背景
在 Uber Eats 优食的规模上,图像处理是运营的必要条件。该平台管理着数亿张产品图片,每小时有数百万次更新流经系统。每张图像都有成本:网络带宽、处理时间、存储空间和 CDN 占用空间。随着 Uber Eats 优食从餐厅扩展到杂货、酒类和家居用品,形象渠道开始紧张。例如,单一产品(例如一罐可口可乐)可能会出现在数千个店面中。但是,后端将每次外观都视为新上传。没有跨商家共享资产的概念。每次上传都会触发新的下载、新的转换和新的存储作,即使图像与系统中已有的图像相同。旧方法还假设 URL 更改将伴随任何图像更改。如果 URL 保持不变,它不会跟踪内容更新。此被阻止的图像会刷新,从而导致尴尬的解决方法。工程目标很明确:减少不必要的处理,降低存储和 CDN 成本,并尽可能重用现有工作。在本文中,我们将了解优步如何实现数亿张图像重复数据删除的目标。
旧系统的局限性
原始图像管道基于一个简单的假设运行:如果 URL 是新的,则图像必须是新的。如果 URL 相同,请跳过所有内容。但是,没有机制来检测两个不同的 URL 是否指向同一图像。系统将每个传入 URL 视为唯一,即使底层图像字节相同。因此,由不同商家上传或在不同上下文中列出的同一图像将被多次下载、处理和存储。
请参见下图:

更糟糕的是,当 URL 保持不变时,系统无法检测到内容更改。如果商家在未修改 URL 的情况下更新了图像,系统会完全忽略它。没有验证,没有重新处理,没有缓存失效。
这有几个主要缺点:
- 冗余映像下载导致网络使用量膨胀。
- 不必要的处理周期推高了计算成本。
- 重复的 CDN 条目推高了存储和交付成本。
新图像处理管道
重新设计的图像管道将焦点从 URL 转移到实际图像内容。系统现在不再依赖 URL 更改等外部信号,而是使用内容可寻址缓存。每个图像都由其字节的加密哈希来标识。如果两个图像相同,则它们的哈希值将匹配,无论它们来自哪里或使用什么 URL。此更改使系统能够跨上传、商家和目录更新重复使用工作,而无需依赖脆弱的假设。
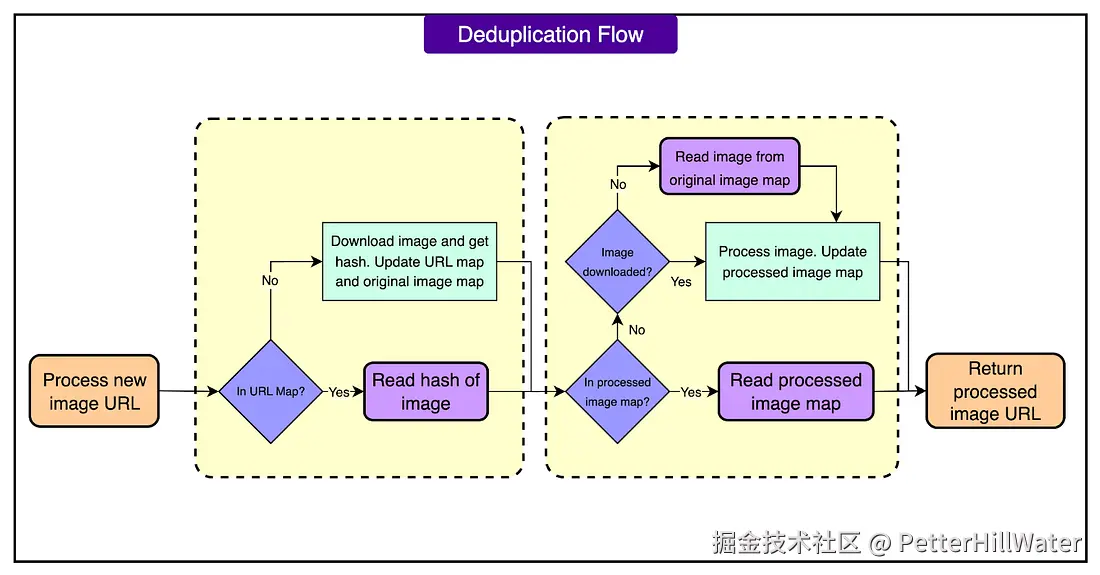
新的映像服务遵循三个主要路径,具体取决于它对映像的了解:
- 已知且已处理: 查找图像哈希和处理规范。如果两者都缓存了,请立即返回处理后的图像。
- 新的和未处理的: 下载图像,计算哈希值,应用转换,存储结果,然后返回它。
- 已知但尚未使用当前规范进行处理: 使用其哈希值检索原始图像,应用请求的处理,并存储输出。
请参阅下图,其中显示了三个流:
为了支持这些流,系统维护三个逻辑映射,如下图所示:
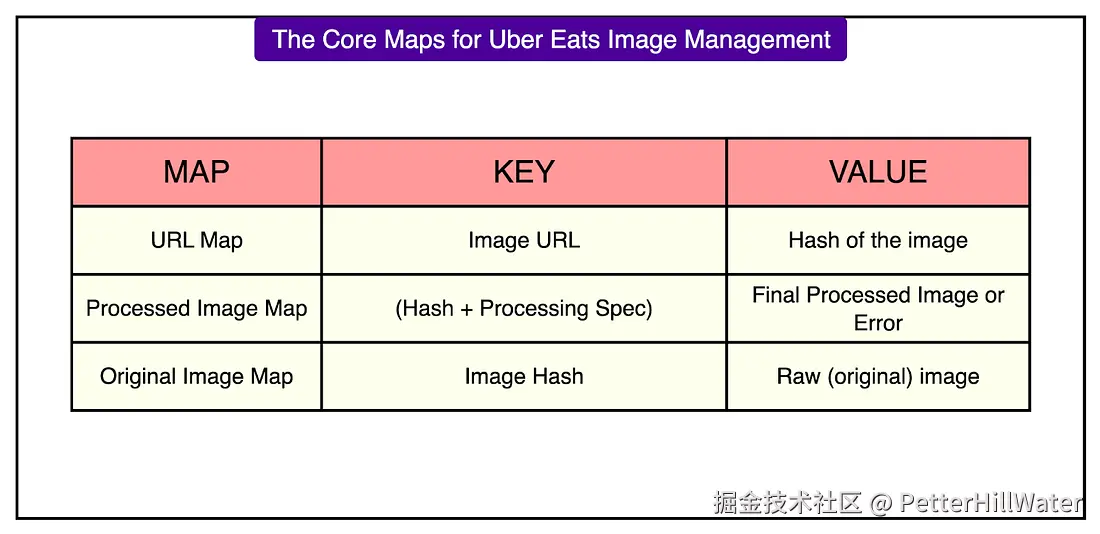
每个地图都处理一个不同的问题:识别内容、链接处理后的输出以及跟踪原始资产。
存储详情如下:
- 图像,包括原始图像和经过处理的变体,都存储在 Terrablob 中,这是 Uber 以 Amazon S3 为蓝本的 blob 存储系统。
- 元数据(例如映射和处理规范)存储在 Docstore 中,Docstore 是一个基于文档的键值存储,针对快速查找进行了优化。
加工处理规范
