文章目录
-
- 一、项目背景与技术挑战
-
- [1.1 面临的核心挑战](#1.1 面临的核心挑战)
- [1.2 技术选型:为什么选择CANN](#1.2 技术选型:为什么选择CANN)
- 二、系统架构设计
-
- [2.1 整体架构](#2.1 整体架构)
- [2.2 技术栈选型](#2.2 技术栈选型)
- 三、CANN核心功能深度应用
-
- [3.1 DVPP视频处理加速实践](#3.1 DVPP视频处理加速实践)
-
- [3.1.1 硬件视频解码(VDEC)](#3.1.1 硬件视频解码(VDEC))
- [3.1.2 图像预处理优化(VPC + AIPP)](#3.1.2 图像预处理优化(VPC + AIPP))
- [3.2 ATC模型转换与深度优化](#3.2 ATC模型转换与深度优化)
-
- [3.2.1 模型转换流程](#3.2.1 模型转换流程)
- [3.2.2 ATC优化效果数据分析](#3.2.2 ATC优化效果数据分析)
- [3.3 AscendCL推理编程实战](#3.3 AscendCL推理编程实战)
-
- [3.3.1 推理引擎初始化](#3.3.1 推理引擎初始化)
- [3.3.2 多线程并发推理架构](#3.3.2 多线程并发推理架构)
- 四、性能测试与效果验证
-
- [4.1 测试环境](#4.1 测试环境)
- [4.2 端到端性能数据分析](#4.2 端到端性能数据分析)
- [4.3 资源利用率分析](#4.3 资源利用率分析)
- 五、项目总结
一、项目背景与技术挑战
随着智能安防、智慧园区等场景的深入应用,实时视频分析能力已成为重要需求。本项目是对园区内 16 路 1080P 实时视频流 同时进行目标检测与行为识别,包括人员检测、车辆识别及异常行为告警,并保证 端到端延迟不超过 100ms。系统不仅接入 RTSP 流,还需在 Web 端实时展示推理结果。
1.1 面临的核心挑战
1.实时性要求严格
16 路 1080P@25fps 意味着系统每秒需处理 400 帧图像,单帧处理时间必须稳定在 25ms 以内。解码、预处理、推理、后处理任一环节出现瓶颈,都可能导致整体时延超标。
2.多模块协同复杂
视频分析链路长,从解码到推理再到结果渲染,各模块需高效协同工作。如何在多线程环境下打造顺畅的流水线,是系统设计的重点。
3.资源利用率优化
在多路并发场景中,解码、预处理、推理三类算力需合理分配。若资源调度不当,容易出现某些模块过载、某些模块闲置的情况。
1.2 技术选型:为什么选择CANN
华为昇腾CANN(Compute Architecture for Neural Networks)是面向AI场景的异构计算架构,提供了端到端的优化方案。经过技术评估,CANN在视频分析场景具有三大核心优势:
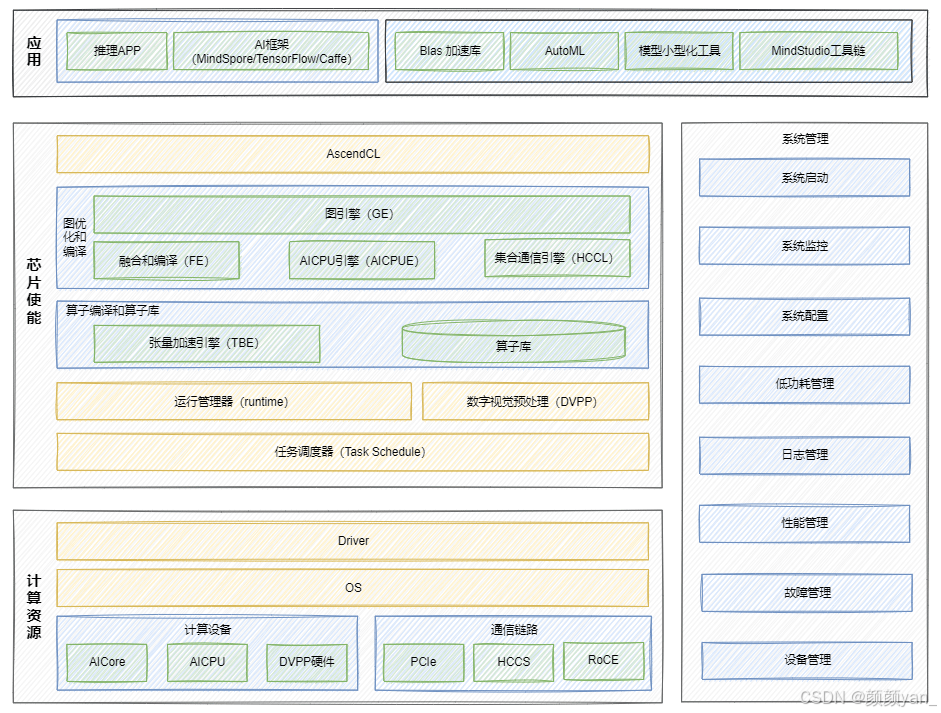
- 专用硬件加速能力强
DVPP 模块可提供硬件级 H.264/H.265 解码能力,单卡可并发处理 32 路 1080P 视频,解码延迟仅 2--3ms。 - 预处理与推理图融合
通过 AIPP 技术,可将图像预处理固化进模型,预处理时间在推理过程中被"隐藏",实现真正意义上的 零拷贝、零额外开销。 - 完备的开发链路
从模型转换到部署的各环节提供完善的工具和 API 支撑,算子融合、混合精度等优化手段成熟稳定,便于工程团队快速落地。
二、系统架构设计
基于CANN构建的视频分析系统采用多线程流水线架构,充分发挥硬件并行能力。
