不是高并发项目,就真的用不到限流熔断吗?
昨晚下班回家,我跟我哥边吃饭边聊天。
他一边扒饭,一边说:"我有个朋友昨天去面试了,你猜人家都问了啥?"
他去面试的是一家做教育的公司,规模不大,总共就十几个人,创业型公司, 面试官也是公司老板兼技术负责人,属于一人多岗型选手。
一开始技术基础八股文什么的还聊得挺正常,问项目经历啥的,接着就有问到:
"你之前做的项目 QPS 大概多少?"
"并发量多大?是怎么支撑的?用什么架构?多少台服务器? 几个节点?"
他朋友当时想了一下,脑子飞快过了一遍以前做过的项目,然后自然地把之前参与的系统夸了一波,讲了讲项目背景、技术栈、团队情况......
后面面试官又问道:
"那你们项目中做过限流、熔断、降级这些并发防护吗?哪些业务场景里用到过?"
他朋友当场一愣,脑子里飞快过了一遍自己写过的接口,但------好像真没做过......。事后跟我哥吐槽说:
"这问题我听说过,但说实话,还真没实际做过,再说我们那项目体量 也根本用不到啊......这怎么答?
难不成说'我们业务没这么大压力所以也没用'?或者说 项目全靠服务器扛? 出了问题就重启?这不就默认自己菜了吗?"
但实际就是这样啊。很多中小公司、创业团队,项目本身压力没那么大,服务跑得风平浪静,CPU 都不带飙的,哪来的"高并发"?
更别说什么限流、熔断、降级.....听说过归听说过,文档也刷过几遍,这不是属于八股文吗?但项目里根本没机会实战,甚至连"为什么要做"都没太多感知。
不是不想搞,而是公司项目根本没触发那个"必须搞"的场景啊?!
但是也不能指着面试官说:"你问这玩意儿不合理!" 从面试的角度来说,他其实是在通过这些问题来 "反推"我们的能力边界。
想看看我们有没有做过复杂场景、是不是接触过真正的大中型项目,
有没有写过需要"思考系统稳定性"的代码,
又或者说....咱是不是只会写增删改查的 CRUD。
虽然我们工作才五六年 但是我要的工资高啊 总不能啥也不没做过吧.....😅
那问题来了:
我们项目不是高并发的,就真的不需要限流、熔断、降级吗?
做这些是不是属于"无效架构"?
还是说......其实我们也能做点"变相"的限流降级,只是没意识到?
当然,站在普通开发者的角度,有时候这些"系统防护"根本不是我们主要考虑的东西,
毕竟业务赶得紧,功能写完就上线,稳定性那是"运维 + 架构"的事儿。
但如果我们的简历上,写过什么"技术负责人""主程"这种角色,
那再说从没考虑过限流熔断这些,就确实有点说不过去了。
毕竟角色不同,对系统的思考深度也应该不一样哈。
那我们的项目里,什么时候真的会用到这些?
好,那说到底------
我们这些中小项目、单体服务、并发不高的系统,到底在哪些场景下真的会用到限流、熔断、降级这些机制呢?
是不是非得等到 QPS 上万,服务器被打爆,才配做这些事?
限流到底是干嘛的?
简单点讲,限流就是控制请求频率,防止某个接口被一瞬间打爆。
它不是专门给"高并发项目"准备的,
而是任何系统只要出现"频繁调用、重接口、外部依赖"等情况,限流就能派上用场。
举个很常见的例子:
登录页面点 5 次"获取验证码",我们收到了 5 条短信,还被扣了几毛钱。
你以为只是前端加了个"倒计时"?其实后端也得限一下,不然就等着被刷爆吧。
为什么要限流?
你可能会说:我这小项目 QPS 都没上百,要啥限流?
但其实吧......
限流并不一定是为了"抗住大流量",
更多时候是为了防误操作、防浪费、防止被滥用或者刷爆接口。
不限流可能出啥事?
- 一个用户狂点接口,拖慢整体性能
- AI 生图接口一人请求 50 次,直接把显卡跑崩
- 第三方接口卡住,我们请求排队等死
- 被爬虫刷注册、刷下单、刷接口
我们不管,就相当于在门口挂了个牌子写着:
"随便进、无限用、服务器我请!"
那不好意思,哪天真来个"猛男"刷我们接口几万次,那我们可能连日志都看不清了......
用了限流能带来什么?
- 明确控制每个用户/IP 的调用频率,避免滥用
- 给系统"兜个底",出问题也能保护核心服务
- 提前暴露异常调用或接口设计问题
- 面试官问起来能掏点干货,不至于卡壳。
那熔断又是啥?
简单讲,熔断就是"我知道你那边有问题,那我就暂时不找你了" 。
它的作用是------当某个接口 / 服务频繁失败时,主动"断开"调用,避免继续浪费资源,还可能拖累自己。
说白了,就是服务之间的"自我保护机制"。
为什么要做熔断?
