一、安装LLaMA-Factory
我们使用LLaMA-Factory来进行微调,安装LLaMA-Factory来参考文章:
大模型微调工具LLaMA-Factory的安装流程-CSDN博客
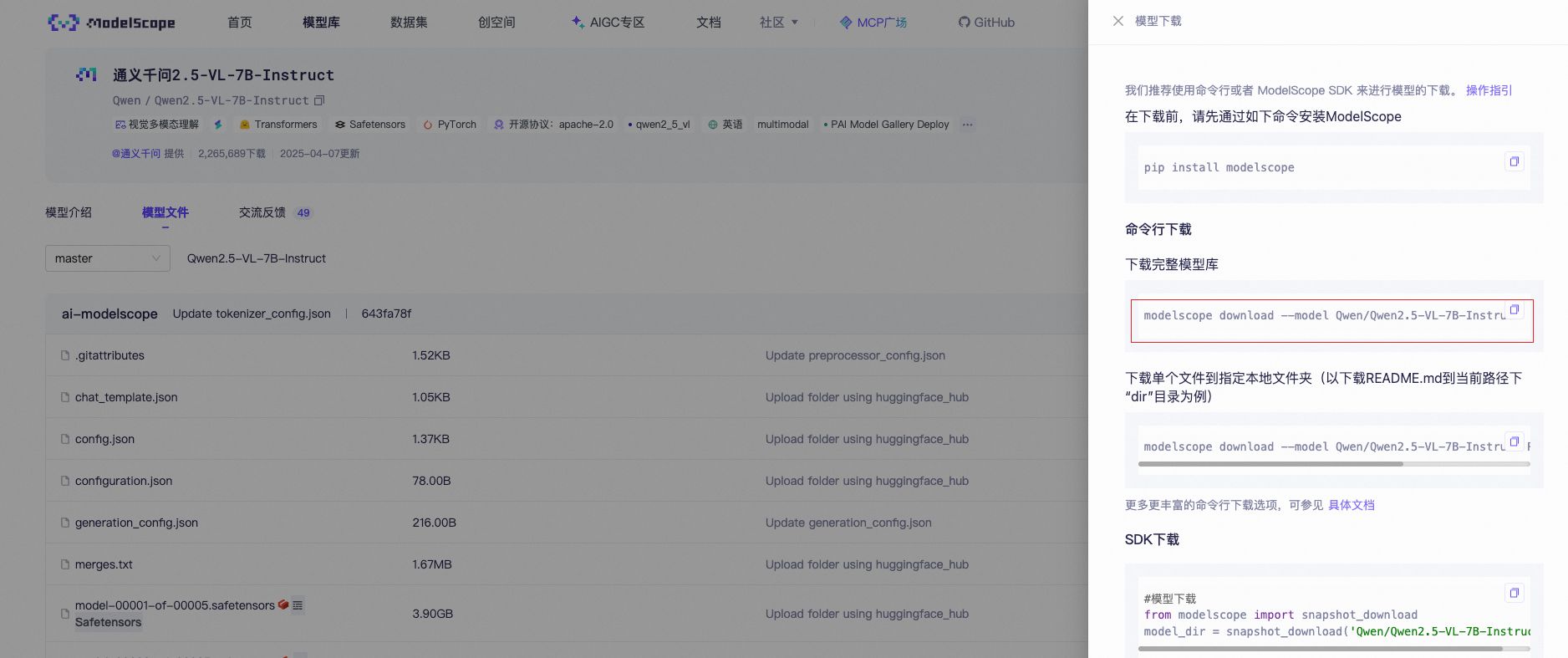
二、下载千问2.5-VL-7B模型
我们使用千问2.5-VL-7B多模态模型来进行微调
通义千问2.5-VL-7B-Instruct
下载命令(需要先安装modelscope的依赖,魔塔上有安装教程):
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct
三、数据集
在微调之前准备数据集,我们使用Kaggle平台上开放的数据集FER-2013,该数据集包含了大量的人脸表情图片,并做了对应的表情标注。
数据地址:FER-2013 | Kaggle
数据下载后需要构建训练集和验证集的json格式文件,包括图片的路径和情感标签。
下面是处理数据的脚本:
python
import json
import os
from pathlib import Path
# 定义消息对象
class Message:
def __init__(self, role, content):
self.role = role
self.content = content
# 定义对话组对象
class ConversationGroup:
def __init__(self, messages, images):
self.messages = messages
self.images = images
def to_dict(self):
return {
"messages": [msg.__dict__ for msg in self.messages],
"images": self.images
}
def get_file_paths(directory):
"""
获取指定目录下所有文件夹中的文件路径
:param directory: 要扫描的根目录
:return: 包含所有文件路径的列表
"""
file_paths = []
# 检查目录是否存在
if not os.path.exists(directory):
print(f"错误:目录 '{directory}' 不存在")
return file_paths
# 遍历目录下的所有项目
for item in os.listdir(directory):
item_path = os.path.join(directory, item)
# 只处理文件夹(忽略文件)
if os.path.isdir(item_path):
# 遍历文件夹中的所有文件
for file in os.listdir(item_path):
file_path = os.path.join(item_path, file)
# 只添加文件(忽略子文件夹)
if os.path.isfile(file_path):
file_paths.append(file_path)
return file_paths
def get_path_dir_info(path_file):
new_path = "archive" + path_file.split("archive")[1]
path_n = Path(new_path)
# 获取上一级目录名
parent_dir_name = path_n.parent.name
return new_path, parent_dir_name
emotion = {
"angry":"生气/愤怒",
"disgust":"厌恶",
"fear":"害怕/恐惧",
"happy":"开心/快乐",
"neutral":"平静",
"sad":"悲伤/难过",
"surprise":"惊讶/惊奇"
}
if __name__ == '__main__':
all_files = get_file_paths("/Users/youngwea/Downloads/archive/train")
print(all_files)
output_data = []
for file in all_files:
new_path , dir_name = get_path_dir_info(file)
user_message = Message("user", "<image>是什么表情?")