每个图像转换请求都包含一个处理规范,该规范定义了应如何处理图像。这包括:
- 输入约束,例如最小分辨率或可接受的文件类型。
- 输出格式,如 JPEG 或 PNG。
- 调整大小指令,包括目标尺寸或纵横比。
图像哈希和处理规范共同形成一个唯一键。如果之前处理过该组合,系统可以立即返回结果,而无需执行任何工作。此缓存机制同样适用于成功的转换和已知故障。
错误被视为一等结果。例如,如果上传的图像太小而无法满足请求的分辨率,系统会使用相同的 hash-plus-spec 键在"已处理的图像映射"中记录失败。下次该映像具有相同的规格时,系统会跳过下载和转换并返回缓存错误。
这可以避免在同一错误输入上重复失败,并防止在保证失败的请求上浪费计算周期。它还使跨客户端的错误报告更快、更一致。
处理稳定 URL 背后的图像更新
并非每个图像更新都带有新的 URL。商家通常会替换 URL 后面的内容,而不更改 URL 本身。在旧系统中,这意味着更新被静默忽略。系统假设已知 URL 始终指向同一图像,这导致提供过时或不正确的数据。
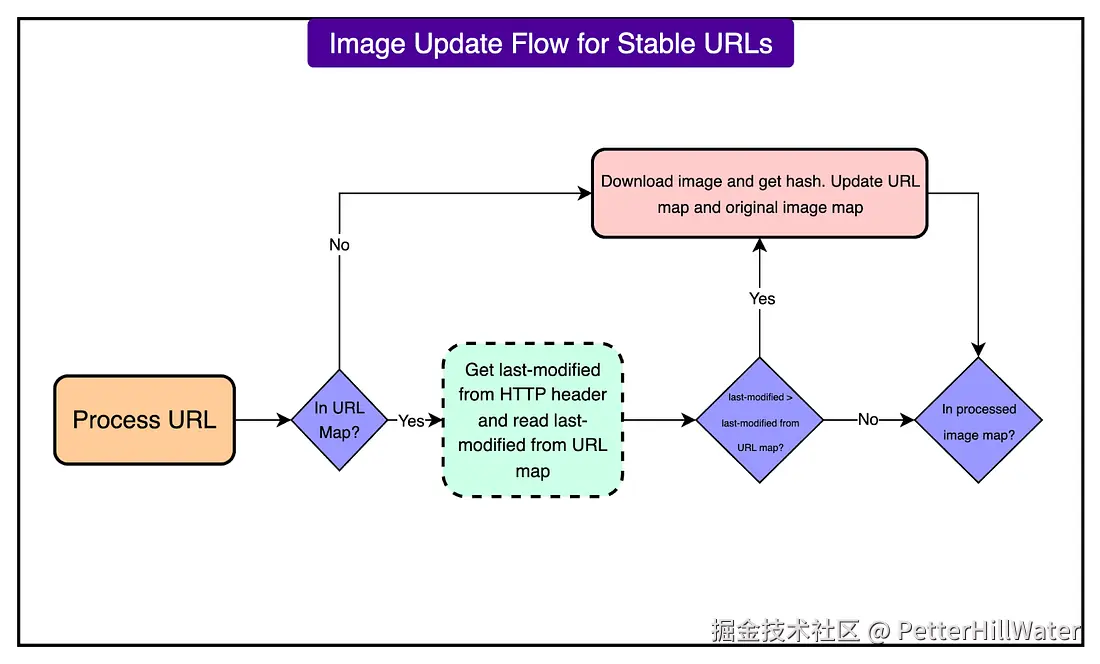
为了解决这个问题,新管道使用 HTTP Last-Modified 标头来检测同一 URL 后面的图像是否发生了变化。在图像处理过程中:
- 系统会检查 URL 映射中存储的上次修改值****。
- 它将此值与图像服务器返回的当前 Last-Modified 值进行比较。
- 如果时间戳已更改,则会重新下载并重新散列映像。
- 如果时间戳相同,则系统使用缓存的哈希值并跳过下载。
请参见下图:
这种方法允许商家保持稳定的 URL,同时仍提供更新的内容。映像管道会尊重这些更新,而不会盲目地重新处理每个请求。它还避免了在没有任何变化的情况下进行不必要的工作。
原则匹配
结合 Scalability Rules: Principles for Scaling Web Sites 中的原则,对以上方案进行深度、逐条的解读。
I. Reduce the equation(简化方程)
原则 1:不要过度设计。
- 解读: Uber 之前的图片系统就是典型的过度设计:它基于"URL 不同则图像不同"的假设,导致系统被设计得过于复杂(每个 URL 都触发一次完整流程),而实际上这个假设是错误的。
- 改进: 新系统不再依赖 URL,而是直接基于图像内容的哈希值进行去重。这种简化(从"URL 唯一"到"哈希唯一")大幅降低了系统复杂度。
原则 3:简化解决方案 3 倍(帕累托法则)。
- 解读: 之前系统对每一张图片都要进行下载、转换、存储、CDN 缓存等多个步骤,导致 80% 的工作是重复的。
- 改进: 新系统通过哈希去重,使得 99% 的请求无需重新处理,直接命中缓存,极大简化了 80% 的无效工作。
II. Distribute the work(分布式工作)
原则 7:设计可克隆的服务(X 轴扩展)。
- 解读: 新系统的图片处理服务是无状态的(基于哈希值),可以轻松横向扩展(克隆多个实例)来处理高并发。
- 实践: 每个图片处理请求都是独立的,不依赖上下文,因此可以通过负载均衡器轻松分发到多个服务实例。
