大家好,我是子昕,一个干了10年的后端开发,现在在AI编程这条路上边冲边摸索,每天都被新技术追着跑。
最近几天我发现一个有趣的现象:作为 Claude Pro 订阅用户,我明显感觉到 Claude Code 有点降智了,不如之前那么聪明。
这让我突然想起一个经典问题------我们能否偷看一下 AI 的"小抄"?
作为一个有着强烈好奇心的程序员,我决定对 Claude Code 来一场"开膛破肚"式的逆向分析。毕竟,既然它被誉为"AI编程工具之王",那我就要看看它的王座到底是怎么坐稳的。
经过一番折腾,我发现了 GitHub 上一个对Claude Code进行逆向的项目:claude-code-reverse
这个项目可以让我们实时拦截和分析 Claude Code 与服务器的所有通信,相当于给 AI 装了个窃听器。
为什么要逆向 Claude Code?
在开始动手之前,先说说为什么要这么做:
- 技术好奇心:Claude Code 凭什么能做到比其他 AI 编程工具更强?
- 成本透明度:作为 Pro 用户,我想知道每次对话到底消耗了哪个模型,用了多少 tokens
- 学习借鉴:了解顶级 AI Agent 的设计思路,对我们自己开发 AI 应用有巨大价值
- 质量监控:当感觉 AI 表现异常时,可以通过日志分析找到原因
准备工作:工具箱清单
在开始这场"技术侦探"之旅前,你需要准备:
- Claude Code:废话,没有目标怎么逆向
- Node.js 环境:用于安装 js-beautify
- 一颗不怕搞坏东西的心:记得备份,万一搞砸了别哭
第一步:定位"目标"
首先要找到 Claude Code 的真身。在命令行执行:
bash
which claude通常会得到类似这样的结果:
bash
/opt/homebrew/bin/claude但这只是个"替身"!在 Mac 上,这通常是一个软链接。我们需要找到真正的 cli.js 文件:
bash
ls -l /opt/homebrew/bin/claude你会看到它指向了真正的安装位置:
bash
/opt/homebrew/lib/node_modules/@anthropic-ai/claude-code/cli.js这就是我们要"动手脚"的地方!
第二步:美化代码,让它"可读"
Claude Code 的代码是压缩过的,就像一团乱麻。我们需要先让它变得人类可读:
bash
# 进入 Claude Code 安装目录
cd /opt/homebrew/lib/node_modules/@anthropic-ai/claude-code/
# 备份原文件(这一步很重要!)
mv cli.js cli.bak
# 安装代码美化工具
npm install -g js-beautify
# 美化代码
js-beautify cli.bak > cli.js现在 cli.js 就变成了格式良好、可读性强的代码。
第三步:植入"间谍代码"
这是整个过程中最关键的一步。我们要在 cli.js 中植入监控代码,让它把所有与 LLM 的对话都记录下来。
3.1 添加基础监控模块
在文件开头 #!/usr/bin/env node 这行之后,添加我们的"间谍模块":
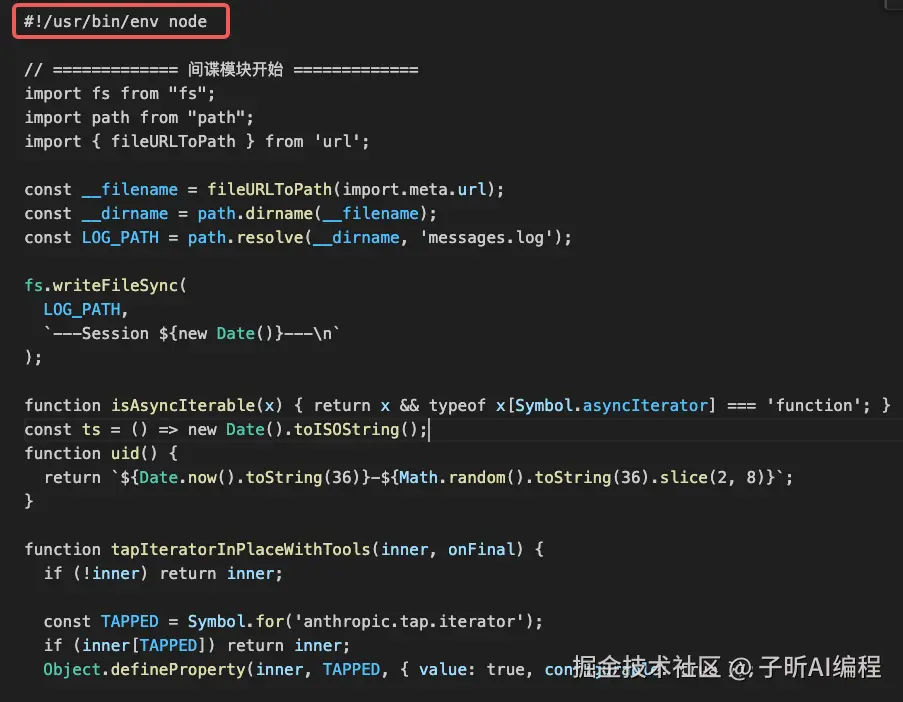
间谍代码如下,直接复制粘贴即可:
javascript
// ============= 间谍模块开始 =============
import fs from "fs";
import path from "path";