假设我们在项目中调用了一个短信服务商的接口,用户点击"发送验证码"后,系统会向第三方发送请求。
但最近这个短信服务老是出问题:不是超时、就是接口 500。
如果我们不加熔断,每个请求都死等,接口一旦出故障,用户那边就卡着不动。
更严重的是,我们这边的线程池、连接数、资源都被这些失败请求占满了,导致别的接口也跟着受影响------
原本挂的是三方接口,现在连自己服务也慢了,最后全挂了。
而且更糟的是------这种情况我们后台可能一开始根本感知不到,毕竟是第三方的接口。 日志看起来只是"偶尔失败",但用户那边早就打不开页面、验证码收不到了。
那我们只能等用户来反馈,等到客服群开始炸、客诉量上来了,事故其实已经很严重了。
这就是最典型的"被拖死",一条链子上,哪怕只是最末端一个环节出问题,都会影响整个系统的稳定性。
这时候,如果我们加了熔断,系统就能这么做:
哎?这个短信接口最近挂得挺频繁,那我暂停调用几秒,等恢复了我再继续试。
这样不仅能保全调用方(比如我们本地服务),还能给对方(被压垮的服务)一个喘息的机会。
不做熔断会怎样?
- 一个接口挂了,全链路都跟着报错
- 数据库慢查询拖垮整个服务
- AI 接口崩了,但我们还在死等结果
- 出现雪崩效应(一个依赖挂了,拖死一片)
说白了,不做熔断,就像服务之间没有"安全断路器"。
一个人感冒,结果全公司都病倒了。
那什么时候需要用到熔断?
- 比如我们依赖的服务/接口 不稳定、响应慢、容易挂
- 某些外部系统接口(如三方 API、支付、OCR) 出现频繁失败
- 某个模块处理能力有限,但调用量突然暴涨
- 用户请求对接多个服务,其中某个服务宕了
这些场景下,如果我们没有兜底逻辑,可能一个失败请求就变成全系统的灾难源。
最后说的降级是啥?为啥要做?
简单讲:降级就是在服务不太行的时候,先不做"全量功能",但也不至于直接挂。
它跟熔断不一样,熔断是"我不请求了",而降级更像是:"我请求失败了,那我换个'备胎方案'。"
比如说:
- 接口超时,就别真等着,一秒不行我就给个默认值;
- 搜索服务挂了,我先返回几个热词;
- 商品详情查不到库存,那我显示"请联系客服";
- 发验证码服务炸了?那我告诉用户"系统繁忙,请稍后再试",而不是让页面一直 loading。
不做降级会怎么样?
很简单:服务一出问题,我们就只能"黑"在那儿。
用户体验暴跌,接口响应慢,前端加载失败,甚至带崩整个系统。
特别是当我们依赖多个子系统时,一个点挂掉,可能全站瘫痪。
但如果我们加了降级,就可以做到"哪怕部分功能不可用,核心流程还能跑"。
什么场景下需要做降级?
其实很多时候,我们不是所有接口都非得"完美返回",有些功能挂了不影响主流程,这时候就该果断降级,该退一步就退一步,别硬撑。
常见的适合做降级的场景有这些:
- 非核心功能:比如推荐列表、弹窗广告、评论数这种,挂了也不至于影响下单、支付,就可以选择直接屏蔽或返回空数据。
- 依赖第三方的接口:像天气服务、短信、支付、内容审核这些,出了问题我们也控制不了,那就要准备降级方案,不然挂他们也拖着我们崩。
- 大促或高并发压测场景:一到高峰,数据库、消息队列、缓存全上压力,这时候可以先降级一些耗资源的非关键功能,比如关闭动画、关闭排行榜、减少接口字段。
- 缓存失效的兜底策略:比如 Redis 挂了或者大面积失效,为了不让数据库被瞬间冲爆,接口可以直接走"空返回""部分缓存""默认数据"等兜底方案。
- 非核心场景、可有可无的内容:比如推荐模块加载失败就不展示、排行榜加载慢就不返回、积分接口调用失败就提示"稍后再试"等------这种"宁可没数据,也不能卡住主流程"的地方,非常适合加降级。
限流怎么实现?项目中啥时候才该加?
前面说了这么多,那我们项目里到底该 怎么用限流?
是不是要造个复杂的中间件、配个 Nginx 插件、接个 Redis? 其实没那么麻烦,一开始也不需要太麻烦。
举个例子------发验证码接口
这个场景我觉得我们在项目中一定不陌生:
用户点击"获取验证码",后台就调用短信服务发一条短信。
听起来很简单?但这个接口,其实是最容易被刷爆的那种哈!
那为什么这个接口要限流?
发一条短信是要钱的,哪怕我们接了服务商优惠价,一条也要几分钱。平时正常用还好,但只要被人点得快了、点多了,成本就直接上来了。
很多服务商后台本身也会做频控,但光靠人家的限制还不够,我们自己的代码里也得限一下。
如果我们不加,用户手快一点,1 秒点 5 次,短信网关那边都来不及返回。
更别说真要是碰上恶意爬虫扫手机号、批量注册、刷验证码......