III. Design to scale out horizontally(水平扩展)
原则 10:设计为水平扩展,而非垂直扩展。
- 解读: 旧系统可能依赖单点的高性能存储或 CDN 节点(垂直扩展),而新系统通过哈希去重,使得存储和处理可以分散到多个节点(水平扩展)。
- 实践: 所有图片(原始和处理后的)存储在 Uber 自研的分布式对象存储 Terrablob 中,天然支持水平扩展。
原则 12:扩展数据中心。
- 解读: 新系统通过分布式存储(Terrablob)和分布式缓存(Docstore),天然支持多数据中心部署,避免单点故障。
原则 13:利用云。
- 实践: 虽然 Uber 自研了 Terrablob,但其设计思想与 AWS S3 类似(对象存储),本质上是云原生的设计。
IV. Use the right tools(使用合适的工具)
原则 14:合理使用数据库。
- 解读: 元数据(哈希映射、处理规范)存储在 Docstore(文档型键值存储)中,而非传统 RDBMS,因为这类数据不需要复杂关系查询,但需要高速读写。
- 实践: Docstore 的键值模型非常适合"哈希 → 处理结果"的快速查找。
原则 16:日志要足够。
- 解读: 新系统可能会记录每次哈希计算、缓存命中、缓存未命中、错误类型等,以便后续优化和故障排查。
V. Don't duplicate your work(避免重复工作)
原则 17:不要检查你的工作。
- 解读: 旧系统每次都对同一图片重复处理,相当于"重复检查"。
- 改进: 新系统通过哈希缓存,避免重复处理,直接复用已有结果。
原则 18:减少重定向。
- 实践: 新系统通过直接返回缓存结果,避免了不必要的 CDN 重定向或回源。
VI. Use caching aggressively(积极使用缓存)
原则 20:使用 CDN。
- 实践: 所有处理后的图片结果都会缓存到 CDN,避免重复计算和传输。
原则 21:使用 Expires 头。
- 实践: 图片处理结果通过 HTTP 缓存头(如
Cache-Control和Expires)控制缓存时间,减少重复请求。
原则 24:利用应用缓存。
- 实践: 哈希值与处理结果的映射存储在 Docstore 中,相当于应用层的缓存。
原则 25:使用对象缓存(内存缓存)。
- 实践: 可能使用 Redis/Memcached 缓存热点哈希值,避免频繁查询 Docstore。
原则 26:缓存层独立部署。
- 实践: 缓存(Docstore)与图片处理服务解耦,避免缓存故障影响主流程。
VII. Learn from mistakes(从错误中学习)
原则 1:不要依赖 QA。
- 解读: 旧系统的"URL 不变则图片不变"的假设,本质上是设计缺陷,而非 QA 能发现的问题。
- 改进: 新系统通过哈希和
Last-Modified头,自动检测图片更新,无需人工干预。
原则 2:设计可回滚。
- 实践: 新系统可能支持灰度发布或回滚机制,避免新系统上线后出现问题。
VIII. Database rules(数据库规则)
原则 1:避免昂贵的跨表查询。