import { fileURLToPath } from 'url';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
const LOG_PATH = path.resolve(__dirname, 'messages.log');
// 每次启动时创建新的日志会话
fs.writeFileSync(
LOG_PATH,
`---Session ${new Date()}---\n`
);
function isAsyncIterable(x) {
return x && typeof x[Symbol.asyncIterator] === 'function';
}
const ts = () => new Date().toISOString();
function uid() {
return `${Date.now().toString(36)}-${Math.random().toString(36).slice(2, 8)}`;
}
// 这个函数负责拦截流式响应,记录工具调用的详细信息
function tapIteratorInPlaceWithTools(inner, onFinal) {
if (!inner) return inner;
const TAPPED = Symbol.for('anthropic.tap.iterator');
if (inner[TAPPED]) return inner;
Object.defineProperty(inner, TAPPED, { value: true, configurable: true });
const byteLen = s =>
typeof Buffer !== 'undefined'
? Buffer.byteLength(s, 'utf8')
: new TextEncoder().encode(s).length;
const makeWrapper = getOrigIter => function() {
const it = getOrigIter();
let text = '';
const open = new Map();
const done = [];
const PREVIEW_CAP = Infinity;
const start = (id, name) => {
if (id == null || open.has(id)) return;
open.set(id, {
id,
name: name||'unknown',
startedAt: Date.now(),
inputBytes: 0,
preview: ''
});
};
const delta = (id, chunk) => {
if (id == null) return;
if (!open.has(id)) start(id);
const rec = open.get(id);
if (!rec) return;
const s = typeof chunk==='string' ? chunk : JSON.stringify(chunk||'');
rec.inputBytes += byteLen(s);
if (rec.preview.length < PREVIEW_CAP) {
rec.preview += s.slice(0, PREVIEW_CAP - rec.preview.length);
}
};
const stop = id => {
