一、基本概念
前瞻操作符(Lookahead)属于零宽断言,用于匹配后面跟随/不跟随指定模式的位置:
(?=...)肯定前瞻(匹配后面是...的位置)(?!...)否定前瞻(匹配后面不是...的位置)
核心特性:只检查不消耗字符,不影响主匹配结果
前瞻操作是正则表达式中的零宽度断言。零宽度意味着它在匹配时,不会实际消耗字符串中的字符,只是对匹配位置前后的字符进行条件判断。简单来说,前瞻就像是在匹配过程中,提前 "偷看" 一下后面的字符是否符合特定模式,但这个被 "偷看" 的部分并不会成为最终匹配结果的一部分。
前瞻操作的重点与难点
重点
-
条件判断机制 :准确理解肯定前瞻和否定前瞻的条件判断方式。肯定前瞻(
X(?=Y))要求X后面必须紧跟着Y才能匹配成功;否定前瞻(X(?!Y))则要求X后面不能紧跟着Y才匹配成功。这是前瞻操作的核心逻辑,也是在各种文本匹配场景中运用的关键。 -
非捕获特性 :要牢记前瞻操作不会捕获它所检查的内容。例如在
\d+(?=€)这个表达式中,€符号只是用于检查前面的数字是否为价格数字,但€本身不会包含在匹配结果中。这一特性在需要精确提取特定部分文本时非常有用,但也需要特别注意,以免误解匹配结果。 -
灵活组合运用 :将前瞻操作与其他正则表达式元素(如字符类、量词等)灵活组合。比如
^.*apple(?=\s+is).*$中,不仅使用了肯定前瞻来判断apple后面是否跟着空格和is,还结合了^和$表示匹配整行,以及.*表示任意字符的多次出现,从而实现复杂的文本匹配需求。
难点
-
复杂条件构建 :当面对复杂的文本匹配需求时,构建准确的前瞻条件较为困难。例如,在验证密码强度时,要求密码必须包含大写字母、小写字母、数字和特殊字符中的至少两种,且长度在 8 - 32 位之间。这就需要综合运用多个前瞻条件以及其他正则表达式元素来构建复杂的正则表达式。如:
^(?!(a - z)*$)(?!(A - Z)*$)(?!(0 - 9)*$)(?!([^a-zA - Z0 - 9])*$).{8,32}$。这里使用了四个否定前瞻,分别确保密码不全是小写字母、不全是大写字母、不全是数字、不全是特殊字符,然后通过.{8,32}确保密码长度符合要求。 -
性能优化:随着前瞻条件的增多和正则表达式的复杂度增加,匹配效率会受到影响。例如,嵌套过多的前瞻断言可能导致性能急剧下降。在处理大数据量文本时,需要谨慎设计正则表达式,尽量简化前瞻条件,避免不必要的复杂嵌套。例如,在从大量日志文本中提取特定信息时,如果正则表达式中包含过多复杂的前瞻操作,可能会导致程序运行缓慢。
常见误区
-
误认为前瞻内容会被捕获 :如在
let result = "1只火鸡价值30€".match(/\d+(?=€)/);中,有些人可能会错误地认为€也会被包含在result[0]的匹配结果中。实际上,前瞻部分(?=€)只是用于检查前面的数字是否符合后面跟着€这个条件,并不会成为匹配结果的一部分。 -
前瞻条件逻辑错误 :在构建复杂前瞻条件时,容易出现逻辑错误。比如,在判断一个字符串是否不包含某个子串时,使用
^(?!substring).*$这个表达式,本意是匹配开头位置,且开头后面不能跟着substring,然后匹配任意字符直到结尾。但如果对前瞻逻辑理解不深,可能会错误地认为这个表达式能匹配整个字符串中都不包含substring的情况。实际上,它只是确保开头位置后面不紧跟substring,对于字符串中间部分是否包含substring并没有起到全面检查的作用。 -
忽视性能问题:在编写正则表达式时,尤其是涉及多个前瞻操作时,没有充分考虑性能问题。例如,在一个循环中对大量文本进行匹配操作,且每次匹配都使用了复杂的前瞻正则表达式,可能会导致程序运行效率极低。在实际应用中,需要根据文本数据量和性能要求,合理设计正则表达式,必要时可以考虑将复杂的匹配逻辑拆分成多个简单的匹配步骤,以提高整体性能。
二、类型对比
| 类型 | 语法 | 匹配条件 | 示例 |
|---|---|---|---|
| 肯定前瞻 | (?=exp) |
后面跟随exp | a(?=b) 匹配a后面有b的a |
| 否定前瞻 | (?!exp) |
后面不跟随exp | a(?!b) 匹配a后面不是b的a |
三、应用场景
1. 表单验证(密码复杂度)
javascript
// 要求:包含数字、字母、特殊字符且长度≥8
const passwordRegex = /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[!@#$%^&*]).{8,}$/;
console.log(passwordRegex.test("Pass123!")); // true
console.log(passwordRegex.test("weakpass")); // false2. 数据清洗(价格提取)
javascript
const text = "商品价: ¥299 促销价: ¥199 参考价: ¥259";
// 提取¥符号开头的价格(忽略¥)
const prices = text.match(/¥(\d+)(?!\s*折)/g);
