关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
在自然语言处理(NLP)和文本分析领域,分词(Word Segmentation) 是最基础也是至关重要的一步。它指的是将连续的文本序列(如句子、段落)切分成具有独立语义或语法意义的词汇单元(词或 Token)的过程。
对于像英语这样以空格分隔单词的语言,分词相对简单。然而,对于中文、日文、泰文等没有明显词边界标记的语言,分词就成为一个复杂且核心的技术挑战。
Java 作为企业级应用和大型系统开发的主力语言,拥有众多成熟、高效的分词框架库。本节将介绍几个开箱即用的框架。
02 使用场景
2.1 搜索
比如:我们在百度搜索京东咸鱼,搜索结果里面即包括京东的相关信息,也包括咸鱼的相关信息。明显是经过了分词,才能得到的结果。如图:
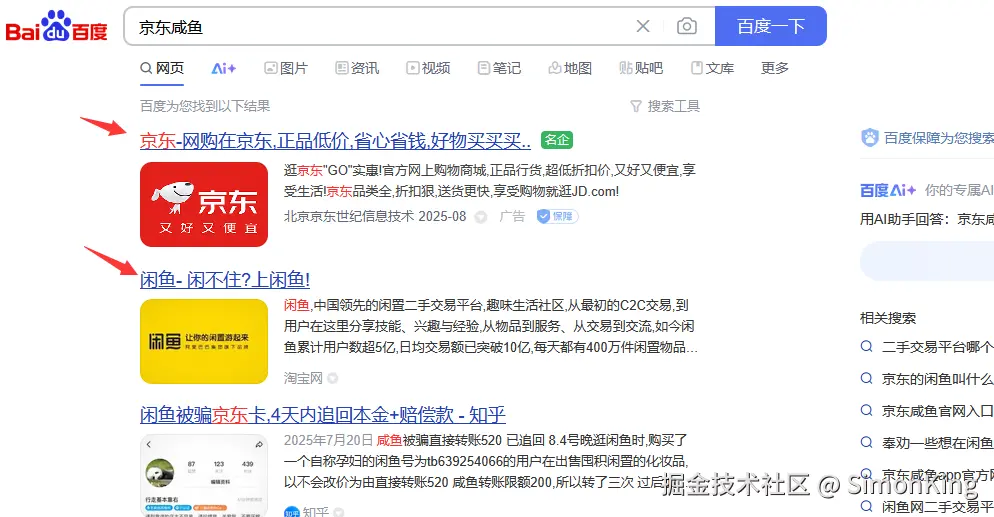
至于百度底层用的是什么搜索引擎,我们暂且不去关注。
搜索功能使用的频率很高,几乎每一个网站都可能用到,所用到的技术五花八门。有精确查询的、模糊匹配的还有使用所有引擎(如:ES、Solr、opensearch等)的。
不同场景,使用的技术自然也不一样。
- 精确查询:一般用户列表查询,多用于后台管理系统。
- 模糊匹配:一般用户快捷查询,多用于首页
- 搜索引擎:技术相对复杂,多用户海量的搜索。
精确查询和模糊匹配一般的数据都会支持,如Mysql,数据量比较少的情况下可以随意使用,数据量大起来,可以通过建立合适的索引提高查询效率。而模糊匹配一般都不会走索引,查询的效率相对来说比较低下。
如果需要大量的模糊搜索,且数据量大的话,搜索引擎将是不错的选择。搜索引擎中最终的一个就是分词器,通过分词器将输入的条件分成词条,使用倒排索引的技术,提高搜索的性能。
2.2 关键词拆分
如何从一个文本中提炼出关键词呢?如何将一段地址分割出省市区呢?......
依然需要分词,随着大模型的兴起,分词的功能变得越来越强大。可以实现语义分析、情感分析、纠错等复杂的场景。
03 IK分词器
IK分词器一直被认为是支持中文最好的分词器,常用做ES、Solr的分词插件,同样也提供了Maven版本的类库。
Github地址:github.com/magese/ik-a...
3.1 Maven依赖
xml
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.5.0</version>
</dependency>3.2 案例
java
@Test
void test01() throws IOException {
String text = "小米su7特斯拉modelY比亚";
StringReader reader = new StringReader(text);
IKSegmenter ikSegmenter = new IKSegmenter(reader, true);
// 动态加载
// Dictionary.getSingleton().addWords(Arrays.asList("特斯拉modelY"));
Lexeme lexeme;
while ((lexeme = ikSegmenter.next()) != null) {
System.out.println(lexeme.getLexemeText());
}
// 执行结果:
// 小米
// su7
// 特斯拉
// modely
// 比亚
}我们可以看到,我们做任何配置的情况下,IK已经分出了小米、su7、特斯拉、modely这样的词,还是比较满意的。
如果我们想小米su7变成一个词输出,我们又该如何是好呢?这时候,我们就需要扩展词库了。
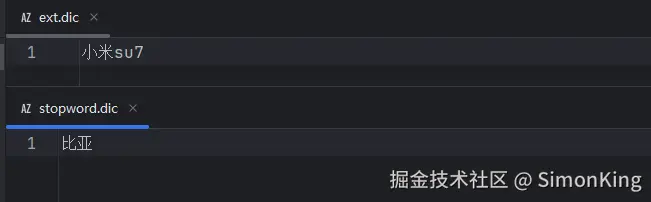
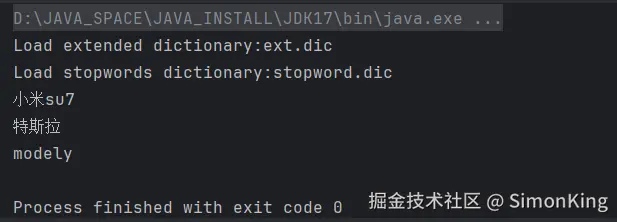
ext.dic:主词库的扩展词库stopword.dic:忽略的词库
例如:我们需要忽略比亚这个词,小米su7变成一个词。
我们需要在项目的resources下分别建立词库ext.dic和stopword.dic词库,并添加指定的词:
运行结果:
04 HanLP