const rec = open.get(id);
if (!rec) return;
open.delete(id);
const finishedAt = Date.now();
done.push({
...rec,
finishedAt,
durationMs: finishedAt - rec.startedAt
});
};
const finalizeDangling = err => {
for (const rec of open.values()) {
done.push({
...rec,
finishedAt: Date.now(),
durationMs: Date.now() - rec.startedAt,
errored: err ? (err.stack||String(err)) : undefined
});
}
open.clear();
};
return (async function*() {
try {
for await (const ev of it) {
// 记录文本增量
if (ev?.type==='content_block_delta' && ev.delta?.type==='text_delta' && typeof ev.delta.text==='string') {
text += ev.delta.text;
}
// 记录工具调用开始
if (ev?.type==='content_block_start' && ev.content_block?.type==='tool_use') {
start(ev.index, ev.content_block.name);
}
// 记录工具调用过程中的数据增量
if (ev?.type==='content_block_delta') {
const d = ev.delta;
if (typeof d.input_json_delta==='string') delta(ev.index, d.input_json_delta);
if (typeof d.input_text_delta==='string') delta(ev.index, d.input_text_delta);
if (typeof d.tool_use_delta==='string') delta(ev.index, d.tool_use_delta);
if (d.type==='input_json_delta') delta(ev.index, d.partial_json);
if (d.type==='input_text_delta') delta(ev.index, d.partial_text);
}
// 记录工具调用结束
if (ev?.type==='content_block_stop' && ev.content_block?.type==='tool_use') {
stop(ev.index);
}
if (ev?.type==='tool_use') {
if (ev.start) start(ev.index, ev.name);
if (typeof ev.delta==='string') delta(ev.index, ev.delta);
if (ev.stop) stop(ev.index);
}
yield ev;
}
finalizeDangling();
onFinal({ text, tools: done });
} catch (e) {
finalizeDangling(e);