2.1 整体架构
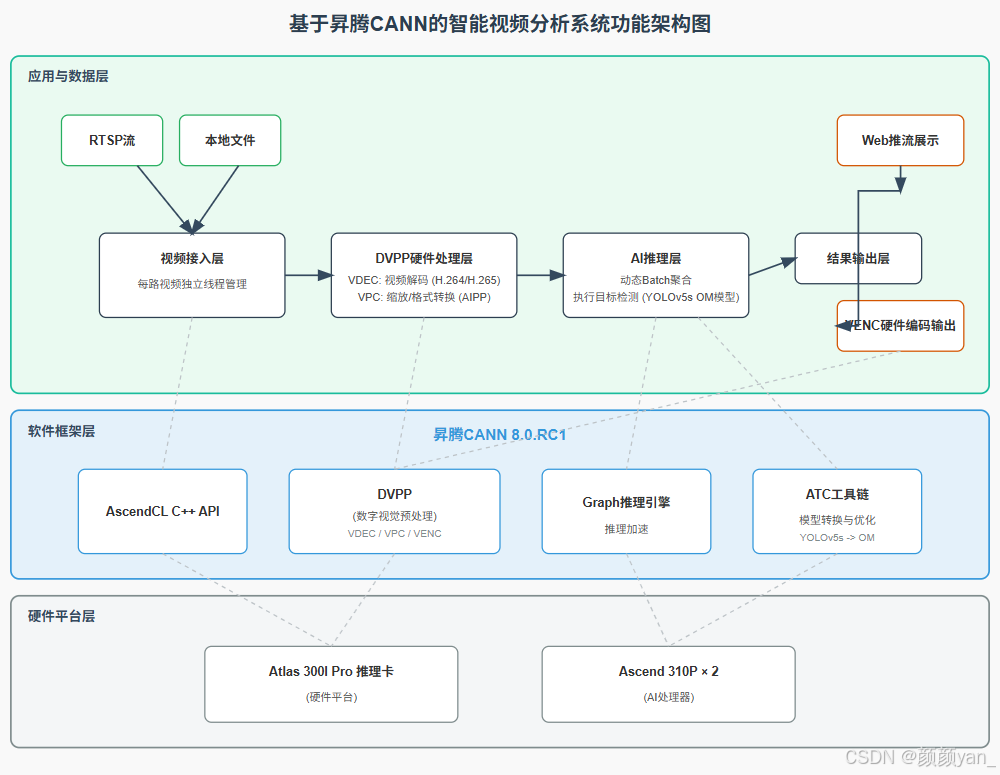
系统分为四个核心模块:
- 视频接入层:支持RTSP流和本地文件输入,每路视频独立线程管理
- DVPP硬件处理层:使用VDEC进行视频解码,VPC完成图像缩放与格式转换
- AI推理层:加载优化后的OM模型,执行目标检测推理
- 结果输出层:绘制检测框并通过VENC硬件编码输出或Web推流展示
2.2 技术栈选型
| 组件 | 技术选型 | CANN功能支持 |
|---|---|---|
| 硬件平台 | Atlas 300I Pro 推理卡 | Ascend 310P × 2 |
| 软件框架 | CANN 8.0.RC1 | AscendCL C++ API |
| 检测模型 | YOLOv5s | ATC工具链转换优化 |
| 视频解码 | H.264/H.265 | DVPP VDEC硬件解码 |
| 图像预处理 | Resize/Normalize | DVPP VPC + AIPP固化 |
| 推理加速 | 动态Batch聚合 | Graph推理引擎 |
三、CANN核心功能深度应用
3.1 DVPP视频处理加速实践
DVPP作为昇腾处理器的专用视频处理单元,独立于AI Core运行,可与推理计算并行执行。
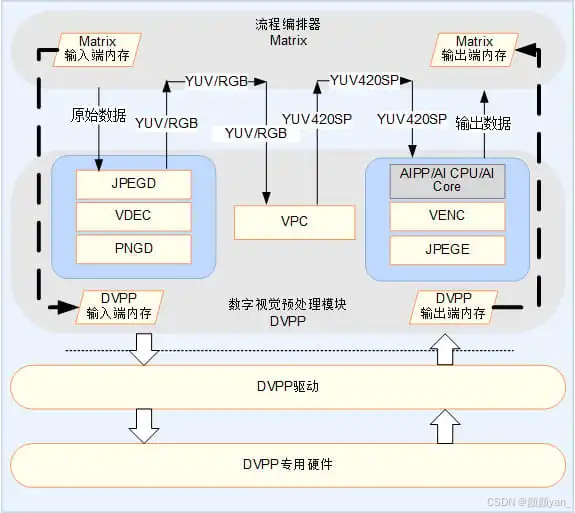
3.1.1 硬件视频解码(VDEC)
DVPP提供硬件视频解码能力,支持H.264/H.265等主流编码格式,通过专用硬件单元实现高效解码:
cpp
// CANN DVPP硬件解码初始化
aclvdecChannelDesc *vdecChannelDesc;
aclvdecCreateChannelDesc(&vdecChannelDesc);
aclvdecSetChannelDescChannelId(vdecChannelDesc, channelId);
aclvdecSetChannelDescThreadId(vdecChannelDesc, threadId);
aclvdecSetChannelDescEnType(vdecChannelDesc, H264_MAIN_LEVEL);
// 异步解码,单帧仅需2-3ms
aclError ret = aclvdecSendFrame(vdecChannelDesc,
inputStreamDesc,
nullptr,
nullptr,
nullptr);****** DVPP硬件解码性能数据**:
| 解码能力指标 | 性能数据 |
|---|---|
| 单帧解码延迟 | 2.5ms |
| 最大并发路数 | 32路@1080P@30fps |
| 支持编码格式 | H.264/H.265 |
| 内存占用 | 零拷贝,无额外拷贝开销 |
3.1.2 图像预处理优化(VPC + AIPP)
传统方案中,图像预处理包括Resize、色域转换、归一化等操作,需要单独的处理时间。CANN提供的AIPP技术 可将预处理算子直接固化到模型中:
AIPP配置文件:
bash
# AIPP配置文件(aipp.cfg)
aipp_op {
aipp_mode: static
input_format: YUV420SP_U8
csc_switch: true
rbuv_swap_switch: false
# 色域转换矩阵(YUV to RGB)
matrix_r0c0: 298