一晚上过去,服务商短信额度被清空,老板早上过来一看:
短信钱扣爆了,用户还在投诉没收到验证码。
到时候你觉得------是你优化代码快,
还是老板优化你快?
那我们能怎么处理?
很简单,根据这个场景,我们可以做一个基础限流逻辑:
- 限制:一个 IP 每分钟最多请求 5 次
- 超过就直接返回错误提示:"操作太频繁,请稍后再试"
不需要用什么复杂组件,哪怕用内存存个 map,或者加个 Redis 计数器都能实现。
我们只是通过"业务场景"出发,加一个最基本的防护措施 ,
不是为了抗几万 QPS,而是为了让服务在被误用或滥用时,至少能顶得住、不崩盘。
实现一个简单的限流逻辑
下面我还是用go的Gin 框架,写一个简单的 IP 限流中间件 ,毕竟我还在学习GO语言 hhh.....
让我们刚刚说的"发验证码接口"在一分钟内最多只能请求 5 次。
先不管 Redis、不搞高可用,我们就用最简单的内存 map 来实现。
注意:这种方式适合开发/测试或单机部署,正式环境建议换成带过期的 Redis 实现哈。
我们用的是 Go 官方提供的限流库:
bash
go get golang.org/x/time/rate它实现了经典的令牌桶算法,用来控制请求速率,非常适合做限流。
创建 IP 限流中间件
我们用 Gin 框架实现一个最基础的"IP 维度限流器 ",
限制每个 IP 每秒只能访问 1 次,最多允许瞬时突发 3 次。
我们可以把它放在 middleware/limiter.go,结构如下:
go
package limiter
import (
"fmt"
"net/http"
"sync"
"time"
"github.com/gin-gonic/gin"
"golang.org/x/time/rate"
)
// 用 map 存每个 IP 的 limiter
var visitors = make(map[string]*rate.Limiter)
var mu sync.Mutex
func getLimiter(ip string) *rate.Limiter {
mu.Lock()
defer mu.Unlock()
limiter, exists := visitors[ip]
if !exists {
// 每秒 1 个请求,最大突发 3 次
limiter = rate.NewLimiter(1, 3)
visitors[ip] = limiter
// 自动清理,避免 map 越来越大(10分钟后清掉)
go func() {
time.Sleep(10 * time.Minute)
mu.Lock()
delete(visitors, ip)
mu.Unlock()
}()
}
return limiter
}