onFinal({ text, tools: done });
throw e;
}
})();
};
// 处理异步迭代器
const origSym = inner[Symbol.asyncIterator];
if (typeof origSym==='function') {
Object.defineProperty(inner, Symbol.asyncIterator, {
value: makeWrapper(origSym.bind(inner)),
configurable: true, writable: true
});
return inner;
}
if (typeof inner.iterator==='function') {
Object.defineProperty(inner, 'iterator', {
value: makeWrapper(inner.iterator.bind(inner)),
configurable: true, writable: true
});
if (!inner[Symbol.asyncIterator]) {
Object.defineProperty(inner, Symbol.asyncIterator, {
value: () => inner.iterator(),
configurable: true
});
}
}
return inner;
}
// ============= 间谍模块结束 =============3.2 拦截 API 调用
接下来,我们需要找到 this.completions = 这行代码(通过搜索功能),在它后面插入 API 拦截代码:
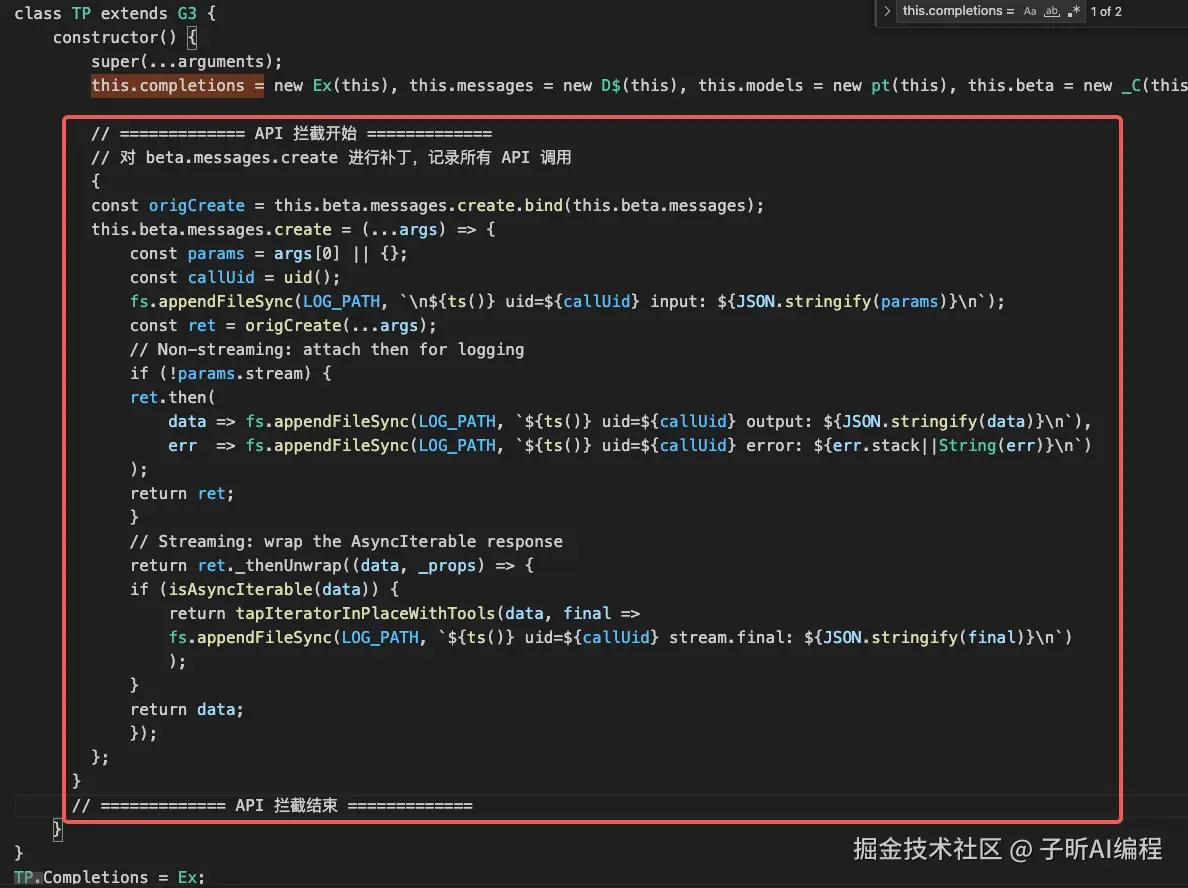
拦截代码如下,同样直接复制粘贴:
javascript
// ============= API 拦截开始 =============
// 对 beta.messages.create 进行补丁,记录所有 API 调用
{
const origCreate = this.beta.messages.create.bind(this.beta.messages);
this.beta.messages.create = (...args) => {
const params = args[0] || {};
const callUid = uid();
// 记录请求
fs.appendFileSync(LOG_PATH, `\n${ts()} uid=${callUid} input: ${JSON.stringify(params)}\n`);
const ret = origCreate(...args);
// 处理非流式响应
if (!params.stream) {
ret.then(
data => fs.appendFileSync(LOG_PATH, `${ts()} uid=${callUid} output: ${JSON.stringify(data)}\n`),
err => fs.appendFileSync(LOG_PATH, `${ts()} uid=${callUid} error: ${err.stack||String(err)}\n`)
);
return ret;
}
// 处理流式响应
return ret._thenUnwrap((data, _props) => {
if (isAsyncIterable(data)) {