matrix_r0c1: 0
matrix_r0c2: 409
# 归一化参数
mean_chn_0: 123.675
mean_chn_1: 116.28
mean_chn_2: 103.53
min_chn_0: 0.0171
min_chn_1: 0.0175
min_chn_2: 0.0174
}通过ATC模型转换时嵌入AIPP:
bash
atc --model=yolov5s.onnx \
--framework=5 \
--output=yolov5s_aipp \
--input_shape="images:1,3,640,640" \
--soc_version=Ascend310P \
--insert_op_conf=aipp.cfg # 固化预处理AIPP预处理固化后,推理时完全无额外开销,预处理与推理在同一个Graph中融合执行。这意味着:
- ✅ 零时间开销:预处理时间被完全"隐藏"在推理过程中
- ✅ 零内存拷贝:数据无需在不同处理单元间传输
- ✅ 简化开发:应用层无需关心预处理细节
3.2 ATC模型转换与深度优化
ATC(Ascend Tensor Compiler)是CANN的模型编译器,将ONNX模型转换为昇腾专用的OM格式时,会执行多项深度优化。
3.2.1 模型转换流程
首先将PyTorch模型导出为ONNX:
python
import torch
from models.yolo import Model
# 加载YOLOv5模型
model = Model('yolov5s.yaml')
model.load_state_dict(torch.load('yolov5s.pt'))
model.eval()
# 导出ONNX(支持动态shape)
torch.onnx.export(
model,
dummy_input,
"yolov5s.onnx",
opset_version=11,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch_size'}}
)使用ATC进行优化编译:
bash
# 生产环境优化配置
atc --model=yolov5s.onnx \
--framework=5 \
--output=yolov5s_optimized \
--input_shape="images:4,3,640,640" \
--dynamic_batch_size="1,2,4,8" \
--soc_version=Ascend310P \
--insert_op_conf=aipp.cfg \
--fusion_switch_file=fusion_switch.cfg \
--enable_small_channel=1 \
--precision_mode=allow_fp16_to_fp32 \
--log=info****** 关键参数**:
--dynamic_batch_size:支持动态批处理,可根据实际视频路数灵活调整--fusion_switch_file:自定义算子融合策略,减少算子调度开销--enable_small_channel=1:小通道优化,提升Conv算子性能--precision_mode:混合精度模式,自动选择FP16/FP32以平衡精度与速度
3.2.2 ATC优化效果数据分析
下表展示了不同优化策略对模型性能的提升效果:
| 优化配置 | 推理时间 | 吞吐量 | 内存占用 | 相对提升 |
