Anthropic最新发布的Claude Opus 4.1在AI编程领域树立了新的标杆,在SWE-bench基准测试中达到74.5%的优异成绩,超越众多竞争对手。本文深入解析了该模型在编程能力、智能体任务和推理能力方面的核心升级,并为国内用户提供了详细的使用指南,包括直接访问方式、API接入方案和成本优化策略。

Claude Opus 4.1的核心升级
1. 编程能力再创新高
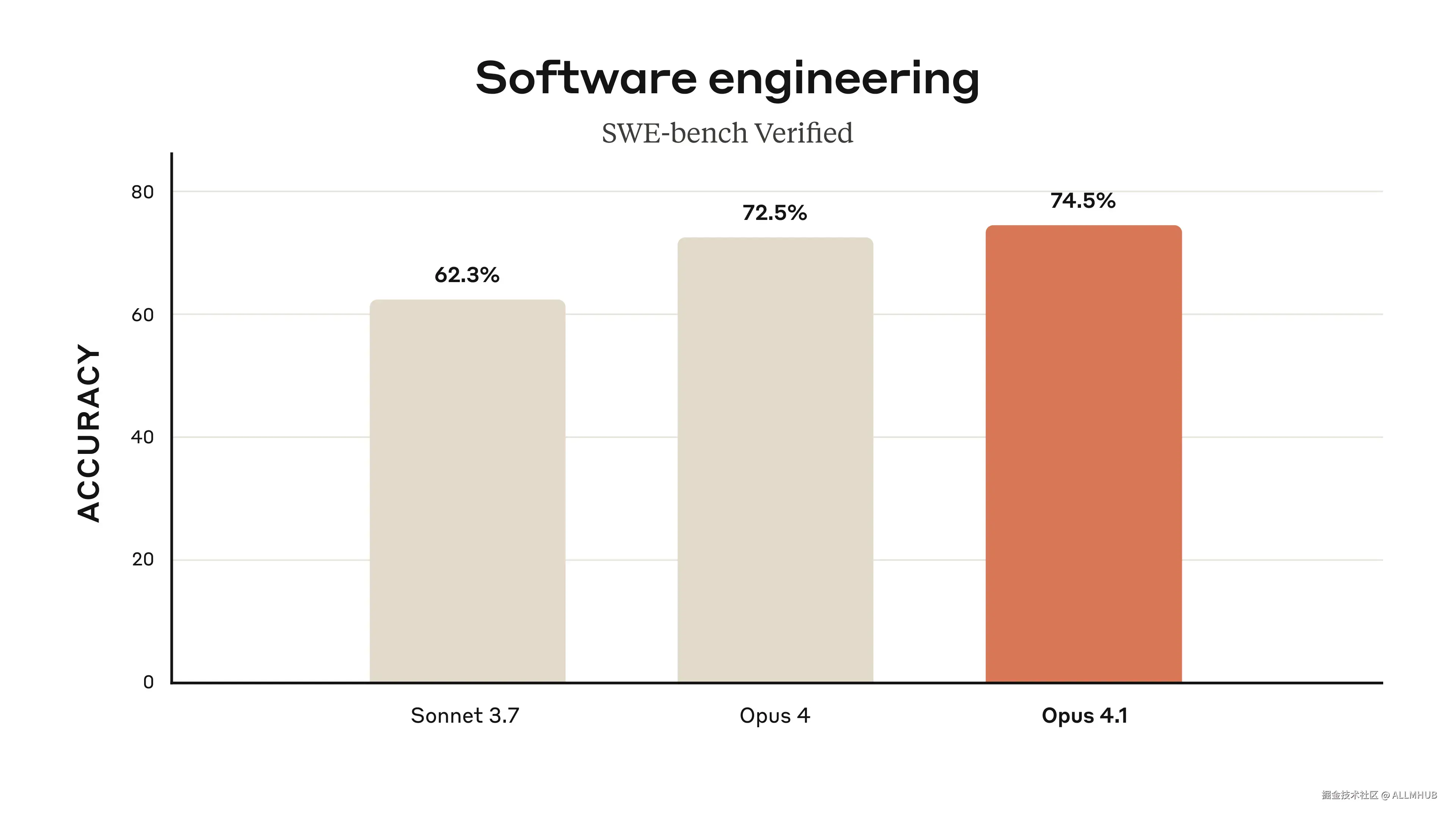
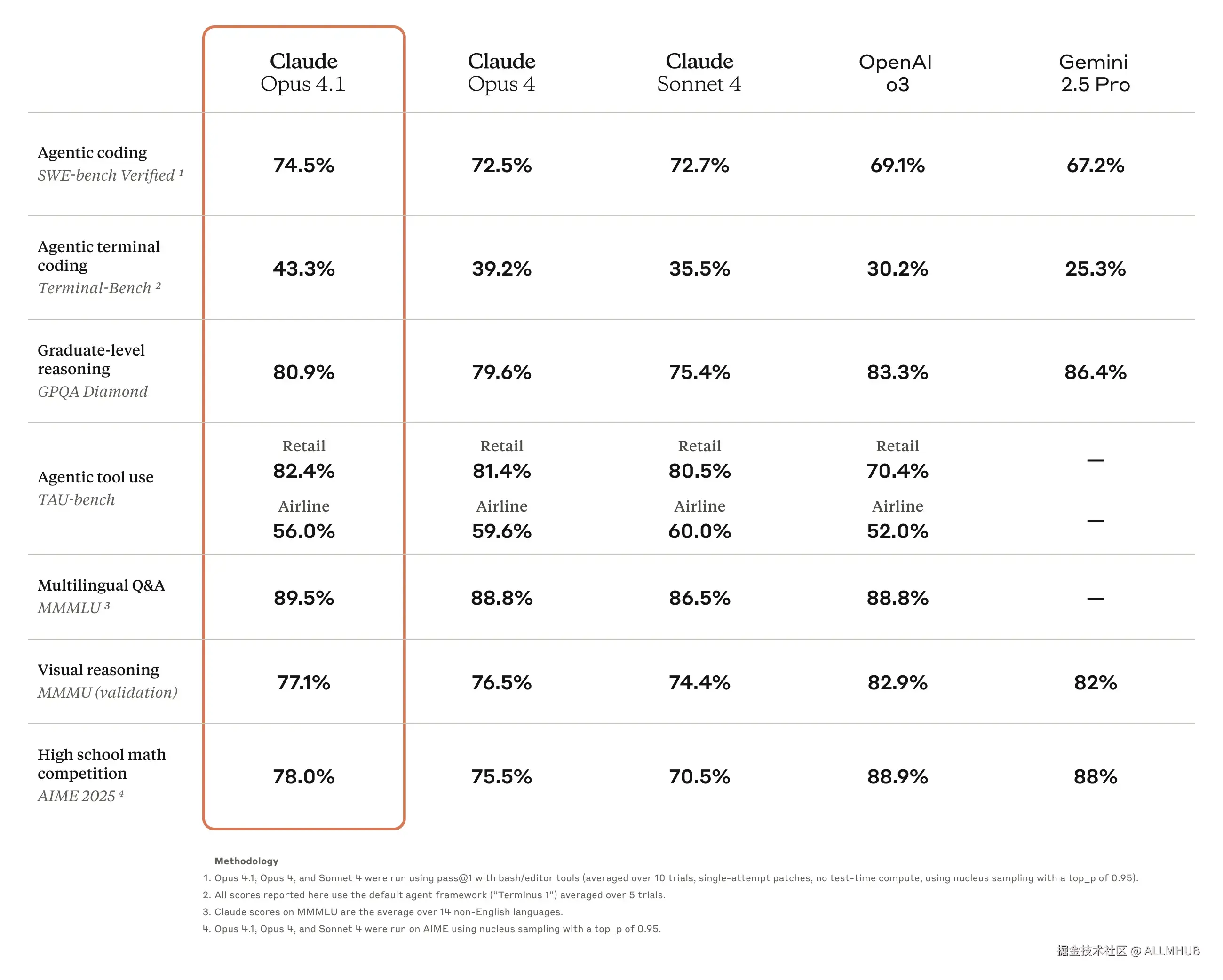
Claude Opus 4.1在编程领域的表现可谓是突破性的。在业界权威的SWE-bench Verified基准测试中,新模型取得了74.5%的优异成绩,相比前代Opus 4的72.5%有了明显提升,成功超越了Gemini 2.5 Pro等竞争对手,稳居行业领先地位。
这一成绩的背后,体现的是模型在实际编程场景中的卓越表现。无论是处理复杂的算法实现、大型项目的代码重构,还是准确的错误定位和修复,Claude Opus 4.1都展现出了专业级的能力水准。
2. Agent搜索与研究能力增强
新版本在Agent任务处理方面也有了质的飞跃。模型能够更快速地检索和整合多源信息,无论是内部文档还是外部数据库,都能快速定位关键信息并生成完整的分析报告。这对于需要进行深度研究和数据分析的用户来说,无疑是一个巨大的便利。
3. 推理能力的提升