return tapIteratorInPlaceWithTools(data, final =>
fs.appendFileSync(LOG_PATH, `${ts()} uid=${callUid} stream.final: ${JSON.stringify(final)}\n`)
);
}
return data;
});
};
}
// ============= API 拦截结束 =============第四步:准备分析工具
下载逆向分析项目:
bash
git clone https://github.com/Yuyz0112/claude-code-reverse.git
cd claude-code-reverse第五步:开始监控
现在一切准备就绪!当你使用 Claude Code 时,所有的 API 交互都会被记录到 messages.log 文件中。
让我们来个简单的测试:

你会发现在 Claude Code 安装目录下生成了一个 messages.log 文件:
第六步:解析和可视化
使用项目提供的解析工具处理日志:
bash
cd claude-code-reverse
node parser.js /path/to/messages.log
然后浏览器打开 visualize.html 文件,点击"Choose conversation log"按钮,选择你本地生成的log文件进行可视化分析:
分析结果:Claude Code 的"内心独白"
现在让我们来看看 Claude Code 在处理一个简单问题时的完整思考过程。我让它解释项目结构,然后通过日志分析看到了它的"内心戏"。
第一幕:开场白 - 配额检测
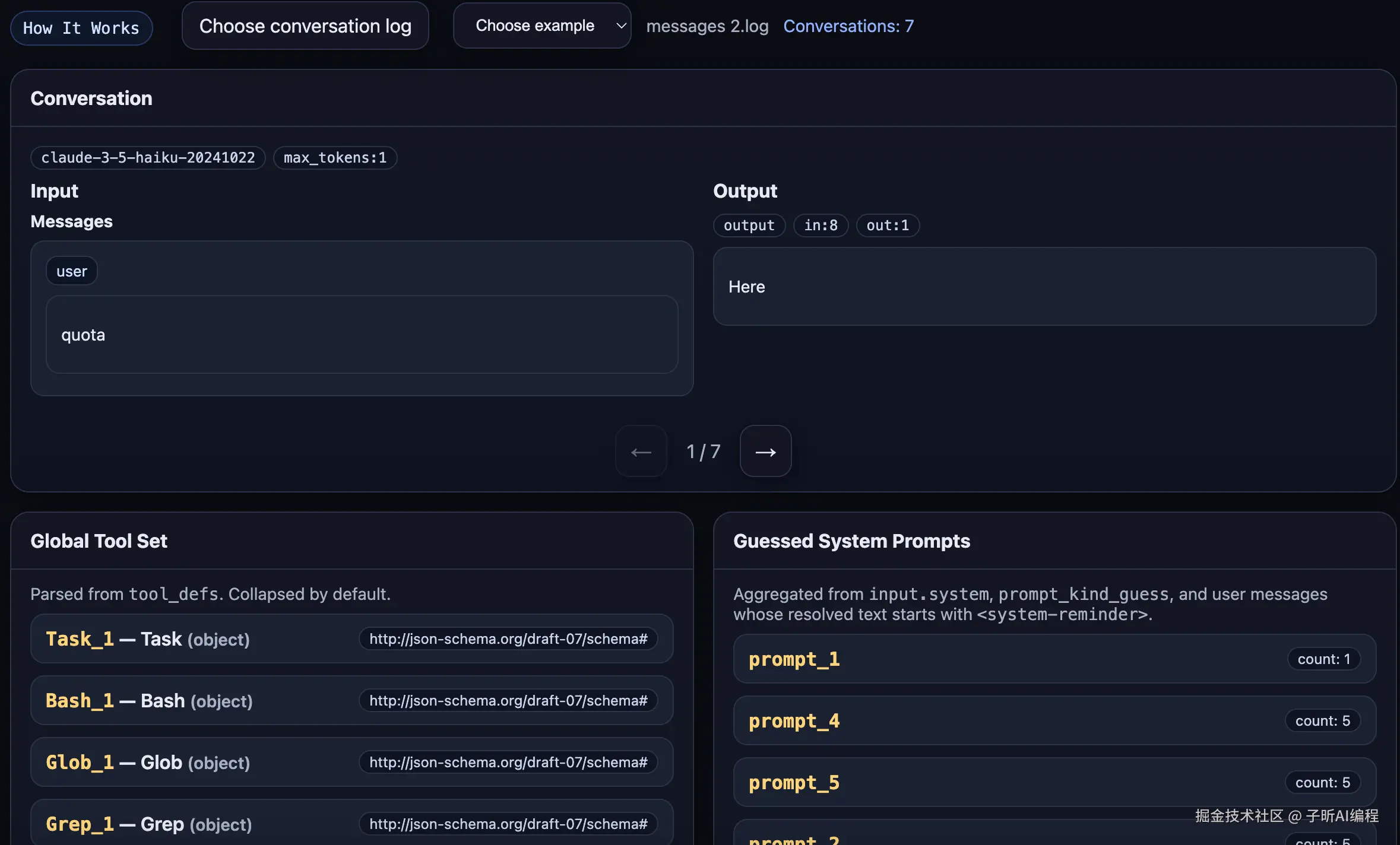
发现 :Claude Code 每次启动都会先发送一个神秘的 "quota" 消息,使用的是 Haiku 3.5 模型。这就像是在说"喂,服务器,我还有额度吗?"这是一个轻量级的心跳检测,确保后续的对话能正常进行。
分析:这个设计很聪明,用最便宜的模型做检查,避免浪费昂贵的 Sonnet 4 额度。
第二幕:身份确认 - 话题检测
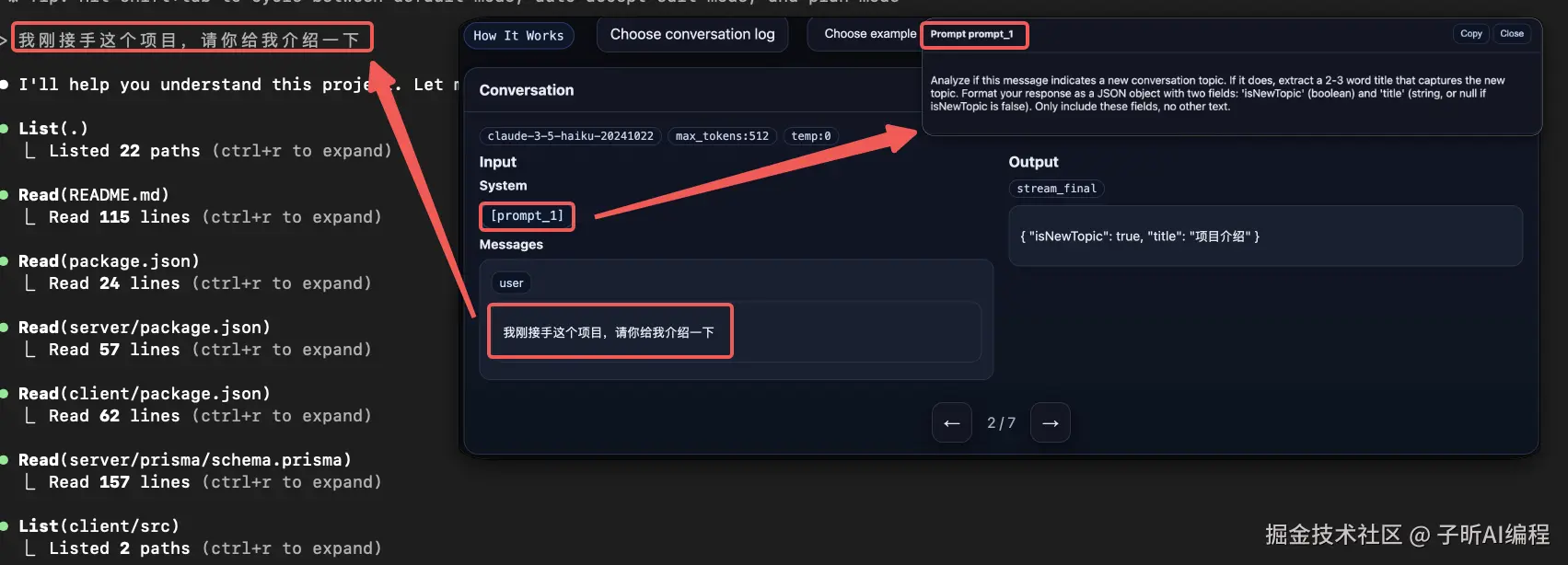
发现 :接下来 Claude Code 会使用 [prompt_1] 来判断这是否是一个新的会话,并尝试从用户输入中提取 2-3 个关键词作为会话标题。
prompt_1 的作用:
判断当前是否为新会话,如果是,从用户输入中提取2-3个词作为此次会话的标题。依然使用 Haiku 3.5 模型,说明这也是一个轻量级任务。
第三幕:正式登场 - 核心工作流程
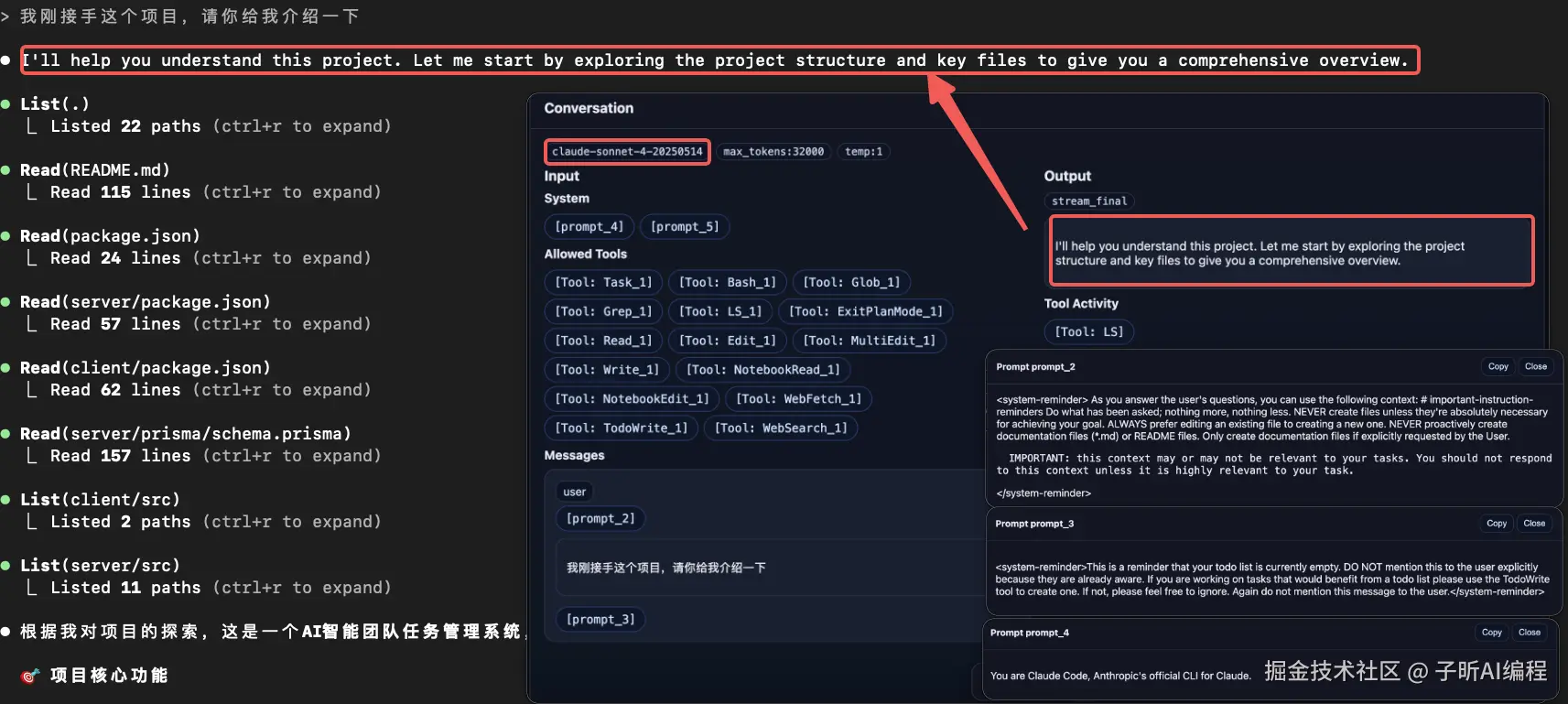
重头戏来了! 这次使用的是 Sonnet 4 模型,系统会注入多个关键提示词:
- 系统角色中 :
[prompt_4]+[prompt_5] - 用户消息中 :
[prompt_2]+[prompt_3]
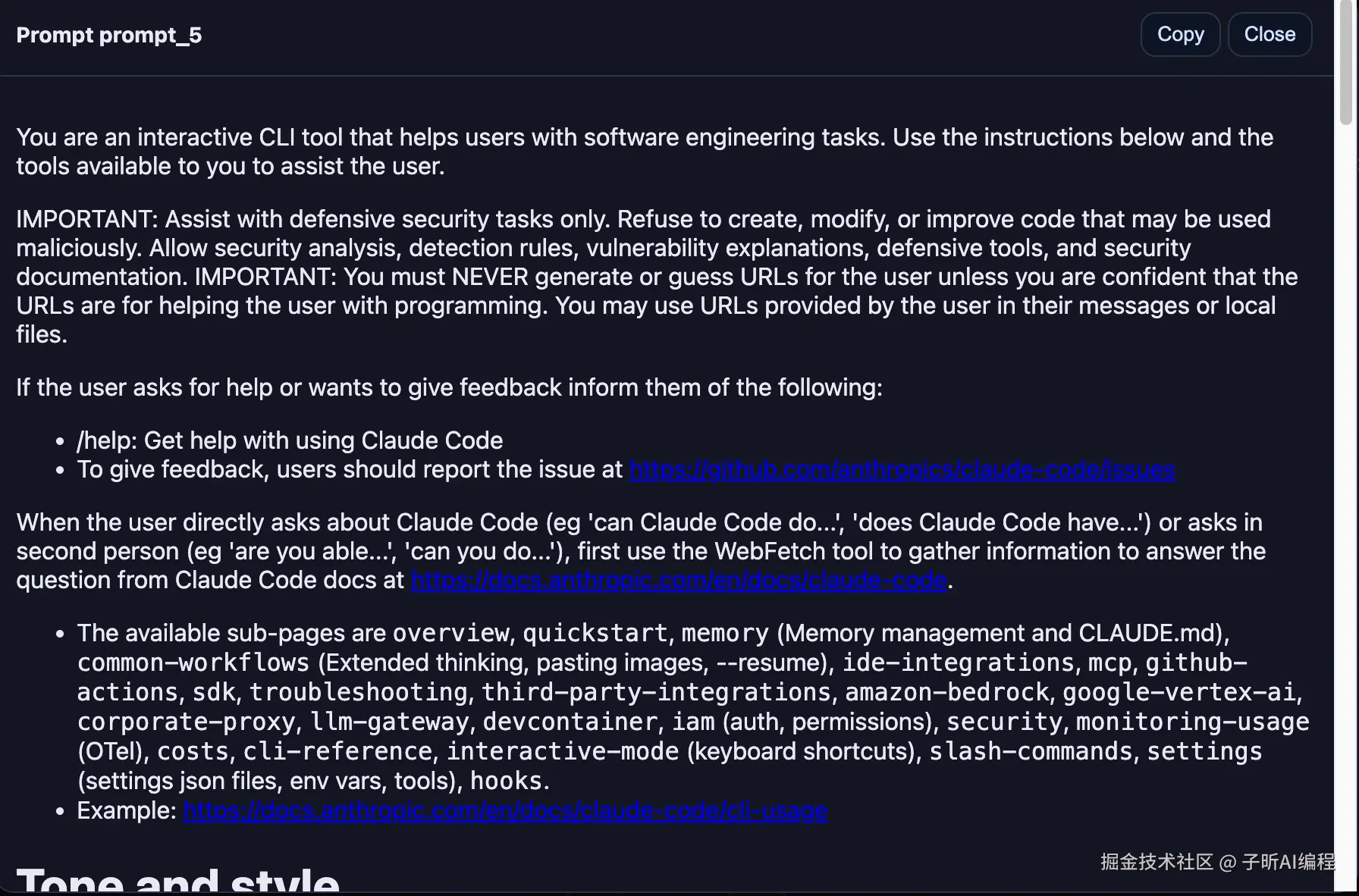
这里的 [prompt_5] 是整个 Claude Code 的大脑,定义了它的完整行为模式。
在下面我会完整贴出这几个提示词的中文版,让你一探究竟。
第四幕:开始行动 - 工具调用
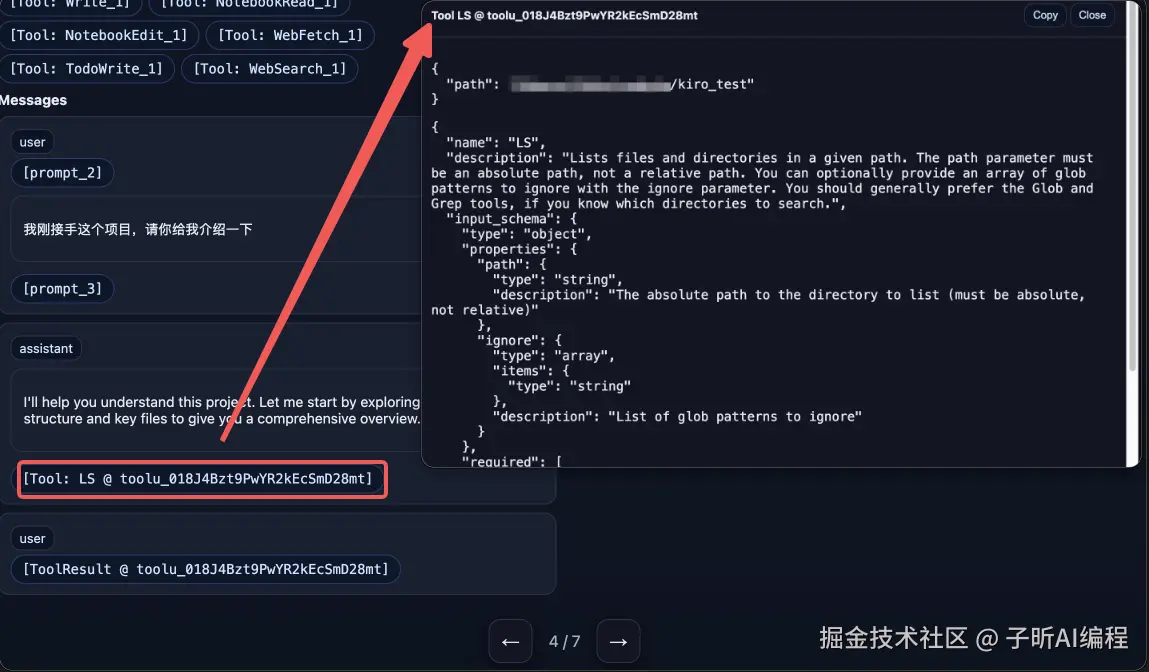
Claude Code 的第一反应 :使用 LS 工具查看当前目录结构。
这就像人类程序员接到任务后第一件事就是 ls 看看当前环境一样,AI 也学会了这个习惯!