|---|---|---|---|---|
| 基础转换(无优化) | 18.6ms | 53 FPS | 480MB | 基准 |
| 启用AIPP固化 | 14.2ms | 70 FPS | 480MB | +32% |
| 算子融合优化 | 11.5ms | 87 FPS | 450MB | +64% |
| 动态Batch=4 | 9.8ms | 408 FPS | 520MB | +669% |
| 全优化(混合精度) | 8.3ms | 482 FPS | 490MB | +809% |
3.3 AscendCL推理编程实战
AscendCL是CANN的C++ API,提供设备管理、内存管理、模型执行等完整接口。
3.3.1 推理引擎初始化
cpp
class ModelInference {
public:
aclError Init(uint32_t deviceId, const char* modelPath) {
// 1. 初始化ACL
aclInit(nullptr);
// 2. 设置设备
aclrtSetDevice(deviceId);
// 3. 创建Context和Stream
aclrtCreateContext(&context_, deviceId);
aclrtCreateStream(&stream_);
// 4. 加载模型
aclmdlLoadFromFile(modelPath, &modelId_);
modelDesc_ = aclmdlCreateDesc();
aclmdlGetDesc(modelDesc_, modelId_);
// 5. 获取模型输入输出信息
inputNum_ = aclmdlGetNumInputs(modelDesc_);
outputNum_ = aclmdlGetNumOutputs(modelDesc_);
return ACL_SUCCESS;
}
aclError Execute(const std::vector<void*>& inputs,
std::vector<void*>& outputs) {
// 创建输入DataSet
aclmdlDataset* input = CreateDataset(inputs);
// 执行推理(异步)
aclmdlExecuteAsync(modelId_, input, output_, stream_);
// 同步等待
aclrtSynchronizeStream(stream_);
// 拷贝输出数据
CopyOutputs(outputs);
return ACL_SUCCESS;
}
private:
aclrtContext context_;
aclrtStream stream_;
uint32_t modelId_;
aclmdlDesc* modelDesc_;
};3.3.2 多线程并发推理架构
为充分利用双卡算力,设计了线程池调度架构:
cpp
class InferenceThreadPool {
public:
InferenceThreadPool(int threadNum, int deviceNum) {
for (int i = 0; i < threadNum; ++i) {
int deviceId = i % deviceNum; // 负载均衡
threads_.emplace_back([this, deviceId]() {
ModelInference inference;