func IPBasedRateLimit() gin.HandlerFunc {
return func(c *gin.Context) {
ip := c.ClientIP()
limiter := getLimiter(ip)
if !limiter.Allow() {
// 为了方便本地调试,打印限流返回的 JSON 响应内容
fmt.Println("[限流] 返回 JSON:", gin.H{
"error": "请求太频繁,请稍后再试",
})
c.AbortWithStatusJSON(http.StatusTooManyRequests, gin.H{
"error": "请求太频繁,请稍后再试",
})
return
}
c.Next()
}
}应用限流中间件
我们在 main.go 中注册这个中间件,并加个测试接口 /send-code:
go
package main
import (
"github.com/gin-gonic/gin"
"go-rate-limit-demo/middleware/limiter"
"net/http"
)
func main() {
r := gin.Default()
// 注册限流中间件
r.Use(limiter.IPBasedRateLimit())
r.GET("/send-code", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "验证码发送成功",
})
})
r.Run(":8888")
}本地压测:用 hey 模拟高频请求
写完限流逻辑,怎么验证它真的能拦截住频繁请求?
我们可以装一个小巧好用的压测工具 ------ hey。
安装 hey
bash
# Mac 安装
brew install hey
# Linux 安装(Ubuntu/Debian)
sudo apt install hey
# 如果没源,可以自己编译:
# https://github.com/rakyll/hey示例压测
我们启动go后 接口地址为 http://localhost:8888/send-code,我们来压一波:
bash
hey -n 20 -c 5 http://localhost:8888/send-code| 参数 | 含义 |
|---|---|
-n |
总请求数 |
-c |
并发数 |
上面的命令表示:
总共发送 20 个请求,模拟 5 个并发用户同时访问。
执行完后,我们就看到 hey 返回的响应统计信息,包括成功请求数、失败请求数、耗时分布等内容。
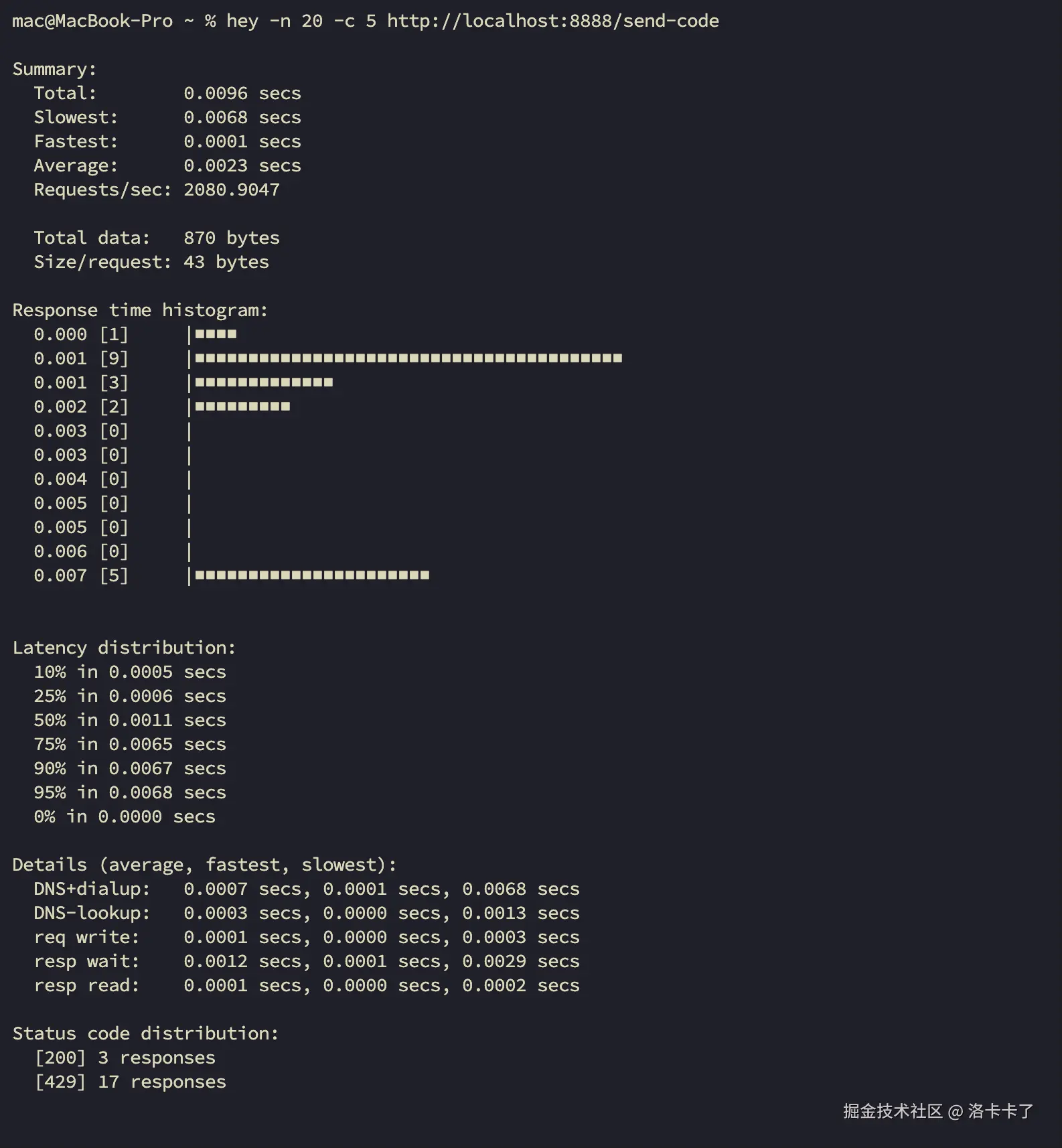
如果限流逻辑生效,我们就可以看到部分请求返回 429 ,说明已经开始拒绝超频访问啦!
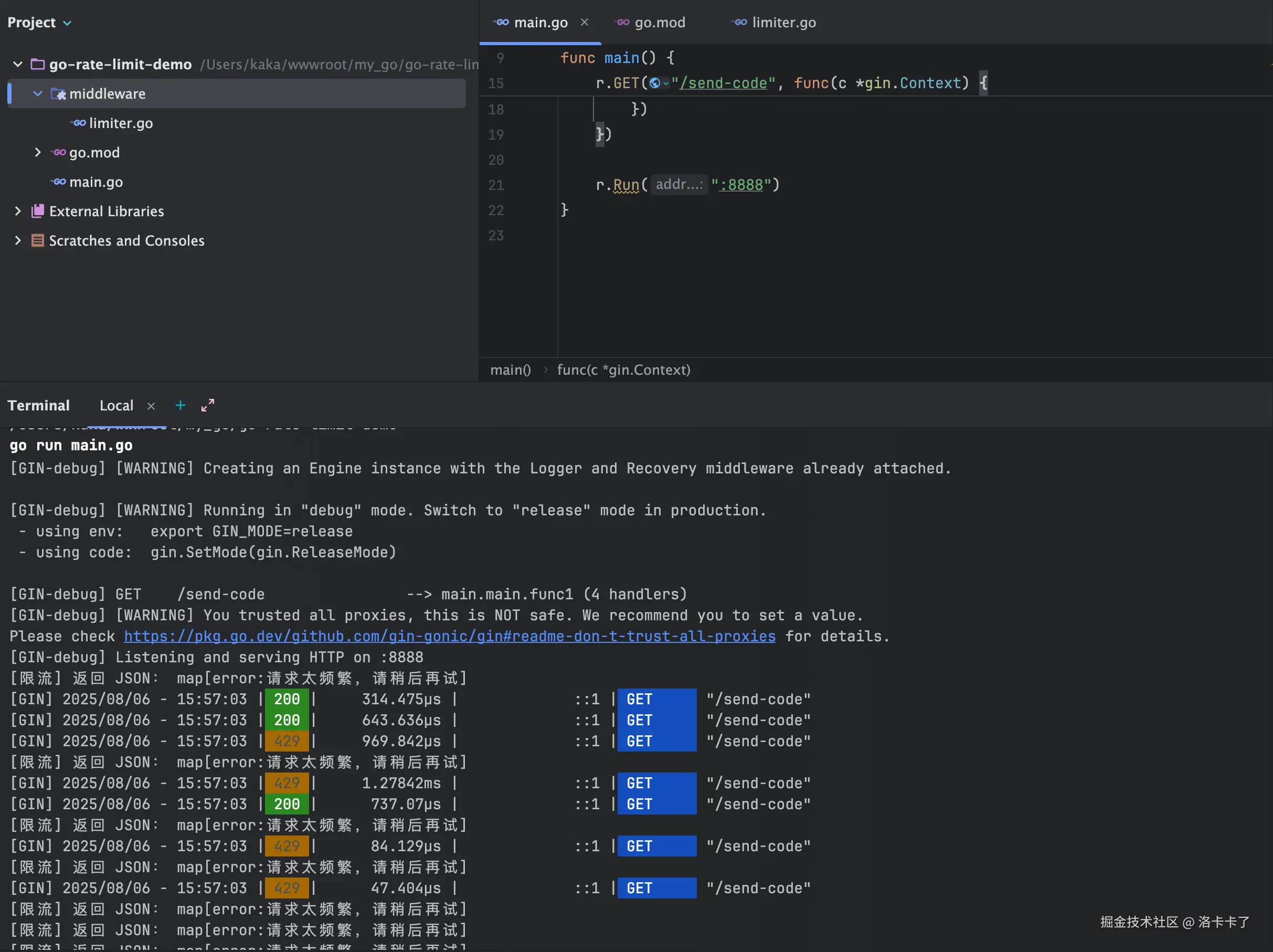
