本文深入介绍 LangChain 的 Memory 系统机制,包括
ConversationMemory类型、历史对话拼接与自动总结功能,助你搭建支持上下文记忆与多轮对话的智能链条。
一、为什么需要 Memory 系统?
- LLM 默认无状态,每次调用仅看当前输入,不记忆前文
- 对话系统要记住上下文,答案才能"接得住"
- Memory 系统负责 记录、拼接、管理历史对话,并把相关内容注入 prompt,以维持对话连续性与上下文理解能力
二、Memory 类型概览
| 类型 | 功能 | 适用场景 |
|---|---|---|
ConversationBufferMemory |
存储完整对话历史 | 短会话或上下文窗口足够 |
ConversationBufferWindowMemory |
仅保留最后 k 条消息 | 对话较长时防止上下文膨胀 |
ConversationSummaryMemory |
使用 LLM 自动生成 summary,拼接到 prompt | 对话长、希望压缩上下文时 |
ConversationSummaryBufferMemory |
综合 buffer + summarization 多策略混合 | 平衡记忆与上下文长度管理 |
这些 Memory 类型虽已逐步迁移至 LangGraph,但源码支持仍可使用,适合当前链式记忆机制。
三、如何使用 RunnableWithMessageHistory
LangChain 提供 RunnableWithMessageHistory 封装任何 Runnable,实现会话记忆管理:
langchain_core.runnables.history.RunnableWithMessageHistory
实现逻辑简要(How it works):
python
class RunnableWithMessageHistory(Runnable):
def __init__(
self,
runnable: Runnable, # 被包裹的链或模型
get_session_history: Callable, # 根据 session_id 获取 MessageHistory 对象
input_messages_key: str = ...,
history_messages_key: str = ...
):
...
def invoke(self, input: dict, config: RunnableConfig) -> Any:
# 1. 从 config 中获取 session_id
session_id = config.configurable.get("session_id")
# 2. 调用 get_session_history(session_id) 获取消息记录对象
history = self.get_session_history(session_id)
# 3. 从 history 读取历史消息 → 注入 input 中指定的 key
input[self.history_messages_key] = history.messages
# 4. 执行原始 runnable
output = self.runnable.invoke(input, config)
# 5. 将当前对话的输入/输出消息记录到 history 中
history.add_messages([HumanMessage(...), AIMessage(...)])
return output作用(What it does):
- 包装一个模型调用链,如
ChatPromptTemplate | ChatModel - 生命周期中自动注入历史消息至 prompt,并保存交互信息
- 需要传入:
get_session_history、input_messages_key、history_messages_key等参数 - 不改变原有链的功能,只是在调用前后插入"历史注入 + 历史记录"逻辑
python
import os
from typing import Dict
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 模拟一个内存中的历史记录存储(实际部署可替换为 Redis 等)
session_store: Dict[str, ChatMessageHistory] = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in session_store:
session_store[session_id] = ChatMessageHistory()
return session_store[session_id]
# 创建 Prompt 模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个非常专业且友好的助手。"),
("user", "{question}"),
])
# 创建原始模型链
llm = ChatOpenAI(
temperature=0.7,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
chain = prompt | llm
# 包装为带记忆功能的链
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="question", # 输入参数名
history_messages_key="history", # prompt 接收历史的参数名
)
# 执行调用,自动注入历史并记录
response = chain_with_history.invoke(
{"question": "帮我总结一下《实践论》的核心论点,纯文本输出。"},
config={"configurable": {"session_id": "user123"}}
)
print(session_store)
print(response.content)
此机制适合单用户/多线程管理,可替换持久化存储(如 Redis)用于实际部署。
当然可以。下面是对你提供的内容进行专业、全面的扩展说明 ,包括每种 Memory 类型的功能解析、使用场景 及完整示例代码。
四、Memory 类型与历史拼接方法详解
LangChain 的 Memory 系统本质上是对历史消息的持久化与上下文拼接机制,其核心目标是:
- 维持上下文连贯性(记住历史提问/回答)
- 节省 Prompt 长度(通过滑窗或摘要机制)
- 提升用户体验(多轮对话、状态感知)
1. ConversationBufferMemory:最简单的全量对话缓存器
✅ 适用于短对话或窗口足够大的场景
功能说明:
- 缓存所有历史消息(用户与 AI 的对话)
- 会被自动拼接注入 Prompt 中
- 容易超长,但适合简单原型开发
示例代码:
python
import os
from langchain.chains.conversation.base import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
memory = ConversationBufferMemory(return_messages=True)
llm = ChatOpenAI(
temperature=0.7,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
chain = ConversationChain(
llm=llm,
memory=memory,
verbose=False
)
print(chain.invoke(
{"input": "请用一句话回答(不要超过30个汉字):苏联的存在时间区间是什么?"})["response"])
print(chain.invoke({"input": "我刚才问的问题是什么?"})["response"])
2. ConversationBufferWindowMemory:滑动窗口对话历史
✅ 适用于需要历史但受限于 Prompt 长度的中长对话
功能说明:
- 只保留最后
k轮对话(默认每轮包含用户+AI 各一条) - 防止历史无限增长,减小 Token 压力
- 控制成本与上下文权衡
示例代码:
python
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(
k=3, # 仅保留最近3轮消息
return_messages=True
)搭配使用方式与 ConversationBufferMemory 相同。
3. ConversationSummaryMemory:自动摘要上下文
✅ 适用于历史很长但上下文窗口受限场景
功能说明:
- 使用 LLM 自动生成对历史对话的总结(如"用户想了解投资建议...")
