x=dicter.fit_transform(x)
print(dicter.get_feature_names_out())
print(x[:5])
scaler = StandardScaler()
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
model = LogisticRegression(max_iter=1000,fit_intercept=True)
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
print(score)
python
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)
model = LogisticRegression(max_iter=5000)
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
print(score)
x_new=[[5,5,4,2],
[1,1,4,3]]
y_predict = model.predict(x_new)
y_por = model.predict_proba(x_new)
print(y_predict)
print(y_por)
print(model.coef_)
print(model.intercept_)