从上面的日志可以看到,有些请求拿到了 200,说明被正常放行;
而另外一些返回了 429,说明速率被控制住了,限流器成功"出手",非常好用!
限流还有哪些方式?
我们上面用 IP 做了一个最简单的限流,其实已经能解决一些基础问题了。
但在真实项目里,限流还有很多种实现方式,不同的业务和系统架构,适合的限流手段也不太一样。下面简单列几个常见的做法:
| 限流方式 | 简要说明 | 常见应用场景 |
|---|---|---|
| IP 限流 | 针对每个 IP 单独限流 | 防刷、防爆破、防止接口滥用 |
| 接口级限流 | 对特定接口设置 QPS 限制 | 高成本接口(如图片识别、AI 接口) |
| 用户级限流 | 按登录用户维度限制访问频率 | 限制恶意操作、防止单用户滥用 |
| 全局限流 | 控制整个服务的总请求量 | 系统资源紧张时的保护措施 |
| Redis 限流 | 利用 Redis 跨节点共享限流数据 | 多节点部署场景下统一限流控制 |
| 令牌桶 / 漏桶算法 | 控制处理速率或排队节奏 | 高并发系统、稳定输出的场景 |
这些限流方式,其实很多在我们常用的框架中(比如 Spring Cloud、Gin、Express 等)都有现成的中间件或组件可以直接用,这里我就不再展开讲具体代码了。想自己实现的可以去掘金社区搜搜相关的文章哈还是很多的。
那我们怎么实现一个熔断机制呢?
Go 语言里比较常见的熔断方案,一般会用第三方库,比如:
github.com/sony/gobreaker:一个经典的熔断器实现,原理清晰、使用也不复杂,非常适合我们这种项目不大的中后台服务。- 另外像
afex/hystrix-go,是 Netflix Hystrix 的 Go 版本,也可以用,只是稍微重一些,适合更复杂的微服务架构。
如果是用其他语言的,也有对应的熔断方案:
- Java:最出名的当然是 Hystrix,虽然现在已经停止维护了,但像 Resilience4j 也是很流行的现代替代方案,Spring Cloud 也集成得很好。
- PHP :可以看下 php-circuit-breaker 这类库,虽然生态不如 Java 丰富,但基本逻辑差不多。
- Node.js:推荐 opossum,轻量级、灵活,适合写 API 网关时使用。
当然我们自己项目没用那么重的微服务架构,搞个 gobreaker 实现下核心逻辑就够用了。
那什么场景适合做熔断呢?
只要我们有调用外部服务(尤其是三方接口)并且不稳定的,基本都建议做熔断。 比如:
- 调用第三方短信 / 邮件 / 支付服务
- OCR、AI 模型推理接口(有时候响应很慢)
- 自己拆分出来的服务之间调用(比如 RPC、HTTP 接口)
我就不做熔断能出现什么问题?
