当我们还在惊叹"文生图"模型(如Stable Diffusion)能把文字变成精美插画时,OpenAI的Sora已经迈出了更激进的一步------让文字直接生成分钟级的逼真视频。这两款现象级生成式AI背后,既有技术同源的血脉,也有因"静态vs动态"而产生的本质差异。今天我们就来拆解Sora与文生图潜在扩散模型的异同,看看AIGC从"画纸"到"银幕"的演进逻辑。
一、技术同源:共享生成式AI的底层基因
尽管生成的内容维度不同,Sora与文生图潜在扩散模型(以Stable Diffusion为代表)在技术底层有着深刻的共性,堪称"同宗同源":
1. 多模态理解的基石
两者都依赖**"文本-视觉"对齐的多模态技术**。比如文生图模型用CLIP(对比语言-图像预训练模型)把文字和图像特征映射到同一语义空间;Sora大概率也采用了类似的多模态对齐方案(甚至可能是更先进的多模态大模型),确保"文字描述"能精准驱动"视觉生成"。
2. 生成式框架的逻辑闭环
它们都遵循**"从噪声到内容"的扩散生成逻辑**:
- 文生图模型在"潜在图像空间"中,通过U-Net逐步去除噪声,把随机噪声变成符合文本指令的图像;
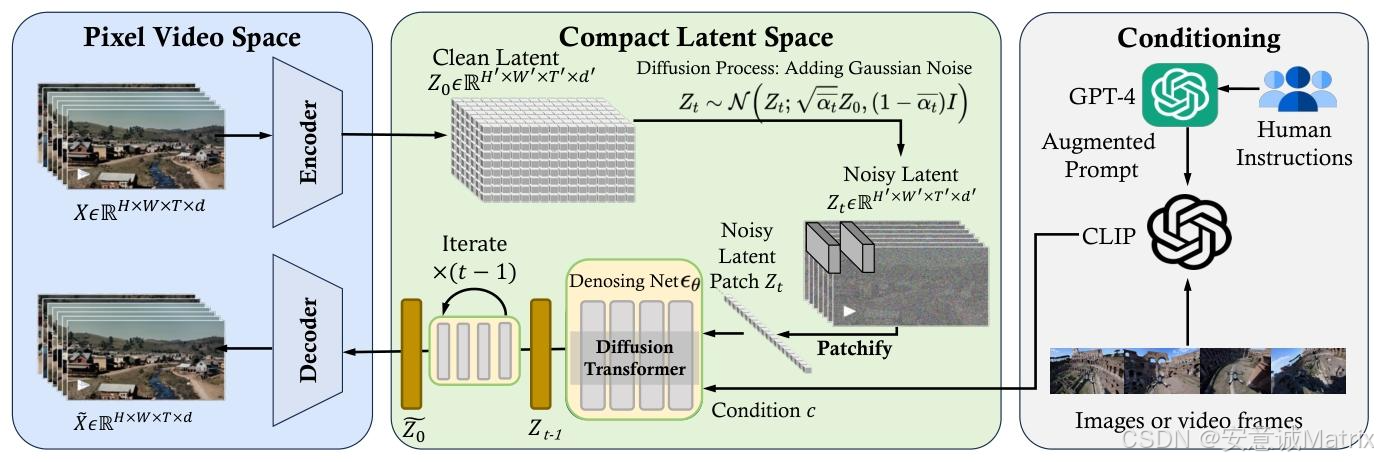
- Sora则可能在"潜在视频空间"中,通过时空建模的网络(如时空Transformer)逐步去噪,让噪声序列进化成连贯的视频片段。
二、核心差异:从"画纸"到"动态宇宙"的跨越
当从"生成单张图像"升级到"生成连续视频",技术挑战呈几何级增长,这也造就了Sora与文生图模型的本质差异:
1. 维度之战:2D像素 vs 3D时空
- 文生图模型 :聚焦2D空间维度,只需建模"高度×宽度×颜色通道"的像素分布,核心挑战是"单帧的细节、风格、语义一致性"(比如让生成的"赛博朋克城市"既有霓虹质感,又符合建筑逻辑)。
- Sora :直面3D时空维度,需同时建模"高度×宽度×时间帧×颜色通道"的时空分布。这意味着它不仅要关心"某一帧的画面好不好看",还要解决"帧与帧之间的运动是否连贯""物理规律是否合理"(比如"企鹅在广场跳踢踏舞",每只企鹅的动作幅度、节奏都得符合现实逻辑)。
2. 建模复杂度:单帧艺术 vs 时序叙事
- 文生图的潜在扩散 :在"潜在图像空间"中用2D U-Net或Transformer 做去噪,网络只需捕捉"空间上的像素依赖关系"(比如相邻像素的颜色、纹理关联)。训练数据是海量单张图像,学习目标是"把文字变成一张好看的图"。
- Sora的技术路径 (推测):大概率采用时空Transformer或3D卷积网络 ,既要捕捉"单帧内的空间细节",又要学习"帧与帧之间的时序依赖"(比如物体运动的加速度、轨迹连续性)。训练数据是大规模视频+多模态数据,学习目标是"把文字变成一段逻辑自洽的动态叙事"。
3. 应用边界:工具属性 vs 生产力革命
- 文生图模型 :定位是"创意工具",服务于插画师、设计师、自媒体人,解决"静态视觉内容的高效创作"(比如一键生成产品海报、小说封面)。
- Sora :野心是"生产力革命",瞄准影视、游戏、广告、短视频等行业,试图重构"动态内容的生产流程"(比如无需实拍就能生成电影片段、游戏CG,甚至替代部分剪辑、特效工作)。
三、演进启示:AIGC的下一站在哪里?
从"文生图"到"Sora"的技术跨越,其实暗含着AIGC的演进逻辑:
1. 技术互哺:静态与动态的双向赋能
文生图模型的"单帧细节建模能力"可以反哺视频生成(让Sora的每一帧都足够精美);而Sora的"时序建模技术"也能助力文生图模型的"动态扩展"(比如生成"图像序列动画")。这种技术互哺会让AIGC的边界持续拓宽。
2. 产业落地:从"辅助创作"到"定义创作"
文生图模型已经让"普通人创作专业级图像"成为现实;Sora则可能让"普通人创作专业级视频"成为可能。未来,AIGC将从"辅助工具"升级为"创作核心",重塑影视、游戏、广告等行业的生产关系。
3. 挑战与伦理:创意与责任的平衡
随着生成内容的"逼真度"和"叙事性"越来越强,"内容真实性鉴别""版权归属""虚假信息传播"等伦理挑战也会加剧。这需要技术开发者、行业从业者、监管机构共同构建"创新与责任并重"的生态。
结语
Sora与文生图潜在扩散模型的异同,本质是AIGC从"静态像素革命"到"动态时空革命"的缩影。前者让我们"画笔下的创意瞬间落地",后者让我们"脑海中的故事活起来"。这场从"画纸"到"银幕"的演进,才刚刚拉开序幕------谁又能预料,下一个突破会在哪个维度发生呢?
(注:Sora的具体技术细节尚未完全公开,本文分析基于行业共识与技术演进逻辑推测,仅供参考。)