一)实验任务和数据集
实验任务 微调 Bert 基础模型让其实现情感二分类,使用的数据集为 sst-2,其数据结构如下所示。
javascript
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 67349
})
validation: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 872
})
test: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1821
})
})训练数据 67349 条,验证数据 872 条,测试数据 1821 条。SST-2 是自然语言处理(NLP)领域最经典的情感分类数据集之一, 每个样本是单个句子 (而非完整段落),标签为 0(负面)/1(正面),该数据集用于评估模型的句子级情感分类能力,是 NLP 领域的 "基准数据集" 之一 ------ 几乎所有预训练模型(如 BERT、RoBERTa)都会在 SST-2 上做微调测试,以展示其文本理解性能。
其数据的基本内容如下所示。
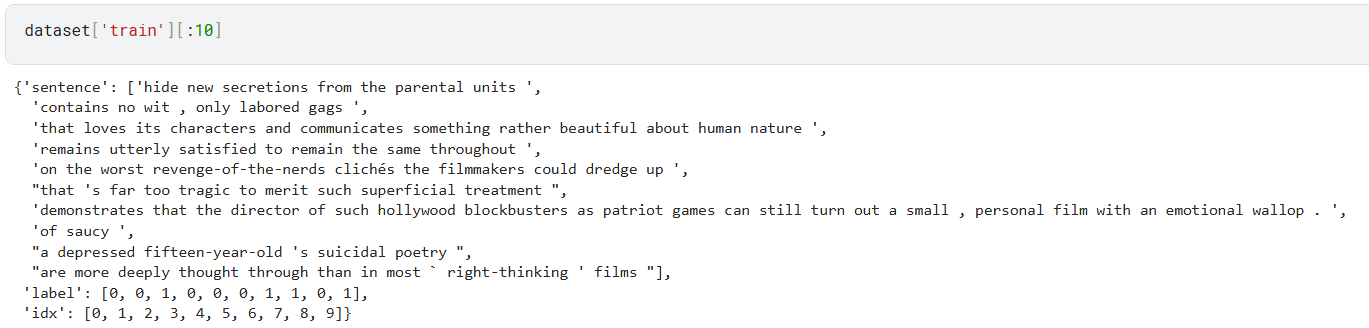
二)实验模型
实验模型选择 bert-base-uncased ,是 Hugging Face 生态中最常用的预训练模型之一 ,是 BERT 系列的基础版本之一,双向 Transformer 预训练语言模型,"uncased" 含义是训练时会将所有文本转为小写(如 "Hello"→"hello"),因此对大小写不敏感,约 1.1 亿参数,12 层 Transformer 编码器 + 768 维隐藏层 + 12 个注意力头。
python
# 1. 加载分词器(必须和预训练模型对应)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 2. 加载适用于分类任务的BERT模型
# num_labels=2 对应SST-2的"正面/负面"二分类
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased",
num_labels=2 # 分类任务的类别数,根据实际任务调整
)模型加载后 不能直接预测 ------ 加载的模型分类头是随机初始化的,需要在 SST-2 数据集上微调训练后,才能用于情感分类推理。
因为像 BERT 这样的模型无法直接 "阅读" 文本,它们只能处理数字张量(Tensor)。必须要将原始的文本数据集,通过分词器(Tokenizer)处理成模型可以理解和训练的数字格式。
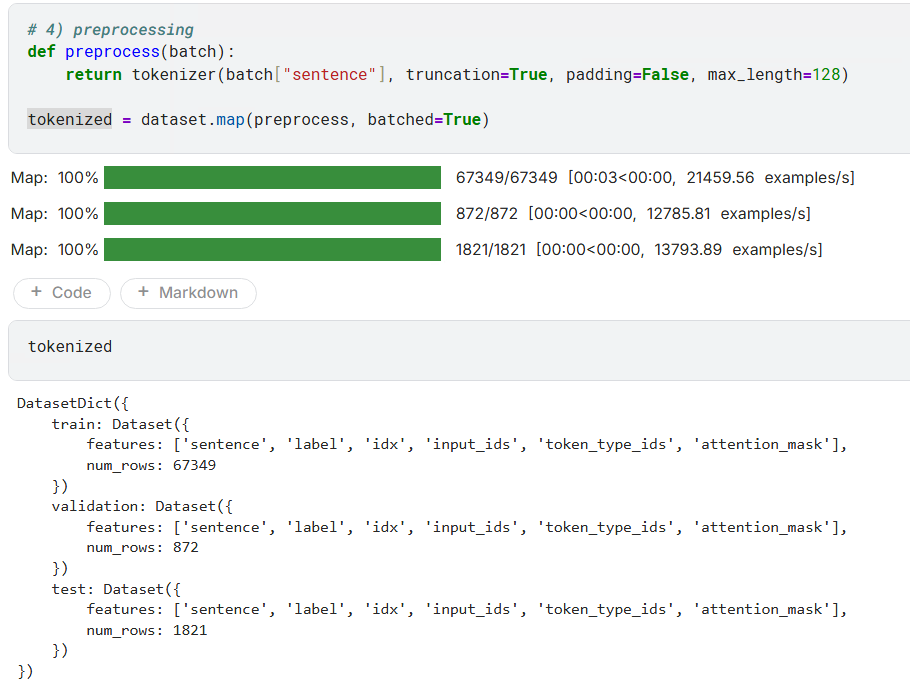
三)定义评估模型的性能指标
python
metric_acc = load_metric("accuracy")
metric_f1 = load_metric("f1")
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
acc = metric_acc.compute(predictions=preds, references=labels)["accuracy"]
f1 = metric_f1.compute(predictions=preds, references=labels, average="binary")["f1"]
return {"accuracy": acc, "f1": f1}四)训练
python
# 7) training args
training_args = TrainingArguments(
output_dir="./bert-sst2-finetuned",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
save_total_limit=2,
fp16=True, # if using an NVIDIA GPU with mixed-precision support
seed=42,
logging_strategy="epoch",