我们可以想象一下,如果我们调用一个接口 5 次都超时,用户那边体验已经炸了,我们这边服务资源也被拖慢。
如果再加上多个接口同时请求这个"有毒"的服务,整个系统可能就像"堵车"一样,哪里都不动了。
这时候,加一个简单的熔断器逻辑,其实就像我们知道这条路堵死了,先封起来让大家走别的路,等一会再放行。
实现一个简单的熔断机制
我们现在来用 Go 实现一个最基础的熔断机制,使用的是社区非常成熟的库:
步骤一:安装依赖
bash
go get github.com/sony/gobreaker步骤二:创建模拟的"第三方服务"
我们模拟一个接口,它可能会失败(比如随机返回 500),用来测试熔断。
go
// mock_service.go
package main
import (
"errors"
"fmt"
"math/rand"
_ "time"
)
func unstableService() (string, error) {
r := rand.Intn(10)
if r < 6 {
fmt.Println("调用服务:失败")
return "", errors.New("模拟服务失败")
}
fmt.Println("调用服务:成功")
return "第三方服务成功响应", nil
}步骤三:接入 gobreaker 熔断器
go
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"github.com/sony/gobreaker"
"net/http"
"time"
)
func main() {
r := gin.Default()
// 创建熔断器配置
cbSettings := gobreaker.Settings{
Name: "SMS Breaker",
MaxRequests: 2, // 熔断后允许的请求数量
Interval: 0, // 统计窗口时间
Timeout: 5 * time.Second, // 熔断后多长时间尝试恢复
ReadyToTrip: func(counts gobreaker.Counts) bool {
fmt.Printf("失败次数统计:%+v\n", counts)
return counts.ConsecutiveFailures >= 3
},
}
cb := gobreaker.NewCircuitBreaker(cbSettings)
r.GET("/send-code", func(c *gin.Context) {
fmt.Println("当前熔断器状态:", cb.State().String())
result, err := cb.Execute(func() (interface{}, error) {
return unstableService()
})
if err != nil {
fmt.Println("[熔断保护] 请求失败:", err)
c.JSON(http.StatusServiceUnavailable, gin.H{
"error": "服务暂时不可用,请稍后重试",
})
return
}
