在多模态AI的牌桌上,玩家们一直仰望着 Gemini 和 GPT-4o 这样的闭源巨头。开源社区虽然英雄辈出,但总感觉在最顶尖的视觉语言理解上,还差着那么一口气。直到 2025 年 8 月 6 日,一个意想不到的玩家------小红书 Hi Lab,带着他们的 dots.vlm1,直接掀了桌子。
这不仅仅是一次常规的模型开源,更像是一份战书。它的核心信息很简单:我们来了,而且我们能打。

王炸组合:自研视觉心脏 + 顶级语言大脑
忘掉那些在现有模型上修修补补的"微调"方案吧。小红书这次玩得很大,他们为 dots.vlm1 打造了一颗全新的"视觉心脏"------一个从零开始训练的 12亿参数 NaViT 视觉编码器。
"从零训练"这四个字,在圈内意味着巨大的投入和底气。它摆脱了对现有视觉模型的依赖,意味着感知能力的上限完全由自己定义。更妙的是,它原生支持动态分辨率,不再需要把所有图片都粗暴地裁剪成一个尺寸,无论是高清长图还是奇形怪状的图表,都能尽收眼底。
而与这颗强大心脏匹配的,是久经考验的 DeepSeek-V3 语言模型。这相当于给一辆底盘扎实的越野车,装上了一台性能猛兽的引擎。视觉的深度感知,加上文本的强大推理,双剑合璧。
不走寻常路:用"结构化"数据喂出的刁钻胃口
如果说模型架构是骨骼,那训练数据就是血肉。dots.vlm1 的强大,很大程度上源于它"挑食"的训练数据。
除了常规的图文配对,Hi Lab 团队给它"喂"了海量的结构化图片。这意味着什么?它看的不再仅仅是"一只猫在草地上",而是复杂的科研图表、密密麻麻的商业报表和技术文档。通过这种特训,dots.vlm1 练就了一双"火眼金睛",能精准洞察图片中的逻辑关系和结构信息,而不是仅仅看个热闹。
这种对高质量、结构化数据的执着,让它在处理现实世界中最棘手的视觉任务时,表现得游刃有余。
实力如何?数据不说谎
空谈架构和数据都是虚的,我们直接看战绩。
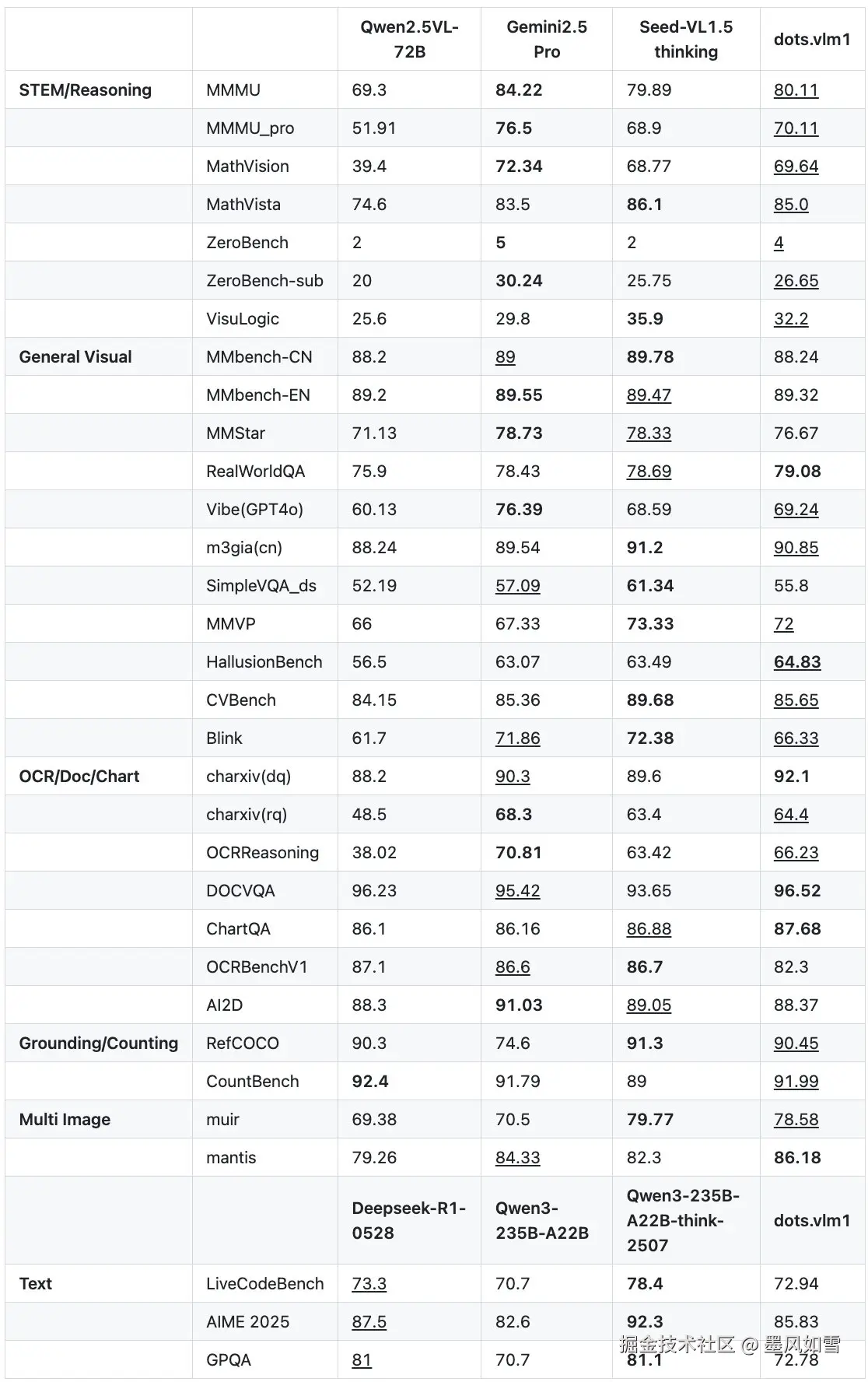
在 MMMU (多学科理解)、MathVista (数学推理)这类公认的高难度综合基准上,dots.vlm1 的表现已经杀到了闭源顶流 Gemini 2.5 Pro 的门前,差距微乎其微。特别是在 ChartQA(图表问答)这类任务上,它甚至实现了反超。
这意味着,当其他开源模型还在努力理解"图片里有什么"时,dots.vlm1 已经能和你讨论"这张财务报表第三季度的同比增长率是多少"了。同时,它的文本能力也完全看齐 DeepSeek 主力模型,写代码、解数学题都不在话下。
开源的终极形态:给你全套"施工图纸"
小红书这次的开源,不是扔出一个模型文件就完事了。他们几乎是把整个项目的"施工图纸"都交给了社区:从视觉预训练,到多模态预训练,再到最终的指令微调,全套方案、中间模型、训练细节一并放出。
这背后传递的信号是:我们不仅做出了一个好模型,我们还希望整个社区都能复现、借鉴、并超越它。这才是开源精神最纯粹的体现。
总而言之,dots.vlm1 的出现,不是在开源多模态领域里添了一块砖,而是直接立起了一座新的灯塔。它证明了通过创新的架构设计和高质量的数据工程,开源模型完全有能力与闭源巨头一较高下。
对于开发者和研究者来说,一个强大、可复现、商业友好的多模态基础设施已经摆在面前。接下来,就看大家能用它创造出怎样的新物种了。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站