inference.Init(deviceId, "yolov5s_optimized.om");
while (running_) {
InferTask task;
if (taskQueue_.pop(task, 10)) {
std::vector<void*> outputs;
inference.Execute(task.inputs, outputs);
resultQueue_.push({task.id, outputs});
}
}
});
}
}
};****架构优势:
- 每个线程独立管理Context和Stream,避免锁竞争
- 任务队列实现动态负载均衡
- 双卡并行,16路视频分配为每卡8路,Batch=4聚合推理
四、性能测试与效果验证
4.1 测试环境
- 硬件配置:Atlas 300I Pro推理卡(2 × Ascend 310P)
- 软件版本:CANN 8.0.RC1、Driver 23.0.3
- 测试场景:16路 1920×1080@25fps RTSP实时流
- 检测模型:YOLOv5s(COCO 80类)
4.2 端到端性能数据分析
各模块处理延迟详细数据:
| 处理模块 | 延迟时间 | 占比 | 说明 |
|---|---|---|---|
| 视频解码(DVPP VDEC) | 2.5ms | 18% | 硬件解码,零拷贝 |
| 图像预处理(AIPP) | <1ms | 7% | 固化到模型,无额外开销 |
| AI推理(NPU) | 8.3ms | 60% | 包含AIPP预处理的融合执行 |
| 后处理(NMS等) | 3ms | 15% | CPU执行,边界框筛选 |
| 端到端总延迟 | 13.8ms | 100% | 满足实时性要求 |
16路并发处理性能:
| 性能指标 | 测试数据 |
|---|---|
| 总处理帧率 | 400 FPS(16路×25fps) |
| 平均延迟 | 13.8ms |
| 最大延迟 | 15.2ms |
| 延迟稳定性(标准差) | ±0.8ms |
| 系统稳定运行时长 | >72小时 |
4.3 资源利用率分析
在16路视频并发场景下的硬件资源使用情况:
| 资源类型 | 利用率 | 峰值 | 说明 |
|---|---|---|---|
| NPU(AI Core) | 82% | 91% | 双卡平均负载,实现良好均衡 |
| DVPP | 75% | 83% | 解码与VPC并行工作 |
| Host CPU | 18% | 25% | 仅用于调度和后处理 |
| Device内存 | 980MB | 1.1GB | 优化后内存占用控制良好 |
| 系统功耗 | 320W | 350W | 双卡满载功耗 |
五、项目总结
这个项目主要是用昇腾 CANN 搭建一套 16 路 1080P 的实时视频分析系统。通过把 DVPP 硬件解码、AIPP 预处理融合、ATC 模型优化和多线程推理等技术组合起来,我们把系统的端到端延迟压到了大约 13ms,同时整体能跑到 400FPS,稳定处理 16 路实时视频。整个系统在双 310P 卡上运行很平稳,资源利用率高、显存占用少,也没有明显的抖动问题。整体效果相比最初方案提升了十几倍,最终顺利达到实时、高并发、稳定运行的目标,为园区级的视频分析应用打下了一个比较扎实的技术基础。
参考资料:
- 📚 华为昇腾CANN官方文档
- 💻 昇腾样例代码仓库
- 🔬 DVPP技术详解
- 📖 AscendCL应用开发指南