c.JSON(http.StatusOK, gin.H{
"message": result,
})
})
r.Run(":8888")
}然后我们本地来测试下:
我们用curl来多次访问接口地址:
bash
curl http://localhost:8888/send-code
然后我们来看下接口响应结果:
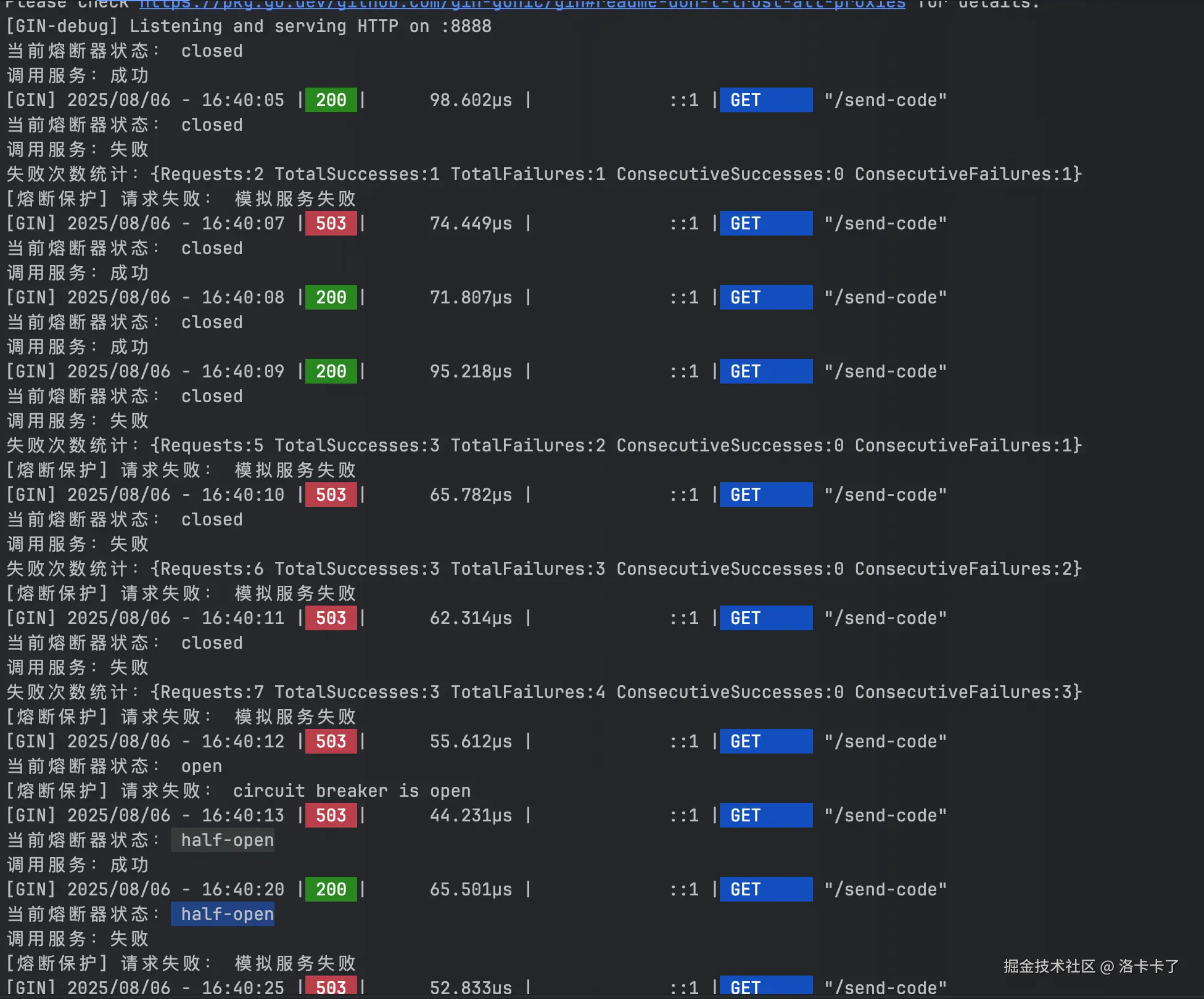
熔断机制效果实测
在上面我们实现了一个简单的熔断器,并使用随机失败模拟了第三方服务不稳定的情况。我们通过访问 /send-code 接口多次请求,来看熔断的状态变化。
请求 & 状态过程
从日志来看:
arduino
请求次数:1、2 次
结果:200(成功)
熔断状态:closed(关闭,正常状态)说明服务正常,熔断器什么都不做。
arduino
请求次数:第 3、4 次
结果:503(失败)
熔断状态:closed
统计数据:ConsecutiveFailures: 1 -> 2连续失败次数累计,虽然还没达到熔断阈值(比如设置的 3 次),但已经开始累积。
arduino
请求次数:第 5 次
结果:503(失败)
熔断状态:open
统计数据:ConsecutiveFailures: 3,熔断器被触发!连续失败达到上限,熔断器进入 open 状态:
- 后续请求不再执行实际逻辑
- 直接返回错误(如 "circuit breaker is open")
这就避免了继续压垮系统。
arduino
再等几秒(达到设置的 ResetTimeout 时间)
请求次数:第 6 次
熔断状态:half-open(半开)熔断器进入试探状态,允许少量请求尝试是否恢复。
arduino
第 6 次返回:200(成功)
状态仍为:half-open系统开始恢复信心,如果接下来连续成功次数达到设定阈值,就会切换回 closed。
arduino
第 7 次返回:503(失败)
状态仍为:half-open → open刚刚恢复就又失败,说明服务还不稳定,熔断器又重新打开(Open 状态),继续拒绝请求。
整体效果回顾
通过日志我们能清楚地看到:
- 熔断器如何统计失败并触发保护机制
- 如何进入
half-open状态做健康探测 - 一旦发现恢复,就回归正常;失败就继续熔断
这种机制就是为了避免调用方持续"无脑撞墙",能自动拉闸保护系统,让下游恢复后再重新连接。
在项目中,熔断能帮我们避免啥?
其实就一句话:别让别人的问题拖垮自己。
比如我们调用了第三方短信服务,结果它老是超时、挂掉,我们这边还傻傻等,一堆请求排队,线程卡死,接口全挂。更惨的是,用户那边点半天没反应,我们还没收到报警,等我们反应过来,已经一地鸡毛。
熔断的作用就是:发现对方不靠谱,先断掉,保住自己不出事。
那降级,我们怎么来实现呢?
说白了,降级其实就是"出问题就别死扛,先给个兜底响应" 。
实现方式很灵活,不需要多高级的框架,用最朴素的 if 判断、try-catch、状态码判断就能搞。
重点不在于"代码写得多优雅",而是我们有没有意识 :
某个地方如果挂了,我该返回什么,怎么保证主流程不断。
举个项目里的实际业务场景
还记得我们上面举的"发验证码"接口吗?