# logging_steps=100,
report_to="none",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized["train"],
eval_dataset=tokenized["validation"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()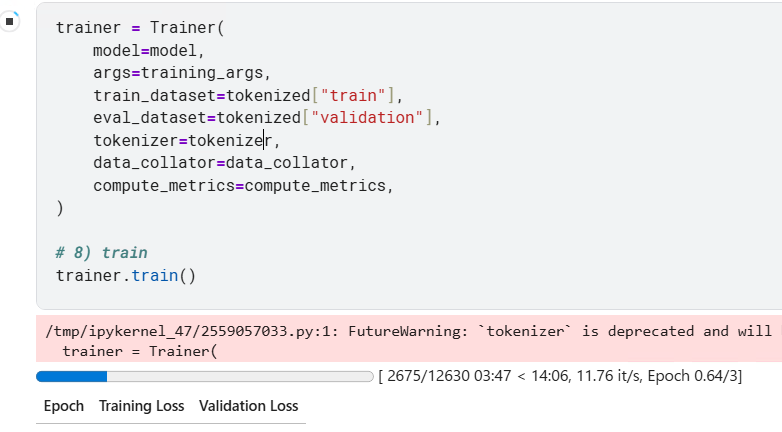
五)完整脚本
python
############ 1 加载库 ############
import numpy as np
from datasets import load_dataset
from evaluate import load as load_metric
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
DataCollatorWithPadding,
set_seed,
)
############ 2 加载数据集 ############
dataset = load_dataset("glue", "sst2")
############ 3 加载分词器和模型 ############
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased", use_fast=True)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased",num_labels=2)
############ 4 数据处理 ############
def preprocess(batch):
return tokenizer(batch["sentence"], truncation=True, padding=False, max_length=128)
tokenized = dataset.map(preprocess, batched=True)
data_collator = DataCollatorWithPadding(tokenizer)
############ 5 模型评价 ############
metric_acc = load_metric("accuracy")
metric_f1 = load_metric("f1")
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
acc = metric_acc.compute(predictions=preds, references=labels)["accuracy"]
f1 = metric_f1.compute(predictions=preds, references=labels, average="binary")["f1"]
return {"accuracy": acc, "f1": f1}
############ 6 模型训练 ############
training_args = TrainingArguments(
output_dir="./bert-sst2-finetuned",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
save_total_limit=2,
fp16=True, # if using an NVIDIA GPU with mixed-precision support
seed=42,
logging_strategy="epoch",
# logging_steps=100,
report_to="none",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized["train"],
eval_dataset=tokenized["validation"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()