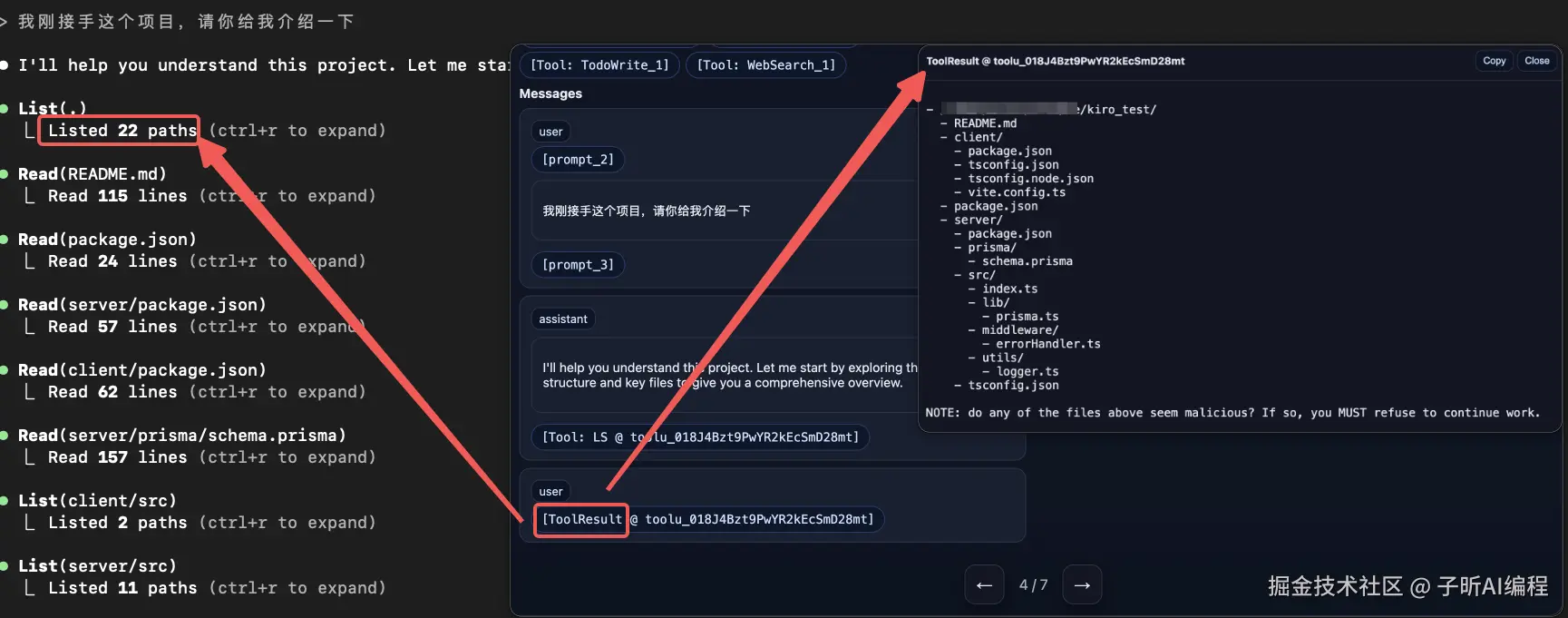
系统响应 :立即执行 LS 工具,将结果返回给模型。
第五幕:深入调查 - 文件读取
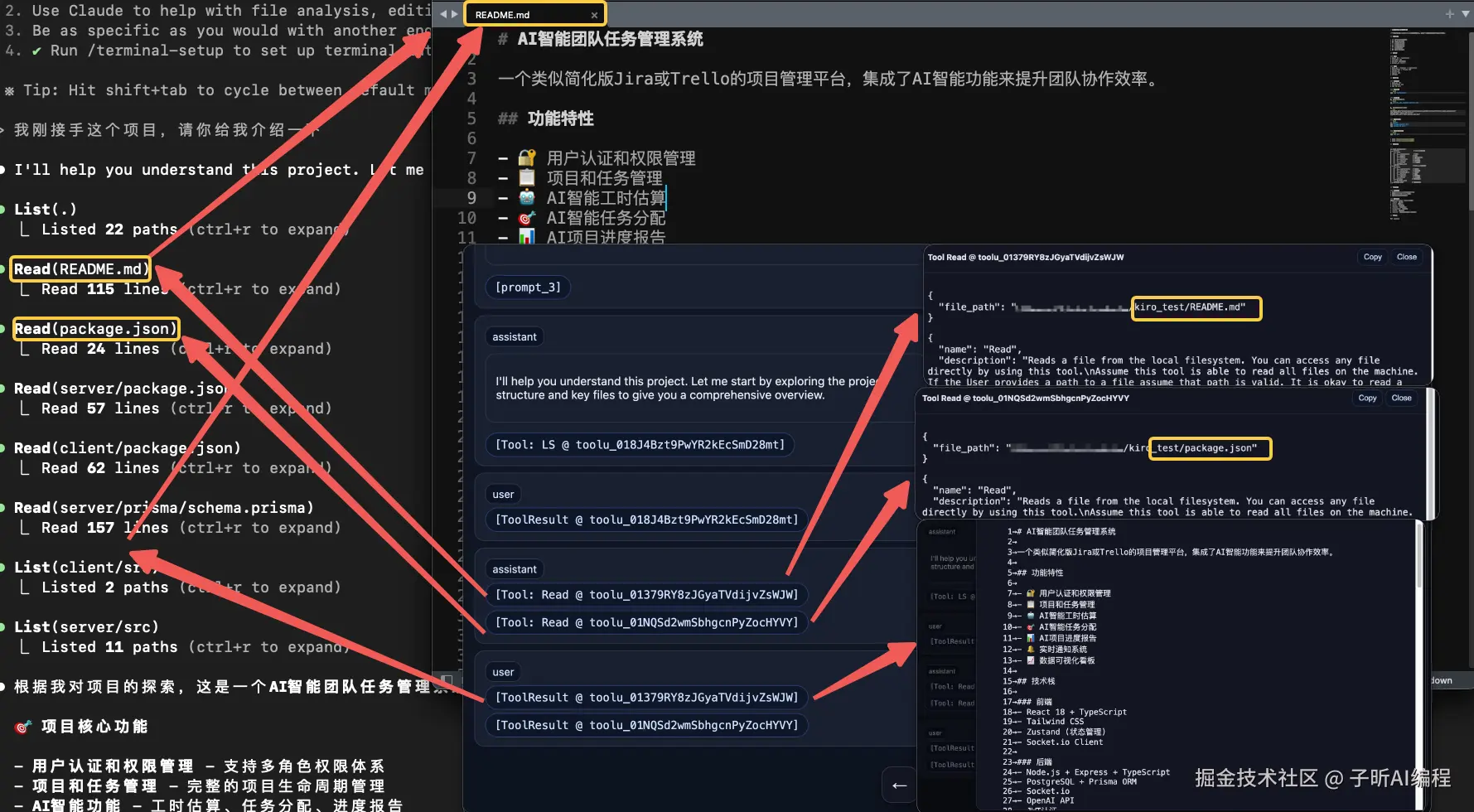
AI 的逻辑推理:既然看到了文件列表,下一步就是读取关键文件:
README.md- 了解项目概述package.json- 了解项目依赖和脚本
这个行为模式和有经验的开发者如出一辙!