假设我们用的短信服务商突然挂了、超时、接口 500,那发验证码就失败了。
这个时候,我们可以这样处理:
go
resp, err := sendSmsToVendor(phone, code)
if err != nil {
// 降级处理:记录日志 + 返回默认提示
log.Println("[降级] 短信服务异常,启动兜底逻辑", err)
// 返回提示,不让用户一直重试
c.JSON(http.StatusOK, gin.H{
"message": "验证码发送失败,请稍后再试",
})
return
}或者更进一步,我们可以:
- 异步写入失败记录,后续人工补发
- 弹出备用通道:比如用另一个服务商发送
- 直接假装"验证码发送成功",但日志记录失败用户,后面限频处理
这就是典型的"降级"------我们知道它挂了,但我们不崩,能兜住就行。
实现一个简单的降级逻辑
我们模拟这样一个业务逻辑:
项目中
/recommend接口会调用一个"推荐服务"获取推荐列表。但推荐服务有时候可能挂掉或者超时。如果失败,我们就返回一个默认推荐列表(兜底),让用户页面也不至于空白。
示例代码:main.go
go
package main
import (
"log"
"math/rand"
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
// 推荐接口
r.GET("/recommend", func(c *gin.Context) {
data, err := callRecommendService()
if err != nil {
log.Println("[降级触发] 推荐服务异常,使用默认数据:", err)
// 兜底响应:返回默认推荐列表
c.JSON(http.StatusOK, gin.H{
"data": []string{"默认推荐 A", "默认推荐 B", "默认推荐 C"},
"msg": "推荐服务暂时不可用,已使用默认内容",
})
return
}
// 正常返回推荐内容
c.JSON(http.StatusOK, gin.H{
"data": data,
"msg": "推荐成功",
})
})
r.Run(":8888")
}
// 模拟推荐服务调用(随机失败)
func callRecommendService() ([]string, error) {
if rand.Float64() < 0.5 {
// 模拟服务失败
return nil, fmt.Errorf("推荐服务挂了")
}
// 模拟正常返回
return []string{"推荐 X", "推荐 Y", "推荐 Z"}, nil
}运行和测试
bash
go run main.go然后我们用curl访问多几次:
bash
curl http://localhost:8888/recommend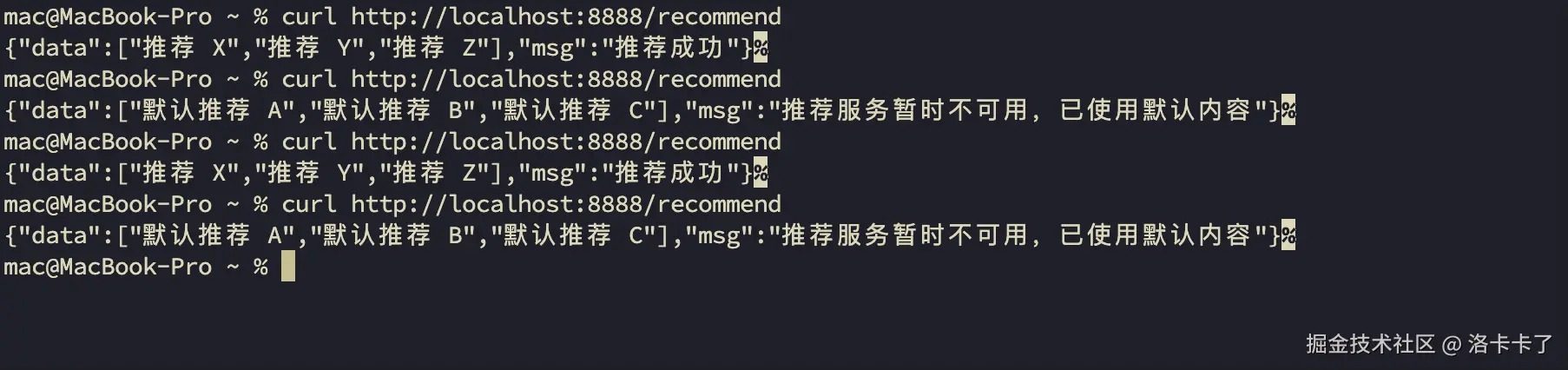
通过访问结果我们看到有时候返回正常推荐,有时候返回默认推荐(触发降级)。
补充说明一点
- 我们这里用
rand.Float64()模拟接口不稳定的情况,实际中我们可能是请求第三方接口,判断是否超时/报错。 - 降级可以用很轻量的方式实现,不需要一定上中间件或限流框架。
- 核心思想是:接口失败了,不能"什么也不做",要兜底、提示、记录,至少保证不影响主流程。
不是"高并发专属",而是"系统健康必备"
通过上面这几个例子其实我们就可以感觉出来:
限流、熔断、降级,并不是只有那种日活千万、请求量爆炸的系统才需要做的"高端配置"。
很多时候,我们做这些操作,并不是为了显得"项目高级",而是出于最基本的 稳定性考虑。
我们接手的项目不一定要"足够大",但只要存在:
- 外部接口调用(比如短信、支付、第三方 API)
- 用户可能频繁操作的接口(比如发验证码、搜索、评论)
- 有风险的依赖环节(缓存、数据库、中间件)
哪怕只是小系统,也值得提前加一些防护手段,避免关键时刻掉链子。
而且这些机制并不复杂,不一定非得用上各种框架组件------
只要从实际业务出发,想清楚"这个点出问题会不会拖垮系统",我们就能做出合理的应对。
最怕的不是"没扛住高并发",而是 出了问题连兜底都没准备,等到用户反馈、老板追问,那时候就真的晚咯。
顺便说句面试建议:
很多同学面试的时候一听"有没有做过限流熔断降级",就慌了,说"我们项目没用过"。
但如果我们真的理解了这些机制该在什么场景下做、怎么做、为了解决什么问题,
哪怕我们项目里没上过,也可以结合我们当前的业务场景说一套自己的思路,照样能讲出深度。
别怕没做过,怕的是 连在哪些地方该做都不知道。