- 将该 summary 注入到 Prompt 中作为上下文
- 每轮对话后 summary 会动态更新,保持语义完整
示例代码:
python
import os
from langchain.chains.conversation.base import ConversationChain
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
temperature=0.7,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
memory = ConversationSummaryMemory(
llm=llm, # 用于生成摘要的 LLM
return_messages=True,
max_token_limit=300 # 控制 summary 长度
)
chain = ConversationChain(
llm=llm,
memory=memory,
verbose=False
)
response = chain.invoke(dict(input="我最近很焦虑,可能是因为工作压力大。"))
print(response['response'])
print("\n" + "*" * 100 + "\n")
response = chain.invoke(dict(input="你有什么放松建议吗?"))
print(response['response'])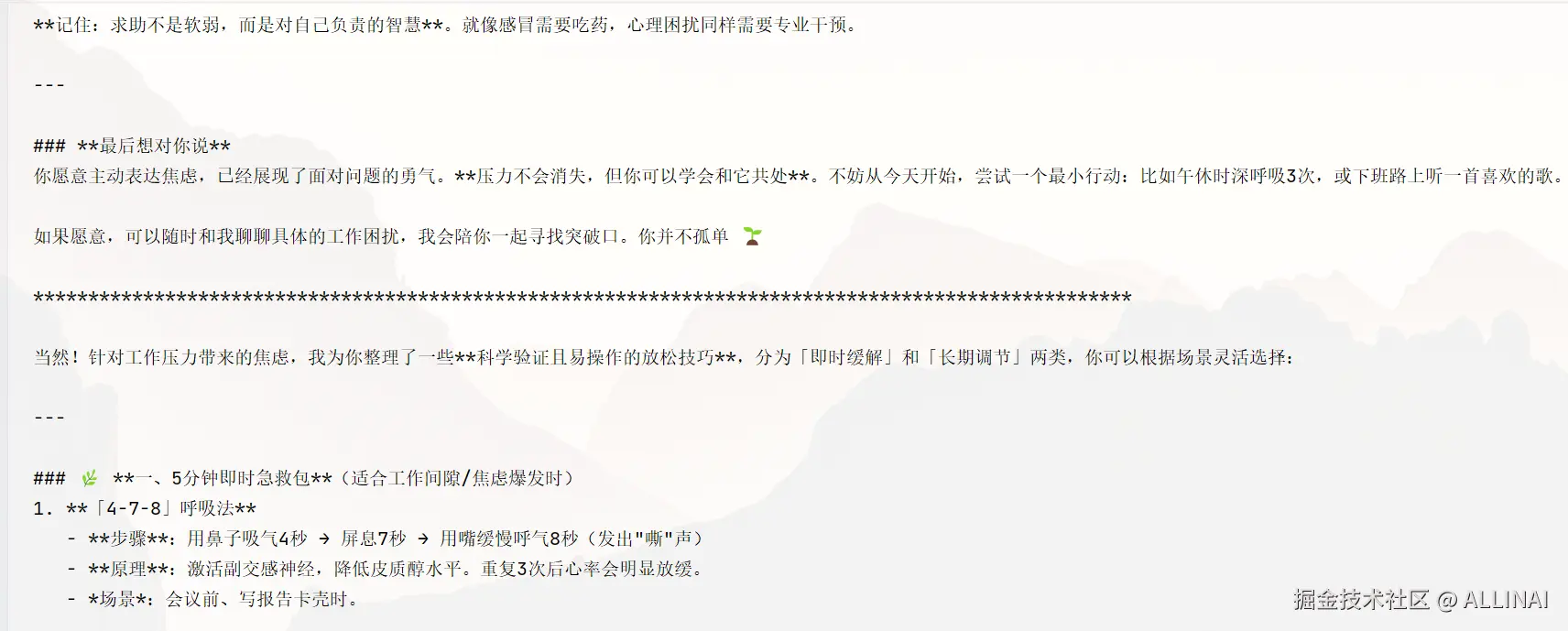
4. ConversationSummaryBufferMemory:摘要 + 滑窗的混合策略
✅ 适用于既想缩短上下文,又希望保留部分原文历史
功能说明:
- 保留一部分原始对话(如最近2轮)
- 对更早的对话进行摘要压缩
- 综合使用 buffer + summarization 的策略
示例代码:
python
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm=ChatOpenAI(),
max_token_limit=500,
return_messages=True
)此方案对长时间交互特别友好,适合实际产品部署。
5. 自定义 Memory:继承 BaseMemory / BaseChatMessageHistory
如果你希望将消息保存到数据库、Redis、MongoDB 等,也可以通过实现自定义 Memory 类来替换默认行为:
python
from langchain_core.chat_history import BaseChatMessageHistory
class MyCustomMemory(BaseChatMessageHistory):
def __init__(self):
self.messages = []
def add_message(self, message): self.messages.append(message)
def add_messages(self, messages): self.messages.extend(messages)
def clear(self): self.messages.clear()你可以将其结合到 RunnableWithMessageHistory 或自定义链中。
✅ 小结对比
| Memory 类型 | 优点 | 适用场景 |
|---|---|---|
ConversationBufferMemory |
实现简单、保留全部对话 | 原型、短对话 |
ConversationBufferWindowMemory |
控制窗口大小、性能更好 | 中长对话 |
ConversationSummaryMemory |
自动压缩语义、节省 token | 超长上下文、摘要理解 |
ConversationSummaryBufferMemory |
兼顾原文与摘要,灵活性最高 | 高质量对话系统 |
总结
- Memory 系统让 LLM 拥有"记忆"能力,从无状态到上下文感知
- Buffer 简单直观,适合短期交互;Window 和 Summary 可应对长对话
RunnableWithMessageHistory是目前主流记忆注入入口- 可与 LangGraph 持久化结合,构建可扩展、多用户、分支记忆体系
接下来,我们将解析 LangChain Agent 的决策流程、工具调用与动作推理机制,构建智能 Agent 执行体系。