Claude Opus 4.1在逻辑推理和问题处理方面表现出了更强的能力。模型能够处理更加复杂的多步骤推理任务,在面对需要综合多个知识领域的问题时,也能给出更加准确和完整的答案。
国内用户使用的三种方法详解
1. Claude官网及Anthropic官网API 开发者可以直接使用模型标识符"claude-opus-4-1-20250805"来调用。API定价为每百万输入token 15美元,每百万输出token 75美元。
2. 海外云平台集成 新模型已经集成到Amazon Bedrock和Google Cloud的Vertex AI平台,为企业用户提供了更多的部署选择。
3. 中转API服务 挑选优质的中转API服务,通过无限制的网络环境,让API的使用更加顺畅,国内中转平台ALLMHUB API已完成接入。

实际应用场景展示
编程开发场景
在实际的编程测试中,Claude Opus 4.1展现出了令人印象深刻的能力。以创建俄罗斯方块游戏为例,仅需要简单的提示"build the tetris game",模型就能生成完整可运行的游戏代码。
更重要的是,模型在处理大型代码库时表现出了极高的准确度。正如日本乐天集团的反馈,Claude Opus 4.1能够准确定位需要修改的代码部分,既不会进行不必要的更改,也不会引入新的错误。
多文件代码重构
GitHub的评估结果显示,Claude Opus 4.1在多文件代码重构方面有着显著的性能提升。这对于维护大型项目的开发团队来说是一个重大利好,能够大幅提升代码维护的效率和质量。
创意项目开发