// 提取匹配中的捕获组
const priceNumbers = prices ? prices.map(match => match.match(/¥(\d+)/)[1]) : [];
console.log(priceNumbers); // 输出: ['299', '199']3. 日志分析(错误追踪)
javascript
const logs = [
"ERROR: 2023-08-01 14:30 - SocketTimeout",
"WARN: 2023-08-01 14:32 - ConnectionReset",
"ERROR: 2023-08-01 14:35 - NullPointer"
];
// 提取ERROR级别日志(排除WARN)
const errorRegex = /^ERROR:.*?(?!WARN)/;
logs.filter(log => errorRegex.test(log));四、SVG匹配原理图

五、肯定前瞻(Positive Lookahead)
肯定前瞻的语法是X(?=Y),表示匹配X,但前提是X后面紧跟着Y。这里的X和Y都可以是任意的正则表达式模式。
示例 1:提取价格数字
假设我们有一个字符串,其中包含商品价格,价格后面跟着货币符号€,我们要提取价格数字。
javascript
let str = "1只火鸡价值30€";
let result = str.match(/\d+(?=€)/);
console.log(result[0]); // 输出: 30在这个例子中,\d+匹配一个或多个数字,(?=€)表示这个数字后面必须紧跟着€符号。注意,€符号本身不会包含在匹配结果中。
示例 2:匹配包含特定单词的行
假设我们有一个文本,要找出其中包含单词apple且后面跟着is的行。
javascript
let text = "I like apples.\nApples are red.\nAn apple is a fruit.";
let lines = text.split('\n');
lines.forEach(line => {
let match = line.match(/^.\*apple(?= is).\*\$/);
if (match) {
console.log(match[0]);
}
});
// 输出: An apple is a fruit.这里^.*apple(?= is).*$匹配整行,其中apple后面必须紧跟着 is。^和$分别表示行的开始和结束。
肯定前瞻的 SVG 示意图
下面用一个简单的 SVG 示意图来表示肯定前瞻的匹配过程(假设匹配abc(?=def)):
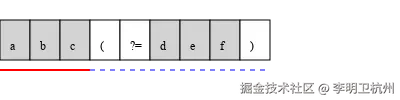
在这个示意图中,红色线条表示实际匹配的部分(abc),蓝色虚线表示前瞻检查的部分(def),蓝色部分不会成为最终匹配结果的一部分。
六、否定前瞻(Negative Lookahead)
否定前瞻的语法是X(?!Y),表示匹配X,但前提是X后面不紧跟着Y。
示例 1:提取非价格数字
还是之前的价格字符串例子,现在我们要提取数量数字,也就是后面不跟着€符号的数字。
javascript
let str = "2只火鸡价值60€";
let result = str.match(/\d+(?!€)/);
console.log(result[0]); // 输出: 2这里\d+(?!€)匹配一个或多个数字,且这些数字后面不能跟着€符号。
示例 2:匹配不包含特定单词的行
假设我们要找出文本中不包含单词banana的行。
javascript
let text = "I like apples.\nApples are red.\nI don't like bananas.";
let lines = text.split('\n');
lines.forEach(line => {
let match = line.match(/^(?!.\*banana).\*\$/);
if (match) {
console.log(match[0]);
}
});
// 输出: I like apples.
// Apples are red.这里^(?!.*banana).*$匹配整行,其中行中不能包含banana这个单词。^和$分别表示行的开始和结束,?!.*banana表示从行开始处往后看,不能出现banana。
否定前瞻的 SVG 示意图
用 SVG 示意图表示否定前瞻的匹配过程(假设匹配abc(?!def)):
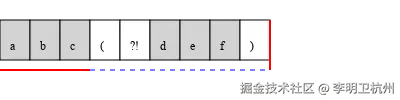
在这个示意图中,红色线条表示实际匹配的部分(abc),蓝色虚线表示前瞻检查的部分(def),当蓝色部分不匹配时,红色部分才会被作为匹配结果。如果蓝色部分匹配,红色部分就不会被匹配。
通过以上肯定前瞻和否定前瞻的介绍及示例,你应该对正则表达式中的前瞻操作有了更深入的理解。在实际应用中,前瞻操作可以帮助你更精确地进行文本匹配和处理。