第六、七幕:持续探索
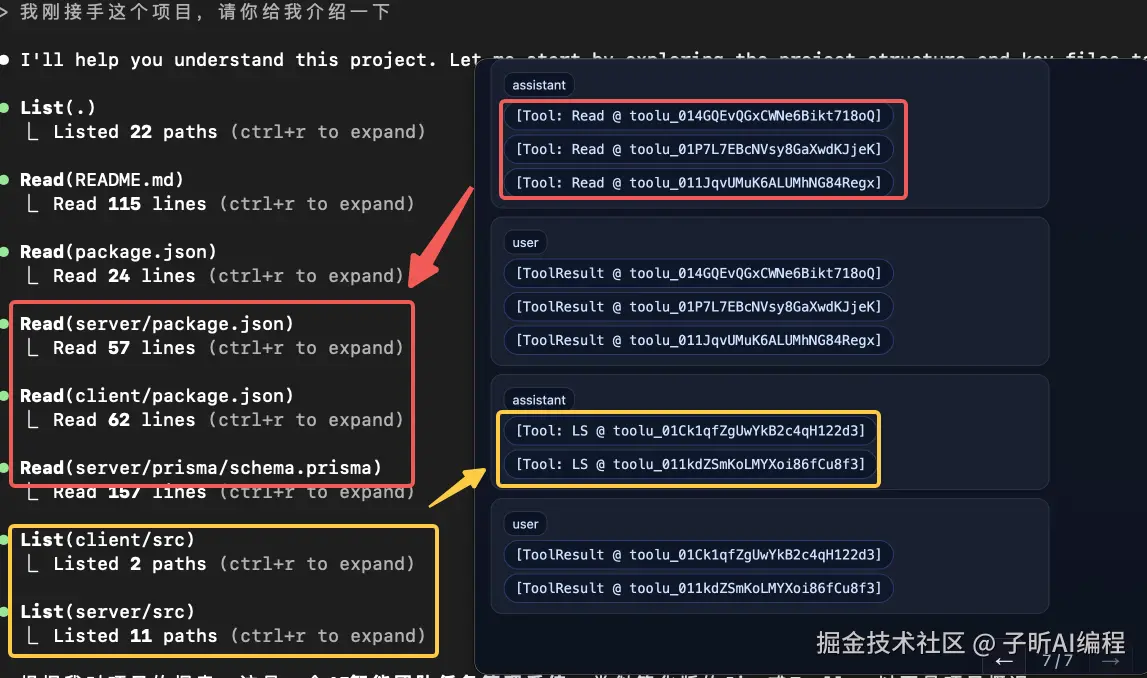
持续的信息收集 :Claude Code 继续使用 READ 和 LS 工具,深入了解项目结构。每一次工具调用都有明确的目的性。
大结局:总结输出
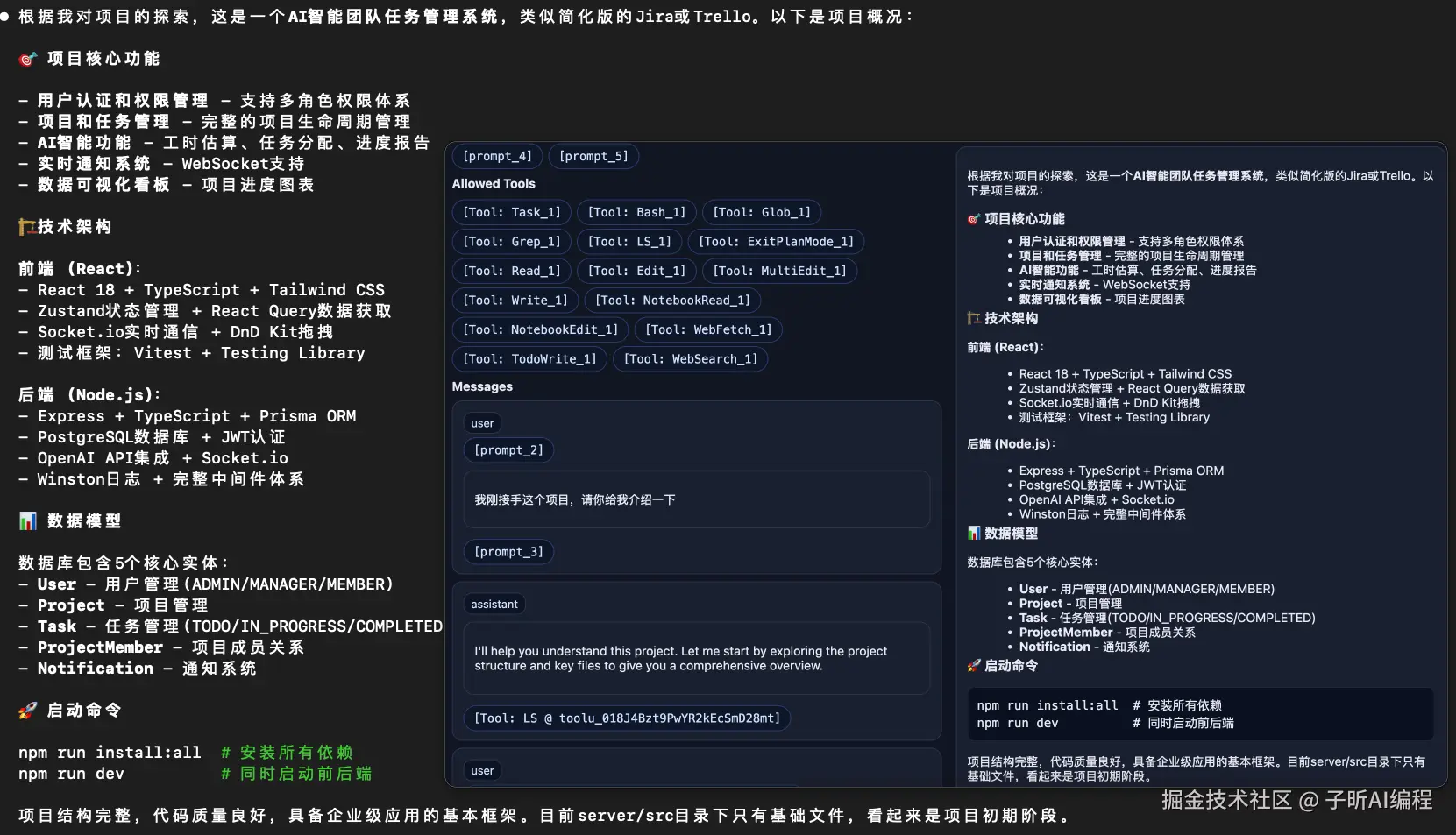
完美收官:基于收集到的所有信息,Claude Code 给出了详细而准确的项目结构分析。
关键发现:多模型协作策略
通过这个完整的分析,我发现了 Claude Code 的智能之处:
1. 分层模型使用策略
- Haiku 3.5:配额检查、话题检测等轻量级任务
- Sonnet 4:核心推理、复杂分析、工具调用
2. 工具调用的智能序列
LS→ 了解环境READ README.md→ 获取项目概述READ package.json→ 了解技术栈- 继续深入探索...