assistant_message = Message("assistant", emotion.get(dir_name))
conversation = ConversationGroup(
messages=[user_message, assistant_message],
images=[new_path]
)
output_data.append(conversation.to_dict())
json_output = json.dumps(output_data, indent=2, ensure_ascii=False)
with open('../data/qwen2.5-vl-train-data.json', 'w', encoding='utf-8') as file:
file.write(json_output)处理好的数据集需要复制到LLaMA-Factory的工程项目的/data目录中去,再在dataset_info.json文件中添加数据文件。
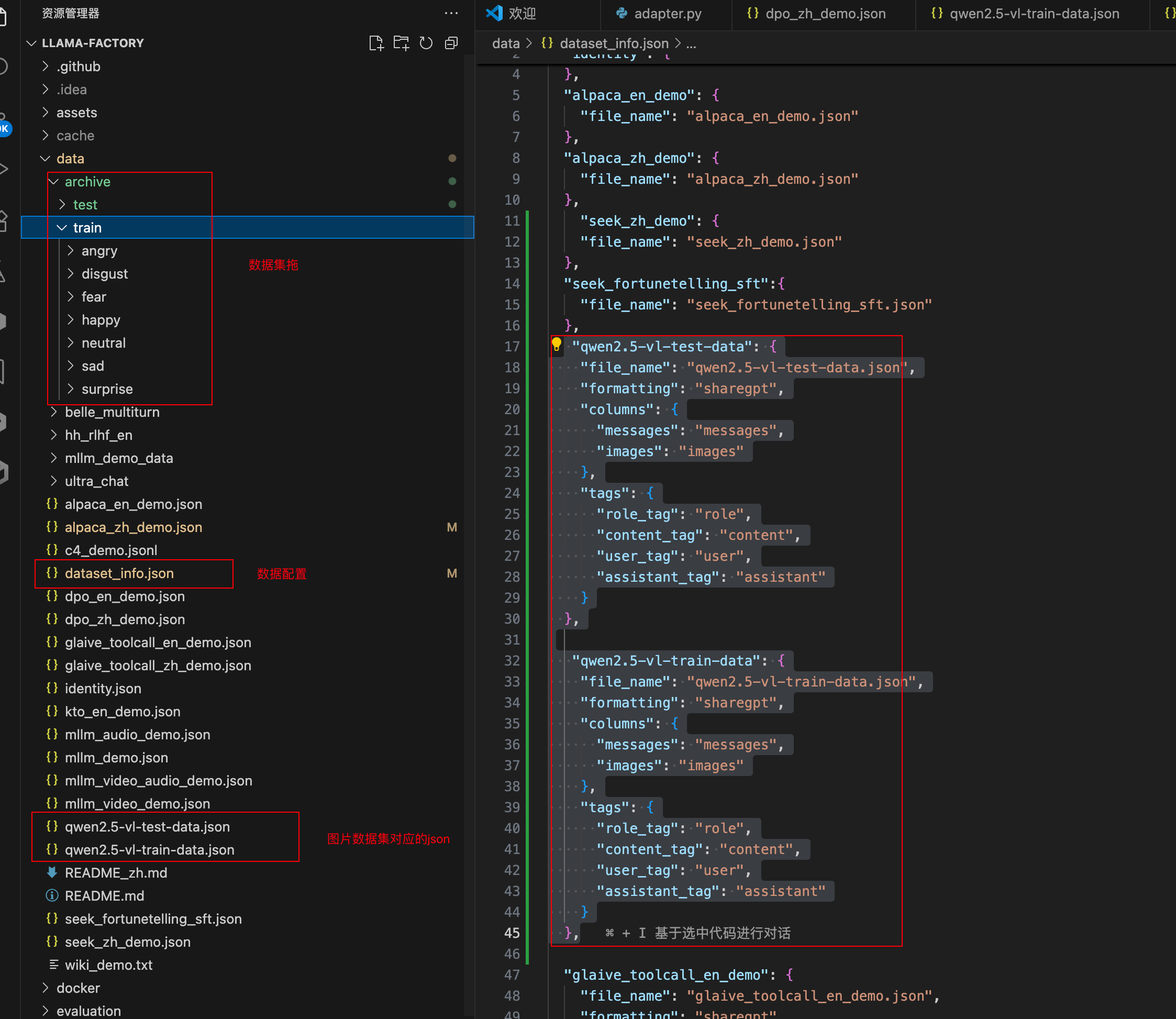
三、训练配置:
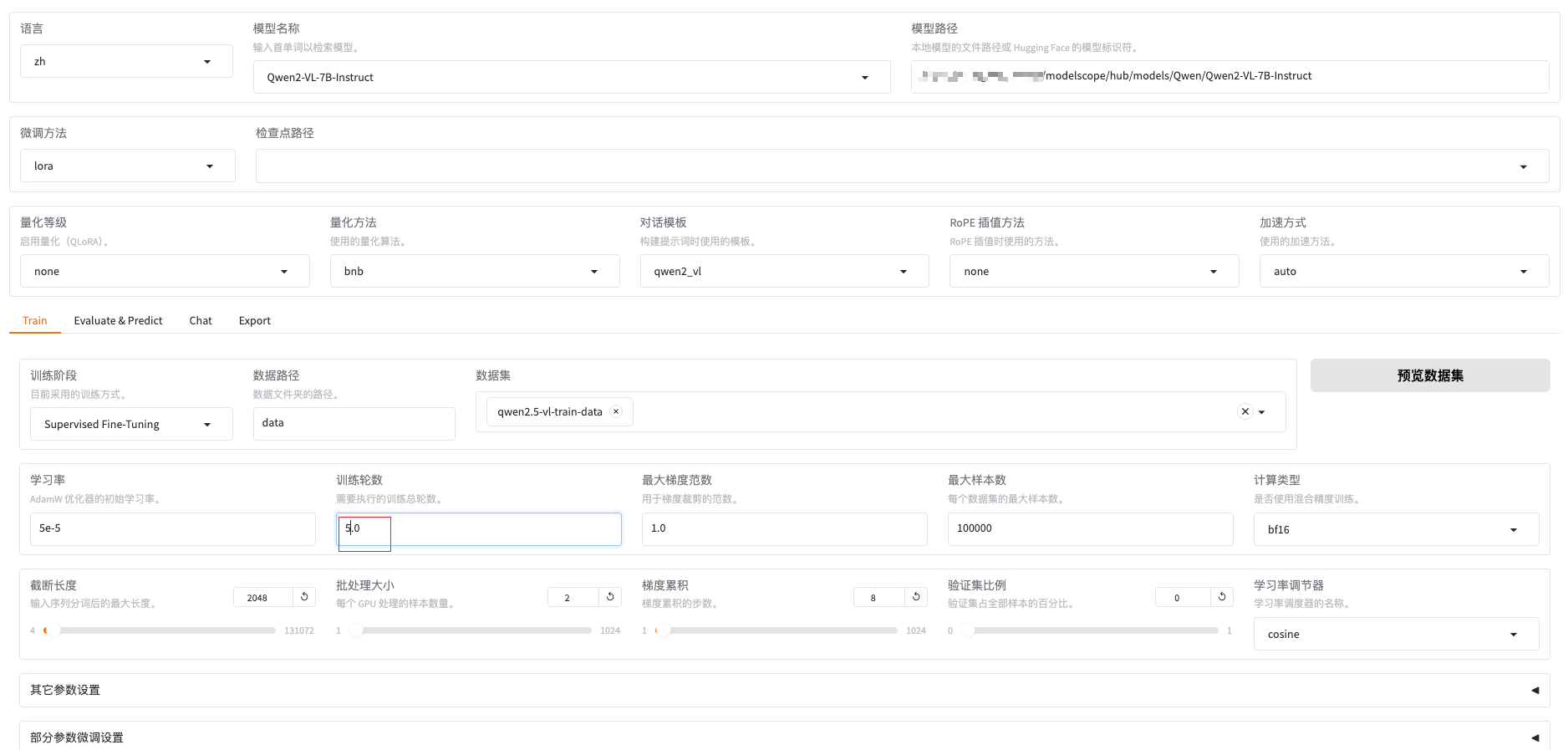
训练轮数为3的时候,对识别表情不太准确。增大后准确率高点。
训练脚本:
python
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path xxx/modelscope/hub/models/Qwen/Qwen2.5-VL-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen2_vl \
--flash_attn auto \
--dataset_dir data \
--dataset qwen2.5-vl-train-data \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 5.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to none \
--output_dir saves/Qwen2.5-VL-7B-Instruct/lora/train_qwen2.5-vl-_2025-07-31-14-02-45 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--freeze_vision_tower True \
--freeze_multi_modal_projector True \
--freeze_language_model False \
--image_max_pixels 589824 \
--image_min_pixels 1024 \
--video_max_pixels 65536 \
--video_min_pixels 256推荐一个非常好用的工具集合:在线工具集合 - 您的开发助手