HanLP的功能不局限于分词,具有丰富的功能。提供RESTful 和native 两种API,分别面向轻量级和海量级两种场景。无论何种API何种语言,HanLP接口在语义上保持一致。
用户还可以基于HanLP训练数据自己的模型词库、语料等。
GitHub地址:github.com/hankcs/HanL...
4.1 HanLP2.x
HanLP2.x是基于深度学习的,号称次世代最先进的NLP技术,支持包括简繁中英日俄法德在内的104种语言上的联合任务。
提供RESTful API,API地址:www.hanlp.com/api
Maven依赖
xml
<dependency>
<groupId>com.hankcs.hanlp.restful</groupId>
<artifactId>hanlp-restful</artifactId>
<version>0.0.12</version>
</dependency>案例
java
@Test
void test02() throws IOException {
String text = "小米su7特斯拉modelY比亚";
HanLPClient HanLP = new HanLPClient("https://www.hanlp.com/api", null);
Map<String, List> parse = HanLP.parse(text);
System.out.println(parse);
}结果

调用第三方API总是不可控的,功能虽然丰富,但是只用于分词就显的大材小用了,这里不展开讨论了。
官方提供了详细的说明文档,功能设计文本纠错、语义分析、情感分析等,有兴趣的可以直接测试,地址如下:
4.2 HanLP1.x
HanLP1.x是一个轻量级的工具包,比较符合我们日常使用。同样提供丰富的分词功能。如标准分词、NLP分词、索引分词等7种分词,人名识别、地名识别等6种识别以及其他功能。
文档地址:github.com/hankcs/HanL...
Maven
xml
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.6</version>
</dependency>案例1
标准分词
java
@Test
void test03() {
String text = "小米su7特斯拉modelY比亚";
System.out.println(HanLP.segment(text));
// [小米/n, su/nx, 7/m, 特斯拉/nrf, modelY/nx, 比/p, 亚/b]
}案列2
加载自定义词库:

java
@Test
void test04() {
Config.CustomDictionaryPath = new String[]{"dictionary/ext.txt"};
String text = "小米su7特斯拉modelY比亚";
System.out.println(HanLP.segment(text));
// [小米su7/n, 特/d, 斯/rg, 拉/v, modelY/nx, 比/p, 亚/j]
}动态加载词库:
java
@Test
void test05() {
// 动态增加
CustomDictionary.add("小米su7");
String text = "小米su7特斯拉modelY比亚";
System.out.println(HanLP.segment(text));
// [小米su7/nz, 特斯拉/nrf, modelY/nx, 比/p, 亚/b]
}其他的案例这里不再赘述,可以看考文档。
05 Jieba-analysis

Github地址:github.com/huaban/jieb...
5.1 Maven依赖
xml
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>5.2 案例
java
@Test
void test03() throws IOException {
String text = "小米su7特斯拉modelY比亚";
// 创建分词器对象
JiebaSegmenter segmenter = new JiebaSegmenter();
// 使用精确模式分词
List<String> segList = segmenter.sentenceProcess(text);
System.out.println("精确模式分词结果:" + segList);
// 精确模式分词结果:[小米, su7, 特斯拉, modelY, 比亚]
}06 Ansj_seg
6.1 Maven 依赖
xml
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.1</version>
</dependency>6.2 案例
java
@Test
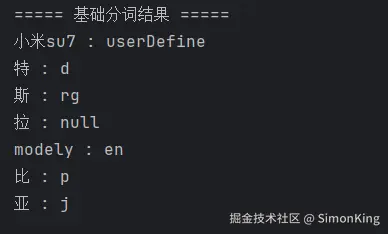
void test04(){
String text = "小米su7特斯拉modelY比亚";
// 动态添加分词
DicLibrary.insert(DicLibrary.DEFAULT, "小米su7");
Result result = ToAnalysis.parse(text);
System.out.println("===== 基础分词结果 =====");
result.getTerms().forEach(term ->
System.out.println(term.getName() + " : " + term.getNatureStr())
);
}
07 小结
中文分词的框架很多,小编以为IK对中文支持最好,HanLP功能更丰富,且比较活跃。当然还有其他优秀的中文分词框架。评论区可以留言讨论。