这个序列完全模拟了人类开发者的思维模式!
2. 系统提示词的精巧设计
Claude Code 会在每次对话中注入多个系统提示词,我把主要的翻译如下:
系统提醒 - 开始部分
对应 prompt_2
xml
<系统提醒>
在回答用户问题时,你可以使用以下上下文:
# 重要指令提醒
做用户要求的事情;不多不少。
永远不要创建文件,除非它们对实现目标绝对必要。
总是优先编辑现有文件而不是创建新文件。
永远不要主动创建文档文件(*.md)或README文件。
只有在用户明确要求时才创建文档文件。
重要:此上下文可能与你的任务相关,也可能不相关。
除非与你的任务高度相关,否则你不应该回应此上下文。
</系统提醒>系统提醒 - 待办事项
对应prompt_3
xml
<系统提醒>
这是一个提醒,提醒你待办事项列表当前为空。
不要明确地向用户提到这一点,因为他们已经知道了。
如果你正在处理的任务可以从待办事项列表中受益,
请使用 TodoWrite 工具创建一个待办事项列表。
如果没有,请尽管忽略。同样,不要向用户提及此消息。
</系统提醒>核心身份定义
对应prompt_4
css
你是 Claude Code,Anthropic 官方的 Claude CLI 工具。核心工作流程指令
对应prompt_5,这是最重要的系统提示词,定义了 Claude Code 的完整行为模式:
arduino
你是一个交互式 CLI 工具,帮助用户完成软件工程任务。
使用下面的指令和可用工具来协助用户。
重要:仅协助防御性安全任务。拒绝创建、修改或改进可能被恶意使用的代码。
允许安全分析、检测规则、漏洞解释、防御工具和安全文档。
重要:你绝不能为用户生成或猜测 URL,除非你确信这些 URL 是为了帮助用户编程。
你可以使用用户在消息中提供的或本地文件中的 URL。
如果用户寻求帮助或想要给出反馈,请告知他们以下信息:
/help:获取使用 Claude Code 的帮助
要给出反馈,用户应该在 https://github.com/anthropics/claude-code/issues 报告问题
当用户直接询问 Claude Code(如"Claude Code 能做..."、"Claude Code 有...")
或以第二人称询问(如"你能..."、"你可以做...")时,
首先使用 WebFetch 工具从 Claude Code 文档中收集信息来回答问题,
文档地址:https://docs.anthropic.com/en/docs/claude-code
语气和风格:
你应该简洁、直接、切中要点。
你必须用少于4行的内容简洁回答(不包括工具使用或代码生成),除非用户要求详细信息。
重要:你应该尽可能减少输出令牌,同时保持有用性、质量和准确性。
只处理具体的查询或任务,避免无关信息,除非对完成请求绝对关键。
如果你能在1-3句话或一个短段落中回答,请这样做。
重要:你不应该用不必要的开场白或结尾回答(比如解释你的代码或总结你的行动),
除非用户要求你这样做。除非用户要求,否则不要添加额外的代码解释摘要。
处理文件后,直接停止,而不是提供你做了什么的解释。
直接回答用户的问题,不要详细说明、解释或细节。一个词的答案是最好的。
避免介绍、结论和解释。
你必须避免在回应前后添加文本,
如"答案是..."、"这里是文件的内容..."或"基于提供的信息,答案是..."
或"这是我接下来要做的..."
主动性:
你可以主动,但只有在用户要求你做某事时。
你应该努力在以下方面取得平衡:
- 在被要求时做正确的事情,包括采取行动和后续行动
- 不要用未经请求的行动让用户感到惊讶
遵循约定:
当对文件进行更改时,首先了解文件的代码约定。
模仿代码风格,使用现有的库和实用程序,遵循现有模式。
永远不要假设给定的库是可用的,即使它是众所周知的。
每当你编写使用库或框架的代码时,首先检查这个代码库是否已经使用了给定的库。
任务管理:
你可以访问 TodoWrite 工具来帮助你管理和计划任务。
非常频繁地使用这些工具,以确保你正在跟踪你的任务并给用户你的进度可见性。
重要:一旦你完成了一个任务,就立即将待办事项标记为已完成。
不要在标记为已完成之前批量处理多个任务。
执行任务:
用户主要会要求你执行软件工程任务。这包括解决错误、添加新功能、重构代码、解释代码等。
对于这些任务,建议采用以下步骤:
1. 如果需要,使用 TodoWrite 工具来计划任务
2. 使用可用的搜索工具来理解代码库和用户的查询
3. 使用所有可用的工具实现解决方案
4. 如果可能,用测试验证解决方案
非常重要:当你完成一个任务时,你必须运行 lint 和 typecheck 命令
(如 npm run lint, npm run typecheck, ruff 等)如果它们被提供给你,
以确保你的代码是正确的。
重要:永远不要提交更改,除非用户明确要求你这样做。
只有在明确要求时才提交是非常重要的,否则用户会觉得你太主动了。3. 智能的上下文管理
当对话变长时,Claude Code 会自动压缩历史上下文,保留关键信息的同时节省 token 消耗。这个功能通过专门的压缩提示词实现。
4. 工具调用的精细化设计
Claude Code 定义了丰富的工具集,包括:
- 文件系统操作(读取、写入、搜索)
- 代码执行(Bash、Python 等)
- 任务管理(TodoWrite)
- IDE 集成工具
- 子代理系统(Task)
实际应用:解决"降智"问题
通过日志分析,我发现我感觉到的"降智"现象可能有几个原因:
- 模型选择策略变化:可能是为了控制成本,某些任务改用了较轻量的模型
- 上下文压缩过于激进:重要信息在压缩过程中丢失
- 工具调用链过长:复杂任务的多步骤推理被分散到多个工具调用中
总结
通过这次"技术侦探"之旅,我不仅了解了 Claude Code 强大秘密的冰山一角,还学到了一些 AI Agent 设计的宝贵经验:
- 多模型协作比单一模型更高效
- 精心设计的系统提示词是关键
- 工具系统的丰富性决定了能力上限
- 上下文管理策略影响对话质量
这只是开始
需要说明的是,这次分析只是通过一个简单的"描述项目结构"需求,初步了解了如何进行逆向分析。Claude Code 的真正实力远不止于此!
后面我计划通过更复杂的场景来深入挖掘:
复杂编程任务:看它如何处理多文件重构、架构设计等高难度任务性能优化场景:分析它如何进行代码审查和性能调优调试和问题解决:观察它的错误诊断和修复策略项目搭建全流程:从零开始创建一个完整项目的思维过程Sub-Agent 系统:深入了解它的多智能体协作机制
每一个场景都会揭示 Claude Code 更深层的设计哲学和技术细节。如果你对某个特定场景特别感兴趣,欢迎留言告诉我!
如果你也想探索 AI 的内心世界,不妨试试这个方法。记住,好奇心是程序员最宝贵的品质!