- 解读: 新系统的元数据存储在键值数据库(Docstore)中,避免了传统 RDBMS 的跨表 JOIN 开销。
原则 4:避免 SELECT FOR UPDATE。
- 实践: 哈希值是只读的,不需要行锁或事务,避免了锁竞争。
**原则 5:不要 SELECT **
- 实践: 每次查询只返回必要的字段(如哈希值、处理结果),避免冗余数据传输。
IX. Design for fault tolerance(容错设计)
原则 36:使用故障隔离的泳道(Swimlanes)。
- 解读: 图片处理服务、存储(Terrablob)、元数据(Docstore)可能分布在不同的故障域(泳道)中,避免单点故障。
- 实践: 例如,Docstore 的故障不会影响图片的 CDN 缓存服务。
原则 37:避免单点故障。
- 实践: 所有组件(Terrablob、Docstore、CDN)都是分布式部署的。
X. Avoid or distribute state(避免状态)
原则 40:追求无状态。
- 解读: 图片处理服务本身是无状态的(输入是哈希值和规格,输出是处理结果),可以轻松横向扩展。
原则 42:使用分布式缓存存储状态。
- 实践: 会话状态(如图片哈希值)存储在 Docstore 中,而非服务实例内存中。
XI. Asynchronous communication(异步通信)
原则 43:尽可能异步通信。
- 解读: 图片处理可能是异步的:用户上传图片后,先返回"处理中"状态,后台异步计算哈希并缓存结果。
XII. Miscellaneous rules(其他)
原则 46:谨慎使用第三方扩展。
- 解读: Uber 自研 Terrablob 而非直接使用 AWS S3,可能是为了避免第三方依赖带来的不可控因素。
原则 50:保持竞争力。
- 解读: 通过减少 99% 的重复处理,Uber 在成本和性能上获得了巨大优势,保持了行业竞争力。
总结
Uber Eats 的图片去重案例,几乎完美诠释了 Scalability Rules 的核心思想:
- 简化设计(哈希去重替代 URL 假设)。
- 水平扩展(分布式存储 + 无状态服务)。
- 缓存为王(CDN + 应用缓存 + 内存缓存)。
- 避免重复工作(99% 请求直接命中缓存)。
- 容错设计(分布式架构 + 泳道隔离)。
这是一次教科书级的规模化实践。
结论
新的内容可寻址图像管道将嘈杂的冗余工作流程转变为精益、高吞吐量的系统。
- 中位延迟为 100 毫秒,P90 不到 500 毫秒,即使在重负载下也能快速提供图像。
- 现在,超过 99% 的请求无需重新处理图像即可完成。这是性能和效率的明显胜利。
通过在内容级别进行重复数据删除,系统避免了重复下载、转换和存储。它会优雅地处理图像更新,即使商家重复使用 URL。这些变化显着降低了基础设施需求,同时提高了可靠性。也许最令人印象深刻的是交付速度。新架构在不到两个月的时间内推出,但支持 Uber Eats 优食容量最大的数据路径之一。这是一个强有力的例子,说明核心系统的有针对性的改进如何释放更广泛的产品速度,尤其是当解决方案快速、可扩展且易于推理时。