除了传统的编程任务,Claude Opus 4.1还能胜任各种创意项目的开发。比如使用p5.js创建复杂的动画效果,生成符合物理规律的交互式视觉作品等。
性能对比分析
根据测试结果,在代码生成和调试能力方面,Claude Opus 4.1的表现可以用"稳定"二字来概括。与其他主流AI模型相比,Claude Opus 4.1在空间理解和逻辑推理方面展现出了明显的优势。
特别值得注意的是,模型在处理复杂任务时的一致性表现非常出色。即使是需要多次尝试的复杂编程任务,Claude Opus 4.1也能保持稳定的输出质量,这对于实际的生产环境使用来说是非常重要的特性。
使用建议与注意事项
合理使用策略
虽然Claude Opus 4.1功能强大,但考虑到使用价格,建议用户:
- 优先用于复杂的编程任务和重要项目
- 充分利用提示缓存等优化功能
- 对于简单任务可以考虑使用其他版本的Claude模型
使用建议
-
明确需求描述:在使用时尽量提供清晰、具体的需求描述,这样能获得更准确的结果。
-
分步骤处理:对于复杂项目,建议分解为多个小任务,逐步完成。
-
代码审查:虽然模型生成的代码质量很高,但仍建议进行必要的代码审查和测试。
未来发展展望
Anthropic公司表示,计划在未来几周内对模型进行更大规模的升级与改进。这表明Claude Opus 4.1只是一个阶段性的更新,更强大的版本还在路上。
对于国内的AI应用市场来说,Claude Opus 4.1的发布无疑提供了一个高质量的AI助手选择。随着模型能力的不断提升和使用费用的逐步优化,相信会有越来越多的开发者和企业选择使用这一强大的工具。